長岡技術科学大学
2015年度GPGPU実践プログラミング(全15回,学部4年対象講義)
第12回偏微分方程式の差分計算
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
・第2回 GPUのアーキテクチャとプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59179215
・第3回 GPGPUプログラミング環境
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59179255
・第3回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59183677
・第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59179449
・第5回 GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59179536
・第6回 パフォーマンス解析ツール
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59179577
・第7回 総和計算
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59179639
・第8回 総和計算(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59179686
・第9回 行列計算(行列-行列積)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59179722
・第10回 行列計算(行列-行列積の高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59179759
・第11回 画像処理
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59179789
・第12回 偏微分方程式の差分計算
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59179972
・第13回 多粒子の運動
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59180018
・第14回 N体問題
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59180054
・第15回 GPU最適化ライブラリ
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59180086
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3













![2階微分の離散化
2階微分の式に整理
22
2
)()(2)(
Δx
ΔxxfxfΔxxf
x
f
GPGPU実践プログラミング15 2015/07/01
dx
サンプリングされた関数値
を配列f[]で保持
f[i]
f[i‐1]
f[i+1]
2階の中心差分
(f[i+1]‐2*f[i]+f[i‐1])/(dx*dx)
f[i]
i
i=0 ・・・ i−1 i i+1](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-14-2048.jpg)
![2階微分の離散化
2015/07/01GPGPU実践プログラミング16
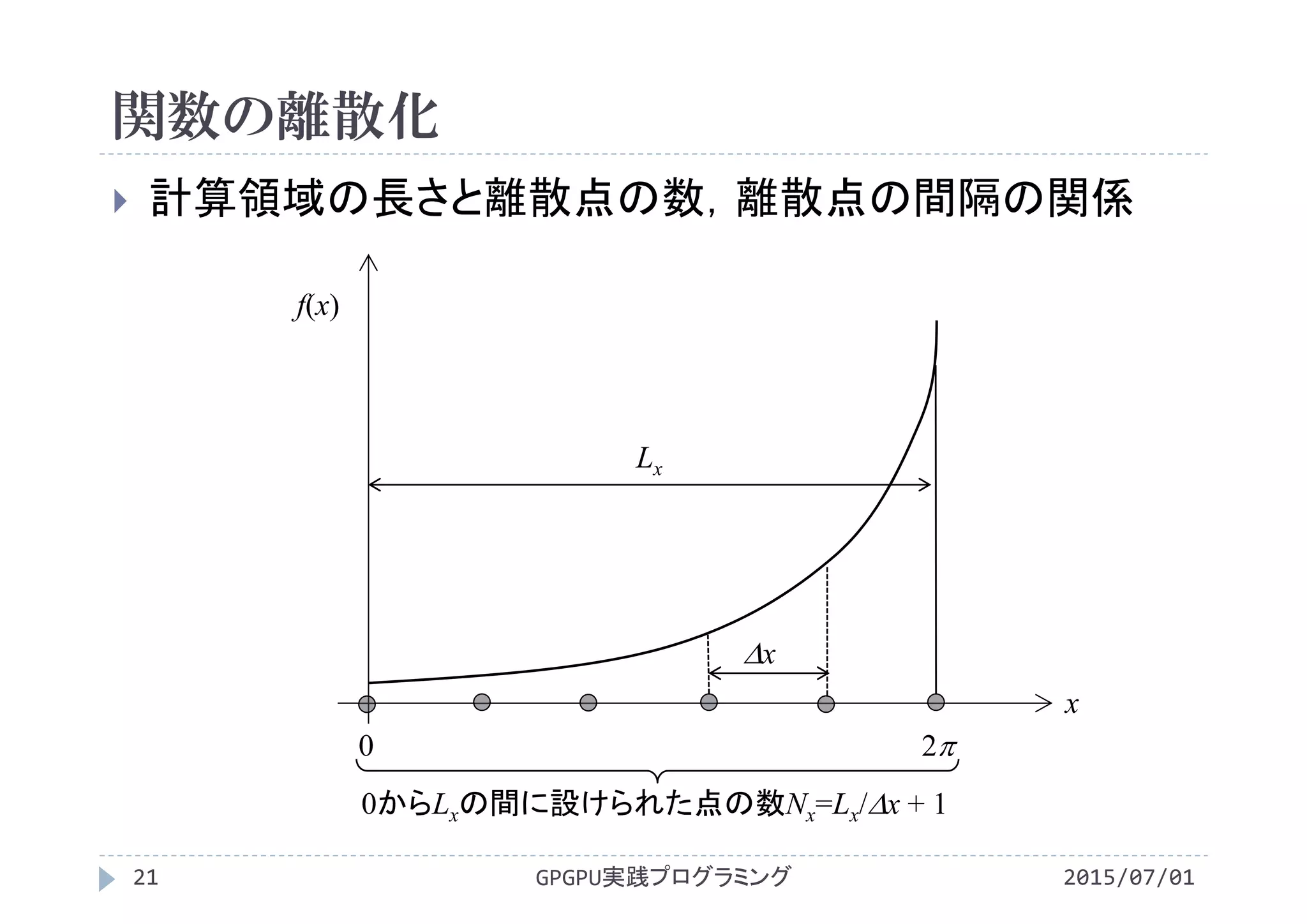
サンプリングされた関数値fの保持
x方向長さ(計算領域の長さ)を等間隔xに分割
間隔xの両端に離散点(観測点)を置き,そこでfの値を定義
原点から順に離散点に番号を付与し,iで表現
離散点iにおけるfの値を配列f[i]に保存
配列f[]
i=0 ・・・ i−1 i i+1
f[i]
i
離散点
配列(メモリ)](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-15-2048.jpg)
![差分法の実装
2015/07/01GPGPU実践プログラミング17
計算領域内部
d2fdx2[i]=(f[i‐1]‐2*f[i]+f[i+1])/dxdx;
境界条件(関数値が無いため処理を変更)
d2fdx2[0 ]=(2*f[0 ]‐5*f[1 ]+4*f[2 ]‐f[3 ])/dxdx;
d2fdx2[N‐1]=(2*f[N‐1]‐5*f[N‐2]+4*f[N‐3]‐f[N‐4])/dxdx;
d2fdx2[i]
f[i]
+ + + + +
2
1
Δx
+](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-16-2048.jpg)
![差分法の実装
2015/07/01GPGPU実践プログラミング18
計算領域内部
d2fdx2[i]=(f[i‐1]‐2*f[i]+f[i+1])/dxdx;
境界条件(関数値が無いため処理を変更)
d2fdx2[0 ]=(2*f[0 ]‐5*f[1 ]+4*f[2 ]‐f[3 ])/dxdx;
d2fdx2[N‐1]=(2*f[N‐1]‐5*f[N‐2]+4*f[N‐3]‐f[N‐4])/dxdx;
d2fdx2[i]
f[i]
+
2
1
Δx](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-17-2048.jpg)
![差分法の実装
2015/07/01GPGPU実践プログラミング19
