Downloaded 194 times




























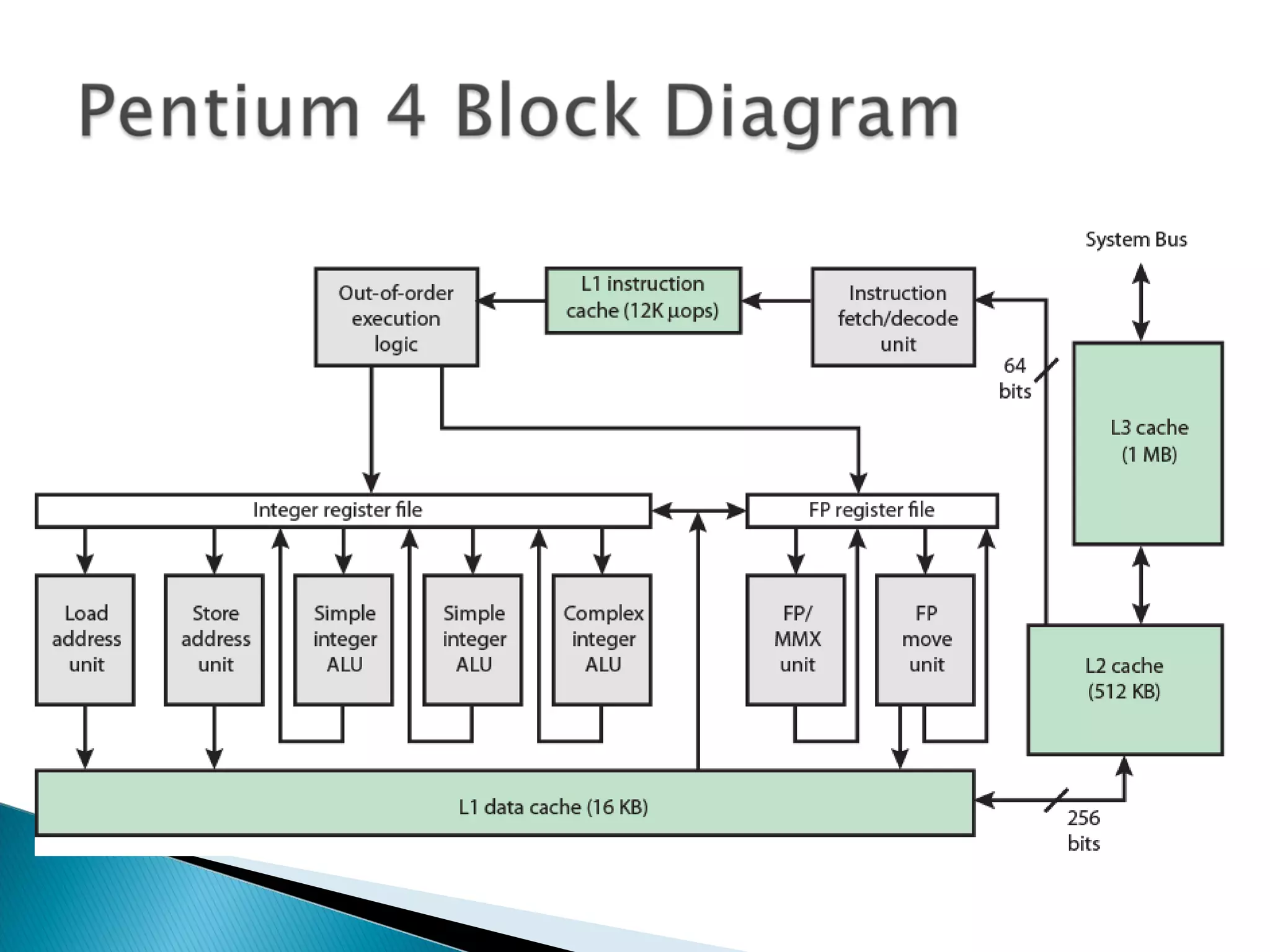


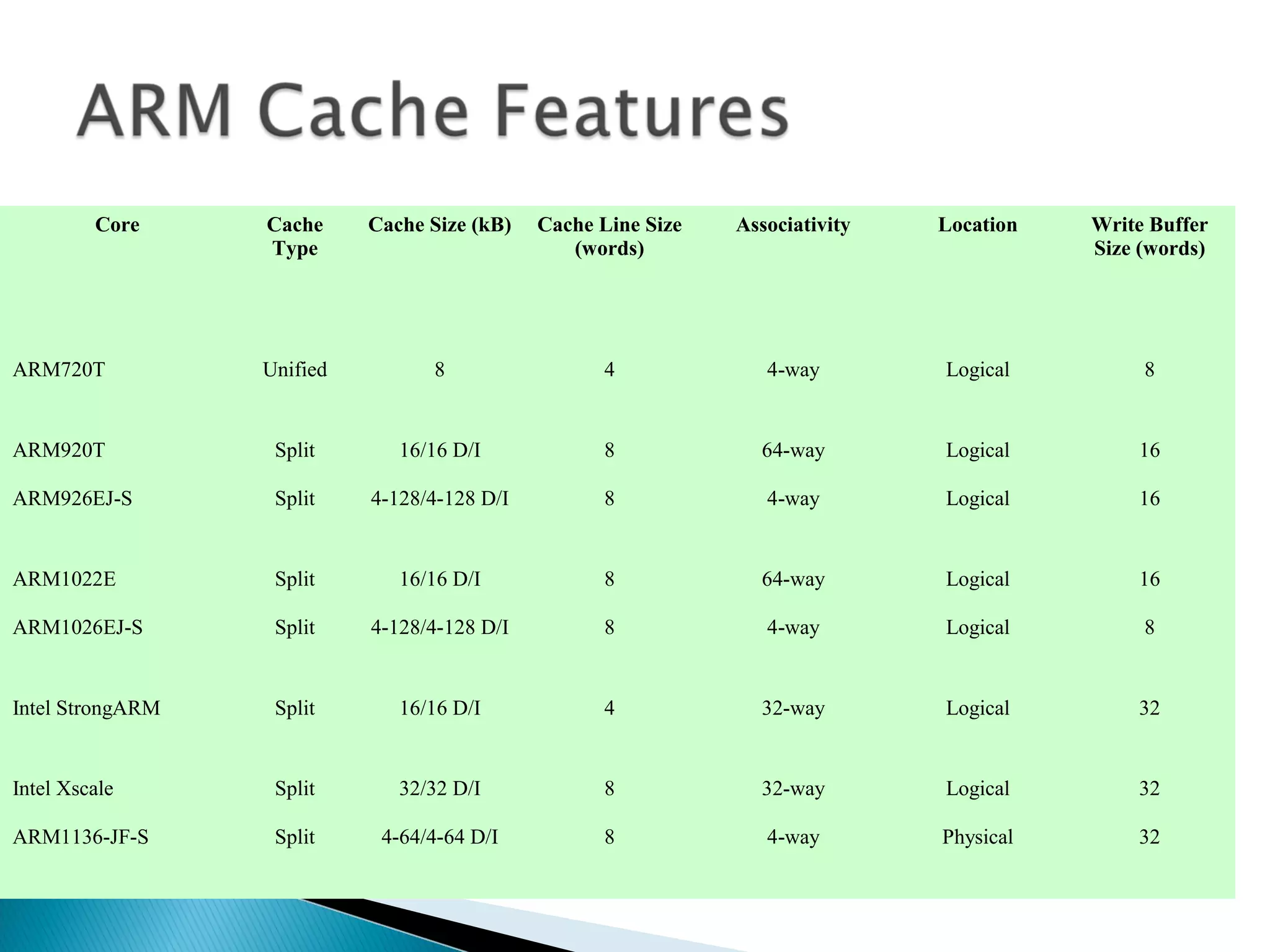

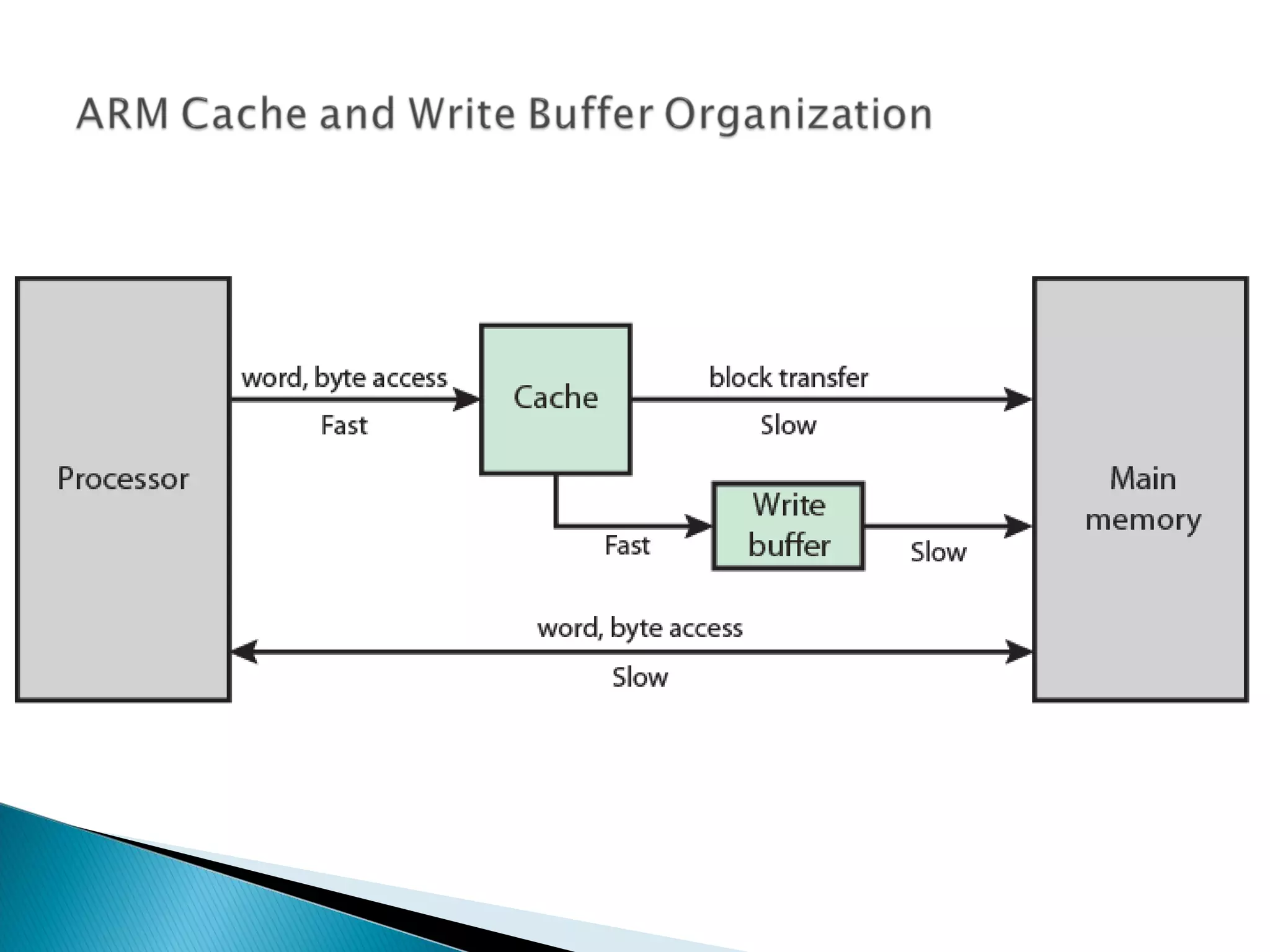


The document discusses cache design and organization. It describes how caches work, sitting between the CPU and main memory to provide fast access to frequently used data. The key aspects covered include cache size, block size, mapping techniques, replacement algorithms, write policies, and the evolution of cache hierarchies in processors like the Pentium IV with multiple levels of on-chip and off-chip caches.
