Related work
• Thefuture frame prediction problem系:
– 過去のframeで条件付けて未来のframeを予測する
– この中でさらに2系統に分かれる
• 過去のframeから生のpixelを予想
– Decomposing Motion and Content for Natural Video Sequence Prediction (ICLR2017) など
• 過去のframeのpixelをreshuffleして未来のframeを構成
– Unsupervised Learning for Physical Interaction through Video Prediction (NIPS2016) など
• GAN系:
– Generating Videos with Scene Dynamics (NIPS2016)
– Temporal Generative Adversarial Nets with Singular Value Clipping (ICCV2017)
• 時間をモデル化するために、それぞれの論文が色々やっている
6
References
• Sergey Tulyakov.Ming-Yu Liu. Xiaodong Yang. Jan Kautz. MoCoGAN: Decomposing Motion and Content for
Video Generation, arXiv preprint arXiv:1707.04993, 2017.
• R. Villegas, J. Yang, S. Hong, X. Lin, and H. Lee. Decomposing motion and content for natural video sequence
prediction. In International Conference on Learning Representation, 2017.
• C. Finn, I. Goodfellow, and S. Levine. Unsupervised learning for physical interaction through video prediction. In
Advances In Neural Information Processing Systems, 2016.
• C. Vondrick, H. Pirsiavash, and A. Torralba. Generating videos with scene dynamics. In Advances In Neural
Information Processing Systems, 2016.
• M.Saito. E.Matsumoto. S.Saito, Temporal Generative Adversarial Nets with Singular Value Clipping, in ICCV,
2017.
• S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text to image
synthesis. In International Conference on Machine Learning, 2016
• Augustus Odena, Christopher Olah, and Jonathon Shlens. Conditional image synthesis with auxiliary classifier
gans. arXiv preprint arXiv:1610.09585, 2016.
• T.Salimans,I.Goodfellow,W.Zaremba,V.Cheung,A.Radford, and X. Chen. Improved techniques for training gans. In
Advances in Neural Information Processing Systems, 2016.
• C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the Inception Architecture for
Computer Vision. ArXiv e-prints, December 2015.
• Kumar Sricharan. Raja Bala. Matthew Shreve. Hui Ding. Kumar Saketh. Jin Sun. Semi-supervised Conditional
GANs, arXiv preprint arXiv:1708.05789, 2017.
• 特に明記がない限り、画像はスライドで引用中の論文より 23
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
MoCoGAN: Decomposing Motion and Content forVideo
Generation
Kei Akuzawa, Matsuo Lab M1](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
MoCoGAN: Decomposing Motion and Content forVideo
Generation
Kei Akuzawa, Matsuo Lab M1](https://image.slidesharecdn.com/0911mocogan-170911121936/75/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-1-2048.jpg)




![Decomposing Motion and Content for Natural Video Sequence Prediction
[Villegas 2017] (MCnet)
• MoCoGANと手法は全く違うが、motionと
contentを分離するというアイデアは共通
• t期以前の画像からt+1期の画像を予測
– x_tをcontentと捉える
– x_t - x_{t-1} をmotionと捉える
• デモ↓
– https://sites.google.com/a/umich.edu/rube
nevillegas/iclr2017
7](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-7-320.jpg)
![Unsupervised Learning for Physical Interaction through Video Prediction
[Finn 2016]
• 過去のframeのpixelをかき混ぜて新しいframeを作る
• 画像をConvolutional LSTMで畳み込んでフィルターを作り、そのフィル
ターを元画像にあててpixelを再構築(理解浅いです)
8](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-8-320.jpg)
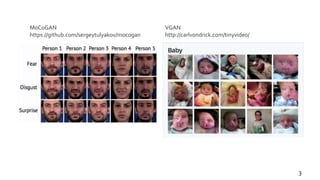
![Generating Videos with Scene Dynamics
[Vondrick 2016] (VGAN)
• 動画をforeground(動く)とbackground
(動かない)に分割
– 「backgroundを固定」は強い仮定(カメラの手
ブレなど)
• 同一のnoiseからdeconvでそれらを生成
し、加重平均をとる
• 画像で条件付けてfuture predictionさせ
ることも可能
• 個人的見解
– 左下図を見るにforegroundの生成が上手く
いっていない。contentとmotionを同一の
noiseで扱うことによりモデルの複雑性が増し
ている?
– 画像作ってから足し合わせるのはよくないん
じゃないか(ズレに敏感そう)
9](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-9-320.jpg)
![Temporal Generative Adversarial Nets with Singular Value Clipping
[M.Saito, Matsumoto, S.Saito 2017] (Temporal GAN)
• 3Dの畳み込みを批判(時間と空間
の特性の違いを考慮すべき)
– ビデオ認識の研究でもこの指摘があるらしい
– しかし今回Discriminatorは3Dの畳み込みを利用、
Generatorのみ特別仕様
• temporal generatorがframe数だけ
latent variableを生成し、それを元
にimage generatorが個々の画像を
生成
• 生成した2枚の画像間の中間画像
も容易に生成できる
• WGANを改良(Singular Value
Clipping)して学習を安定化
10](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-10-320.jpg)