計算領域内部
d2fdx2[i]=(f[i‐1]‐2*f[i]+f[i+1])/dxdx;
境界条件(関数値が無いため処理を変更)
d2fdx2[0 ]=(2*f[0 ]‐5*f[1 ]+4*f[2 ]‐f[3 ])/dxdx;
d2fdx2[N‐1]=(2*f[N‐1]‐5*f[N‐2]+4*f[N‐3]‐f[N‐4])/dxdx;
d2fdx2[i]
f[i]
2
1
Δx
+](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-18-2048.jpg)
![#include<stdlib.h>
#include<math.h>/*‐lmオプションが必要*/
#define Lx (2.0*M_PI)
#define Nx (256)
#define dx (Lx/(Nx‐1))
#define Nbytes (Nx*sizeof(double))
#define dxdx (dx*dx)
void init(double *f){
int i;
for(i=0; i<Nx; i++){
f[i] = sin(i*dx);
}
}
void differentiate(double *f,
double *d2fdx2){
int i;
d2fdx2[0] = ( 2.0*f[0]
‐5.0*f[1]
+4.0*f[2]
‐ f[3])/dxdx;
for(i=1; i<Nx‐1; i++)
d2fdx2[i] = ( f[i+1]
‐2.0*f[i ]
+ f[i‐1])/dxdx;
d2fdx2[Nx‐1]=(‐ f[Nx‐4]
+4.0*f[Nx‐3]
‐5.0*f[Nx‐2]
+2.0*f[Nx‐1])/dxdx;
}
int main(void){
double *f,*d2fdx2;
f = (double *)malloc(Nbytes);
d2fdx2 = (double *)malloc(Nbytes);
init(f);
differentiate(f,d2fdx2);
return 0;
}
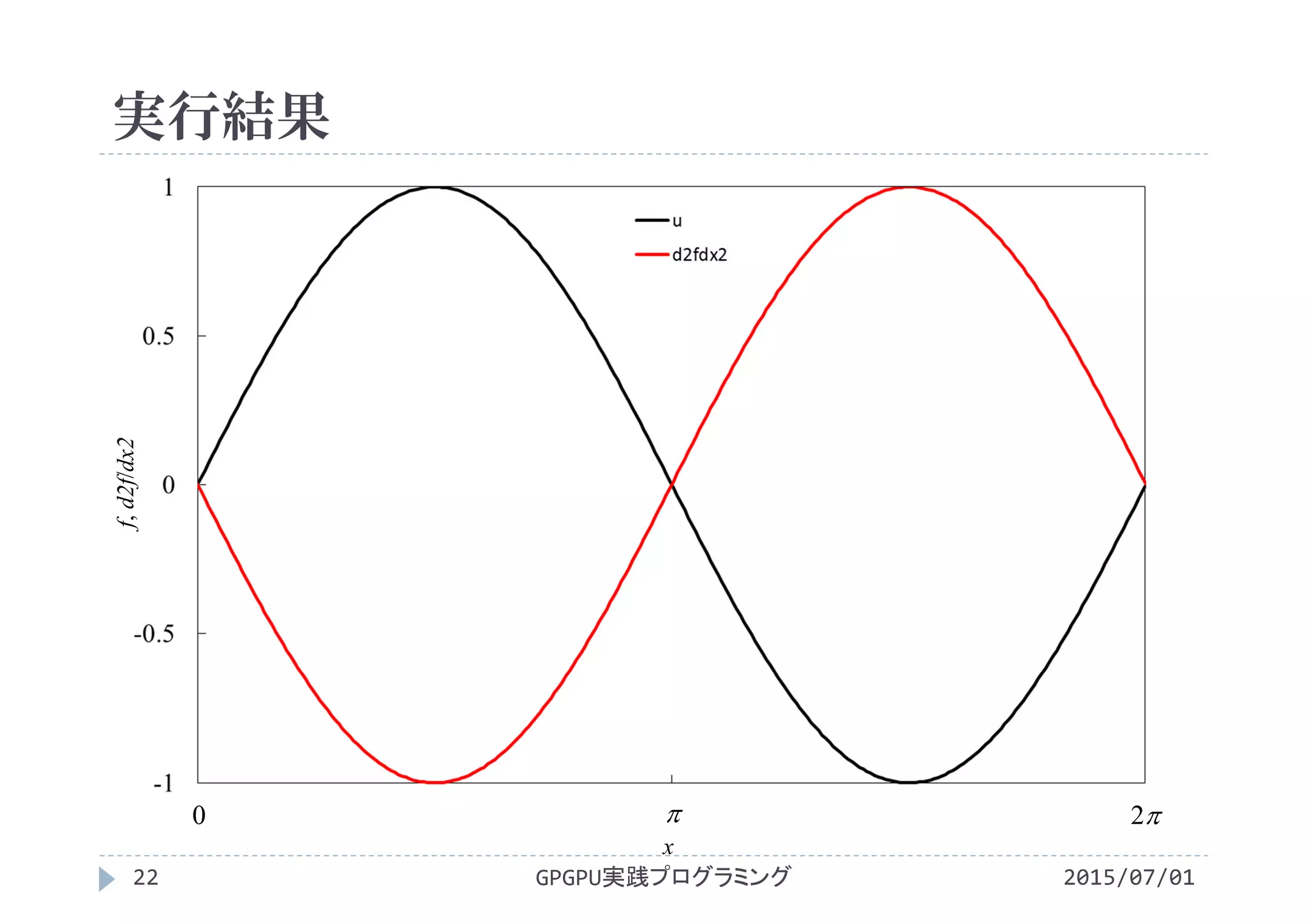
CPUプログラム
2015/07/01GPGPU実践プログラミング20
differentiate.c](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-19-2048.jpg)
![GPUへの移植
計算領域内部を計算するスレッド
d2fdx2[i]=(f[i‐1]‐2*f[i]+f[i+1])/dxdx;
境界を計算するスレッド
d2fdx2[0 ]=(2*f[0 ]‐5*f[1 ]+4*f[2 ]‐f[3 ])/dxdx;
d2fdx2[N‐1]=(2*f[N‐1]‐5*f[N‐2]+4*f[N‐3]‐f[N‐4])/dxdx;
2015/07/01GPGPU実践プログラミング23
d2fdx2[i]
f[i]
+ + + + + +
2
1
Δx
+ +](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-22-2048.jpg)
![#include<stdio.h>
#include<stdlib.h>
#include<math.h>/*‐lmオプションが必要*/
#define Lx (2.0*M_PI)
#define Nx (256)
#define dx (Lx/(Nx‐1))
#define Nbytes (Nx*sizeof(double))
#define dxdx (dx*dx)
#define NT (128)
#define NB (Nx/NT)
void init(double *f){
int i;
for(i=0; i<Nx; i++){
f[i] = sin(i*dx);
}
}
__global__ void differentiate
(double *f, double *d2fdx2){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
if(i==0)
d2fdx2[i] = ( 2.0*f[i ]
‐5.0*f[i+1]
+4.0*f[i+2]
‐ f[i+3])/dxdx;
if(0<i && i<Nx‐1)
d2fdx2[i] = ( f[i+1]
‐2.0*f[i ]
+ f[i‐1])/dxdx;
if(i==Nx‐1)
d2fdx2[i]=(‐ f[i‐3]
+4.0*f[i‐2]
‐5.0*f[i‐1]
+2.0*f[i ])/dxdx;
}
GPUプログラム
2015/07/01GPGPU実践プログラミング24
differentiate.cu](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-23-2048.jpg)
![int main(void){
double *host_f,*host_d2fdx2;
double *f,*d2fdx2;
host_f =(double *)malloc(Nbytes);
cudaMalloc((void **)&f,Nbytes);
cudaMalloc((void **)&d2fdx2,Nbytes);
init(host_f);
cudaMemcpy(f, host_f, Nbytes, cudaMemcpyHostToDevice);
differentiate<<<NB, NT>>>(f, d2fdx2);
//host_d2fdx2=(double *)malloc(Nbytes);
//cudaMemcpy(host_d2fdx2, d2fdx2, Nbytes, cudaMemcpyDeviceToHost);