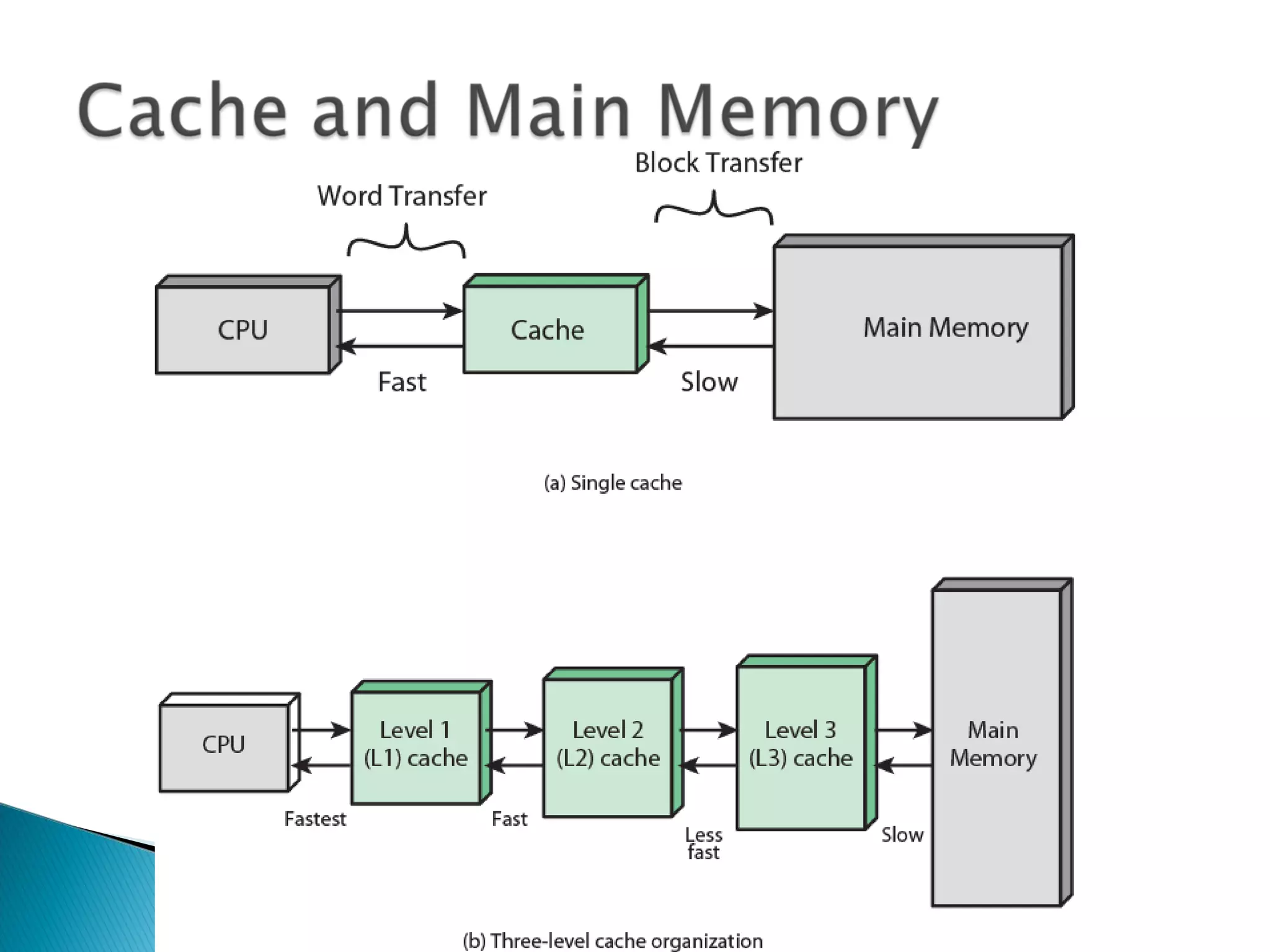
Introduction to cache elements and organization, the role of cache between main memory and CPU, how caching improves data retrieval.
Introduction to cache elements and organization, the role of cache between main memory and CPU, how caching improves data retrieval.
Introduction to cache elements and organization, the role of cache between main memory and CPU, how caching improves data retrieval.
Introduction to cache elements and organization, the role of cache between main memory and CPU, how caching improves data retrieval.