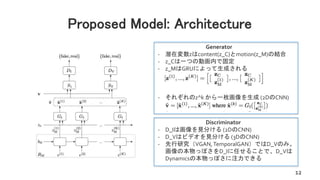
![Proposed Model: Training
• LossはD_VとD_Iについて和をとる
• one sided label smoothing trick [Salimans
2016], [Szegedy 2015]
• 可変長のvideoを生み出す工夫
– video lengthの経験分布を作る
– 分布からvideo lengthをサンプリング
– 生成した可変長の動画から、決まった長さ
を切り取りD_Vに渡す
• D_Vは3DのCNNなので固定長しか受け取れな
いことに注意
13
loss function
Update](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-13-320.jpg)
![補足: One sided label smoothing trick [Salimans 2016], [Szegedy 2015]
• 予測されたラベルD(x)の値が極端な値をとると、過学習を起こしやすく好ましくない。
• Generatorを固定した元での最適なDiscriminatorを以下のようにしてsmoothing
• ただし、分子にp_{model}があると問題
– p_{data]が0に近い場所で、p_{model}が高い確率を割り当てると、Discriminatorをうまく騙せていることになるので、Generatorが
移動するインセンティブを削る
• 結局以下のようにする
14](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-14-320.jpg)
![Proposed Model: Action Conditioned
• text-to-image[Reed 2016]を参考に、actionで条件付けられるようにモデルを拡張できる
– ラベルを埋め込んだもの(z_A)をInput noiseと結合する?(想像)
• actionはmotionとcontentの両方に影響すると考えられる(後述)
– 例: バスケとホッケーじゃユニフォームが違う
• Discriminatorは、真偽とaction labelを同時に見分ける
– Auxiliary classifier GAN[odena 2016] ??
– Improved Techniques for Training GANs [Salimans 2016] ??
15](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-15-320.jpg)
![補足: GANの条件付け
図はSricharan 2017 ( https://arxiv.org/abs/1708.05789 )より
16
• DはlabelをInputとして受け取る • Dはlabelを予測する
• Auxiliary classifier GAN [odena 2016] : Dは真偽とラベルのそれ
ぞれを出力する。
• Improved Techniques for Training GANs [Salimans 2016]:(ラベル
+fake)のK+1次元を出力させる](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-16-320.jpg)


![Experiments: various MoCoGAN settings
• モデル構造の検証
– DiscriminatorをD_Vだけにする
– action labelの組み込み方
• どちらか選ぶ
• 結果:
– D_Iも使ったほうが良さそう
– 𝜖′ = [𝜖, 𝑧 𝐴] が良さそう
19](https://image.slidesharecdn.com/0911mocogan-170911121936/85/DL-MoCoGAN-Decomposing-Motion-and-Content-for-Video-Generation-19-320.jpg)








![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Wavenet a generative model for raw audio](https://cdn.slidesharecdn.com/ss_thumbnails/wavenetagenerativemodelforrawaudio-160920054055-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Controllable Invariance through Adversarial Feature Learning” (NIPS2017)](https://cdn.slidesharecdn.com/ss_thumbnails/20171121iwasawa-171120061515-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DLHacks] DLHacks説明資料](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-170919004557-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Efficient Video Generation on Complex Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20190823dvd-ganlast-190826093116-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)


























