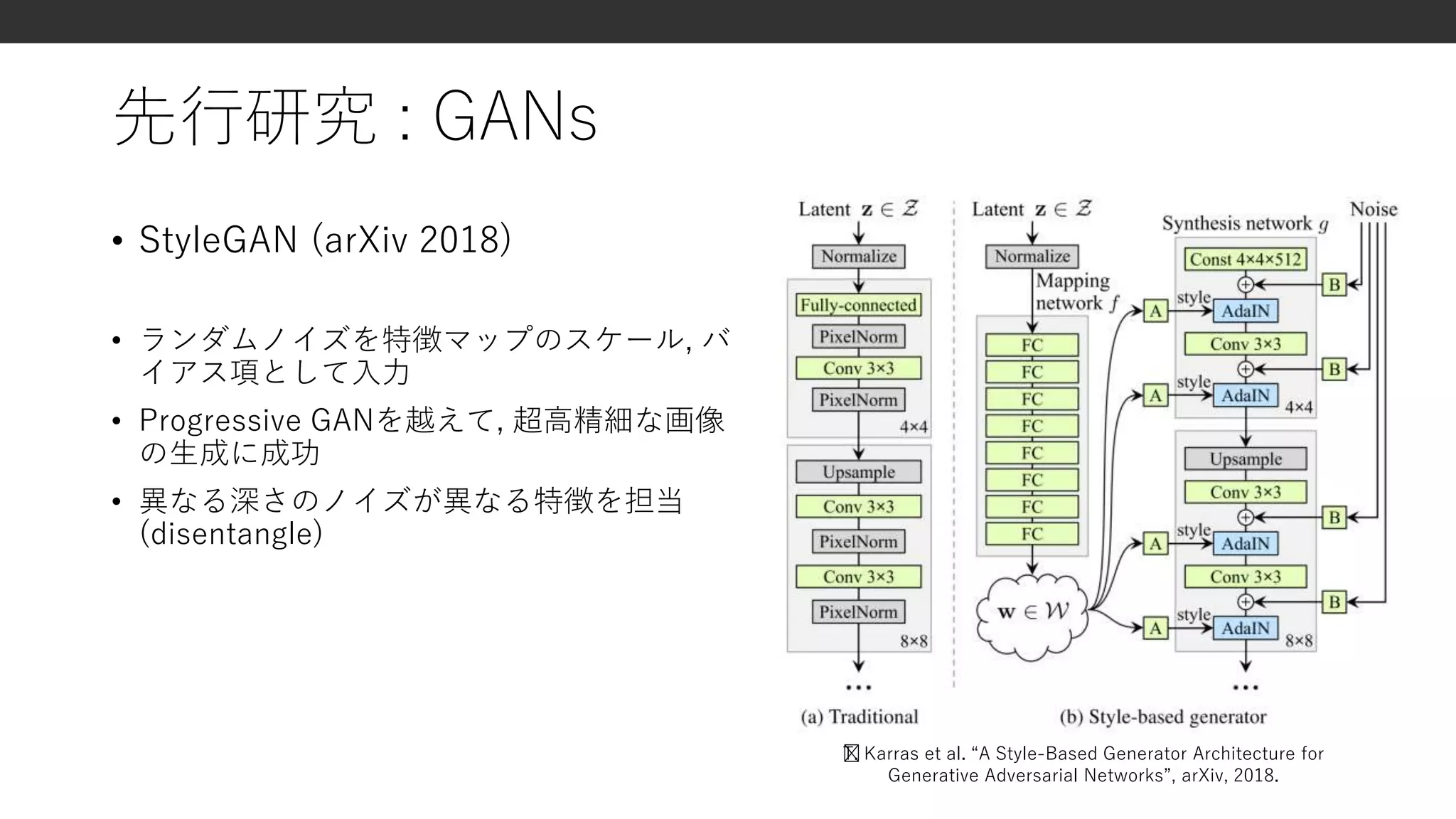
研究背景① : GANs
•できること
• 高精細画像生成 (SAGAN, PGGAN, BigGAN, StyleGANなど)
• 画像変換, 画像編集, motion transfer など
• 苦手なこと
• (conditionalでない) GANで特定の属性を陽に制御すること
• cGANでも, ラベルつきのデータを集めるのは大変
T. Karras et al. “A Style-
Based Generator Architecture
for Generative Adversarial
Networks”, CVPR, 2019.
C. Chan, S. Ginosar, T. Zhou,
and A. A. Efros. Everybody
dance now. arXiv:1808.07371,
2018.
画像生成 motion transfer
9.