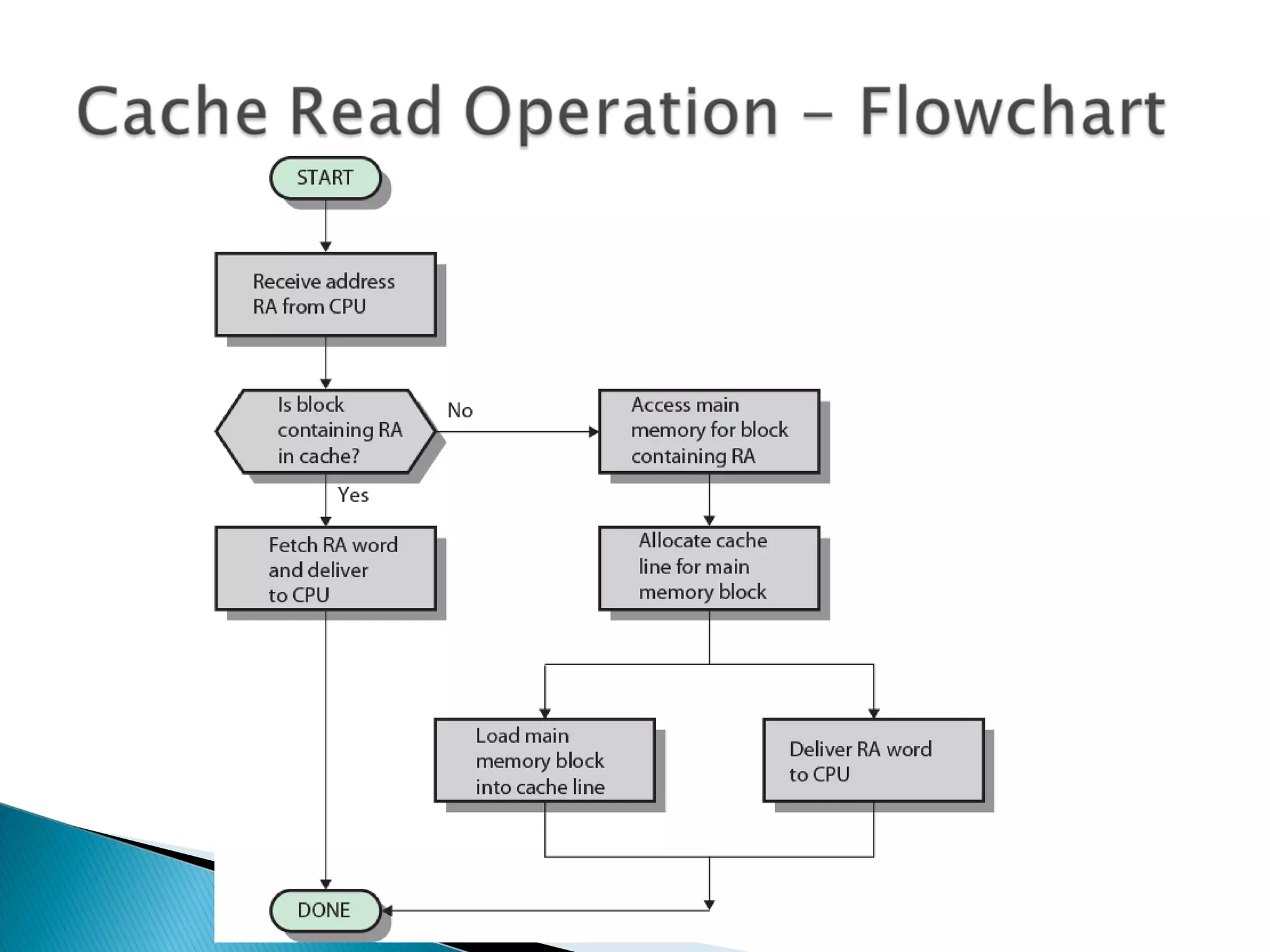
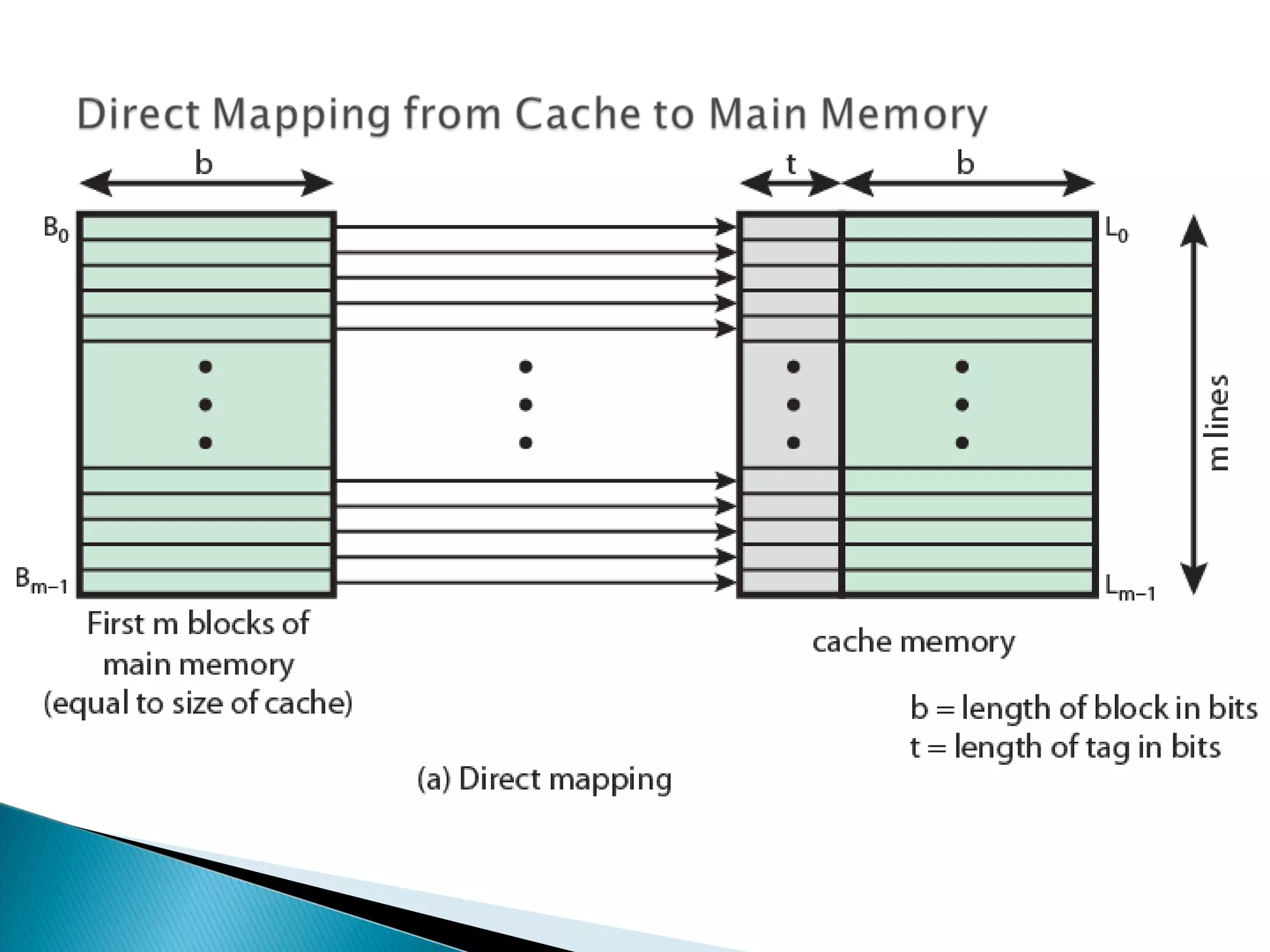
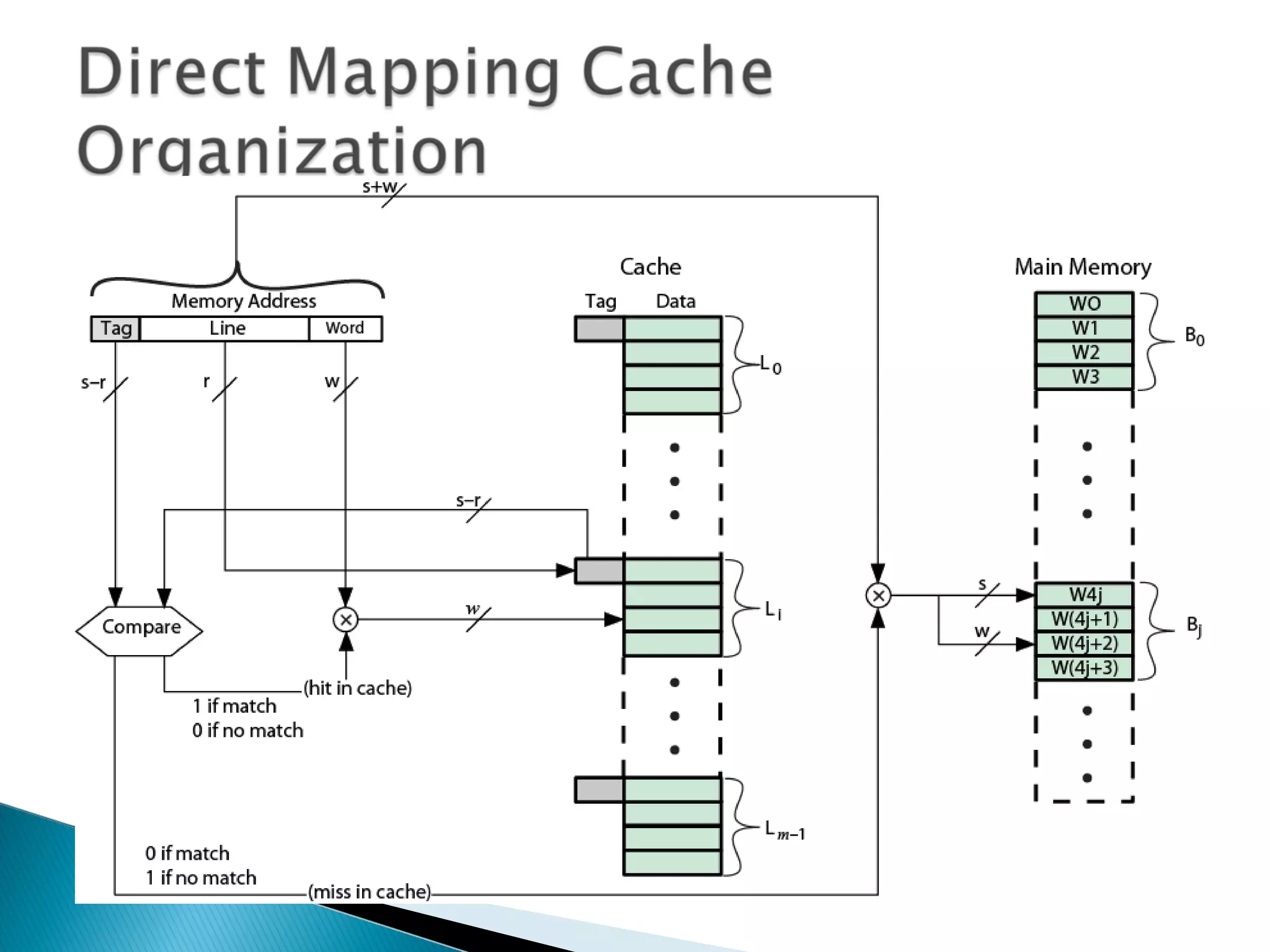