//for(int i=0; i<Nx; i++)printf("%f,%f,%f¥n",i*dx,host_f[i],host_d2fdx2[i]);
free(host_f);
free(host_d2fdx2);
cudaFree(f);
cudaFree(d2fdx2);
return 0;
}
GPUプログラム
2015/07/01GPGPU実践プログラミング25
differentiate.cu](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-24-2048.jpg)





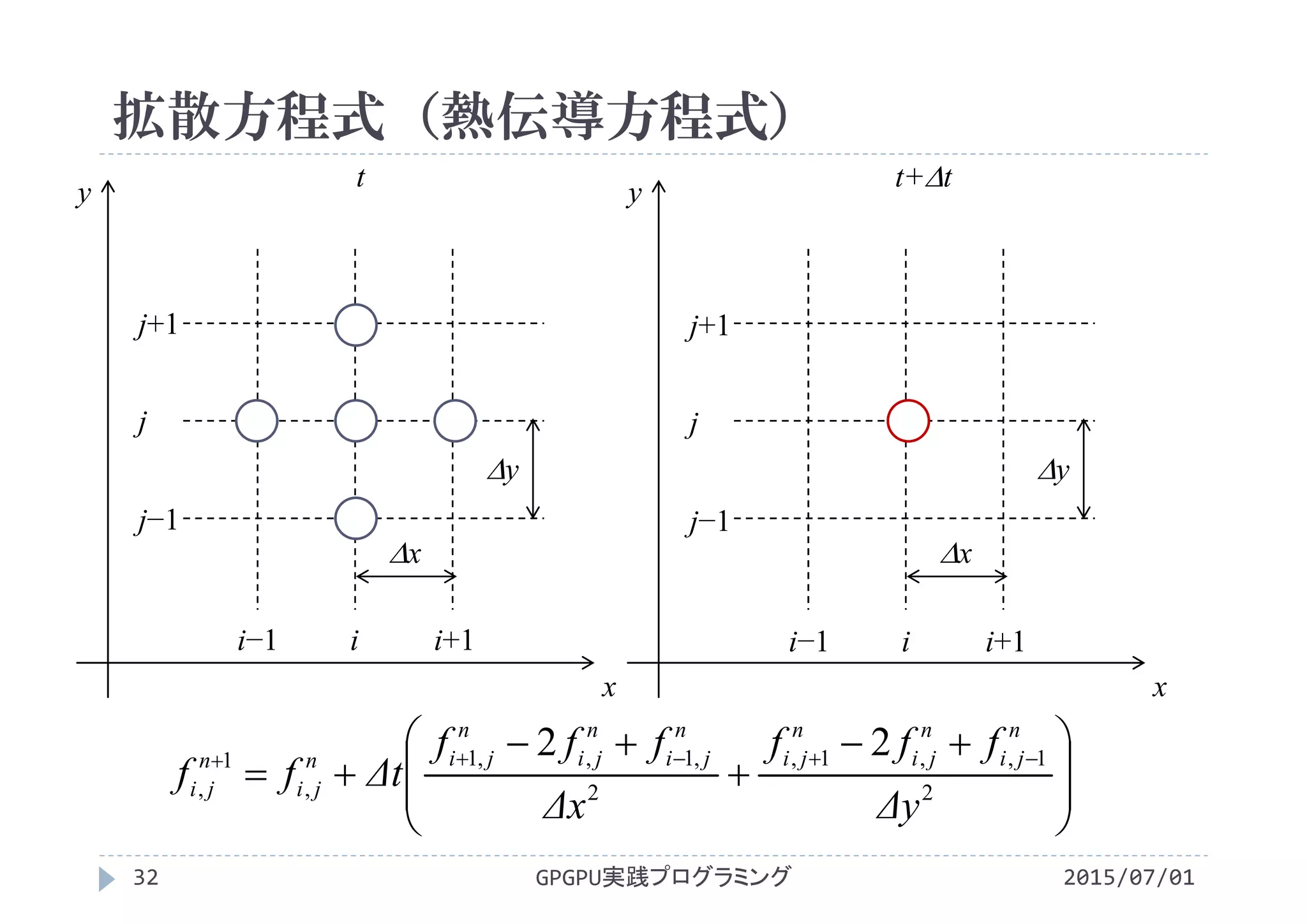
![離散化された関数値の保持
2015/07/01GPGPU実践プログラミング31
各方向を等間隔x, yに分割し,離散点を配置
離散点で関数値を定義し,配列に保存
配列f[][]
i=0 ・・・ i−1 i i+1
i
離散点
配列(メモリ)
j=0 ・・・j−1 j j+1](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-30-2048.jpg)





![void init(double *f, double *f_lap, double *f_new){
int i,j,ij;
double x,y;
for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){
f [i+Nx*j] = 0.0;
f_lap[i+Nx*j] = 0.0;
f_new[i+Nx*j] = 0.0;
x=i*dx‐Lx/2.0;
y=j*dy‐Ly/2.0;
if(sqrt(x*x+y*y)<=0.2) f[i+Nx*j] = 1.0;
}
}
}
void laplacian(double *f, double *f_lap){
int i,j,ij,ip1j,im1j,ijp1,ijm1;
for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){
ij = i+Nx*j;
im1j=i‐1+Nx* j; if(i‐1< 0 )im1j=i+1+Nx*j;
ip1j=i+1+Nx* j; if(i+1>=Nx)ip1j=i‐1+Nx*j;
ijm1=i +Nx*(j‐1);if(j‐1< 0 )ijm1=i+Nx*(j+1);
ijp1=i +Nx*(j+1);if(j+1>=Ny)ijp1=i+Nx*(j‐1);
f_lap[ij] = (f[ip1j]‐2.0*f[ij]+f[im1j])/dxdx
+(f[ijp1]‐2.0*f[ij]+f[ijm1])/dydy;
}
}
}
void integrate
(double *f, double *f_lap, double *f_new){
int i,j,ij;
for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){
ij = i+Nx*j;
f_new[ij] = f[ij] + dt*DIFF*f_lap[ij];
}
}
}
void update(double *f, double *f_new){
int i,j,ij;
for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){
ij = i+Nx*j;
f[ij] = f_new[ij];
}
}
}
CPUプログラム
2015/07/01GPGPU実践プログラミング38
diffusion.c](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-37-2048.jpg)
![CPUプログラム
差分計算
x方向,y方向偏微分を個別に計算して加算
void laplacian(double *f, double *f_lap){
int i,j,ij,ip1j,im1j,ijp1,ijm1;
for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){
ij =i +Nx* j;
im1j=i‐1+Nx* j; if(i‐1< 0 )im1j=i+1+Nx*j;
ip1j=i+1+Nx* j; if(i+1>=Nx)ip1j=i‐1+Nx*j;
ijm1=i +Nx*(j‐1);if(j‐1< 0 )ijm1=i+Nx*(j+1);
ijp1=i +Nx*(j+1);if(j+1>=Ny)ijp1=i+Nx*(j‐1);
f_lap[ij] = (f[ip1j]‐2.0*f[ij]+f[im1j])/dxdx
+(f[ijp1]‐2.0*f[ij]+f[ijm1])/dydy;
}
}
}
GPGPU実践プログラミング39 2015/07/01](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-38-2048.jpg)
![ラプラシアン計算のメモリ参照
ある1点i,jのラプラシアンを計算するために,周囲5点
のfを参照
GPGPU実践プログラミング40 2015/07/01
f[] f_lap[]
i−1 i i+1
j−1jj+1](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-39-2048.jpg)
![ラプラシアン計算のメモリ参照
ある1点i,jのラプラシアンを計算するために,周囲5点
のfを参照
GPGPU実践プログラミング41 2015/07/01
i−1 i i+1
j−1jj+1