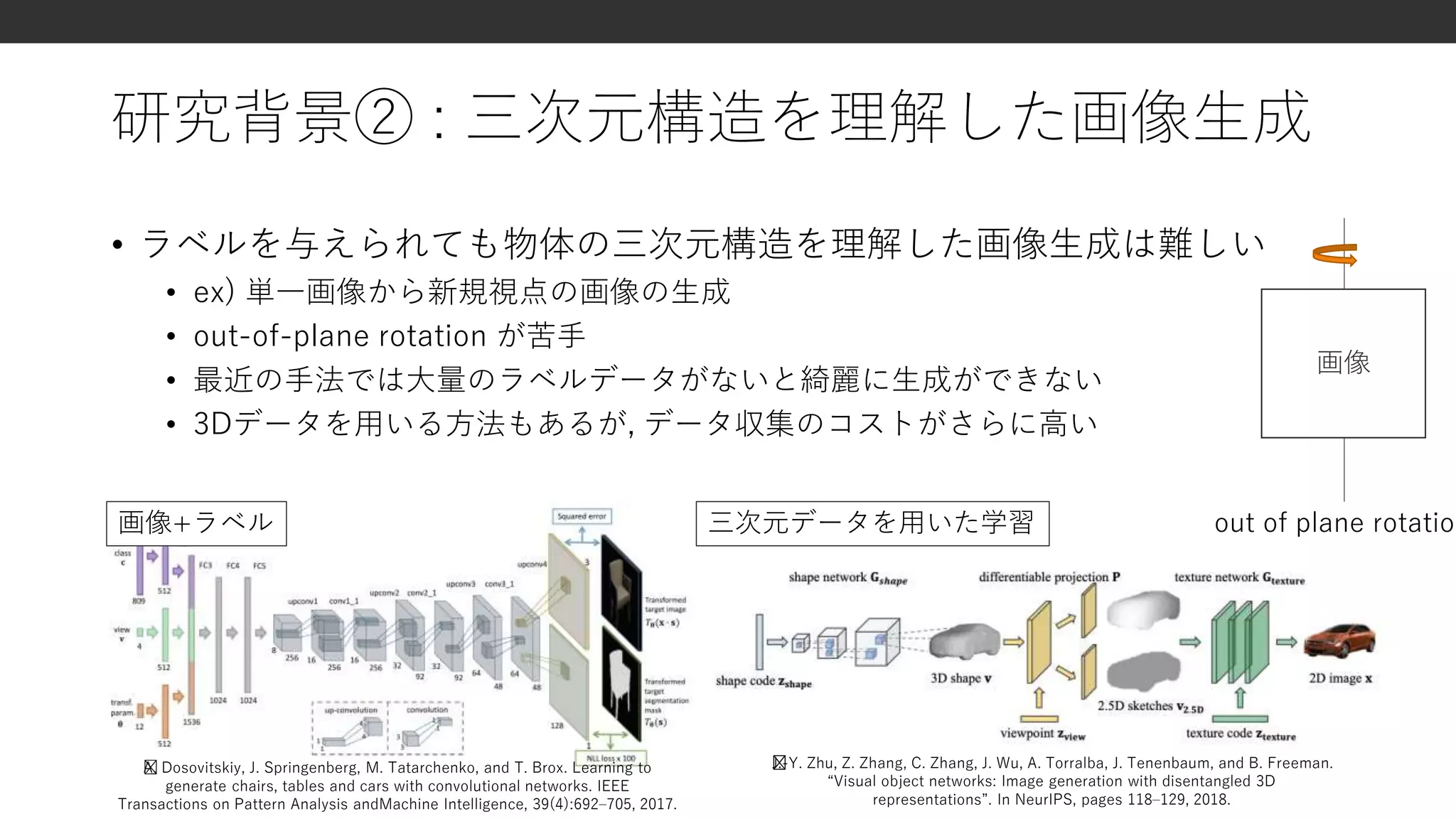
研究背景② : 三次元構造を理解した画像生成
•ラベルを与えられても物体の三次元構造を理解した画像生成は難しい
• ex) 単一画像から新規視点の画像の生成
• out-of-plane rotation が苦手
• 最近の手法では大量のラベルデータがないと綺麗に生成ができない
• 3Dデータを用いる方法もあるが, データ収集のコストがさらに高い
画像
out of plane rotation画像+ラベル
A. Dosovitskiy, J. Springenberg, M. Tatarchenko, and T. Brox. Learning to
generate chairs, tables and cars with convolutional networks. IEEE
Transactions on Pattern Analysis andMachine Intelligence, 39(4):692–705, 2017.
三次元データを用いた学習
J.-Y. Zhu, Z. Zhang, C. Zhang, J. Wu, A. Torralba, J. Tenenbaum, and B. Freeman.
