Downloaded 194 times




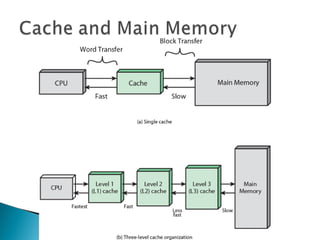

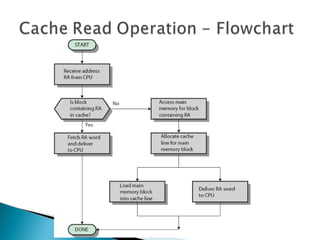






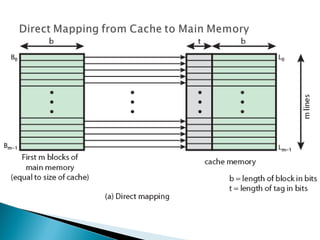
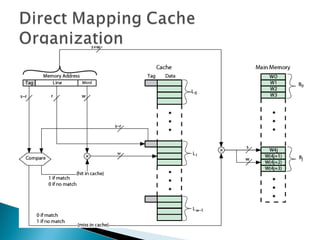



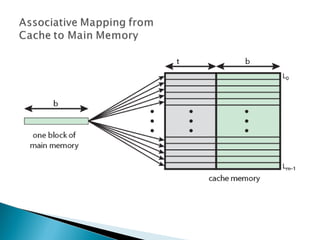
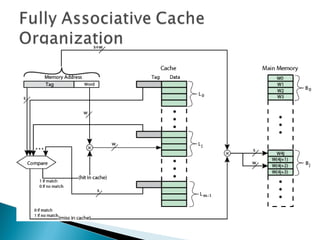




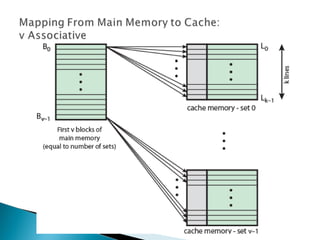
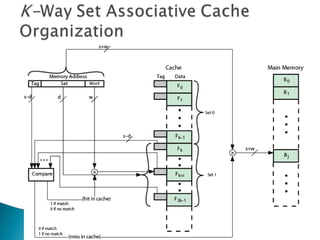











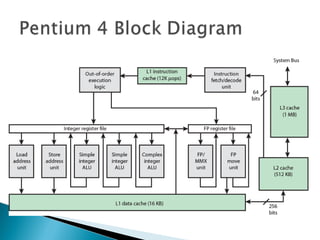


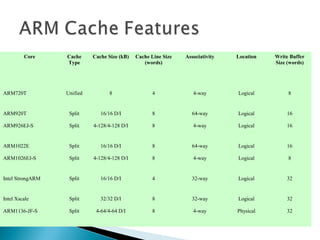

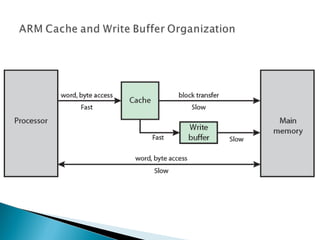


The document discusses cache design and organization. It describes how caches work, sitting between the CPU and main memory to provide fast access to frequently used data. The key aspects covered include cache size, block size, mapping techniques, replacement algorithms, write policies, and the evolution of cache hierarchies in processors like the Pentium IV with multiple levels of on-chip and off-chip caches.























































































