Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
RS
Uploaded by
Ryota Suzuki
PPTX, PDF
24,934 views
【2017年】ディープラーニングのフレームワーク比較
Caffe,Caffe2,TensorFlow,Keras,Torch,PyTorch,Chainer,MatConvNetの各ディープラーニングフレームワークについて,実際の使用感を比較しました.
Technology
◦
Related topics:
Deep Learning
•
Read more
17
Save
Share
Embed
Embed presentation
Download
Downloaded 181 times
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
10
/ 20
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PDF
20171212 gtc pfn海野裕也_chainerで加速する深層学習とフレームワークの未来
by
Preferred Networks
PPTX
ChainerでDeep Learningを試すために必要なこと
by
Retrieva inc.
PDF
ディープラーニング最近の発展とビジネス応用への課題
by
Kenta Oono
PDF
進化するChainer
by
Yuya Unno
PPTX
DLフレームワークChainerの紹介と分散深層強化学習によるロボット制御
by
Ryosuke Okuta
PPTX
深層学習 第4章 大規模深層学習の実現技術
by
孝昌 田中
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
by
marsee101
PDF
Convolutional Neural Network @ CV勉強会関東
by
Hokuto Kagaya
20171212 gtc pfn海野裕也_chainerで加速する深層学習とフレームワークの未来
by
Preferred Networks
ChainerでDeep Learningを試すために必要なこと
by
Retrieva inc.
ディープラーニング最近の発展とビジネス応用への課題
by
Kenta Oono
進化するChainer
by
Yuya Unno
DLフレームワークChainerの紹介と分散深層強化学習によるロボット制御
by
Ryosuke Okuta
深層学習 第4章 大規模深層学習の実現技術
by
孝昌 田中
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
by
marsee101
Convolutional Neural Network @ CV勉強会関東
by
Hokuto Kagaya
What's hot
PPTX
MIRU2014 tutorial deeplearning
by
Takayoshi Yamashita
PDF
Deep learningの概要とドメインモデルの変遷
by
Taiga Nomi
PDF
PythonによるDeep Learningの実装
by
Shinya Akiba
PDF
TensorFlowで学ぶDQN
by
Etsuji Nakai
PPTX
ChainerでDeep Learningを試す為に必要なこと
by
Jiro Nishitoba
PDF
これから始める人のためのディープラーニング基礎講座
by
NVIDIA Japan
PDF
LSTM (Long short-term memory) 概要
by
Kenji Urai
PPTX
Cvim saisentan-6-4-tomoaki
by
tomoaki0705
PDF
深層学習入門
by
Danushka Bollegala
PDF
Introduction to Chainer (LL Ring Recursive)
by
Kenta Oono
PDF
深層学習フレームワーク Chainer の開発と今後の展開
by
Seiya Tokui
PDF
Deep Learning技術の最近の動向とPreferred Networksの取り組み
by
Kenta Oono
PDF
TensorFlowによるCNNアーキテクチャ構築
by
Hirokatsu Kataoka
PPTX
深層学習とTensorFlow入門
by
tak9029
PDF
20180227_最先端のディープラーニング 研究開発を支えるGPU計算機基盤 「MN-1」のご紹介
by
Preferred Networks
PDF
「TensorFlow Tutorialの数学的背景」 クイックツアー(パート1)
by
Etsuji Nakai
PPTX
多層NNの教師なし学習 コンピュータビジョン勉強会@関東 2014/5/26
by
Takashi Abe
PDF
Deep learning入門
by
magoroku Yamamoto
PDF
Deep Learningと画像認識 ~歴史・理論・実践~
by
nlab_utokyo
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
MIRU2014 tutorial deeplearning
by
