Downloaded 84 times

















![P(θ|D,m) KL q(θ)
ELBO
1.
⇤
= argmin KL(q(✓; ) || p(✓ | D))
= argmin Eq(✓; )[logq(✓; ) p(✓ | D)]
ELBO( ) = Eq(✓; )[p(✓, D) logq(✓; )]
⇤
= argmax ELBO( )
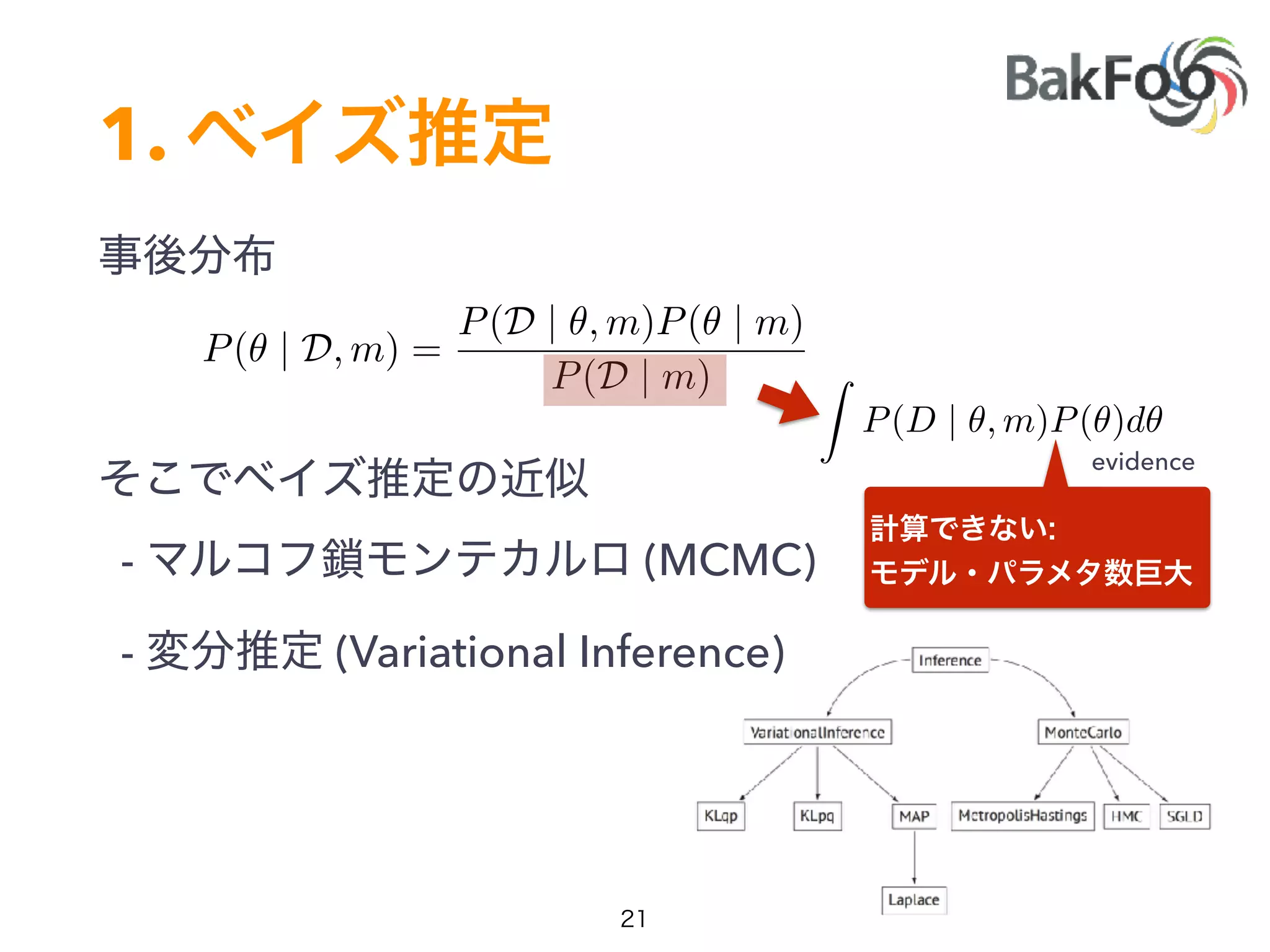