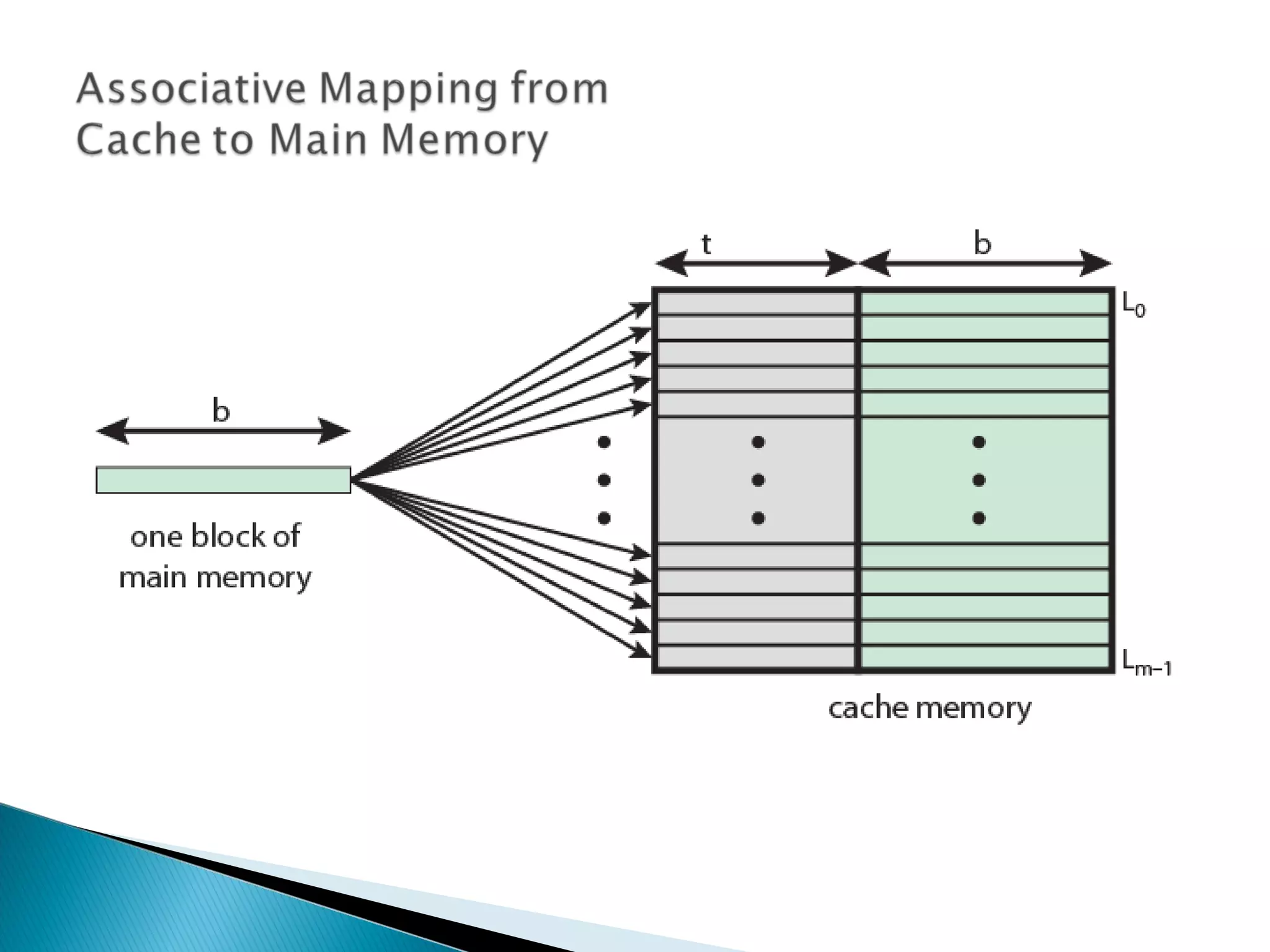
Explanation of cache addressing, block mapping, and how addresses are split for cache functionality.
Explanation of cache addressing, block mapping, and how addresses are split for cache functionality.
