Recommended
PDF
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
PDF
PDF
BlackBox モデルの説明性・解釈性技術の実装
PPTX
[DL輪読会]When Does Label Smoothing Help?
PDF
PDF
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
PDF
PDF
PDF
PDF
Transformerを多層にする際の勾配消失問題と解決法について
PPTX
[研究室論文紹介用スライド] Adversarial Contrastive Estimation
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
PPTX
[DL輪読会]Dense Captioning分野のまとめ
PDF
PDF
PDF
【メタサーベイ】Video Transformer
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
PDF
PPTX
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
PDF
PPTX
PDF
PPTX
PDF
PDF
PDF
More Related Content
PDF
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
PDF
PDF
BlackBox モデルの説明性・解釈性技術の実装
PPTX
[DL輪読会]When Does Label Smoothing Help?
PDF
PDF
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
What's hot
PDF
PDF
PDF
PDF
Transformerを多層にする際の勾配消失問題と解決法について
PPTX
[研究室論文紹介用スライド] Adversarial Contrastive Estimation
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
PPTX
[DL輪読会]Dense Captioning分野のまとめ
PDF
PDF
PDF
【メタサーベイ】Video Transformer
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
PDF
PPTX
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
PDF
PPTX
PDF
PPTX
PDF
Viewers also liked
PDF
PDF
PPTX
NIPS2015読み会: Ladder Networks
PDF
PPTX
猫でも分かるVariational AutoEncoder
PDF
PPTX
PPTX
Clause Anaphora Resolution for Japanese Demonstrative Determiner based on Sem...
PDF
PPTX
Why 40? なぜ40個のサンプルで調査をするのか ― 数値例からの考察
PPTX
PPTX
[DL輪読会]Wavenet a generative model for raw audio
PDF
PPTX
有名論文から学ぶディープラーニング 2016.03.25
PPTX
PPTX
crossnoteの機械学習で文章から作者を判別する
PPTX
crossnoteの機械学習でWikipediaの記事を分類する
PPTX
crossnoteの機械学習でパブリックコメントを分類する
PDF
PPT
Similar to 論文紹介 Semi-supervised Learning with Deep Generative Models
PDF
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
PPTX
Semi supervised, weakly-supervised, unsupervised, and active learning
PDF
PDF
[DL輪読会]10分で10本の論⽂をざっくりと理解する (ICML2020)
PDF
Semi-supervised Active Learning Survey
PPTX
Active Learning と Bayesian Neural Network
PDF
Journal club dec24 2015 splice site prediction using artificial neural netw...
PDF
Deep learning for acoustic modeling in parametric speech generation
PPTX
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
PPTX
[DL輪読会]Meta-Learning Probabilistic Inference for Prediction
PPTX
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
PDF
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
PPTX
「解説資料」Set Transformer: A Framework for Attention-based Permutation-Invariant ...
PPTX
Paper reading - Dropout as a Bayesian Approximation: Representing Model Uncer...
PDF
[DL輪読会]Regularization with stochastic transformations and perturbations for d...
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
More from Seiya Tokui
PDF
Chainer/CuPy v5 and Future (Japanese)
PPTX
PDF
Chainer v2 and future dev plan
PDF
PDF
Learning stochastic neural networks with Chainer
PDF
深層学習フレームワーク Chainer の開発と今後の展開
PDF
論文紹介 Pixel Recurrent Neural Networks