“Visual object networks: Image generation with disentangled 3D
representations”. In NeurIPS, pages 118–129, 2018.
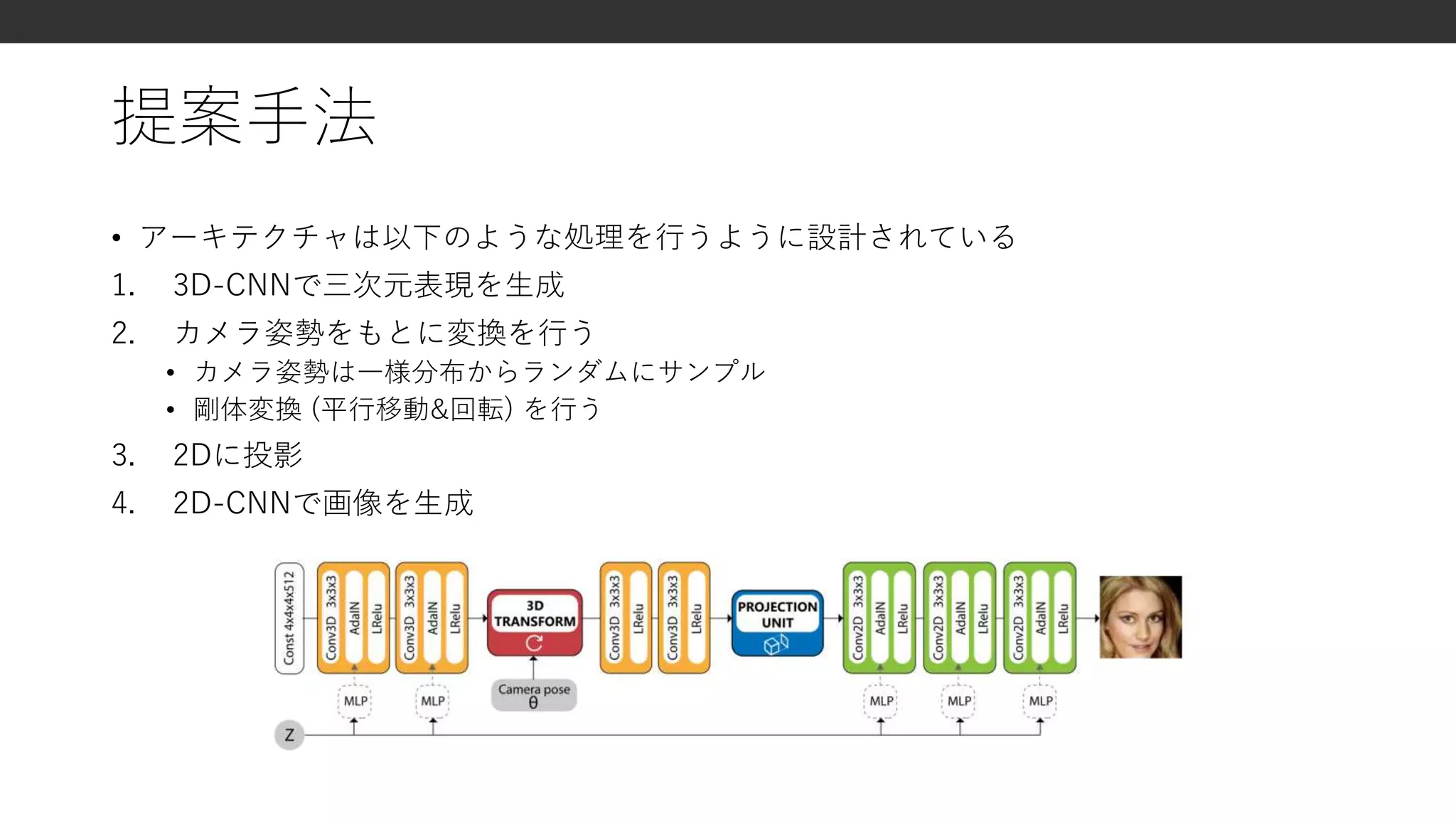
先行研究 : 3Dを考慮した画像生成
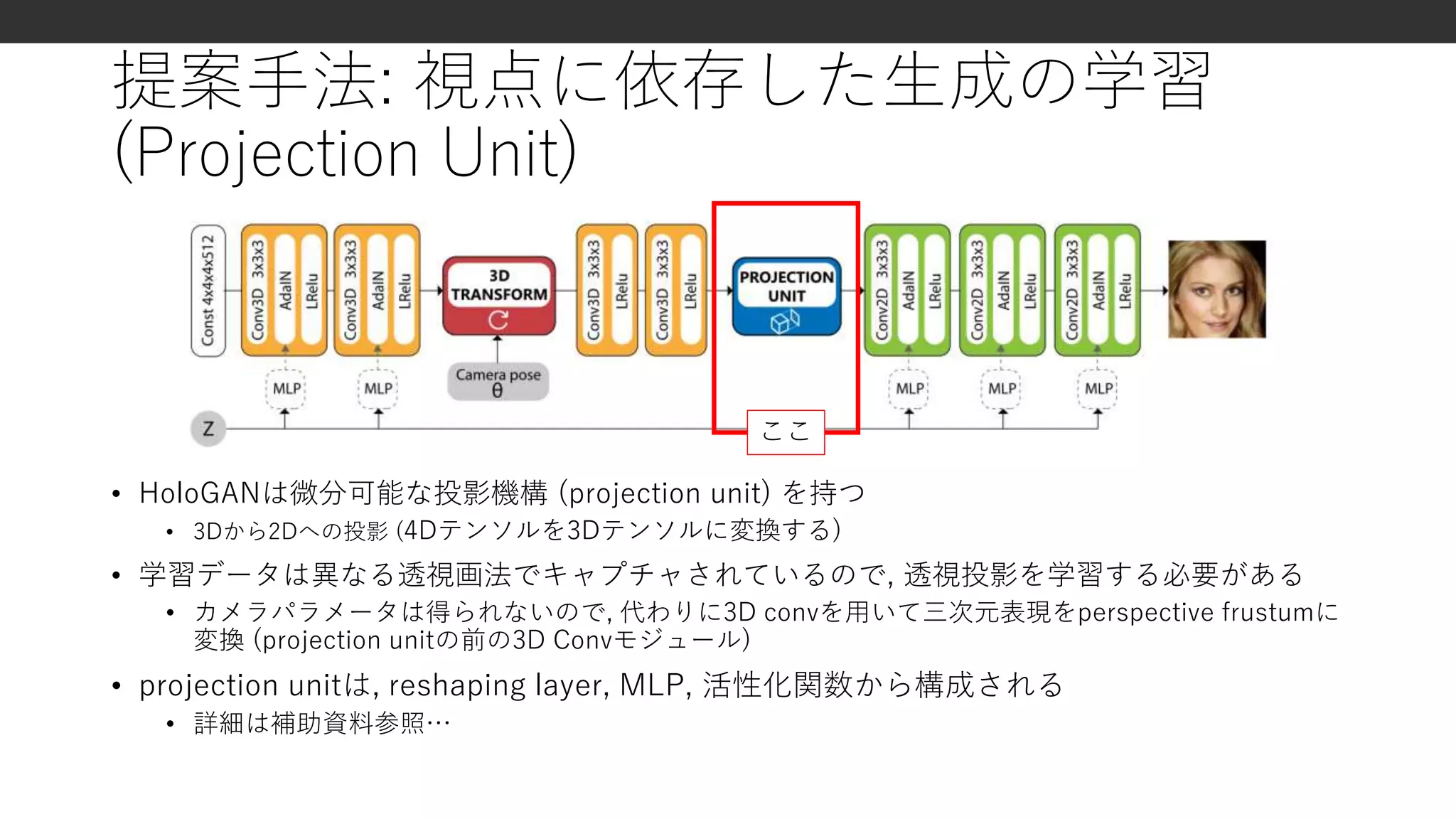
•3Dから2Dへレンダリングする機構 (RenderNet T. H. Nguyen-Phuoc et al.
2019)
× 学習データに3Dデータが必要
• 新しい視点の画像を生成するための三次元の埋め込み表現を獲得する手法
(Rhodin et al. 2018, Sitzmann et al. 2018)
× 入力に複数視点の画像が必要 (Sitzmann et al.)
× 背景のマスクとオブジェクトの姿勢という教師データが必要 (Rhodin et al.)
• 幾何的な情報とテクスチャの情報を分離する手法 (J.-Y. Zhu et al. 2018)
• (1) 3Dオブジェクトを生成, (2) 法線, デプス, シルエットにレンダリング, (3) 画像変換
ネットワークにより, 2D画像に変換
× 学習に3Dデータが必要
× 単一オブジェクトかつ背景が白いデータしか扱えない
16.