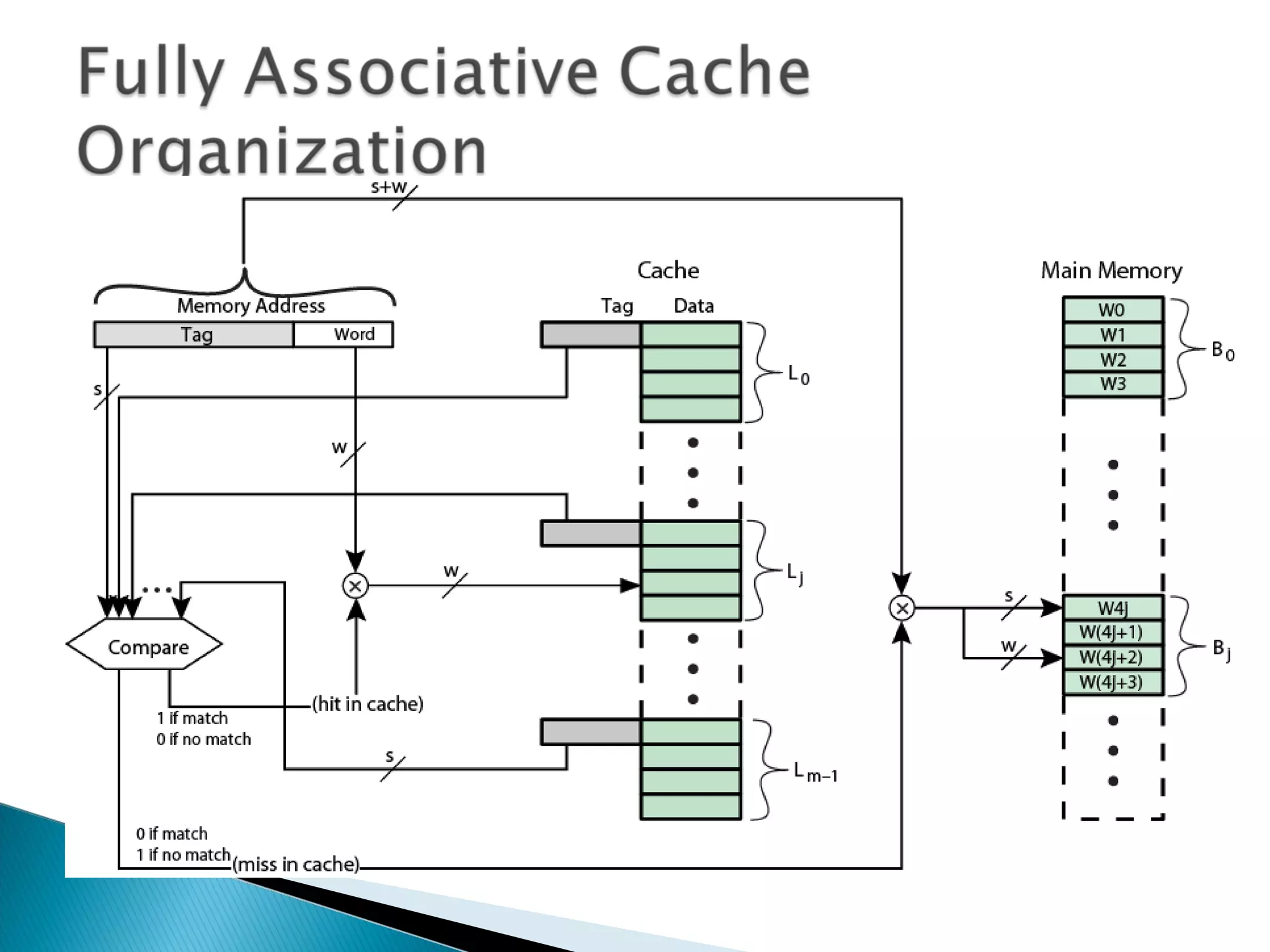
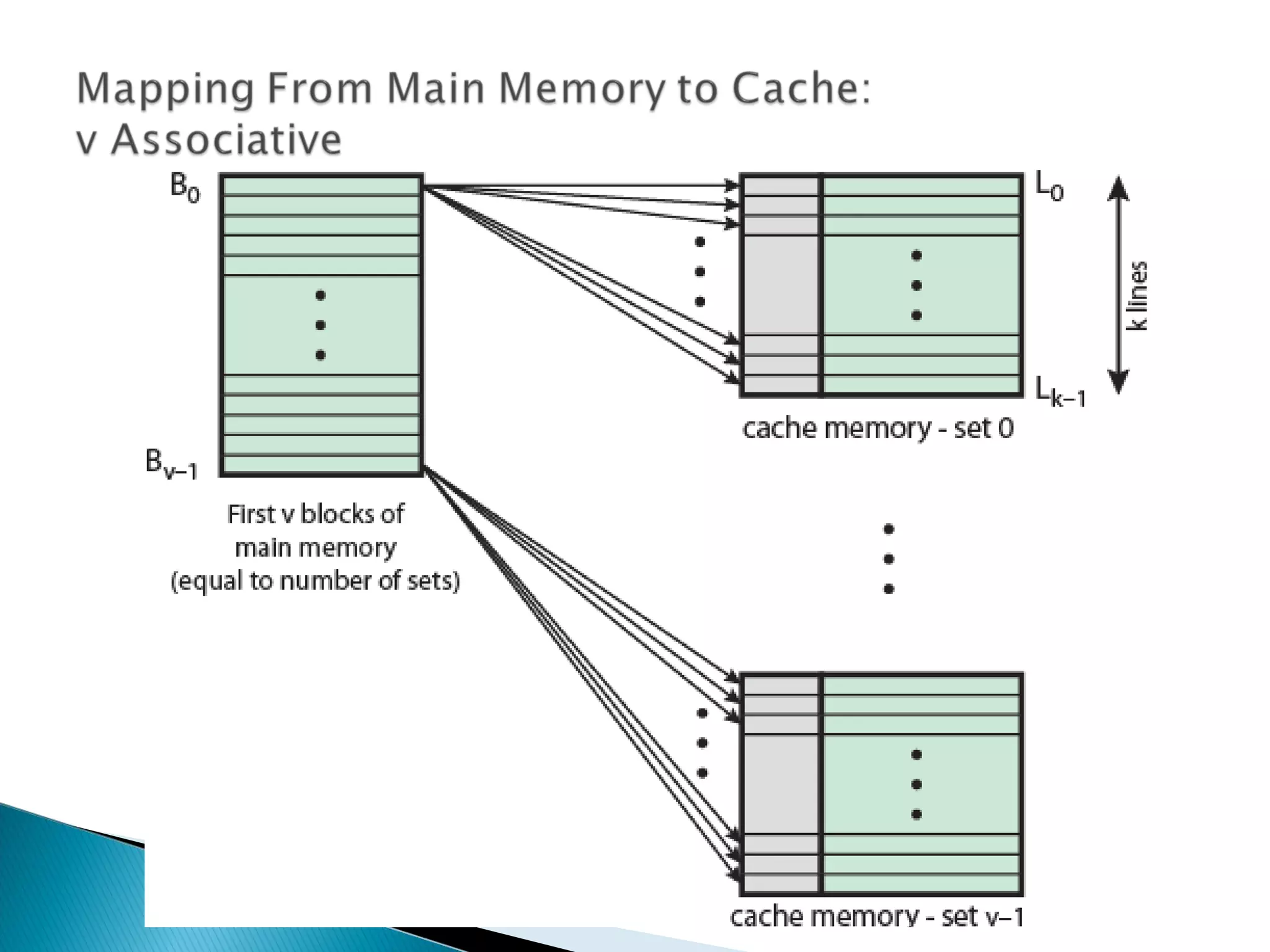
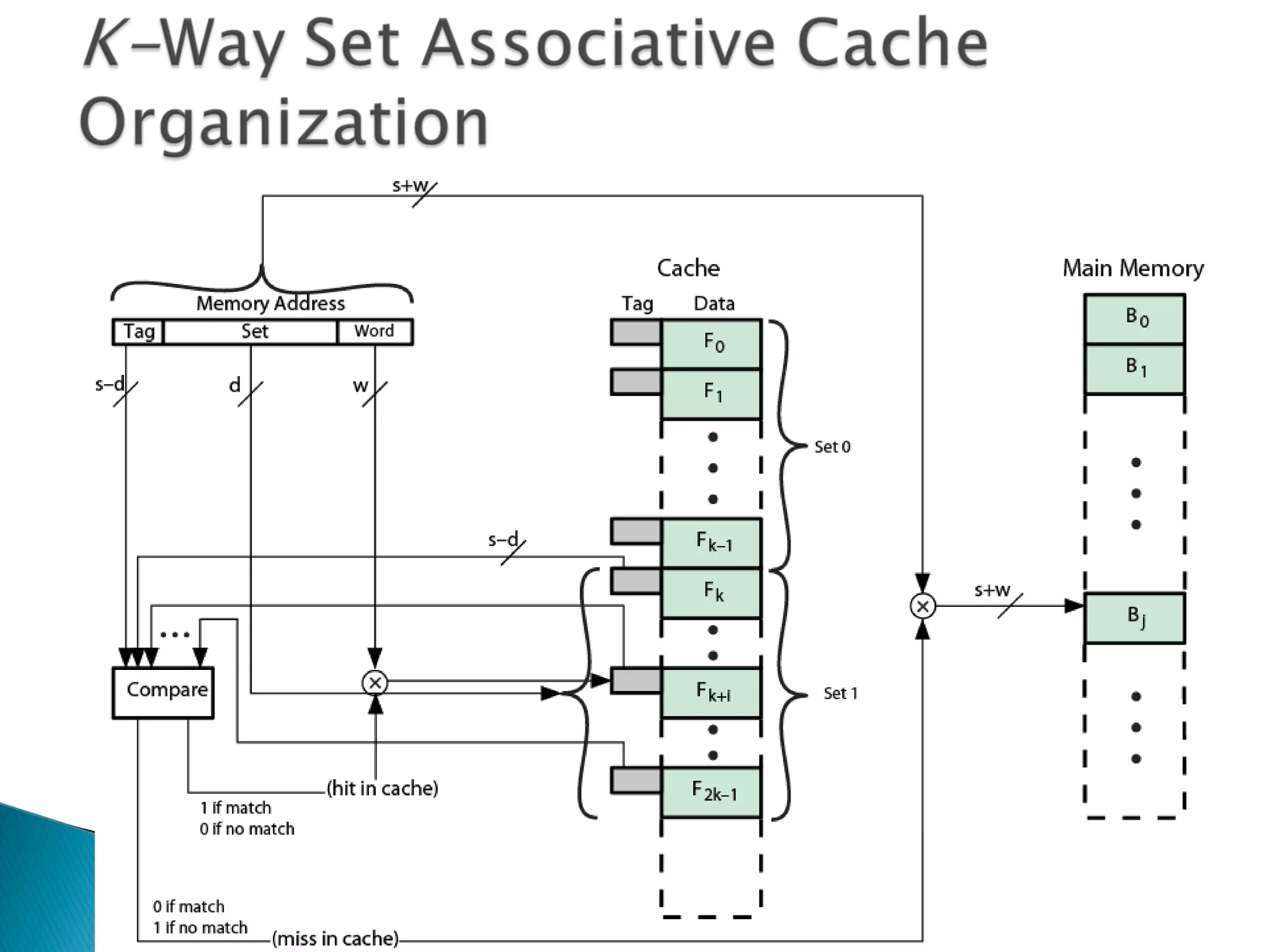
Discusses cache search efficiency, mapping techniques, and how address length impacts cache performance.
Discusses cache search efficiency, mapping techniques, and how address length impacts cache performance.
Explores different cache replacement algorithms such as LRU and FIFO for managing cache lines and addressing memory efficiency.
Details on writing policies, update procedures in cache, and the challenges associated with maintaining cache consistency.
Overview of cache technologies used in different processors, trends in cache design, and comparison of cache specs.
Details on writing policies, update procedures in cache, and the challenges associated with maintaining cache consistency.
Overview of cache technologies used in different processors, trends in cache design, and comparison of cache specs.
Identifies cache management practices involving manufacturers like Intel and ARM, highlighting key search strategies.











![DMA presentation [By- Digvijay]](https://cdn.slidesharecdn.com/ss_thumbnails/digvijay-dmapresentation-131231041837-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











































