Takayoshi Yamashita
Deep learningの概要とドメインモデルの変遷
by
Taiga Nomi
PythonによるDeep Learningの実装
by
Shinya Akiba
TensorFlowで学ぶDQN
by
Etsuji Nakai
ChainerでDeep Learningを試す為に必要なこと
by
Jiro Nishitoba
これから始める人のためのディープラーニング基礎講座
by
NVIDIA Japan
LSTM (Long short-term memory) 概要
by
Kenji Urai
Cvim saisentan-6-4-tomoaki
by
tomoaki0705
深層学習入門
by
Danushka Bollegala
Introduction to Chainer (LL Ring Recursive)
by
Kenta Oono
深層学習フレームワーク Chainer の開発と今後の展開
by
Seiya Tokui
Deep Learning技術の最近の動向とPreferred Networksの取り組み
by
Kenta Oono
TensorFlowによるCNNアーキテクチャ構築
by
Hirokatsu Kataoka
深層学習とTensorFlow入門
by
tak9029
20180227_最先端のディープラーニング 研究開発を支えるGPU計算機基盤 「MN-1」のご紹介
by
Preferred Networks
「TensorFlow Tutorialの数学的背景」 クイックツアー(パート1)
by
Etsuji Nakai
多層NNの教師なし学習 コンピュータビジョン勉強会@関東 2014/5/26
by
Takashi Abe
Deep learning入門
by
magoroku Yamamoto
Deep Learningと画像認識 ~歴史・理論・実践~
by
nlab_utokyo
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
Viewers also liked
PPTX
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
PPTX
地震対策ハッカソン キズナコントラクト
by
彩友美 小岩
PDF
Waston が拓く UX の新しい地平 〜 UX デザイナーが IBM Waston を使ってみた 〜:2017年4月22日 AI eats UX me...
by
Yoshiki Hayama
PDF
Watsonに、俺の推しアイドルがかわいいと、わかってほしかった:2017年12月3日 IBM Cloud (Bluemix) 冬の大勉強会
by
Yoshiki Hayama
PDF
SoftLayer Bluemix Summit 2015: BluemixでWatsonをつかいたおせ!
by
Miki Yutani
PPTX
ニューラルネットワークの仕組みを学ぶ 20170623
by
Hiroki Takahashi
PDF
Atlassian Japan Forum 2017 The Information Ageの現実 なぜ組織が構造改革を進めなければならないのか
by
アトラシアン株式会社
PDF
Dots deep learning部_20161221
by
陽平 山口
PPTX
古典的ゲームAIを用いたAlphaGo解説
by
suckgeun lee
PPTX
【LT版】Elixir入門「第7回:Python/KerasをElixirから繋いでアレコレする」
by
fukuoka.ex
PPTX
【macOSにも対応】AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」
by
fukuoka.ex
PPTX
[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation
by
Deep Learning JP
PPT
AlphaGo Zero 解説
by
suckgeun lee
PDF
Kerasで深層学習を実践する
by
Kazuaki Tanida
PPTX
一年目がWatsonを調べてみた Discovery編
by
Jin Hirokawa
PDF
Watson Build Challengeに参加してみた
by
Wataru Koyama
PDF
Pycon2017
by
Yuta Kashino
PDF
Tokyo webmining 2017-10-28
by
Kimikazu Kato
PDF
Pythonを使った機械学習の学習
by
Kimikazu Kato
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
地震対策ハッカソン キズナコントラクト
by
彩友美 小岩
Waston が拓く UX の新しい地平 〜 UX デザイナーが IBM Waston を使ってみた 〜:2017年4月22日 AI eats UX me...
by
Yoshiki Hayama
Watsonに、俺の推しアイドルがかわいいと、わかってほしかった:2017年12月3日 IBM Cloud (Bluemix) 冬の大勉強会
by
Yoshiki Hayama
SoftLayer Bluemix Summit 2015: BluemixでWatsonをつかいたおせ!