先行研究 : 3Dを考慮した画像生成
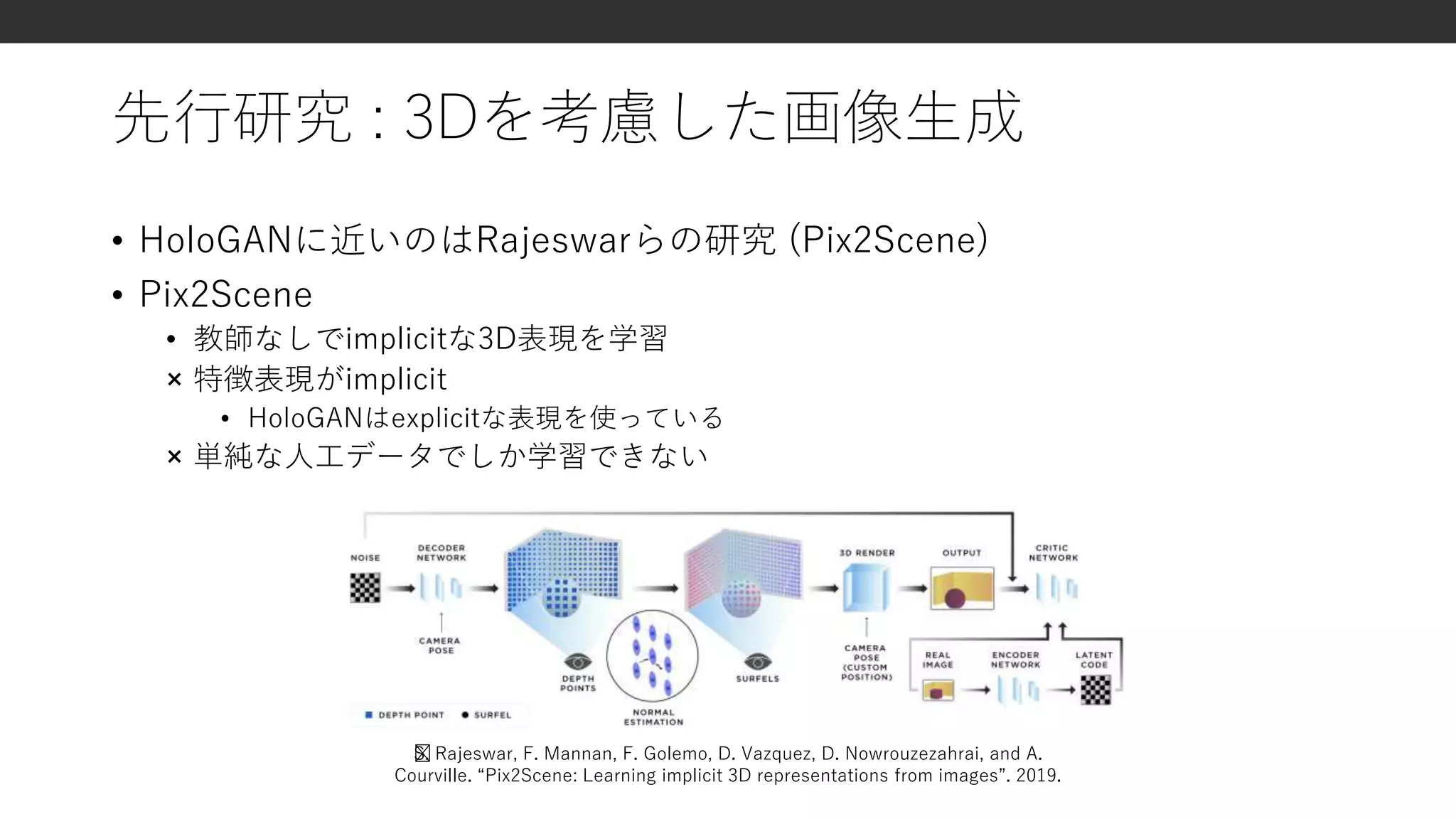
•HoloGANに近いのはRajeswarらの研究 (Pix2Scene)
• Pix2Scene
• 教師なしでimplicitな3D表現を学習
× 特徴表現がimplicit
• HoloGANはexplicitな表現を使っている
× 単純な人工データでしか学習できない
S. Rajeswar, F. Mannan, F. Golemo, D. Vazquez, D. Nowrouzezahrai, and A.
Courville. “Pix2Scene: Learning implicit 3D representations from images”. 2019.
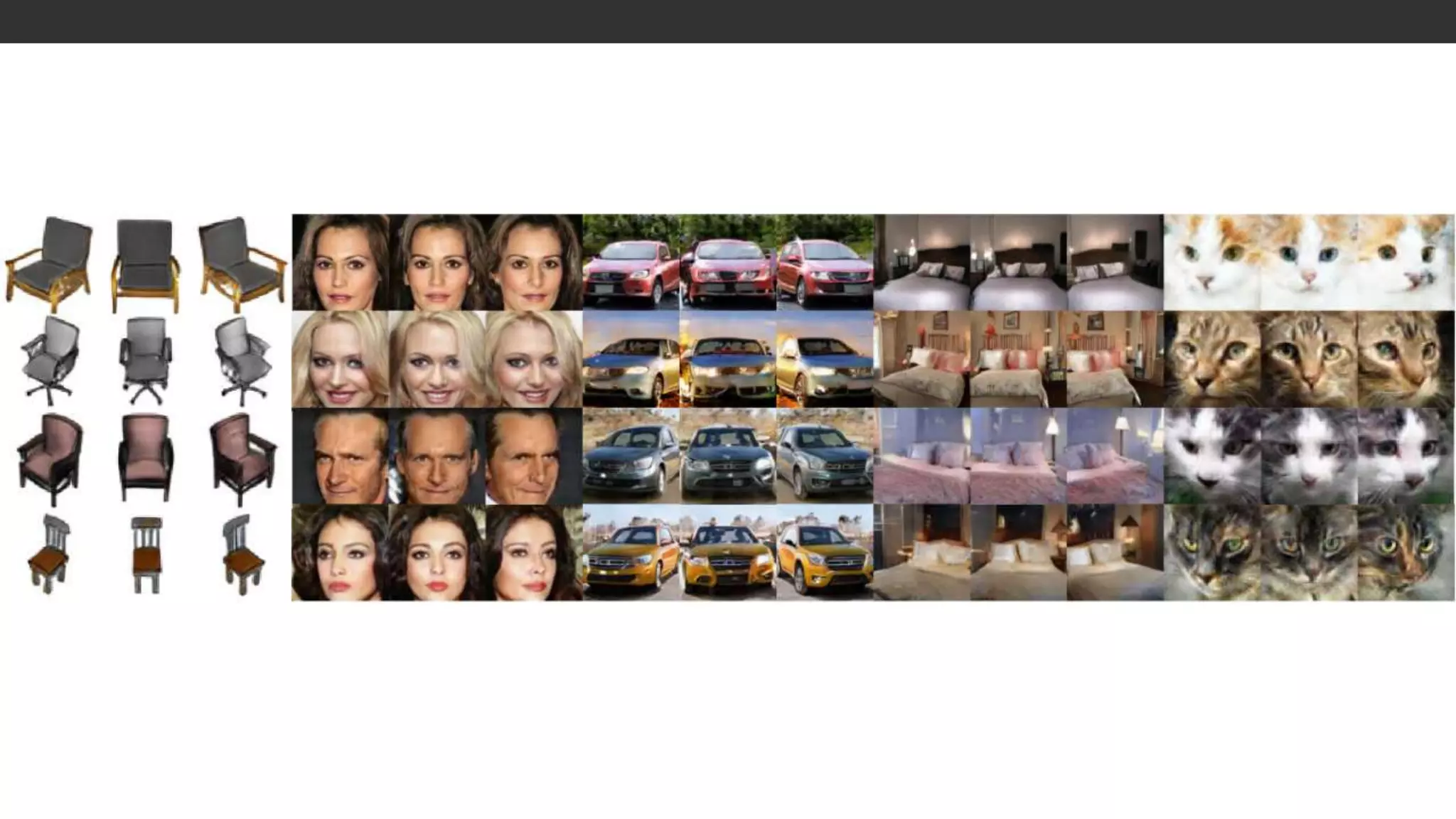