PDF
PDF
Chainer Update v1.8.0 -> v1.10.0+
PDF
Differences of Deep Learning Frameworks
PDF
Overview of Chainer and Its Features
PDF
Chainer Development Plan 2015/12
PDF
PDF
PDF
PDF
論文紹介 Compressing Neural Networks with the Hashing Trick
PDF
深層学習フレームワークChainerの紹介とFPGAへの期待
PDF
Introduction to Chainer: A Flexible Framework for Deep Learning
PDF
Recurrent Neural Networks
PDF
論文紹介 Semi-supervised Learning with Deep Generative Models 1. 2. 3. 従来⼿手法:⼤大きく 4 種類
3
⾃自⼰己教⽰示による学習
• 学習した予測器を使ってラベルなし
データをラベル付けする
• ⼤大マージンの仮説を⼊入れることもあ
る(Transductive SVM)
グラフベースの⼿手法
• データの類似度度グラフを作り,ラベ
ルを伝播させる
• ⼤大概、グラフラプラシアンの固有値
問題に落落ちる
多様体学習による⼿手法
• 予測がデータ多様体に沿ってゆっ
くり変化する制約や正則化を使う
• データ多様体の推定にラベルなし
データが使える
• 例例:Manifold Tangent Classifier
(MTC), AtlasRBF
⽣生成モデルを⽤用いた⼿手法
• ⽣生成モデルを学習する
• 単に特徴学習に使うか,ラベルなし
データを不不完全データとして扱う
今⽇日はこれ
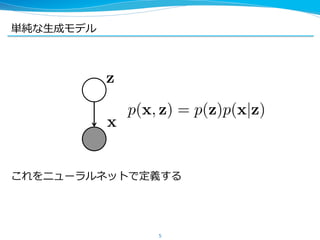
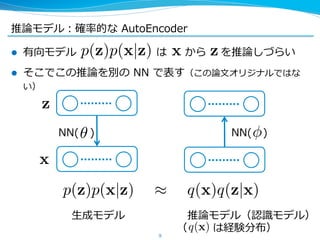
4. 5. 6. 7. 8. 9. 推論論モデル:確率率率的な AutoEncoder
l 有向モデル は から を推論論しづらい
l そこでこの推論論を別の NN で表す(この論論⽂文オリジナルではな
い)
9
p(z)p(x|z) x z
p(z)p(x|z) q(x)q(z|x)
z
x
NN( ) NN( )
⽣生成モデル 推論論モデル(認識識モデル)
( は経験分布)q(x)
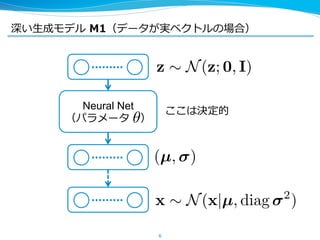
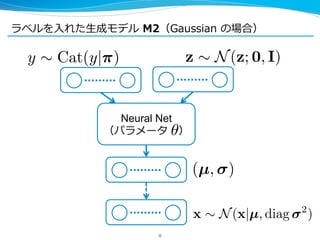
10. 推論論モデルも NN で書く
10
l M1(⼊入⼒力力データの⽣生成モデル)の場合,
l M2(ラベルを⽤用いた⽣生成モデル)の場合,
q (z|x) = N(z|µ (x), diag 2
(x)).
NN
NN
q (z|y, x) = N(z|µ (y, x), diag 2
(y, x)),
q (y|x) = Cat(y| (x)).
11. M1 の⽬目的関数:変分下界(変分 AutoEncoder)
11
log p(x) Eq(z|x)[log p(x|z)] KL[q(z|x) p(z)]
これを最⼤大化する
( のとき左辺と⼀一致)q(x, z) = p(x, z)
半教師あり学習に使う場合, を特徴ベクトル
としてこれを使って識識別器を(半)教師あり学習する(例例えば
TSVM や M2)
z q(z|x)
AutoEncoder に関する正則化項z
12. M2 の⽬目的関数:変分下界+識識別学習
12
ラベルありデータに対しては
ラベルなしデータに対しては
これらとラベルありデータに対する損失を合わせて次の関数を最⼩小化する
log p(x, y) L(x, y) :=
Eq(z|x,y)[log p(x|y, z) + log p(y) + log p(z) log q(z|x, y)]
log p(x) U(x) :=
Eq(y,z|x)[log p(x|y, z) + log p(y) + log p(z) log q(y, z|x)]
(x,y):labeled
L(x, y) +
x:unlabaled
U(x)
(x,y):labeled
log q(y|x)
q(y|x)ここに の項が
⼊入ってない
13. 勾配の計算法:SGVB (SBP)
l ⽬目的関数を略略記:
l 勾配を計算する上で が厄介
l これは Gaussian に関する期待値なので
と書き直せて、勾配をサンプリングで近似できる:
⽣生成・推論論モデルの変分下界の勾配を求めるこの⽅方法は Stochastic
Gradient Variational Bayes や Stochastic BackProp と呼ばれる
(それぞれ ICLRʼ’14, ICMLʼ’14 で独⽴立立に提案されたが,基本的には同じ⼿手
法をさす)
13
Eq(z|x,y)
Eq(z|x,y)[f(x, y, z)]
Eq(z|x,y)[f(x, y, z)] = EN ( |0,I)[f(x, y, µ(x) + (x) )]
Eq(z|x,y)[f(x, y, z)] = EN ( |0,I)[ f(x, y, µ(x) + (x) )]
14. 学習⽅方法:SGVB(SBP) + 勾配法
l 勾配が計算できたので,あとは確率率率的勾配法に投げれば OK
l 論論⽂文では AdaGrad やモーメンタムつきの RMSprop を
使っている,とある
– 3.2 には前者を,4.4 には後者を使ったよと書いてありよくわ
からないが,4.4 の⽅方が詳しく書かれているのでおそらく後
者を使っているのではないかと思う
14
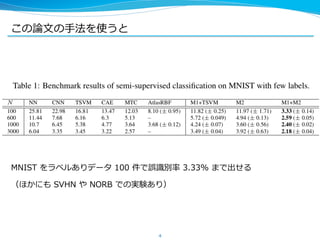
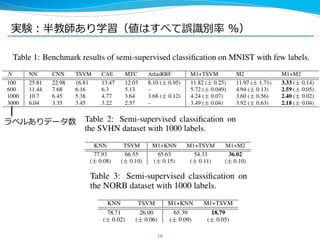
15. 実験:2 種類、⽚片⽅方はその中でさらに 2 種類
l 半教師あり学習 (MNIST, SVHN, NORB)
l 条件つきデータ⽣生成:2 通りの実験
– 2 次元の を使って学習し,ラベル を固定して様々な
から を⽣生成する (MNIST)
– テストデータ から を推論論し,それを使って様々なラ
ベル で を再⽣生成する (MNIST, SVHN)
15
z zy
x|y, z
y x|y, z
x z|x
16. 17. 18. 19. 20. 参考⽂文献
紹介した論論⽂文
Kingma, D. P., Mohamed, S., Jimenez Rezende, D., & Welling, M. (2014).