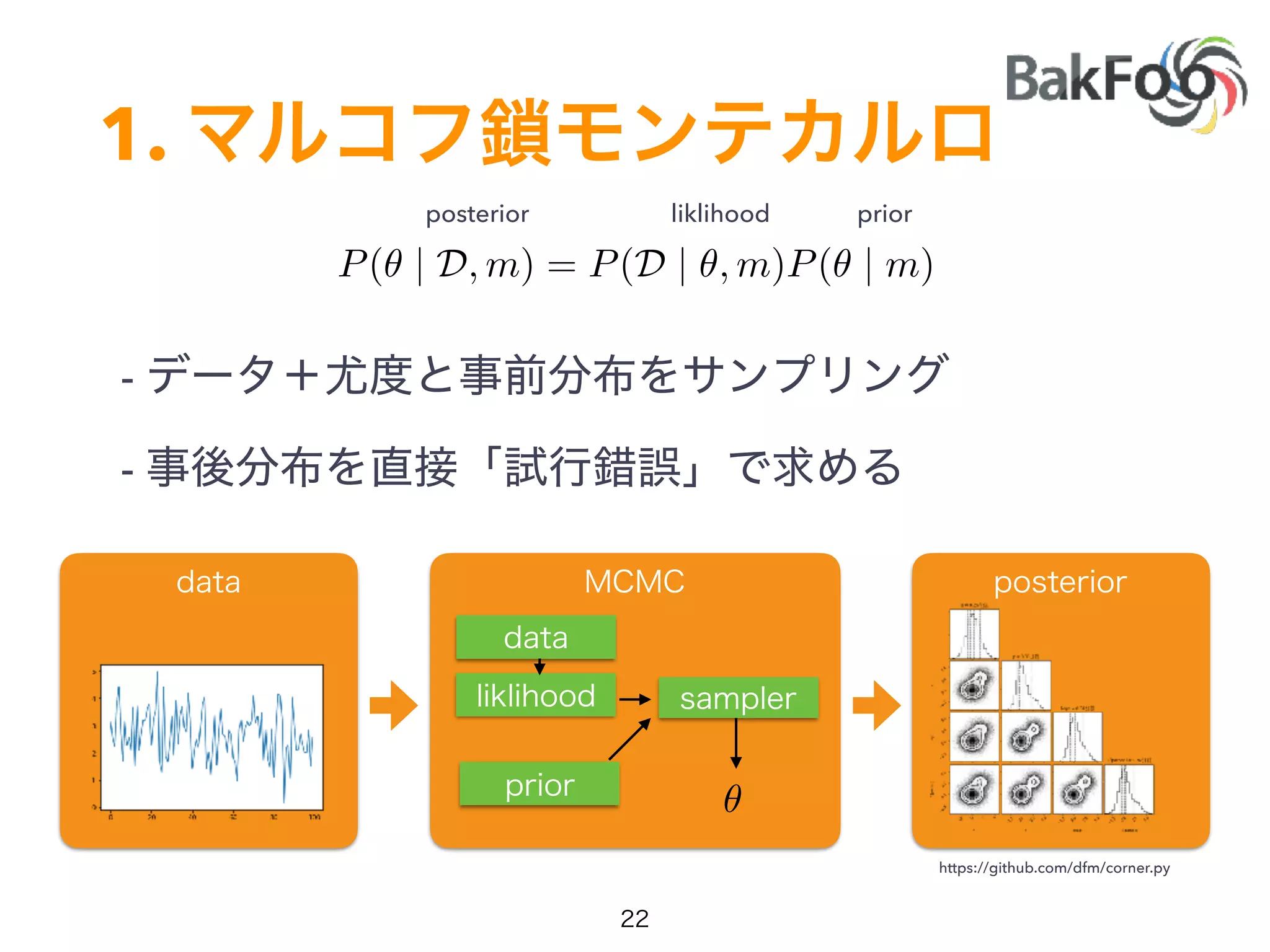
P(✓ | D, m) =
P(D | ✓, m)P(✓ | m)
P(D | m)](https://image.slidesharecdn.com/pycon2017-170909063215/75/Pycon2017-25-2048.jpg)
![1.
- KL =ELBO
- P q
