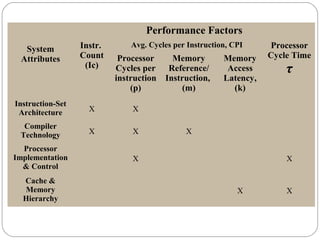
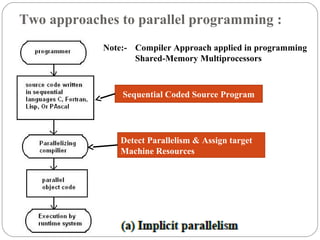
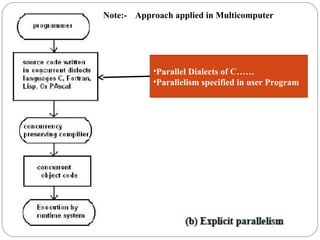
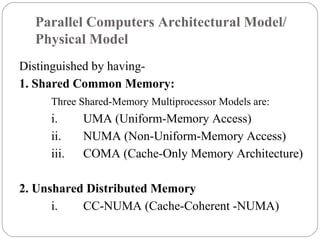
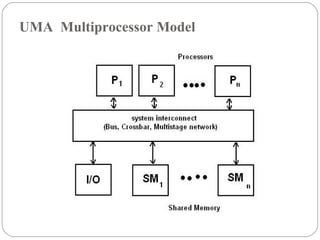
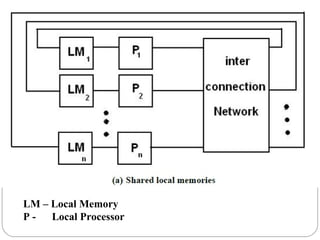
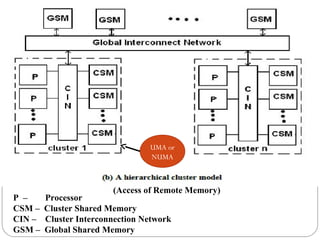
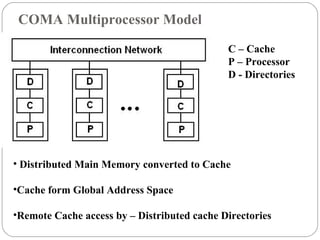
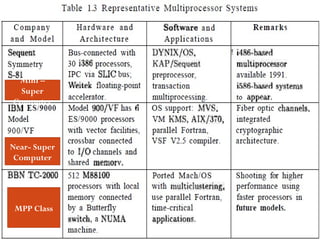
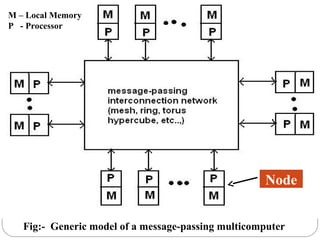
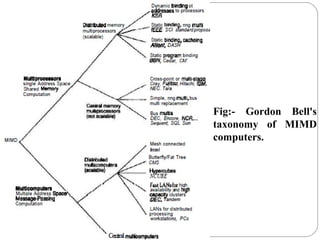
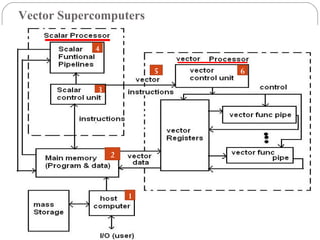
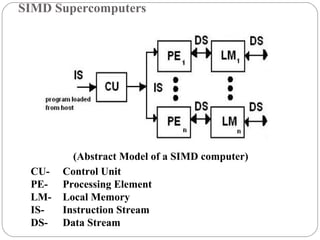
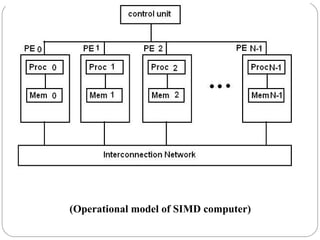
This document discusses various attributes that influence computer system performance. It covers topics like instruction count, cycles per instruction, processor cycle time, memory access latency, and how factors like instruction set architecture, compiler technology, processor implementation, and memory hierarchy can affect these performance attributes and metrics like instructions per second. It also summarizes different types of parallel computer architectures like shared-memory multiprocessors, distributed-memory multicomputers, vector supercomputers and SIMD machines.