Download to read offline


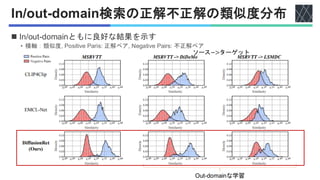
![関連研究:テキスト・ビデオ検索タスク
◼ CLIP4Clip [Luo+, Neurocomputing 2022]
• テキスト・画像の事前学習モデル
CLIP [Radford+, ICML2021]のビデオへの拡張
◼ EMCL-Net [Jin+, NeurIPS2022]
• テキストとビデオの間の差を縮めて向上
• Expectation-Maximization Contrastive Learning (EMCL)
◼ HBI [Jin+, CVPR2023]
• 同著者.テキスト・ビデオ間の関連度の学習を
多変数 協力ゲーム理論によってモデル化.
すべて識別的モデル](https://image.slidesharecdn.com/20251125diffusionret-251127090614-e4ce7c4e/85/DiffusionRet-Generative-Text-Video-Retrieval-with-Diffusion-Model-3-320.jpg)


![Text-Frame Attention Encoder
CLIP [Radford+, ICML2021]
ViT [Dosovitskiy+, ICLR2021]
◼ テキストと動画情報を混ぜ合わせる
◼ テキスト:Text representation 𝐶𝑡
• CLIP [Radford+, ICML2021] (ViT-B/32)の
[CLS]トークン
◼ ビデオ:Video representation 𝐶𝑣
1. 動画から均等に1フレームを抽出
2. ViT [Dosovitskiy+, ICLR2021]でエンコード
• フレームシークエンスをエンコード
• フレームと[CLS]トークンを適応
• フレーム埋め込みを得る
3. 4層Transformerで集約
• 全フレームの特徴量を集約
• Frame representation 𝐹 を得る
4. Attention (QKVモデル) へ入力
• Query: Text representation 𝐶𝑡
• Key/Value: Frame representation 𝐹
𝜏: ハイパーパラメーター
小さいほど、視覚的特徴が集約されるときに
より多くのテキスト情報を入れ込むことができる.
𝐶𝑣 = Softmax 𝐶𝑡𝐹𝑇
/τ′ 𝐹
𝐶𝑣
𝐶𝑡](https://image.slidesharecdn.com/20251125diffusionret-251127090614-e4ce7c4e/85/DiffusionRet-Generative-Text-Video-Retrieval-with-Diffusion-Model-9-320.jpg)

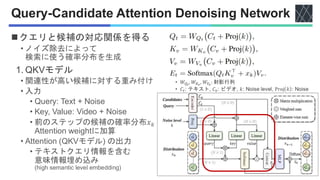
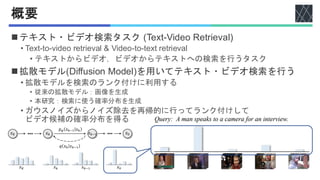
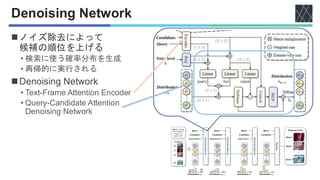
![Query-Candidate Attention Denoising Network
◼クエリと候補の対応関係を得る
2. ノイズ除去 (Denoising) MLP
• 出力分布を計算するための
Relu活性化関数の線形層を含む
• 入力:[𝐶𝑣, 𝐸𝑡] ∈ 𝑅𝑁×2𝐷
• 出力:確率分布
3. Skip connection
• 前ステップの確率分布の情報を
保持するためと考えられる
QKVモデルに対して
テキストとビデオを入れ替える
• Text-to-video retrieval
• Video-to-text retrieval
𝐶𝑣
𝐶𝑡
𝐸𝑡
𝐶𝑣](https://image.slidesharecdn.com/20251125diffusionret-251127090614-e4ce7c4e/85/DiffusionRet-Generative-Text-Video-Retrieval-with-Diffusion-Model-12-320.jpg)

