長岡技術科学大学
2015年度先端GPGPUシミュレーション工学特論(全15回,大学院生対象講義)
第4回GPUのメモリ階層の詳細�(共有メモリ)
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
・第1回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180326
・第2回 GPUによる並列計算の概念とメモリアクセス
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59180382
・第3回 GPUプログラム構造の詳細(threadとwarp)
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59180483
・第4回 GPUのメモリ階層の詳細(共有メモリ)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59180572
・第5回 GPUのメモリ階層の詳細(様々なメモリの利用)
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59180652
・第6回 プログラムの性能評価指針(Flop/Byte,計算律速,メモリ律速)
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59180736
・第7回 総和計算(Atomic演算)
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59180844
・第8回 偏微分方程式の差分計算(拡散方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59180918
・第9回 偏微分方程式の差分計算(移流方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59180982
・第10回 Poisson方程式の求解(線形連立一次方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59181031
・第11回 数値流体力学への応用(支配方程式,CPUプログラム)
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59181134
・第12回 数値流体力学への応用(GPUへの移植)
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59181230
・第13回 数値流体力学への応用(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59181316
・第14回 複数GPUの利用
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59181367
・第15回 CPUとGPUの協調
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59181450
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3










![同じメモリ
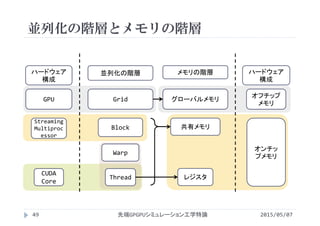
2015/05/07先端GPGPUシミュレーション工学特論11
複数のスレッドがメモリアドレスを共有
複数のスレッドが変数を共有
他のスレッドが書き込んだデータを読むことが可能
共有できるスレッドの範囲はメモリの種類によって変化
//a,b[]がグローバルメモリに確保されている場合*1
__global__ void kernel(...){
int i = blockIdx.x*blockDim.x + threadIdx.x;
:
b[i] = i; //スレッドiが配列要素b[i]に自身のスレッド番号を代入
//b[0,1,...,i‐1,i,...]の値は0,1,...,i‐1,i,...
a = b[i‐1];*2 //スレッドi‐1が書き込んだ値を読み*3,aに代入
: //最後に書き込まれたaの値を全スレッドが共有
} *1 あくまで動作のイメージを説明するための例で正しく実行できない
*2 iが0の場合は考えない
*3 配列bを全スレッドが共有しているので,書き込んだ値以外を読む事が可能](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-11-320.jpg)
![異なるメモリ
2015/05/07先端GPGPUシミュレーション工学特論12
メモリアドレスが共有できず,一つのスレッドのみが
そのメモリアドレスにアクセス
あるスレッドが宣言した変数へアクセスできない
//a,b[]がレジスタに確保されている場合*1
__global__ void kernel(...){
int i = blockIdx.x*blockDim.x + threadIdx.x;
:
b[i] = i; //スレッドiが配列要素b[i]に自身のスレッド番号を代入
//b[0,1,...,i‐1,i,...]の値はb[i]以外不定
a = b[i‐1];*2 //b[i‐1]の値(不定)をaに代入*3
: //aの値はスレッドによって異なる
} *1 あくまで動作のイメージを説明するための例で正しく実行できない
*2 iが0の場合は考えない
*3 配列bは他のスレッドからアクセスできないため,代入した値以外は不定のまま](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-12-320.jpg)













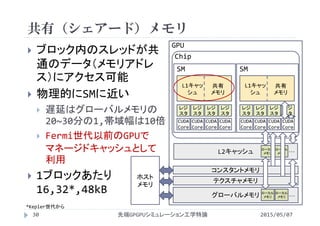
![共有(シェアード)メモリ
修飾子 __shared__ を付けて宣言
データをブロック内で共有するために同期を取る
共有メモリ上でデータを変更してもグローバルメモリ
には反映されない
グローバルメモリへの書き戻しが必要
2015/05/07先端GPGPUシミュレーション工学特論31
__global__ void kernel(flaot *a){
__shared__ float shared_a[NT];//NTはスレッド数
int i = blockDim.x*blockIdx.x + theadIdx.x;
shared_a[threadIdx.x] = a[i];
__syncthreads();
//共有メモリを使った処理
__syncrthreads();
a[i] = shared_a[threadIdx.x];
}](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-31-320.jpg)
![共有(シェアード)メモリ利用のイメージ
2015/05/07先端GPGPUシミュレーション工学特論32
a[i]
a[i]
shared_a[tx]
i= 0 1 2 3 4 5 6 7
tx=threadIdx.x= 0 1 2 3 0 1 2 3
tx= 0 1 2 3 0 1 2 3
ブロック内で同期
共有メモリを使った処理
shared_a[tx]
blockIdx.x=0 blockIdx.x=1
共有メモリを使った処理
一つのブロック内
で使用する分のみ
を確保
同期を取り,共有
メモリ内に正しく
データが入ってい
ることを保証ブロック内で同期
処理の流れ](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-32-320.jpg)