f[] f_lap[]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-40-2048.jpg)
![ラプラシアン計算のメモリ参照
ある1点i,jのラプラシアンを計算するために,周囲5点
のfを参照
GPGPU実践プログラミング42 2015/07/01
i−1 i i+1
j−1jj+1
f[] f_lap[]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-41-2048.jpg)
![ラプラシアン計算のメモリ参照
ある1点i,jのラプラシアンを計算するために,周囲5点
のfを参照
GPGPU実践プログラミング43 2015/07/01
i−1 i i+1
j−1jj+1
f[] f_lap[]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-42-2048.jpg)
![ラプラシアン計算のメモリ参照
ある1点i,jのラプラシアンを計算するために,周囲5点
のfを参照
全てのfを参照し,領域内部のf_lapを計算
GPGPU実践プログラミング44 2015/07/01
f[] f_lap[]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-43-2048.jpg)
![CPUプログラム
境界条件
法線方向の1階微分が0
境界での2階の差分式
GPGPU実践プログラミング45 2015/07/01
f_lap[]
0
n
f
n: 外向き法線ベクトル
jiji
jiji
ff
Δx
ff
,1,1
,1,1
0
2
1,1,
1,1,
0
2
jiji
jiji
ff
Δy
ff
2
,,1
2
,,1
2
,1,,1 22
or
222
Δx
ff
Δx
ff
Δx
fff jijijijijijiji
2
,1,
2
,1,
2
1,,1, 22
or
222
Δy
ff
Δy
ff
Δy
fff jijijijijijiji
](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-44-2048.jpg)
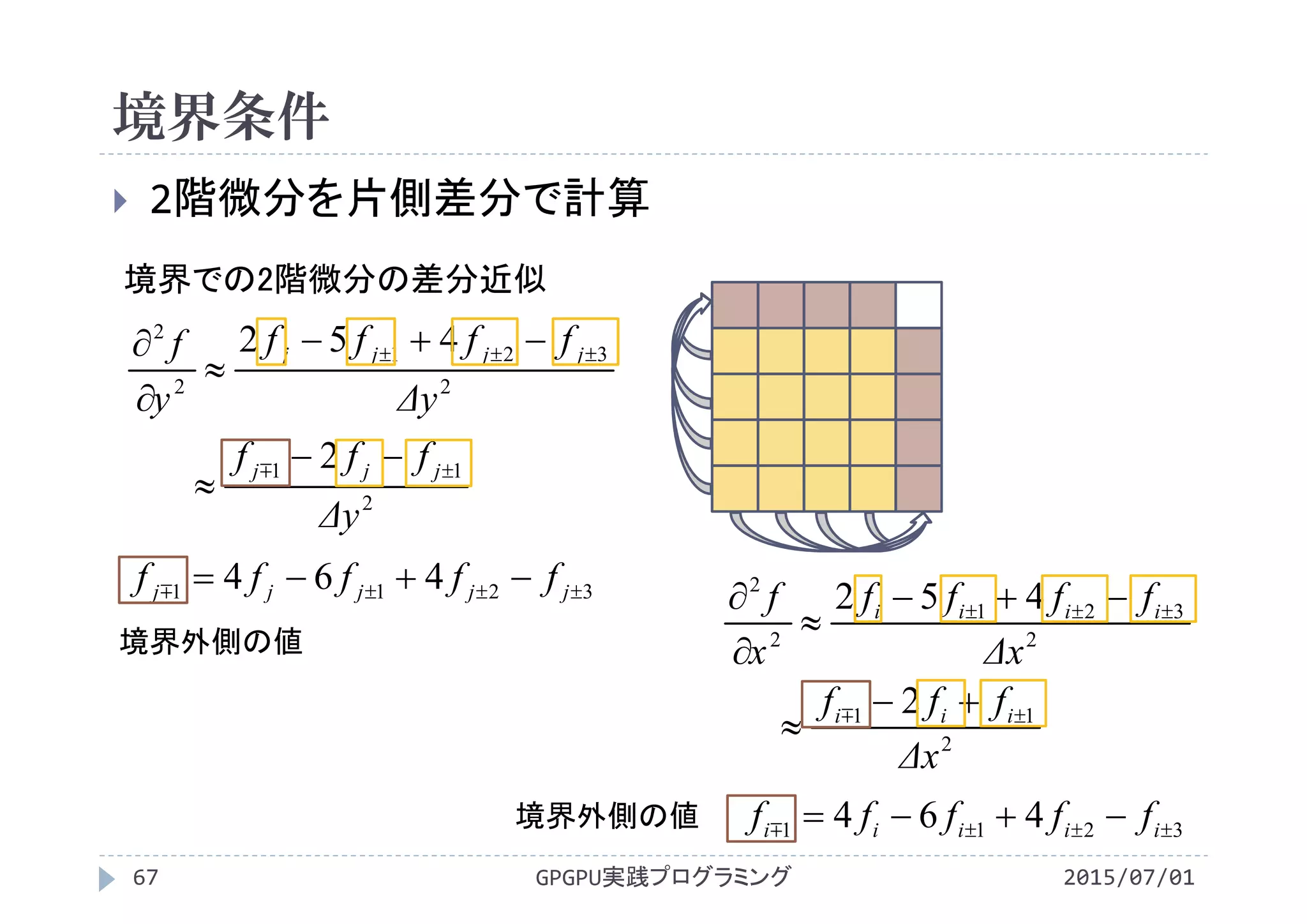
![CPUプログラム
境界条件
参照する点が境界からはみ出して
いる場合は添字を修正
2階微分を計算する式は変更なし
右端ではi+1をi‐1に修正
左端ではi‐1をi+1に修正
上端ではj+1をj‐1に修正
下端ではj‐1をj+1に修正
GPGPU実践プログラミング46 2015/07/01
f_lap[]
if(i‐1< 0 )im1j=i+1+Nx*j;
if(i+1>=Nx)ip1j=i‐1+Nx*j;
if(j‐1< 0 )ijm1=i +Nx*(j+1);
if(j+1>=Ny)ijp1=i +Nx*(j‐1);](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-45-2048.jpg)
![CPUプログラム
fの積分
void integrate(double *f, double *f_lap, double *f_new){
int i,j,ij;
for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){
ij = i+Nx*j;
f_new[ij] = f[ij] + dt*DIFF*f_lap[ij];
}
}
}
GPGPU実践プログラミング47 2015/07/01
2
1,,1,
2
,1,,1
,
1
,
22
Δy
fff
Δx
fff
Δtff
n
ji
n
ji
n
ji
n
ji
n
ji
n
jin
ji
n
ji ](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-46-2048.jpg)
![CPUプログラム
fの更新
fnからfn+1を計算
fn+1からfn+2を計算
今の時刻から次の時刻を求める
求められた次の時刻を今の時刻と見なし,次の時刻を求める
void update(double *f, double *f_new){
int i,j,ij;
for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){
ij = i+Nx*j;
f[ij] = f_new[ij];
}
}
}
GPGPU実践プログラミング48 2015/07/01
同じアルゴリズム](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-47-2048.jpg)

![#define THREADX 16
#define THREADY 16
#define BLOCKX (Nx/THREADX)
#define BLOCKY (Ny/THREADY)
__global__ void laplacian(double *f, double *f_lap){
int i,j,ij,im1j,ip1j,ijm1,ijp1;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
ij =i +Nx* j;
im1j=i‐1+Nx* j; if(i‐1< 0 )im1j=i+1+Nx*j;
ip1j=i+1+Nx* j; if(i+1>=Nx)ip1j=i‐1+Nx*j;
ijm1=i +Nx*(j‐1);if(j‐1< 0 )ijm1=i +Nx*(j+1);
ijp1=i +Nx*(j+1);if(j+1>=Ny)ijp1=i +Nx*(j‐1);