by
Miki Yutani
ニューラルネットワークの仕組みを学ぶ 20170623
by
Hiroki Takahashi
Atlassian Japan Forum 2017 The Information Ageの現実 なぜ組織が構造改革を進めなければならないのか
by
アトラシアン株式会社
Dots deep learning部_20161221
by
陽平 山口
古典的ゲームAIを用いたAlphaGo解説
by
suckgeun lee
【LT版】Elixir入門「第7回:Python/KerasをElixirから繋いでアレコレする」
by
fukuoka.ex
【macOSにも対応】AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」
by
fukuoka.ex
[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation
by
Deep Learning JP
AlphaGo Zero 解説
by
suckgeun lee
Kerasで深層学習を実践する
by
Kazuaki Tanida
一年目がWatsonを調べてみた Discovery編
by
Jin Hirokawa
Watson Build Challengeに参加してみた
by
Wataru Koyama
Pycon2017
by
Yuta Kashino
Tokyo webmining 2017-10-28
by
Kimikazu Kato
Pythonを使った機械学習の学習
by
Kimikazu Kato
Similar to 【2017年】ディープラーニングのフレームワーク比較
PDF
Basic deep learning_framework
by
KazuhiroSato8
PDF
Deep Learning Implementations: pylearn2 and torch7 (JNNS 2015)
by
Kotaro Nakayama
PDF
GPU と PYTHON と、それから最近の NVIDIA
by
NVIDIA Japan
PDF
[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用
by
de:code 2017
PDF
研究を加速するChainerファミリー
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
tfug-kagoshima
by
tak9029
PDF
エヌビディアが加速するディープラーニング ~進化するニューラルネットワークとその開発方法について~
by
NVIDIA Japan
PPTX
DataEngConf NYC’18 セッションサマリー #2
by
gree_tech
PDF
TensorFlow XLAの可能性
by
Mr. Vengineer
PDF
深層学習フレームワークChainerの特徴
by
Yuya Unno
PDF
TensorFlow XLA とハードウェア
by
Mr. Vengineer
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
[ML15]Class Cat佐々木さん「いち早く人工知能テクノロジーを取り入れた製品・サービスを市場に展開するには?」
by
AINOW
PPTX
OSS強化学習フレームワークの比較
by
gree_tech
PDF
機械学習プロジェクトにおける Cloud AI Platform の使い方 (2018-11-19)
by
Yaboo Oyabu
PDF
エヌビディアが加速するディープラーニング~進化するニューラルネットワークとその開発方法について~
by
NVIDIA Japan
PDF
10年ぶりの ニューラルネットワーク
by
Takatsugu Nokubi
PPTX
いきなりAi tensor flow gpuによる画像分類と生成
by
Yoshi Sakai
PDF
TFUG_yuma_matsuoka__distributed_GPU
by
YumaMatsuoka
PDF
深層学習フレームワーク Chainerとその進化
by
Yuya Unno
Basic deep learning_framework
by
KazuhiroSato8
Deep Learning Implementations: pylearn2 and torch7 (JNNS 2015)
by
Kotaro Nakayama
GPU と PYTHON と、それから最近の NVIDIA
by
NVIDIA Japan
[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用
by
de:code 2017
研究を加速するChainerファミリー
by
Deep Learning Lab(ディープラーニング・ラボ)
tfug-kagoshima
by
tak9029
エヌビディアが加速するディープラーニング ~進化するニューラルネットワークとその開発方法について~
by
NVIDIA Japan
DataEngConf NYC’18 セッションサマリー #2
by
gree_tech
TensorFlow XLAの可能性
by
Mr. Vengineer
深層学習フレームワークChainerの特徴
by
Yuya Unno
TensorFlow XLA とハードウェア
by
Mr. Vengineer
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
[ML15]Class Cat佐々木さん「いち早く人工知能テクノロジーを取り入れた製品・サービスを市場に展開するには?」
by
AINOW
OSS強化学習フレームワークの比較
by
gree_tech
機械学習プロジェクトにおける Cloud AI Platform の使い方 (2018-11-19)
by
Yaboo Oyabu
エヌビディアが加速するディープラーニング~進化するニューラルネットワークとその開発方法について~
by
NVIDIA Japan
10年ぶりの ニューラルネットワーク
by
Takatsugu Nokubi
いきなりAi tensor flow gpuによる画像分類と生成
by
Yoshi Sakai
TFUG_yuma_matsuoka__distributed_GPU
by
YumaMatsuoka
深層学習フレームワーク Chainerとその進化
by
Yuya Unno
【2017年】ディープラーニングのフレームワーク比較
1.
【2017年】ディープラーニング のフレームワーク比較 SEPT., 2017 鈴木亮太,大津耕陽,歌田夢香,細原大輔
2.