q(✓; 1)
q(✓; 5)
p(✓, D) p(✓, D)
✓✓
⇤
= argmax ELBO( )
ELBO( ) = Eq(✓; )[p(✓, D) logq(✓; )]](https://image.slidesharecdn.com/pycon2017-170909063215/75/Pycon2017-26-2048.jpg)





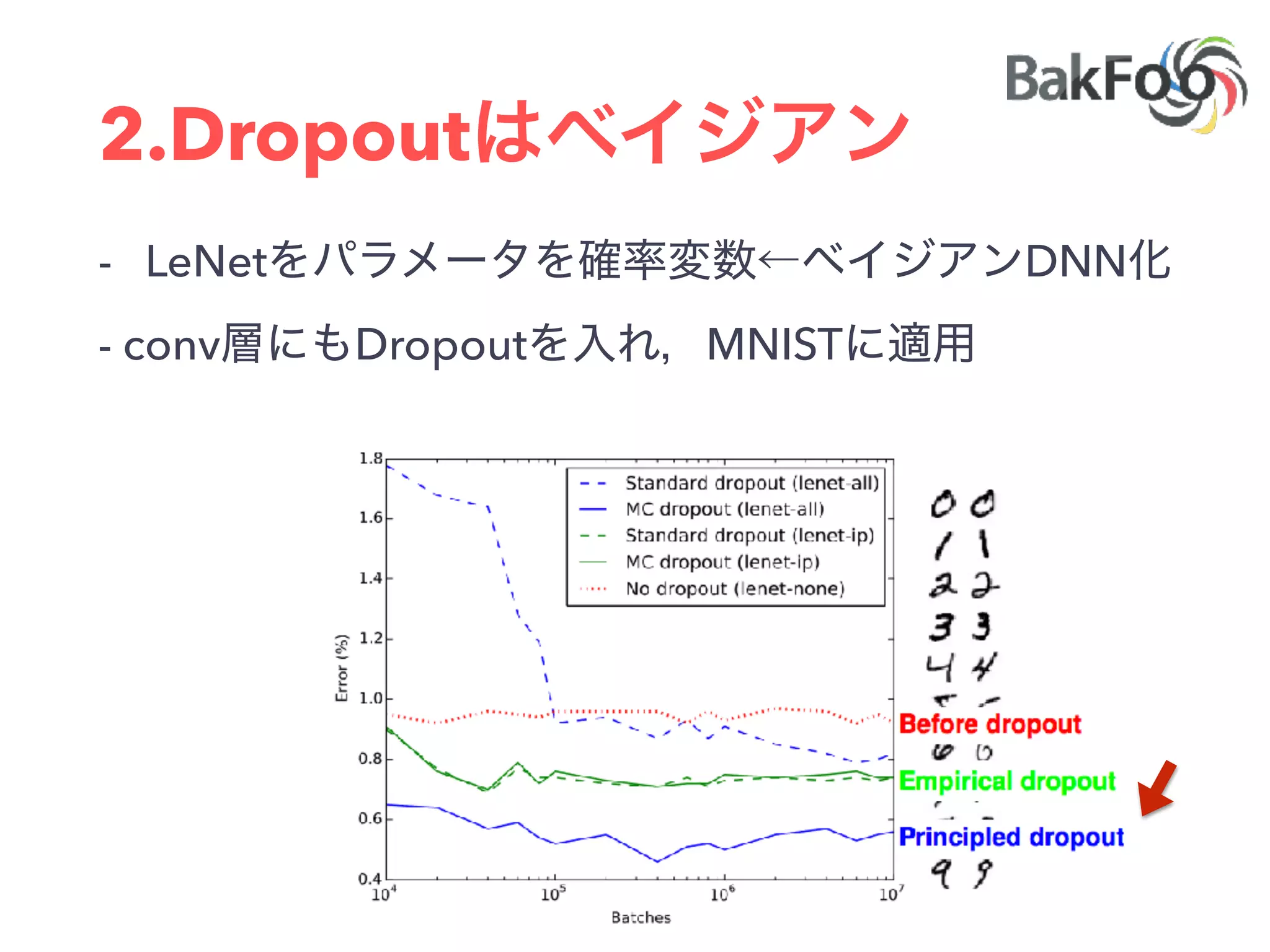