f_lap[ij] = (f[ip1j]‐2.0*f[ij]+f[im1j])/dxdx
+(f[ijp1]‐2.0*f[ij]+f[ijm1])/dydy;
}
__global__ void integrate
(double *f, double *f_lap, double *f_new){
int i,j,ij;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
ij = i+Nx*j;
f_new[ij] = f[ij] + dt*DIFF*f_lap[ij];
}
__global__ void update(double *f, double *f_new){
int i,j,ij;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
ij = i+Nx*j;
f[ij] = f_new[ij];
}
__global__ void init
(double *f, double *f_lap, double *f_new){
int i,j,ij;
double x,y;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
ij = i+Nx*j;
f [ij] = 0.0;
f_lap[ij] = 0.0;
f_new[ij] = 0.0;
x=i*dx‐Lx/2.0;
y=j*dy‐Ly/2.0;
if(sqrt(x*x+y*y)<=0.2) f[ij] = 1.0;
}
GPUプログラム(1スレッドが1点を計算)
2015/07/01GPGPU実践プログラミング50
dif1.cu](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-49-2048.jpg)



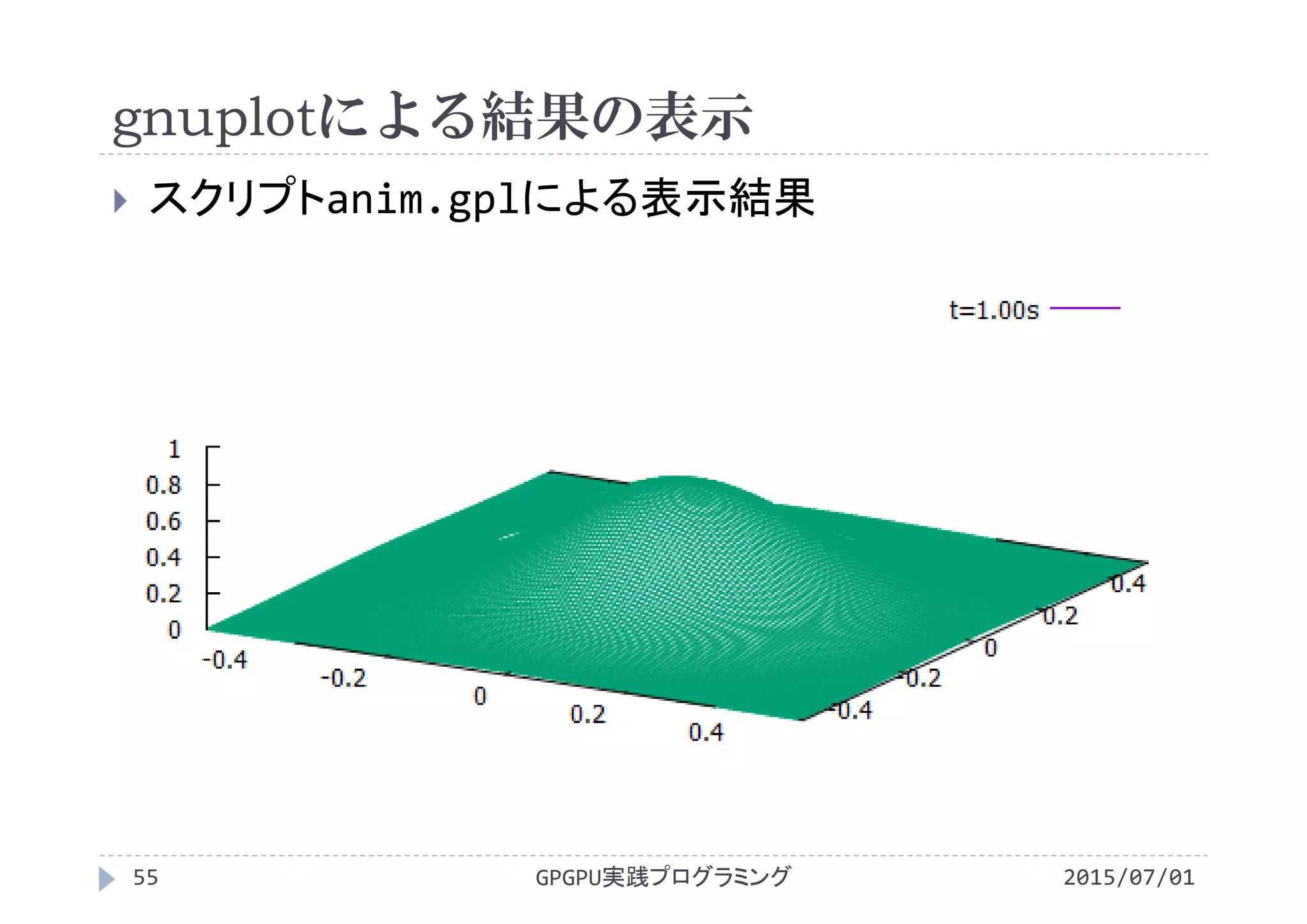
![gnuplotによる結果の表示
2015/07/01GPGPU実践プログラミング54
スクリプトanim.gplの内容
set xrange [‐0.5:0.5] x軸の表示範囲を‐0.5~0.5に固定
set yrange [‐0.5:0.5] y軸の表示範囲を‐0.5~0.5に固定
set zrange [0:1] z軸の表示範囲を0~1に固定
set ticslevel 0 xy平面とz軸の最小値表示位置の差
set hidden3d 隠線消去をする
set view 45,30 視点をx方向45°,y方向30°に設定
set size 1,0.75 グラフの縦横比を1:0.75
unset contour 2次元等高線は表示しない
set surface 3次元で等値面を表示
unset pm3d カラー表示はしない
以下でファイルを読み込み,3次元表示
splot 'f0.00.txt' using 1:2:3 with line title "t=0.00s"
...
splot 'f1.00.txt' using 1:2:3 with line title "t=1.00s"](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-53-2048.jpg)
![gnuplotによる結果の表示
2015/07/01GPGPU実践プログラミング56
スクリプトanim_color.gplの内容
set xrange [‐0.5:0.5] x軸の表示範囲を‐0.5~0.5に固定
set yrange [‐0.5:0.5] y軸の表示範囲を‐0.5~0.5に固定
set zrange [0:1] z軸の表示範囲を0~1に固定
set ticslevel 0 xy平面とz軸の最小値表示位置の差
set hidden3d 隠線消去をする
set view 45,30 視点をx方向45°,y方向30°に設定
set size 1,0.75 グラフの縦横比を1:0.75
unset contour 2次元等高線は表示しない
set surface 3次元で等値面を表示
set pm3d カラー表示する
set cbrange[0:1] カラーバーの表示範囲を0~1に固定
以下でファイルを読み込み,3次元表示
splot 'f0.00.txt' using 1:2:3 with line title "t=0.00s"
...
splot 'f1.00.txt' using 1:2:3 with line title "t=1.00s"](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-55-2048.jpg)

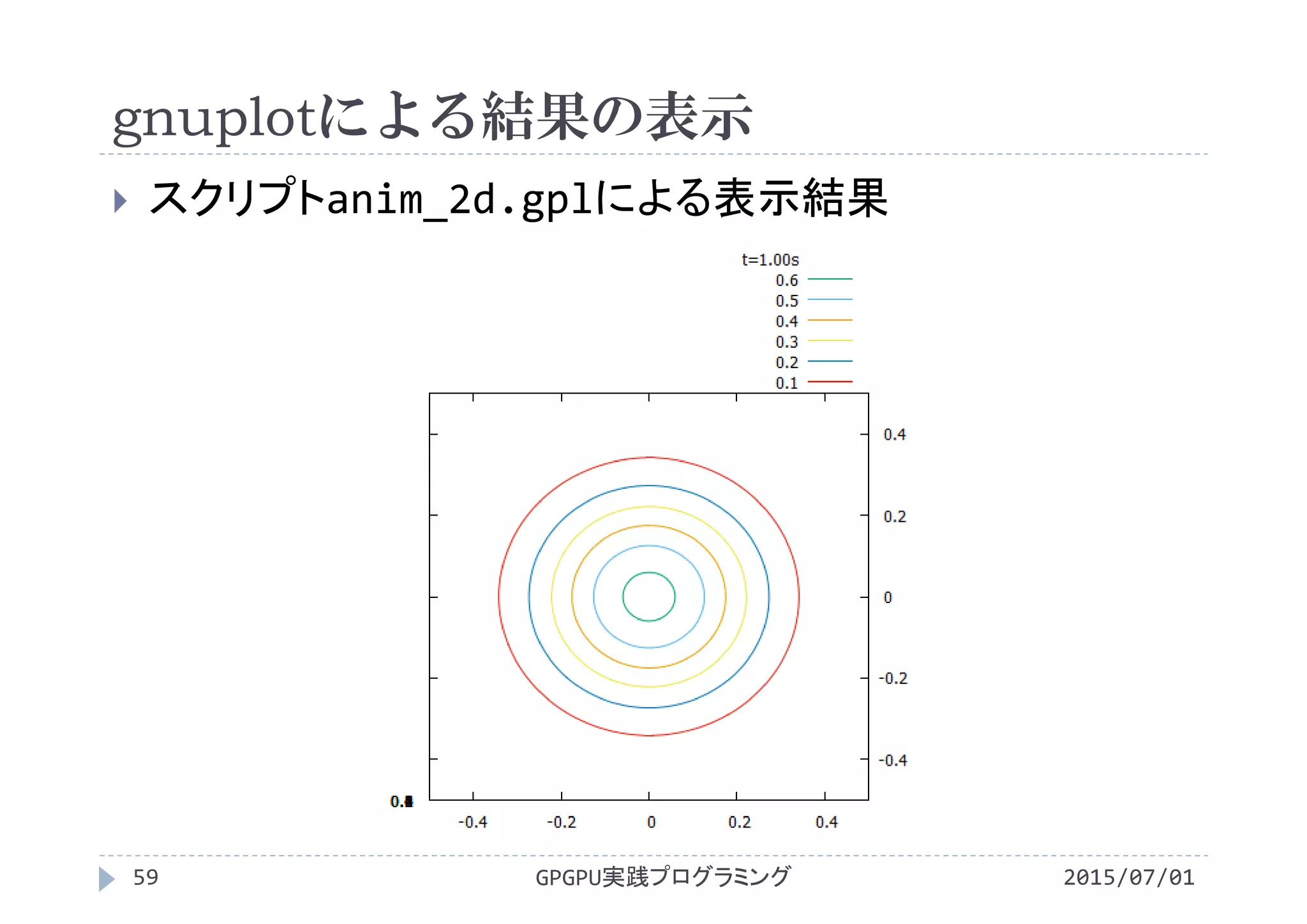
![gnuplotによる結果の表示
2015/07/01GPGPU実践プログラミング58
スクリプトanim_2d.gplの内容
set xrange [‐0.5:0.5] x軸の表示範囲を‐0.5~0.5に固定
set yrange [‐0.5:0.5] y軸の表示範囲を‐0.5~0.5に固定
set zrange [0:1] z軸の表示範囲を0~1に固定
set view 0,0 真上から見下ろす
set size 1,1 グラフの縦横比を1:1
set contour 2次元等高線を表示
unset surface 3次元で等値面を表示しない
unset pm3d カラー表示しない
set cntrparam levels incremental 0,0.1,1
等高線を0から1まで0.1刻みに設定
以下でファイルを読み込み,3次元表示
splot 'f0.00.txt' using 1:2:3 with line title "t=0.00s"
...