フレームワーク多すぎ • Amazon Machine
Learning, Apache SINGA, Big Sur, BigDL, Blocks, Caffe, Caffe2, Chainer, cuda-convnet, cuDNN, darknet, Deeplearning4j, deepy, DIGITS, Dlib, DSSTNE, DyNet, Eblearn, Keras, Lasagne, MatConvnet, Mathematica, Microsoft Cognitive Toolkit (CNTK), Minerva, Mocha.JL, MXNet, neon, Neural Designer, Nnabla, nolearn, NV-Caffe, OpenDeep, PaddlePaddle, PredictionIO, Purine, PyBrain, Pylearn2, PyTorch, Sparking Warter, TensorFlow, Theano, Torch7, Watson ◦ 他多数 • なにこれ • 推測するに,理論的には単純で実装が簡単だから「よーしおれらもつくるべー」 が量産された結果だと思われる. ◦ あるいはcaffeつらい • で,どれがいいの?
3.
概要 • メンバーが実際に使ってみて,各フレームワーク×各観点で分析を行いました. ◦ インストールしやすさ ◦
実装の容易さ ◦ 処理速度 ◦ 学習速度を実験して比較 ◦ 他と比較した特徴 ◦ 10年後残る? ◦ 使用可能言語 ◦ 拡張性 ◦ Windowsで使える? • フレームワーク ◦ Caffe/Caffe2, Torch7/PyTorch, TensorFlow,Keras,Chainer,MatConvNet
4.
特徴早見表 • Caffe/Caffe2 ◦ 古豪 ◦
Caffe2からFacebook ◦ インストール・開発困難→Caffe2で改善 ◦ コードが長い ◦ 最速 • Torch7/PyTorch ◦ Facebook ◦ 高速(Caffe並み) ◦ 開発が楽 ◦ 研究者ユーザが多い • TensorFlow ◦ Google製 ◦ 低速 ◦ 学習(Session)に慣れが必要 • Keras ◦ 非常におてがる,初心者の勉強向け ◦ 勉強だけにして早期卒業をお勧め • Chainer ◦ PFN ◦ 日本人ユーザがほとんど ◦ Define by Run ◦ メンテナンスがホット • MatConvNet ◦ MATLABでつかえる ◦ 研究者ユーザが多い • Theano/PyLearn2 ◦ 古豪2 ◦ しらない ◦ 終了のお知らせ
5.
Caffe • 古豪 ◦ 使い続ける従来のユーザが多い ◦
でも絶賛人口流出中 • 言語 ◦ C++ベース,Pythonも • 苦行 ◦ インストールが大変? ◦ 初心者には苦行 ◦ 最近はそれほどでもない ◦ Windowsにも素直に入る ◦ コーディングがすごく大変 ◦ 一つのネットワーク組むのに3倍以上コード書かさ れる ◦ 一つのネットワークに複数のファイルを用意する 必要があってつらい ◦ 一線を画すガラパゴス感 • 最速 ◦ すごいはやい ◦ Python系はオーバヘッドがある ◦ 学習速度は正義 ◦ 週オーダが日オーダになれば色々試行錯誤して よりよいものが作れる ◦ 開発系・組み込み系では更に重要 • Caffe2の出現に期待感 • 10年後残る? ◦ Caffe2の頑張りで残ると思われる
6.
Caffe2 • FacebookがメンテするCaffeの後継 ◦ Torchとの連携が目論めそう •
ネットワーク構築方法が他のフレーム ワークに近くなる,ユーティリティインタ フェースがついた ◦ イマドキな感じで使える かも(未調査) • インストールが辛い ◦ まだWindowsでの安定的なインストール が不能 ◦ Caffeのようにこれから改善する?
7.