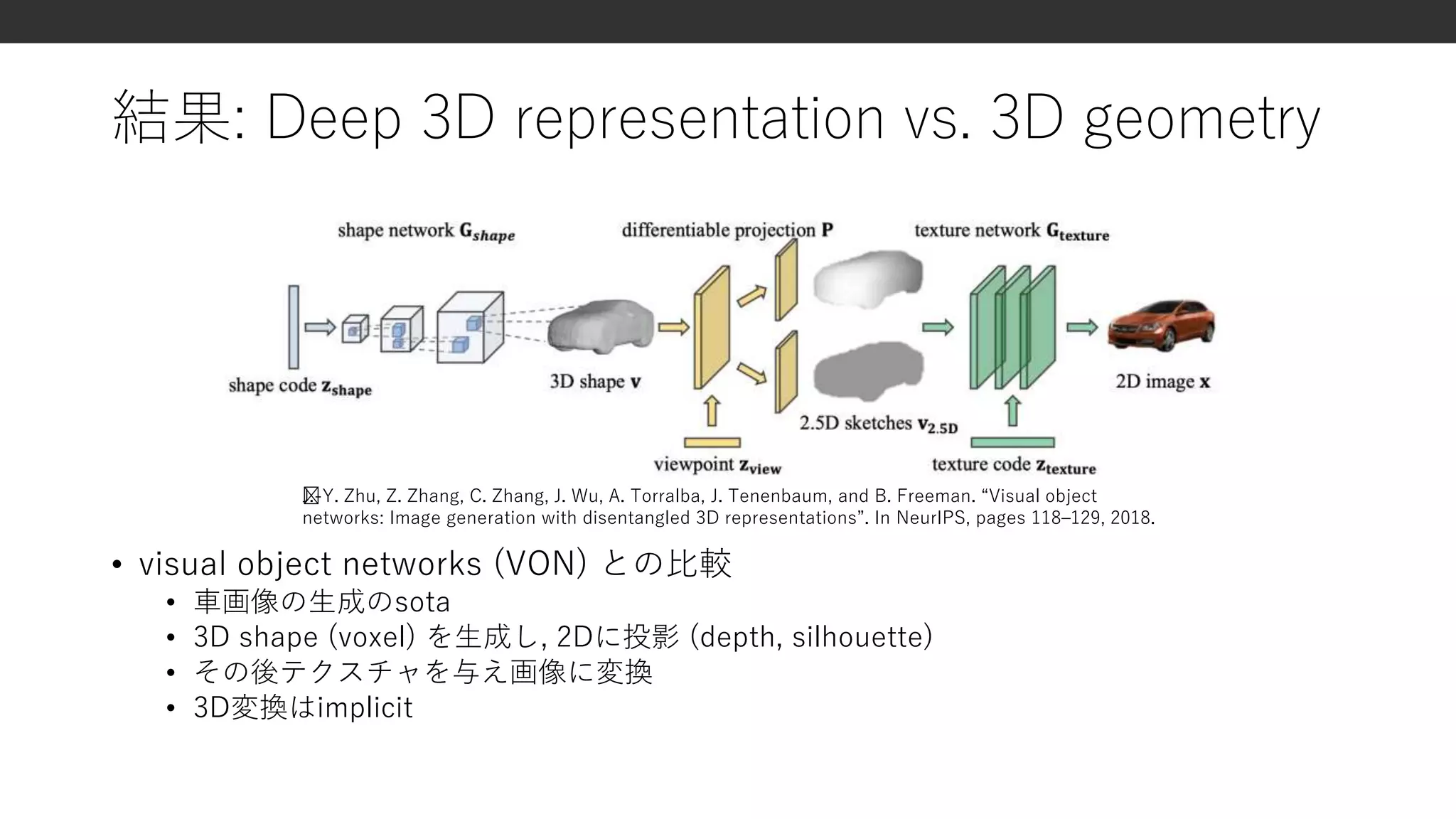
結果: Deep 3Drepresentation vs. 3D geometry
• visual object networks (VON) との比較
• 車画像の生成のsota
• 3D shape (voxel) を生成し, 2Dに投影 (depth, silhouette)
• その後テクスチャを与え画像に変換
• 3D変換はimplicit
J.-Y. Zhu, Z. Zhang, C. Zhang, J. Wu, A. Torralba, J. Tenenbaum, and B. Freeman. “Visual object
networks: Image generation with disentangled 3D representations”. In NeurIPS, pages 118–129, 2018.
31.