splot 'f1.00.txt' using 1:2:3 with line title "t=1.00s"](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-57-2048.jpg)
![様々な境界条件の計算
共有メモリを利用してキャッシュを模擬
共有メモリに付加的な領域を追加
袖領域
GPGPU実践プログラミング60 2015/07/01
f[] f_lap[]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-59-2048.jpg)
![様々な境界条件の計算
共有メモリを利用してキャッシュを模擬
共有メモリに付加的な領域を追加
GPGPU実践プログラミング61 2015/07/01
f[] f_lap[]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-60-2048.jpg)
![様々な境界条件の計算
共有メモリを利用してキャッシュを模擬
共有メモリに付加的な領域を追加
GPGPU実践プログラミング62 2015/07/01
f[]
sf[][]
f_lap[]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-61-2048.jpg)
![付加的な領域(袖領域)の取り扱い
データがグローバルメモリに存在する場合は,グローバ
ルメモリから読み込み
GPGPU実践プログラミング63 2015/07/01
f[]
sf[][]
f_lap[]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-62-2048.jpg)
![付加的な領域(袖領域)の取り扱い
グローバルメモリに無い場合は境界条件から決定
GPGPU実践プログラミング64 2015/07/01
f[]
sf[][]
f_lap[]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-63-2048.jpg)


![#define THREADX 16
#define THREADY 16
#define BLOCKX (Nx/THREADX)
#define BLOCKY (Ny/THREADY)
__global__ void laplacian(double *f, double *f_lap){
int i,j,ij;
int tx,ty;
__shared__ float sf[1+THREADX+1][1+THREADY+1];
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
tx = threadIdx.x + 1;
ty = threadIdx.y + 1;
ij = i+Nx*j;
sf[tx][ty] = f[ij];
__syncthreads();
if(blockIdx.x == 0 && threadIdx.x == 0)
sf[tx‐1][ty] = sf[tx+1][ty];
if(blockIdx.x != 0 && threadIdx.x == 0)
sf[tx‐1][ty] = f[i‐1+Nx*j];
if(blockIdx.x == gridDim.x‐1
&& threadIdx.x == blockDim.x‐1)
sf[tx+1][ty] = sf[tx‐1][ty];
if(blockIdx.x != gridDim.x‐1
&& threadIdx.x == blockDim.x‐1)
sf[tx+1][ty] = f[i+1+Nx*j];
if(blockIdx.y == 0 && threadIdx.y == 0)
sf[tx][ty‐1] = sf[tx][ty+1];
if(blockIdx.y != 0 && threadIdx.y == 0)
sf[tx][ty‐1] = f[i+Nx*(j‐1)];
if(blockIdx.y == gridDim.y‐1
&& threadIdx.y == blockDim.y‐1)
sf[tx][ty+1] = sf[tx][ty‐1];
if(blockIdx.y != gridDim.y‐1
&& threadIdx.y == blockDim.y‐1)
sf[tx][ty+1] = f[i+Nx*(j+1)];
__syncthreads();
f_lap[ij]
= (sf[tx‐1][ty ]‐2.0*sf[tx][ty]+sf[tx+1][ty ])/dxdx
+(sf[tx ][ty‐1]‐2.0*sf[tx][ty]+sf[tx ][ty+1])/dydy;
}
GPUプログラム(ラプラシアンカーネル)
2015/07/01GPGPU実践プログラミング68
dif2.cu](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-67-2048.jpg)
![GPUプログラム(ラプラシアンカーネル)
2015/07/01GPGPU実践プログラミング69
ブロック内のスレッド数+袖領域分の共有メモ
リを確保
袖領域があるために添字の対応が変化
添字の対応を考えないと,必要なデータを袖領域に置い
てしまう
__syncthreads()を呼んでスレッドを同期
共有メモリにデータが正しく書き込まれた事を保証
__shared__ float sf[1+THREADX+1][1+THREADY+1];
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
tx = threadIdx.x;
ty = threadIdx.y;
ij = i+Ny*j;
sf[tx][ty] = f[ij];
__syncthreads();
f[]
sf[][]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-68-2048.jpg)
![GPUプログラム(ラプラシアンカーネル)
2015/07/01GPGPU実践プログラミング70
ブロック内のスレッド数+袖領域分の共有メモ
リを確保
袖領域があるために添字の対応が変化
添字の対応を考えないと,必要なデータを袖領域に置い
てしまう
__syncthreads()を呼んでスレッドを同期
共有メモリにデータが正しく書き込まれた事を保証
__shared__ float sf[1+THREADX+1][1+THREADY+1];
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
tx = threadIdx.x + 1;
ty = threadIdx.y;
ij = i+Ny*j;
sf[tx][ty] = f[ij];
__syncthreads();
f[]
sf[][]
+1](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-69-2048.jpg)
![GPUプログラム(ラプラシアンカーネル)
2015/07/01GPGPU実践プログラミング71
ブロック内のスレッド数+袖領域分の共有メモ
リを確保
袖領域があるために添字の対応が変化
添字の対応を考えないと,必要なデータを袖領域に置い
てしまう
__syncthreads()を呼んでスレッドを同期
共有メモリにデータが正しく書き込まれた事を保証
__shared__ float sf[1+THREADX+1][1+THREADY+1];
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
tx = threadIdx.x + 1;
ty = threadIdx.y + 1;
ij = i+Ny*j;
sf[tx][ty] = f[ij];
__syncthreads();
f[]
sf[][]
+1
+1](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-70-2048.jpg)
![GPUプログラム(ラプラシアンカーネル)
2015/07/01GPGPU実践プログラミング72
袖領域の設定
if(blockIdx.x == 0 && threadIdx.x == 0 ) sf[tx‐1][ty] = sf[tx+1][ty];
if(blockIdx.x != 0 && threadIdx.x == 0 ) sf[tx‐1][ty] = f[i‐1+Nx*j];
if(blockIdx.x == gridDim.x‐1 && threadIdx.x == blockDim.x‐1) sf[tx+1][ty] = sf[tx‐1][ty];
if(blockIdx.x != gridDim.x‐1 && threadIdx.x == blockDim.x‐1) sf[tx+1][ty] = f[i+1+Nx*j];
if(blockIdx.y == 0 && threadIdx.y == 0 ) sf[tx][ty‐1] = sf[tx][ty+1];
if(blockIdx.y != 0 && threadIdx.y == 0 ) sf[tx][ty‐1] = f[i+Nx*(j‐1)];
if(blockIdx.y == gridDim.y‐1 && threadIdx.y == blockDim.y‐1) sf[tx][ty+1] = sf[tx][ty‐1];
if(blockIdx.y != gridDim.y‐1 && threadIdx.y == blockDim.y‐1) sf[tx][ty+1] = f[i+Nx*(j+1)];