Torch7 • Facebookが拡張を出してる • Lua ◦
モジュールの中身はC++なので,C++ラッ パーもある • 高速?(Caffe並み?) ◦ arXivの論文によれば. ◦ 実際使ってみると遅いことが… ◦ 「速い」って言ってるスコアが出ない =ビルドが難物? • 開発が楽 ◦ Kerasに毛が生えたレベルで使えるもよう ◦ 有用なモジュールが多数あって便利 • インストールは楽なほう • Windowsへのインストールは絶望レベル に困難 ◦ 一応やりかたはQiitaの記事にまとめました • ヨーロッパの研究者のユーザ人口が多 い? • 再現性が高い ◦ いざPublishされているものを試してみると, 他のものでは同じ値が出てこないが,Torch だとそのまま出てくる • 総じて研究者向け ◦ 開発にも使えるか
8.
PyTorch • Facebookがメンテナンスしている • Python •
ChainerのForkなので,Chainerとよく似 てる ◦ モジュール名が違うくらい • Define by Run • Python系では最速 ◦ 中身のテンソル計算系などのC++実装が Torchの流用 ◦ データローダが高速 ◦ (本稿では)なぜかTorchよりはやい • インストール,開発が楽 ◦ Windowsでも問題なし • PyTorchに移行するTorchユーザ多い
9.
TensorFlow • Google製 ◦ ユーザ人口が最大 ◦
検索すればやりたいことはほぼ必ず見つかる ◦ 企業ユーザが多い? ◦ シェアは正義 • Python,C++ • 開発が楽 ◦ DNN分かっている人なら,が前につく ◦ 拡張がやりやすい • 低速? ◦ 意外と早い? 安定して最速ビルドを利用できる模様 • 難しい? ◦ 「計算グラフ」で実装する低レベル仕様 ◦ 開発・DNN初心者が触るのは難しいかも ◦ ユーザ多い=初心者・非エンジニア多い ◦ Kerasの吸収で解決するかも • マシン分散がやりやすい ◦ (研究界と比較して)大資産な企業と親 和性が高い • 今後,更に人口が増えるのでは
10.
Keras • 「お手軽」が至上のテーマ • すごく簡単 ◦
インストール1行,気にしなくても勝手に GPUで高速化 ◦ コーディングもいちばん簡単 ◦ あらゆる部分がブラックボックス化してい て,もはやプログラミング不要.ただマー クアップするだけ • TensorFlow,Theanoをバックエンドに する ◦ ユーザ的にはほぼTensorFlowが現状か • 開発者が一人 ◦ 状況が変わると開発終了するかも • TensorFlowに吸収され中 ◦ Kerasモジュールがある ◦ しばらくしたら不要になる? ◦ 「TensorFlowは難しい」を払拭する?
11.
Chainer • 日本の企業Prefered Networks(PFN) が作っている •
Define by Runのさきがけ ◦ 真にRNNを実装可能なパラダイム ◦ 自然言語処理系に強い • DNNをよく知っている必要がありそう • インストール簡単 • DNNはもちろん,様々な機械学習がで きるフレームワークとして成長中 • 機械学習屋が使うのに便利そう • 低速? ◦ 実行時にネットワークをコンパイルする 模様 ◦ 本当に遅いのかちゃんと調べたい
12.
MatConvNet • MATLABで使える ◦ MATLAB使ってた研究者にモテモテ •
これ自体はフリーで導入も簡単 ◦ Parallel Conputing Toolbox(有料)が必要 • インストール超簡単 ◦ さすが有料なだけあるMATLAB • ネットワーク構築の書き方は独特 • 低速? ◦ 要調査
13.
その他 • CNTK ◦ Microsoft様 ◦
高速,多言語らしい • DyNet ◦ Define by Runだって • MXNet ◦ 高速だって • Deeplearning4j ◦ Javaだって
14.
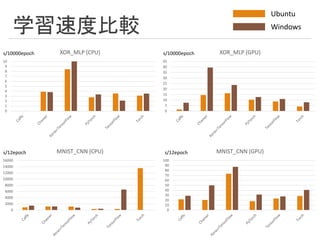
学習速度比較 0 2000 4000 6000 8000 10000 12000 14000 16000 MNIST_CNN (CPU) 0 1 2 3 4 5 6 7 8 9 10 XOR_MLP (CPU) 0 10 20 30 40 50 60 70 80 90 100 MNIST_CNN
(GPU) 0 5 10 15 20 25 30 35 40 45 XOR_MLP (GPU) Ubuntu Windows s/10000epoch s/10000epoch s/12epoch s/12epoch
15.