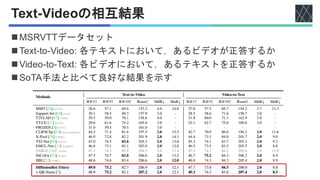
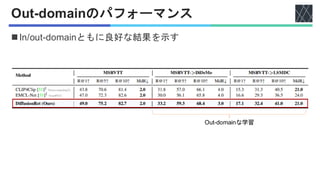
![実験設定
◼データセット
• MSRVTT [Jun+, CVPR2016]
• YouTube動画のそれぞれに20個のテキストが1万本.
• 9,000本の動画を訓練用に、1,000本をテスト用.
• LSMDC [Anna+, CVPR2015]
• 映画202本からビデオクリップ約12万本.
• テスト用に1,000本の動画を使用.
• MSVD [Lin+, ACL2011]
• 1,970本のビデオ.
• 訓練用1,200本,テスト用670本.
• ActivityNet Caption [Krishna+, ICCV2017]
• YouTube動画2万本が収録
• 訓練用約1万本,テスト用約5,000本.
• DiDeMo [Hendricks+, ICCV2017]
• 約1万本の動画.
ワード長32
フレーム数12
ワード長64
フレーム数64](https://image.slidesharecdn.com/20251125diffusionret-251127090614-e4ce7c4e/85/DiffusionRet-Generative-Text-Video-Retrieval-with-Diffusion-Model-14-320.jpg)
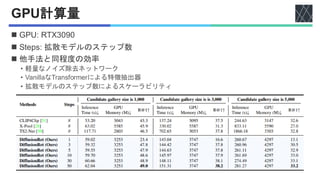
![実験設定
Adam [P. Kingma, arXiv2017]
CLIP [Radford+, ICML2021]
QB-Norm [Bogolin+, CVPR2022]
◼ Batch size: 128
◼ Adam [P. Kingma, arXiv2017] optimizer
◼ 事前学習済みモデル
• CLIP [Radford+, ICML2021] (ViT-B/32), 512次元の特徴量
◼ Initial learning rate
• Text encoder & video encoder: 1e-7
• 他: 1e-3
◼ Temperature: 𝜏 = 0.01, 𝜏′
= 1
◼ QB-Norm [Bogolin+, CVPR2022]: Querybank Normalisation
◼ 評価指標
• R@K↑
• Recall at k : 上位k個に含まれる正解の数 / 正解データの総数
• Rsum↑
• R@1, R@5, R@10の合計
• MdR↓, MnR↓
• Median Rank, Mean Rank:正解カテゴリの予測スコア順位の中央値, 平均](https://image.slidesharecdn.com/20251125diffusionret-251127090614-e4ce7c4e/85/DiffusionRet-Generative-Text-Video-Retrieval-with-Diffusion-Model-15-320.jpg)

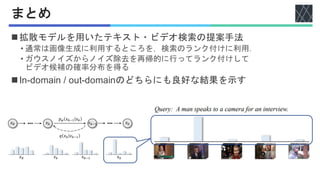

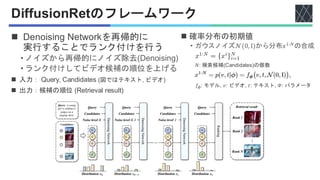
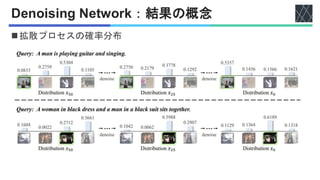
Peng Jin, Hao Li, Zesen Cheng, Kehan Li, Xiangyang Ji, Chang Liu, Li Yuan, Jie Chen, "DiffusionRet: Generative Text-Video Retrieval with Diffusion Model", ICCV2023 https://openaccess.thecvf.com/content/ICCV2023/html/Jin_DiffusionRet_Generative_Text-Video_Retrieval_with_Diffusion_Model_ICCV_2023_paper.html
![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)






















![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)





