__syncthreads();
グローバルメモリにデータがある箇所はグロー
バルメモリから読み込み
グローバルメモリにデータがない箇所は2階微
分が0になるように袖領域の値を決定
ブロックが境界に接しているか否かで処理を切替](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-71-2048.jpg)
![GPUプログラム(ラプラシアンカーネル)
2015/07/01GPGPU実践プログラミング73
共有メモリのデータを利用してラプラシアンを計算
if分岐を排除
f_lap[ij] = (sf[tx‐1][ty ]‐2.0*sf[tx][ty]+sf[tx+1][ty ])/dxdx
+(sf[tx ][ty‐1]‐2.0*sf[tx][ty]+sf[tx ][ty+1])/dydy;
f_lap[]
sf[][]](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-72-2048.jpg)
![2次元的な配列アクセスの優先方向
2015/07/01GPGPU実践プログラミング74
CUDAで2次元的に並列化してアクセ
スする場合
threadIdx.xのスレッド群(threadId
x.yが一定)が連続なメモリアドレスに
アクセス
C言語の多次元配列
2次元目の要素が連続になるようメモリ
に確保
dif2.cuの共有メモリの使い方は不
適切
sf[THREADX+2][THREADY+2]
threadIdx.x
threadIdx.y
THREADX+2
THREADY+2
f[]
Nx
Ny
j
i
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-73-2048.jpg)
![2次元的な配列アクセスの優先方向
2015/07/01GPGPU実践プログラミング75
共有メモリの宣言の変更
1次元目と2次元目を入れ替え
sf[1+THREADX+1][1+THREADY+1]
sf[1+THREADY+1][1+THREADX+1]
配列参照
1次元目の添字はthreadIdx.yを利用
2次元目の添字はthreadIdx.xを利用
threadIdx.xのスレッド群(threadIdx.y
が一定)が連続なメモリアドレスにアクセス
sf[THREADX+2][THREADY+2]
threadIdx.x
threadIdx.y
THREADX+2
THREADY+2
sf[THREADY+2][THREADX+2]
threadIdx.y
threadIdx.x
THREADY+2
THREADX+2](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-74-2048.jpg)
![#define THREADX 16
#define THREADY 16
#define BLOCKX (Nx/THREADX)
#define BLOCKY (Ny/THREADY)
__global__ void laplacian(double *f, double *f_lap){
int i,j,ij;
int tx,ty;
__shared__ float sf[1+THREADX+1][1+THREADY+1];
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
tx = threadIdx.x + 1;
ty = threadIdx.y + 1;
ij = i+Nx*j;
sf[tx][ty] = f[ij];
__syncthreads();
if(blockIdx.x == 0 && threadIdx.x == 0)
sf[tx‐1][ty] = sf[tx+1][ty];
if(blockIdx.x != 0 && threadIdx.x == 0)
sf[tx‐1][ty] = f[i‐1+Nx*j];
if(blockIdx.x == gridDim.x‐1
&& threadIdx.x == blockDim.x‐1)
sf[tx+1][ty] = sf[tx‐1][ty];
if(blockIdx.x != gridDim.x‐1
&& threadIdx.x == blockDim.x‐1)
sf[tx+1][ty] = f[i+1+Nx*j];
if(blockIdx.y == 0 && threadIdx.y == 0)
sf[tx][ty‐1] = sf[tx][ty+1];
if(blockIdx.y != 0 && threadIdx.y == 0)
sf[tx][ty‐1] = f[i+Nx*(j‐1)];
if(blockIdx.y == gridDim.y‐1
&& threadIdx.y == blockDim.y‐1)
sf[tx][ty+1] = sf[tx][ty‐1];
if(blockIdx.y != gridDim.y‐1
&& threadIdx.y == blockDim.y‐1)
sf[tx][ty+1] = f[i+Nx*(j+1)];
__syncthreads();
f_lap[ij]
= (sf[tx‐1][ty ]‐2.0*sf[tx][ty]+sf[tx+1][ty ])/dxdx
+(sf[tx ][ty‐1]‐2.0*sf[tx][ty]+sf[tx ][ty+1])/dydy;
}
GPUプログラム(ラプラシアンカーネル)
2015/07/01GPGPU実践プログラミング76
dif2.cu](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-75-2048.jpg)
![#define THREADX 16
#define THREADY 16
#define BLOCKX (Nx/THREADX)
#define BLOCKY (Ny/THREADY)
__global__ void laplacian(double *f, double *f_lap){
int i,j,ij;
int tx,ty;
__shared__ float sf[1+THREADY+1][1+THREADX+1];
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
tx = threadIdx.x + 1;
ty = threadIdx.y + 1;
ij = i+Nx*j;
sf[ty][tx] = f[ij];
__syncthreads();
if(blockIdx.x == 0 && threadIdx.x == 0)
sf[ty][tx‐1] = sf[ty][tx+1];
if(blockIdx.x != 0 && threadIdx.x == 0)
sf[ty][tx‐1] = f[i‐1+Nx*j];
if(blockIdx.x == gridDim.x‐1
&& threadIdx.x == blockDim.x‐1)
sf[ty][tx+1] = sf[ty][tx‐1];
if(blockIdx.x != gridDim.x‐1
&& threadIdx.x == blockDim.x‐1)
sf[ty][tx+1] = f[i+1+Nx*j];
if(blockIdx.y == 0 && threadIdx.y == 0)
sf[ty‐1][tx] = sf[ty+1][tx];
if(blockIdx.y != 0 && threadIdx.y == 0)
sf[ty‐1][tx] = f[i+Nx*(j‐1)];
if(blockIdx.y == gridDim.y‐1
&& threadIdx.y == blockDim.y‐1)
sf[ty+1][tx] = sf[ty‐1][tx];
if(blockIdx.y != gridDim.y‐1
&& threadIdx.y == blockDim.y‐1)
sf[ty+1][tx] = f[i+Nx*(j+1)];
__syncthreads();
f_lap[ij]
= (sf[ty ][tx‐1]‐2.0*sf[ty][tx]+sf[ty ][tx+1])/dxdx
+(sf[ty‐1][tx ]‐2.0*sf[ty][tx]+sf[ty+1][tx ])/dydy;
}
GPUプログラム(共有メモリの添字を交換
したラプラシアンカーネル)
2015/07/01GPGPU実践プログラミング77
dif3.cu](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-76-2048.jpg)
![ラプラシアンカーネルの実行時間の比較
2015/07/01GPGPU実践プログラミング78
格子分割数 Nx×Ny=2048×2048
1ブロックあたりのスレッド数 16×16
その他カーネルの実行時間
integrate 900s
update 600s
ラブラシアンカーネル 実行時間 [s]
dif1版 1998
dif2版
2286
1900(袖領域の設定を除く)
dif3版
2302
1900(袖領域の設定を除く)](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-77-2048.jpg)

![GPUプログラムの評価
2015/07/01GPGPU実践プログラミング80
if分岐の書き方による実行速度の変化
ブロックとスレッドの条件を同時に記述
Warp内のスレッドが分岐すると実行速度が著しく低下
GPUはブロック単位で分岐,Warp単位で分岐しても実行速度
の低下は抑えられる
上の書き方は最適ではない?