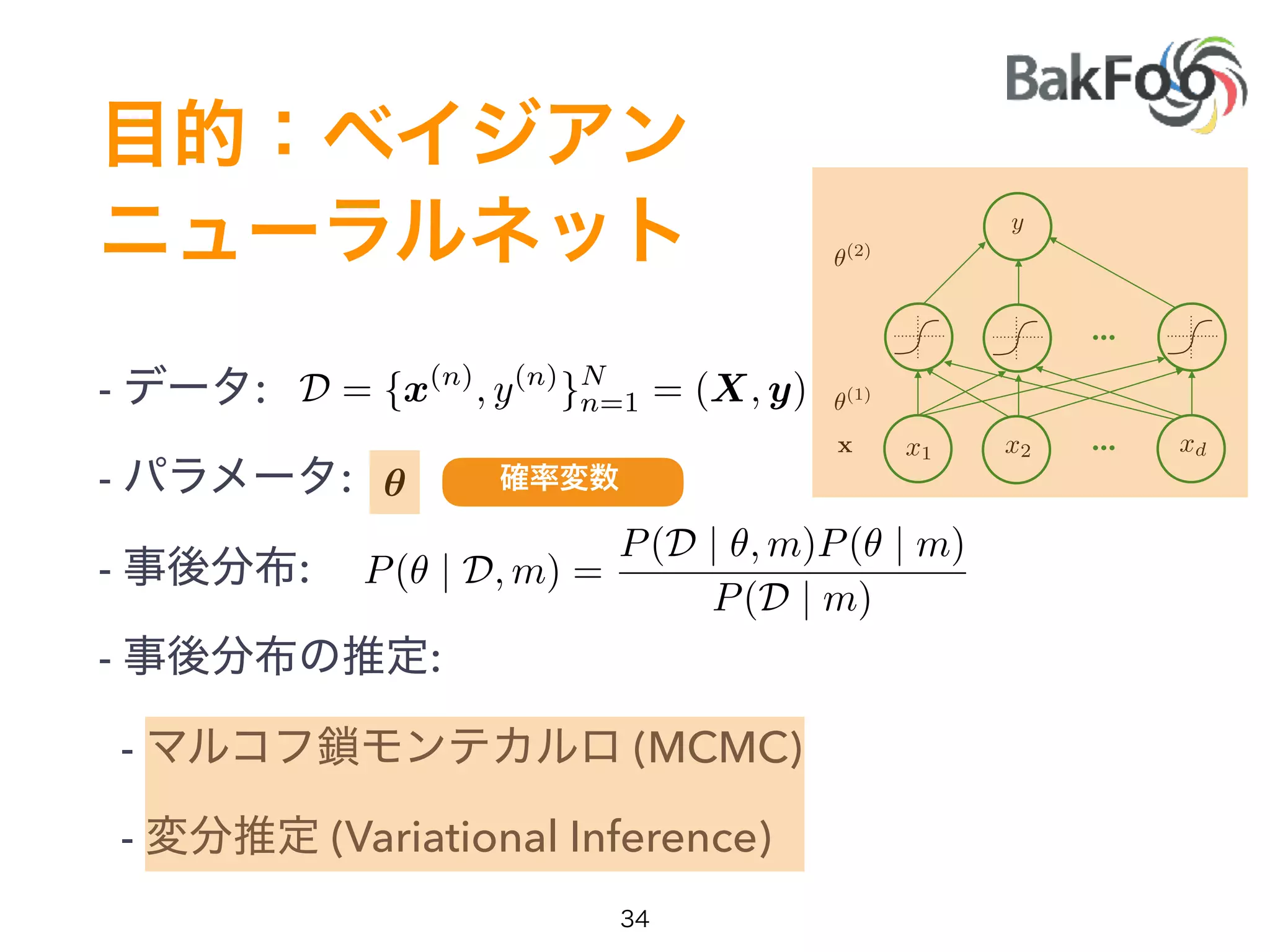




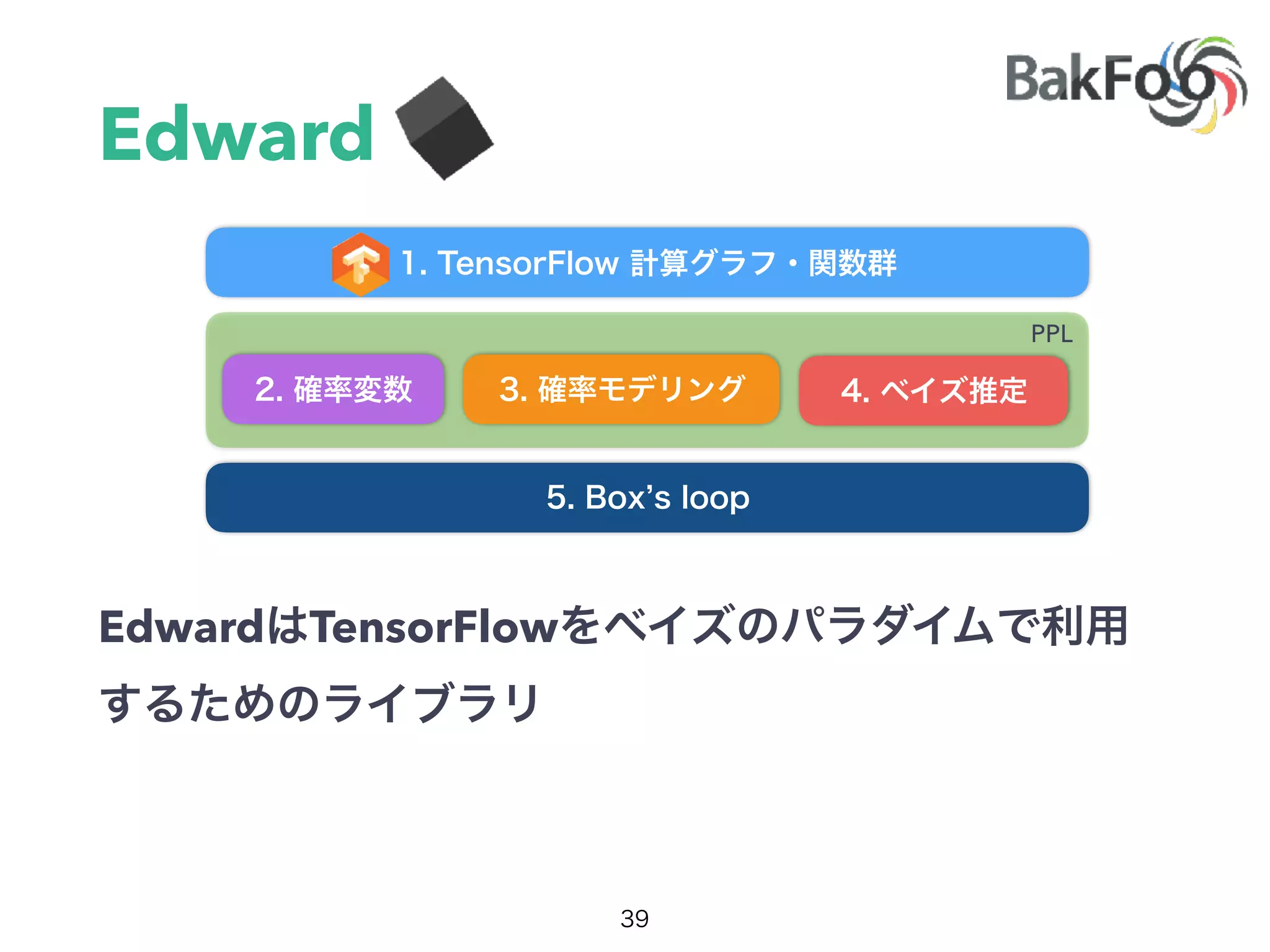


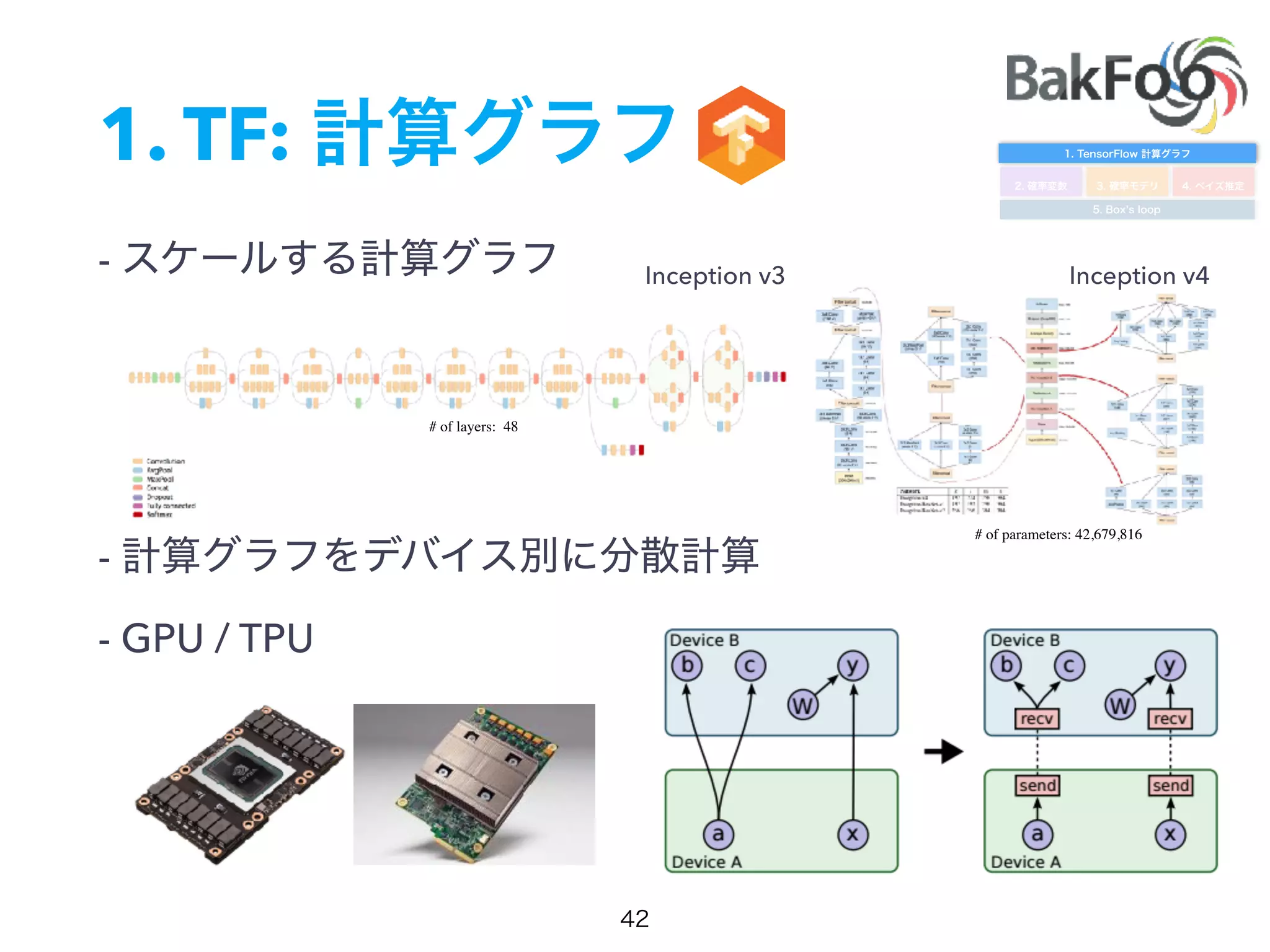



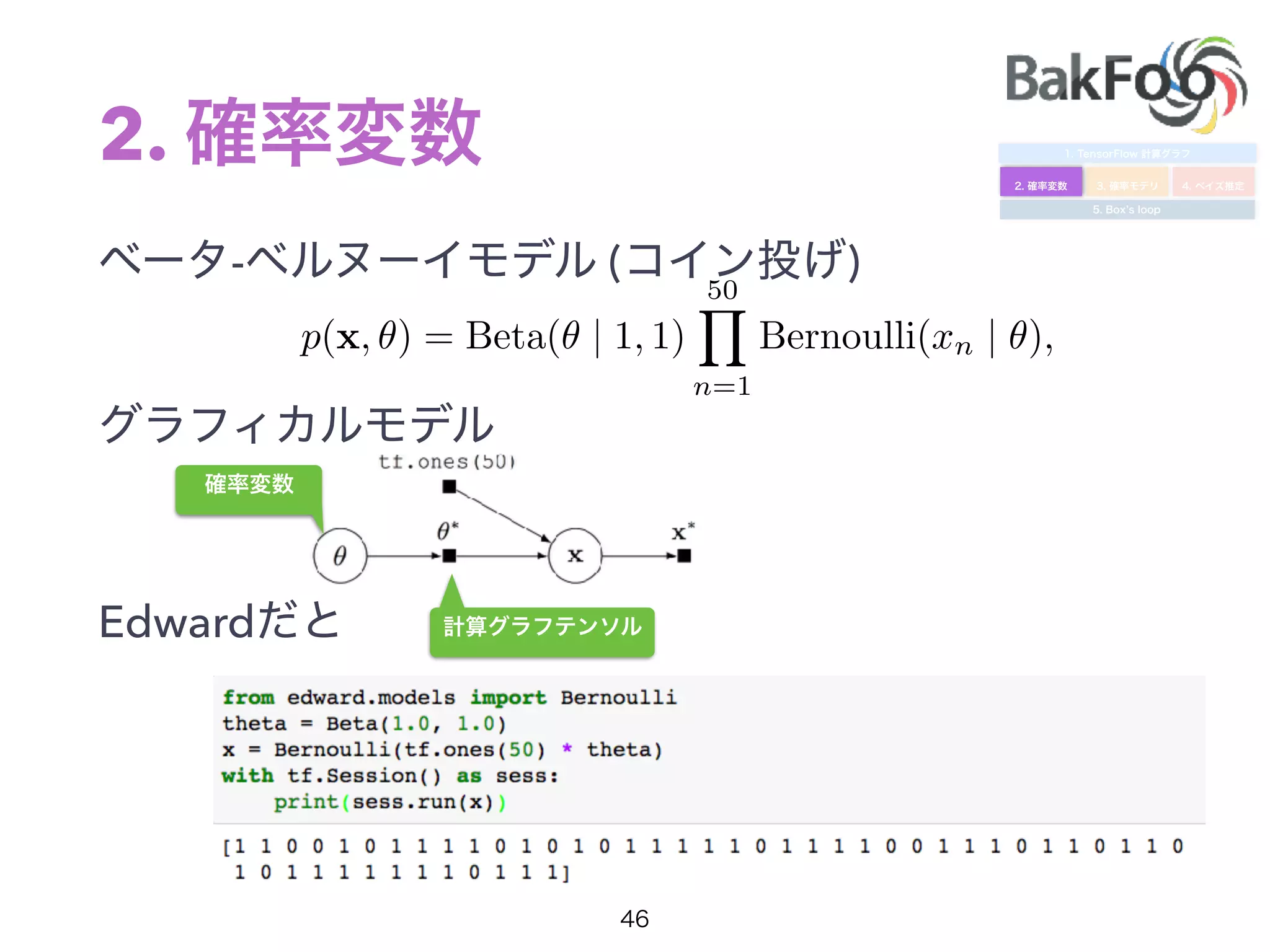

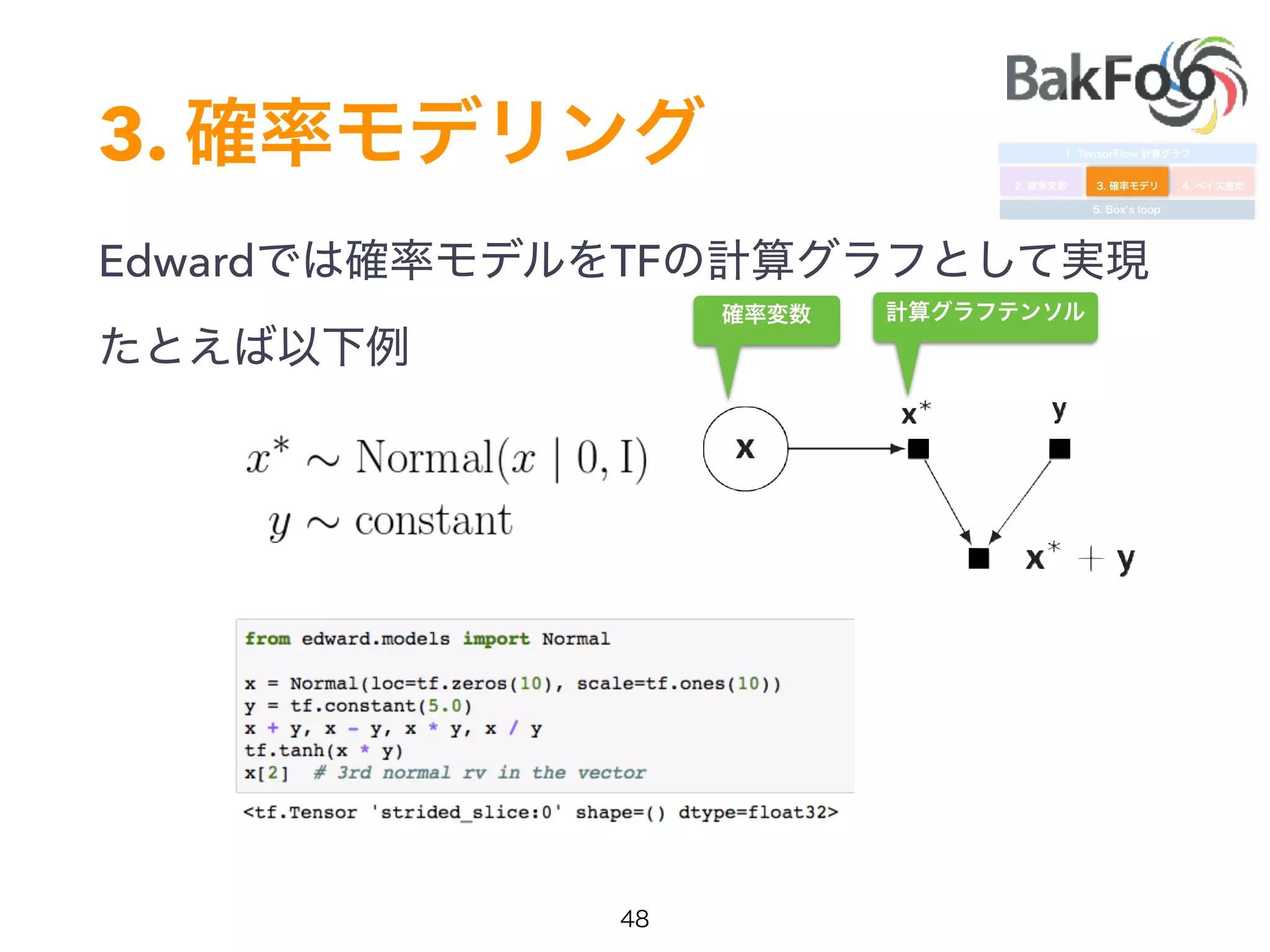