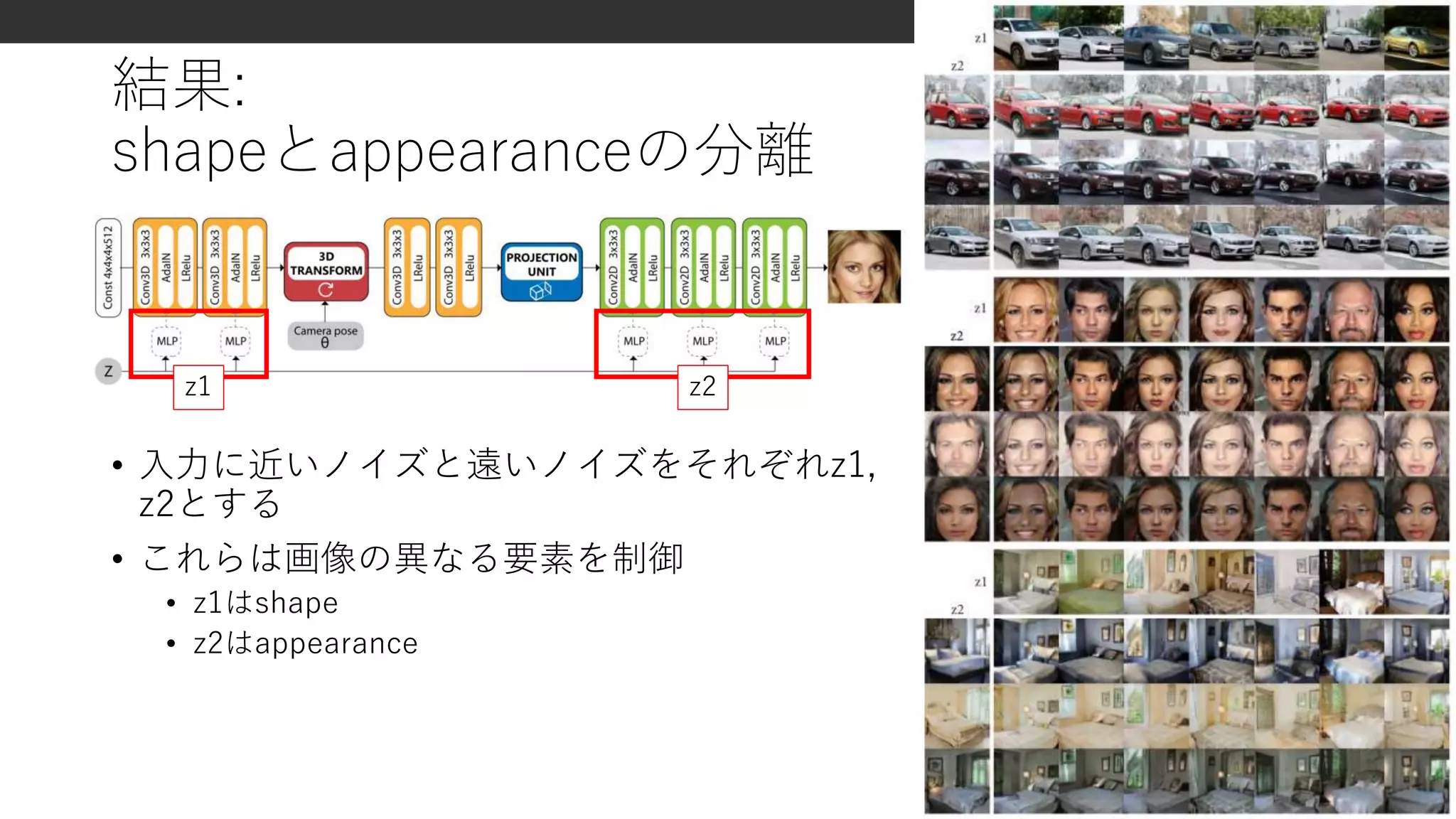
結果: Deep 3Drepresentation vs. 3D geometry
• VON
• 背景がない画像を生成
• 苦手な角度がある
• HoloGAN
• 背景あり
• 滑らかな角度変化
• elevation方向の回転にも対応
参考文献
• T. Phuocet al. “HoloGAN: Unsupervised learning of 3D representations from natural images”,
arXiv, 2019. (project page: https://www.monkeyoverflow.com/#/hologan-unsupervised-
learning-of-3d-representations-from-natural-images/)
• T. Karras et al. “A Style-Based Generator Architecture for Generative Adversarial Networks”,
CVPR, 2019.
• C. Chan, S. Ginosar, T. Zhou, and A. A. Efros. Everybody dance now. arXiv:1808.07371, 2018.
• A. Dosovitskiy, J. Springenberg, M. Tatarchenko, and T. Brox. Learning to generate chairs,
tables and cars with convolutional networks. IEEE Transactions on Pattern Analysis
andMachine Intelligence, 39(4):692–705, 2017.
• J.-Y. Zhu, Z. Zhang, C. Zhang, J. Wu, A. Torralba, J. Tenenbaum, and B. Freeman. “Visual object
networks: Image generation with disentangled 3D representations”. In NeurIPS, pages 118–129,
2018.
38.
参考文献
• H. Katoet al. “Neural 3D Mesh Renderer“, CVPR, 2018.
• S. M. A. Eslami, D. Jimenez Rezende, F. Besse, F. Viola, A. S. Mor- cos,M. Garnelo, A. Ruderman,
A. A. Rusu, I. Danihelka, K. Gregor, D. P. Reichert, L. Buesing, T. Weber, O. Vinyals, D.
Rosenbaum, N. Rabinowitz, H. King, C. Hillier, M. Botvinick, D. Wierstra, K. Kavukcuoglu, and D.
Hassabis. Neural scene representation and rendering. Science, 360(6394):1204–1210, 2018.
• T. Karras et al. “A Style-Based Generator Architecture for Generative Adversarial Networks”,
CVPR, 2019.
• T. Chen et al. “On Self Modulation for Generative Adversarial Networks”, ICLR, 2019.
• T. Phuoc et al. “RenderNet: A deep convolutional network for differentiable rendering from 3D
shapes”, NeurIPS, 2018.
• H. Rhodin, M. Salzmann, and P. Fua. “Unsupervised geometry-aware representation for 3D
human pose estimation”. In ECCV, 2018
39.
参考文献
• V. Sitzmann,J. Thies, F. Heide, M. Nießner, G. Wetzstein, and M. Zollhöfer. “DeepVoxels:
Learning persistent 3D feature embeddings”. arXiv:1812.01024, 2018.
• S. Rajeswar, F. Mannan, F. Golemo, D. Vazquez, D. Nowrouzezahrai, and A. Courville.
“Pix2Scene: Learning implicit 3D representations from images”. 2019.
• I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner.
β-VAE: Learning basic visual concepts with a constrained variational framework. In ICLR, 2017.
• X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel. InfoGAN: Interpretable
representation learning by information maximizing generative adversarial nets. In NIPS, pages
2172–2180, 2016.
• L. Tran et al. Disentangled Representation Learning GAN for Pose-Invariant Face Recognition.
CVPR 2017.