ブロック単位の分岐とスレッド単位の分岐を同時に記述
if(blockIdx.x == 0 && threadIdx.x == 0 ) sf[ty][tx‐1] = sf[ty][tx+1];
if(blockIdx.x != 0 && threadIdx.x == 0 ) sf[ty][tx‐1] = f[i‐1+Nx*j];
if(blockIdx.x == gridDim.x‐1 && threadIdx.x == blockDim.x‐1) sf[ty][tx+1] = sf[ty][tx‐1];
if(blockIdx.x != gridDim.x‐1 && threadIdx.x == blockDim.x‐1) sf[ty][tx+1] = f[i+1+Nx*j];
if(blockIdx.y == 0 && threadIdx.y == 0 ) sf[ty‐1][tx] = sf[ty+1][tx];
if(blockIdx.y != 0 && threadIdx.y == 0 ) sf[ty‐1][tx] = f[i+Nx*(j‐1)];
if(blockIdx.y == gridDim.y‐1 && threadIdx.y == blockDim.y‐1) sf[ty+1][tx] = sf[ty‐1][tx];
if(blockIdx.y != gridDim.y‐1 && threadIdx.y == blockDim.y‐1) sf[ty+1][tx] = f[i+Nx*(j+1)];](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-79-2048.jpg)
![GPUプログラムの評価
2015/07/01GPGPU実践プログラミング81
if分岐の書き方による実行速度の変化
ブロックとスレッドの条件を分け,ifを入れ子に
ブロック単位で分岐した後,スレッド単位で分岐
ブロック単位での分岐による速度低下が抑えられそうな気がする
ブロック単位の分岐を記述する8個のifは2個一組(同じ色の
行)で排他的に分岐
blockIdx.x==0が成立すると,blockIdx!=0は絶対に成立しない
if(blockIdx.x == 0 )if(threadIdx.x == 0 ) sf[ty][tx‐1] = sf[ty][tx+1];
if(blockIdx.x != 0 )if(threadIdx.x == 0 ) sf[ty][tx‐1] = f[i‐1+Nx*j];
if(blockIdx.x == gridDim.x‐1)if(threadIdx.x == blockDim.x‐1) sf[ty][tx+1] = sf[ty][tx‐1];
if(blockIdx.x != gridDim.x‐1)if(threadIdx.x == blockDim.x‐1) sf[ty][tx+1] = f[i+1+Nx*j];
if(blockIdx.y == 0 )if(threadIdx.y == 0 ) sf[ty‐1][tx] = sf[ty+1][tx];
if(blockIdx.y != 0 )if(threadIdx.y == 0 ) sf[ty‐1][tx] = f[i+Nx*(j‐1)];
if(blockIdx.y == gridDim.y‐1)if(threadIdx.y == blockDim.y‐1) sf[ty+1][tx] = sf[ty‐1][tx];
if(blockIdx.y != gridDim.y‐1)if(threadIdx.y == blockDim.y‐1) sf[ty+1][tx] = f[i+Nx*(j+1)];](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-80-2048.jpg)
![GPUプログラムの評価
2015/07/01GPGPU実践プログラミング82
if分岐の書き方による実行速度の変化
2個一組のifの片方をelseに書き換え
2個一組のifにおける条件判断は1回限り
2回ifの条件判断を行うよりは速いような気がする
if(blockIdx.x == 0 ){if(threadIdx.x == 0 ) sf[ty][tx‐1] = sf[ty][tx+1];}
else {if(threadIdx.x == 0 ) sf[ty][tx‐1] = f[i‐1+Nx*j];}
if(blockIdx.x == gridDim.x‐1){if(threadIdx.x == blockDim.x‐1) sf[ty][tx+1] = sf[ty][tx‐1];}
else {if(threadIdx.x == blockDim.x‐1) sf[ty][tx+1] = f[i+1+Nx*j];}
if(blockIdx.y == 0 ){if(threadIdx.y == 0 ) sf[ty‐1][tx] = sf[ty+1][tx];}
else {if(threadIdx.y == 0 ) sf[ty‐1][tx] = f[i+Nx*(j‐1)];}
if(blockIdx.y == gridDim.y‐1){if(threadIdx.y == blockDim.y‐1) sf[ty+1][tx] = sf[ty‐1][tx];}
else {if(threadIdx.y == blockDim.y‐1) sf[ty+1][tx] = f[i+Nx*(j+1)];}](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-81-2048.jpg)
![if分岐の書き方の違いによる実行速度の変化
2015/07/01GPGPU実践プログラミング83
格子分割数 Nx×Ny=2048×2048
1ブロックあたりのスレッド数 16×16
if文の書き方 実行時間 [ms]
ブロックとスレッドの条件
を同時に記述
2.30
ブロックとスレッドの条件
を分け,ifを入れ子に
2.51
2個一組のifの片方を
elseに書き換え
2.35
カーネル1
(共有メモリ不使用)
2.00](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-82-2048.jpg)
![その他の処理の高速化
2015/07/01GPGPU実践プログラミング84
laplacianカーネルとintegrateカーネルの融合
カーネルフュージョン(kernel fusion)
異なる処理を行うカーネルをまとめることでデータを再利用
グローバルメモリへの書き込み,読み出しを回避
__global__ void integrate(double *f, double *f_new){
int i,j,ij;
double f_lap; //ある1点のラプラシアンを計算してレジスタに保存
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
ij= i+Nx*j;
f_lap = ...
f_new[ij] = f[ij] + dt*DIFF*f_lap;
//f[ij]=f[ij]+...とすると,全ての点のf_lapを計算する前にfを更新する可能性がある
}](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-83-2048.jpg)
![その他の処理の高速化
2015/07/01GPGPU実践プログラミング85
値の更新
f_newのデータをfにコピーしているだけ
cudaMemcpyで代用可能
__global__ void update(double *f, double *f_new){
int i,j,ij;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
ij = i+Nx*j;
f[ij] = f_new[ij];
}](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-84-2048.jpg)

![その他の処理の高速化
2015/07/01GPGPU実践プログラミング87
値の更新
ダブルバッファリング(第7回授業参照)でコピーを回避するこ
とも可能
double *dev_f[2];
int in=0;out=1‐in;
cudaMalloc((void **)&dev_f[in ],Nbytes);
cudaMalloc((void **)&dev_f[out],Nbytes);
init<<<Block, Thread>>>(dev_f[in(=0)], dev_f[out(=1)]);
for(n=1;n<=Nt;n++){//n=1
integrate<<<Block, Thread>>>(dev_f[in(=0)],dev_f[out(=1)]);
in = out; out = 1‐in; //in=1, out=0
}](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-86-2048.jpg)
![その他の処理の高速化
2015/07/01GPGPU実践プログラミング88
値の更新
ダブルバッファリング(第7回授業参照)でコピーを回避するこ
とも可能
double *dev_f[2];
int in=0;out=1‐in;
cudaMalloc((void **)&dev_f[in ],Nbytes);
cudaMalloc((void **)&dev_f[out],Nbytes);
init<<<Block, Thread>>>(dev_f[in(=0)], dev_f[out(=1)]);
for(n=1;n<=Nt;n++){//n=2
integrate<<<Block, Thread>>>(dev_f[in(=1)],dev_f[out(=0)]);
in = out; out = 1‐in; //in=0, out=1
}](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-87-2048.jpg)
![その他の処理の高速化
2015/07/01GPGPU実践プログラミング89
値の更新
ダブルバッファリング(第7回授業参照)でコピーを回避するこ
とも可能
dev_f[0]
時刻n
dev_f[1]
時刻n+1
integrate<<<Block, Thread>>>(dev_f[in(=0)],dev_f[out(=1)]);](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-88-2048.jpg)
![その他の処理の高速化
2015/07/01GPGPU実践プログラミング90
値の更新
ダブルバッファリング(第7回授業参照)でコピーを回避するこ
とも可能
dev_f[0]
時刻n+1
dev_f[1]
時刻n
integrate<<<Block, Thread>>>(dev_f[in(=1)],dev_f[out(=0)]);](https://image.slidesharecdn.com/gpgpuprogramming12-160307052540/75/2015-GPGPU-12-89-2048.jpg)























































