学習速度比較 • Caffeはやっぱり最速 • TensorFlowは実は速い?PyTorchも速 そう •
なぜかTorchが遅い ◦ ビルドのところで揺れがある?=インス トールが鬼門? • Kerasはとりあえず遅い ◦ TensorFlowバックエンドなのに,何してる の? • MatConvNetは遅いかもしれない 調査を続けたい • 実は学習速度≠全体の実行速度 ◦ Chainerはぱっと見遅いが,実はDefine by Runの都合上,ネットワークコンパイ ルも計測時間に含まれてしまっているの で注意. • ビルドのやり方,環境によって実行速 度に差が出る ◦ 速度的に安定したビルドの仕方がな い? • 速度のボトルネック要因 ◦ データセットのロード ◦ ネットワークのコンパイル ◦ メモリの扱い ◦ ループのオーバヘッド? ◦ ネットワークの計算 今回の計測ターゲット
16.
言語で比較 • 基本的にラッパーが出回る ◦ 特にC++のラッパーは多いので使うとき に調査するべき ◦
Caffeモデルに変換してCaffe on OpenCV が個人的にオススメ • C++ ◦ Caffe, TnsorFlow • Lua ◦ Torch • Python ◦ TensorFlow, Keras, PyTorch, Chainer • Matlab ◦ MatConvNet • Java ◦ Deeplearning4j • C# ◦ CNTK
17.
結論 • 折角いろいろあるので,適材適所がよいのでは ◦ あとは宗教 •
下記,メンバーのお勧めです. • 初心者 ◦ Tensorflow/Kerasがよさそうです.実に簡単にNNが構築でき,Web資料も親切なのが多いです. ◦ が,玉石混交なので逆に欲しい情報にたどり着かないことも・・・ ◦ (今のところ)Caffeはいろいろと苦行なのでやめておいたほうが… • 企業エンジニア ◦ プロトタイピングにTensorFlow/Torch,開発にCaffe ◦ 自社開発 ◦ 今からメジャーになるのはまずムリだと思いますが • 研究者 ◦ TensorFlowかPyTorchがオススメ ◦ Chainer vs PyTorch > PyTorchがメジャーとりそうな流れ ◦ Caffeが安定して高速動作するのでその点ではオススメ.難しいけど… • 宗教家 ◦ Java教,Microsoft教,…
18.
おまけ
19.
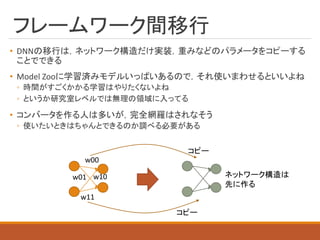
フレームワーク間移行 • DNNの移行は,ネットワーク構造だけ実装,重みなどのパラメータをコピーする ことでできる • Model
Zooに学習済みモデルいっぱいあるので,それ使いまわせるといいよね ◦ 時間がすごくかかる学習はやりたくないよね ◦ というか研究室レベルでは無理の領域に入ってる • コンバータを作る人は多いが,完全網羅はされなそう ◦ 使いたいときはちゃんとできるのか調べる必要がある w00 w01 w10 w11 コピー コピー ネットワーク構造は 先に作る
20.
ハイパーパラメータのチューニング • 「最適」の保証は理論的にない • 学習率が一番影響が大きいので頑張って調整しましょう •
探索をやりましょう ◦ グリッド探索 ◦ ベイズ推定 • ネットワーク構造は最大・自動生成不能パラメータ
Download


























































![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)










![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)








![[ML15]Class Cat佐々木さん「いち早く人工知能テクノロジーを取り入れた製品・サービスを市場に展開するには?」](https://cdn.slidesharecdn.com/ss_thumbnails/classcatml15-20170226-170306025120-thumbnail.jpg?width=640&height=640&fit=bounds)