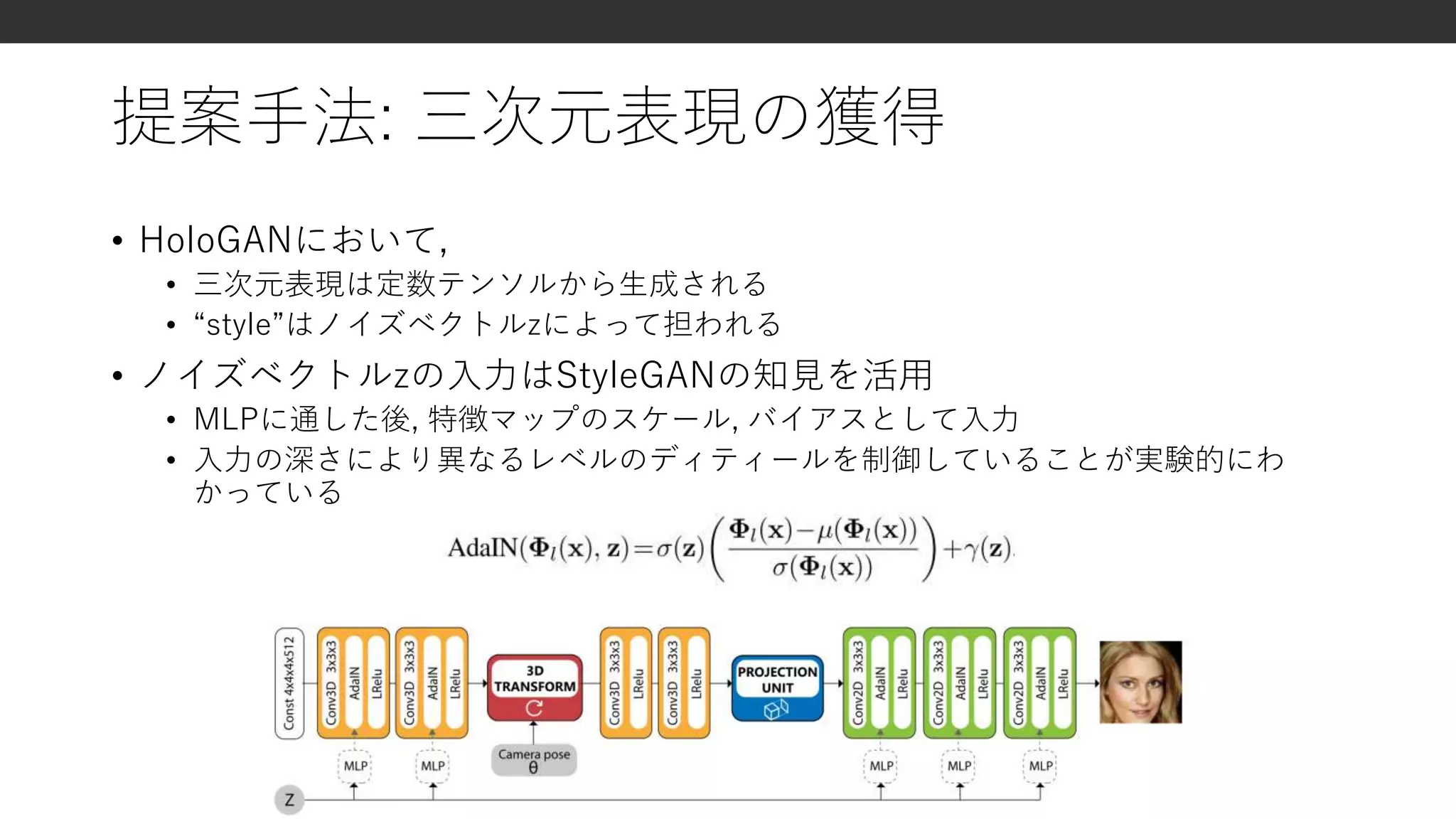
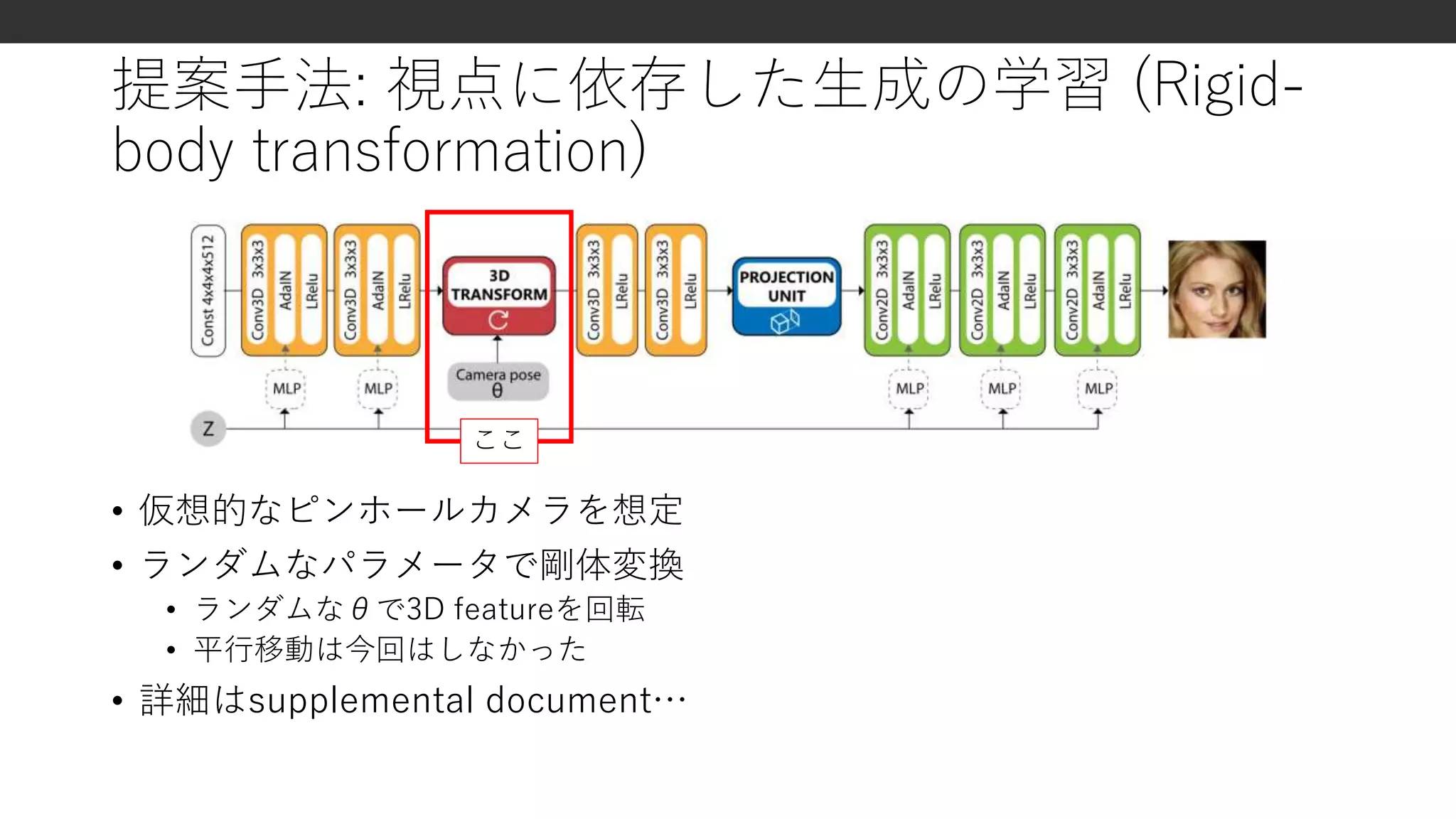
![三次元データの表現方法
explicitな三次元表現
• ボクセル, メッシュなど
剛体変換などの操作が容易
× メモリを効率悪い
× 離散化の方法が非自明
implicitな三次元表現
• 潜在表現ベクトルなど
空間的にコンパクト
表現力が高い
× 陽な変換が難しい
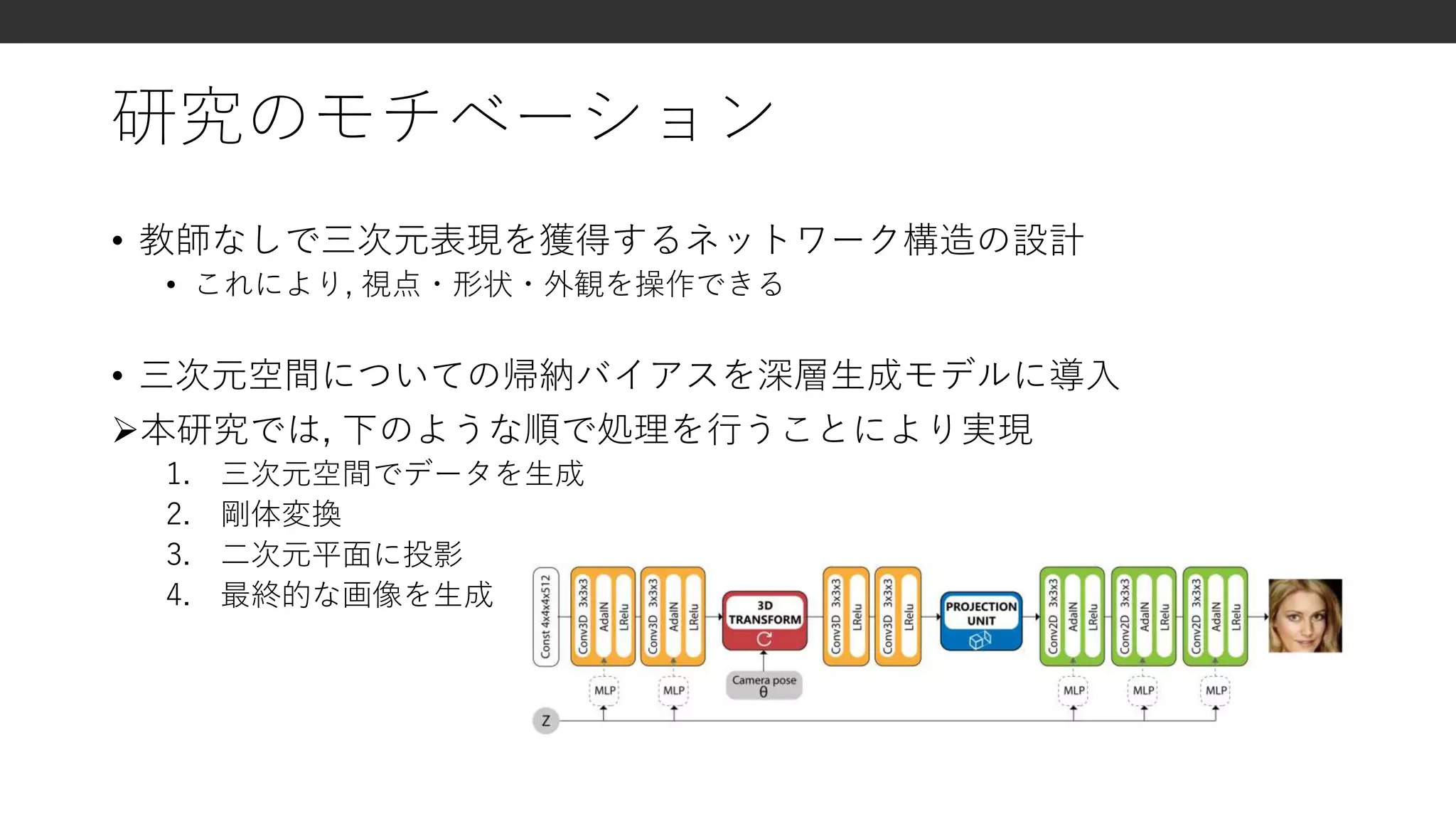
HoloGAN
• 提案手法
明示的な変換ができる
表現力も高い
画像のみから学習可能
H. Kato et al. “Neural 3D Mesh Renderer“, CVPR, 2018. [YouTube] Generative Query Networks](https://image.slidesharecdn.com/hologanslideshare-190830151411/75/HoloGAN-Unsupervised-Learning-of-3D-Representations-from-Natural-Images-11-2048.jpg)





















![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Human Pose Estimation @ ECCV2018](https://cdn.slidesharecdn.com/ss_thumbnails/180928dlseminarposeestimationeccv2018-180928031032-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]3D Human Pose Estimation @ CVPR’19 / ICCV’19](https://cdn.slidesharecdn.com/ss_thumbnails/190816dlseminar3dhpe-190816032821-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]BANMo: Building Animatable 3D Neural Models from Many Casual Videos](https://cdn.slidesharecdn.com/ss_thumbnails/banmo-220225035310-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]GENESIS: Generative Scene Inference and Sampling with Object-Centric L...](https://cdn.slidesharecdn.com/ss_thumbnails/20191206genesis-191206004127-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]EG3D: Efficient Geometry-aware 3D Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/eg3defficientgeometry-aware3dgenerativeadversarialnetworks-211224040111-thumbnail.jpg?width=640&height=640&fit=bounds)





![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)