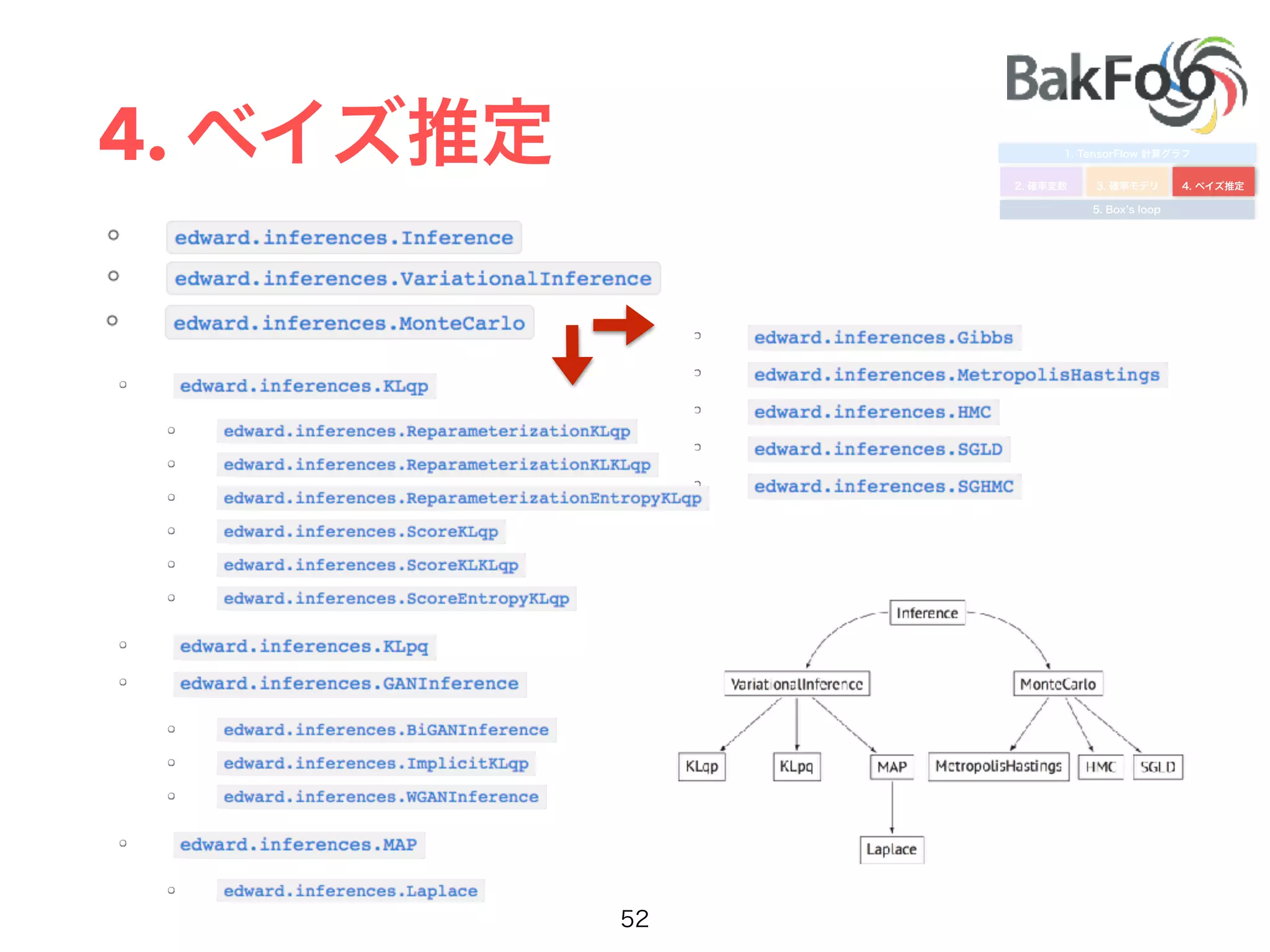














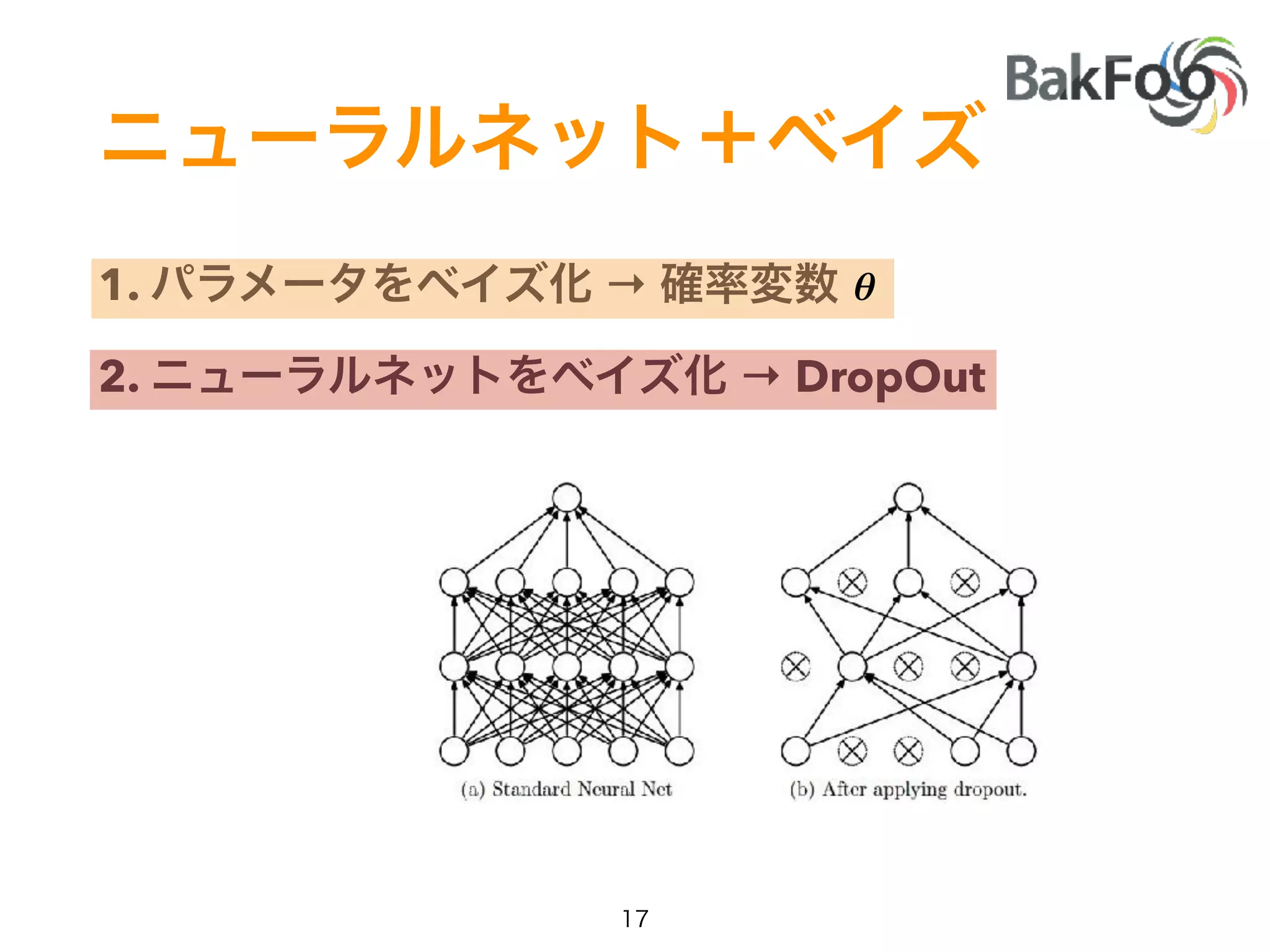
1. Yuta Kashino presented on Edward, a probabilistic programming library built on TensorFlow. Edward allows defining probabilistic models and performing Bayesian inference using techniques like MCMC and variational inference. 2. Dropout was discussed as a way to approximate Bayesian neural networks and model uncertainty in deep learning. Adding dropout to networks can help prevent overfitting. 3. Edward examples were shown using TensorFlow for defining probabilistic models like Bayesian linear regression and hidden Markov models. Models can be easily defined and inference performed.















































![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)

















