Semi-supervised Learning with Deep Generative Models. In Advances in Neural Information
Processing Systems 27 (pp. 3581–3589).
Stochastic Gradient VB(変分 AutoEncoder) の論論⽂文
Kingma, D. P., & Welling, M. (2014). Auto-Encoding Variational Bayes.International
Conference on Learning Representations.
Stochastic BackProp の論論⽂文
Rezende, D. J., Mohamed, S., & Wierstra, D. (2014).
Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In
Proceedings of the 31st International Conference on Machine Learning (pp. 1278–1286).
20





![M1 の⽬目的関数:変分下界(変分 AutoEncoder)
11
log p(x) Eq(z|x)[log p(x|z)] KL[q(z|x) p(z)]
これを最⼤大化する
( のとき左辺と⼀一致)q(x, z) = p(x, z)
半教師あり学習に使う場合, を特徴ベクトル
としてこれを使って識識別器を(半)教師あり学習する(例例えば
TSVM や M2)
z q(z|x)
AutoEncoder に関する正則化項z](https://image.slidesharecdn.com/nips2014yomi-ssl-150120004113-conversion-gate02/85/Semi-supervised-Learning-with-Deep-Generative-Models-11-320.jpg)
![M2 の⽬目的関数:変分下界+識識別学習
12
ラベルありデータに対しては
ラベルなしデータに対しては
これらとラベルありデータに対する損失を合わせて次の関数を最⼩小化する
log p(x, y) L(x, y) :=
Eq(z|x,y)[log p(x|y, z) + log p(y) + log p(z) log q(z|x, y)]
log p(x) U(x) :=
Eq(y,z|x)[log p(x|y, z) + log p(y) + log p(z) log q(y, z|x)]
(x,y):labeled
L(x, y) +
x:unlabaled
U(x)
(x,y):labeled
log q(y|x)
q(y|x)ここに の項が
⼊入ってない](https://image.slidesharecdn.com/nips2014yomi-ssl-150120004113-conversion-gate02/85/Semi-supervised-Learning-with-Deep-Generative-Models-12-320.jpg)
![勾配の計算法:SGVB (SBP)
l ⽬目的関数を略略記:
l 勾配を計算する上で が厄介
l これは Gaussian に関する期待値なので
と書き直せて、勾配をサンプリングで近似できる:
⽣生成・推論論モデルの変分下界の勾配を求めるこの⽅方法は Stochastic
Gradient Variational Bayes や Stochastic BackProp と呼ばれる
(それぞれ ICLRʼ’14, ICMLʼ’14 で独⽴立立に提案されたが,基本的には同じ⼿手
法をさす)
13
Eq(z|x,y)
Eq(z|x,y)[f(x, y, z)]
Eq(z|x,y)[f(x, y, z)] = EN ( |0,I)[f(x, y, µ(x) + (x) )]
Eq(z|x,y)[f(x, y, z)] = EN ( |0,I)[ f(x, y, µ(x) + (x) )]](https://image.slidesharecdn.com/nips2014yomi-ssl-150120004113-conversion-gate02/85/Semi-supervised-Learning-with-Deep-Generative-Models-13-320.jpg)











![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)







![[研究室論文紹介用スライド] Adversarial Contrastive Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/acepub-181119101425-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Wavenet a generative model for raw audio](https://cdn.slidesharecdn.com/ss_thumbnails/wavenetagenerativemodelforrawaudio-160920054055-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]10分で10本の論⽂をざっくりと理解する (ICML2020)](https://cdn.slidesharecdn.com/ss_thumbnails/20200828-ant-200828025358-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Regularization with stochastic transformations and perturbations for d...](https://cdn.slidesharecdn.com/ss_thumbnails/regularizationwithstochastictransformationsandperturbationsfordeepsemi-supervisedlearning-170215034444-thumbnail.jpg?width=640&height=640&fit=bounds)



