![共有(シェアード)メモリの宣言
修飾子 __shared__ を付けて宣言
配列として宣言
要素数を静的(コンパイル時)に決定する場合
__shared__ 型 変数名[要素数]
多次元配列も宣言可能(1,2,3次元)
要素数を動的(カーネル実行時)に決定する場合
extern __shared__ 型 変数名[]
メモリサイズをカーネル呼出時のパラメータで指定
<<<ブロック数,スレッド数,共有メモリのサイズ>>>
2015/05/07先端GPGPUシミュレーション工学特論34
=要素数*sizeof(共有メモリの型)](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-34-320.jpg)














![配列(画像や行列)の転置
2015/05/07先端GPGPUシミュレーション工学特論52
2次元配列の転置
out[j][i] = in[i][j]
in[][] out[][]
Ny
Nx
Nx
Ny](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-52-320.jpg)
![配列(画像や行列)の転置
2015/05/07先端GPGPUシミュレーション工学特論53
1次元配列に保存されたデータの転置
out[i*Ny+j] = in[j*Nx+i]
Ny
Nx
Nx
Ny
in[] out[]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-53-320.jpg)
![#include<stdio.h>
#include<stdlib.h>
#define Nx 4096
#define Ny 2048
#define Nbytes (Nx*Ny*sizeof(int))
void init(int *in, int *out){
int i,j;
for(i=0; i<Nx; i++){
for(j=0; j<Ny; j++){
in[i*Ny + j] = j;
out[i*Ny + j] = ‐1;
}
}
}
void transpose(int *in, int *out){
int i,j;
for(i=0; i<Nx; i++){
for(j=0; j<Ny; j++){
out[j*Nx+i] = in[i*Ny+j];
}
}
}
int main(){
int *in,*out;
in = (int *)malloc(Nbytes);
out = (int *)malloc(Nbytes);
init(in,out);
transpose(in,out);
return 0;
}
CPUプログラム
2015/05/07先端GPGPUシミュレーション工学特論54
transpose.c](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-54-320.jpg)

![1スレッドが書き込む配列要素の決定
2015/05/07先端GPGPUシミュレーション工学特論57
グローバルメモリへの書込は,読込の際に設定した
ブロックやスレッドの配置に制限されない
スレッド番号と配列添字を対応付ける便宜的な概念
in[ij] out[ij]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-57-320.jpg)
![#include<stdio.h>
#define Nx 4096
#define Ny 2048
#define Nbytes (Nx*Ny*sizeof(int))
#define Tx 16
#define Ty 16
__global__
void init(int *in, int *out){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
int j = blockIdx.y*blockDim.y
+ threadIdx.y;
in[i*Ny + j] = j;
out[i*Ny + j] = ‐1;
}
__global__
void transpose(int *in, int *out){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
int j = blockIdx.y*blockDim.y
+ threadIdx.y;
out[j*Nx + i] = in[i*Ny + j];
}
int main(){
int *in,*out;
dim3 Thread(Tx,Ty,1),
Block(Nx/Tx,Ny/Ty,1);
cudaMalloc((void**)&in,Nbytes);
cudaMalloc((void**)&out,Nbytes);
init<<<Block, Thread>>>(in,out);
transpose<<<Block, Thread>>>
(in,out);
return 0;
}
GPUプログラム
2015/05/07先端GPGPUシミュレーション工学特論58
simple_transpose.cu](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-58-320.jpg)
![2次元的な配列アクセスの優先方向
2015/05/07先端GPGPUシミュレーション工学特論59
x, yのどちらをメモリが連続な方向とするか
threadIdx.xが連続な方向にアクセスする場合
(0,0)(1,0)(2,0)(3,0)(0,0)
(3,3) (3,3)
(0,1)(1,1)(2,1)(3,1)
(0,2)(1,2)(2,2)(3,2)
(0,3)(1,3)(2,3)(3,3) (3,3)
(0,0) (0,0)
block(0,0) block(1,0)
threadIdx.x=0~15,
threadIdx.y=0
threadIdx.x=0~15,
threadIdx.y=1
...
[i][j]=[j*Nx+i]
メモリが連続な方向
threadIdx.y
threadIdx.x](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-59-320.jpg)
![2次元的な配列アクセスの優先方向
2015/05/07先端GPGPUシミュレーション工学特論60
x, yのどちらをメモリが連続な方向とするか
threadIdx.yが連続な方向にアクセスする場合
(0,0)(1,0)(2,0)(3,0)(0,0)
(3,3) (3,3)
(0,1)(1,1)(2,1)(3,1)
(0,2)(1,2)(2,2)(3,2)
(0,3)(1,3)(2,3)(3,3) (3,3)
(0,0) (0,0)
block(0,0) block(1,0)
threadIdx.x=0,
threadIdx.y=0~15
threadIdx.x=1,
threadIdx.y=0~15
...
[i][j]=[i*Ny+j]
メモリが連続な方向
threadIdx.y
threadIdx.x](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-60-320.jpg)
![#include<stdio.h>
#define Nx 4096
#define Ny 2048
#define Nbytes (Nx*Ny*sizeof(int))
#define Tx 16
#define Ty 16
__global__
void init(int *in, int *out){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
int j = blockIdx.y*blockDim.y
+ threadIdx.y;
in[i*Ny + j] = j;
out[i*Ny + j] = ‐1;
}
__global__
void copy(int *in, int *out){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
int j = blockIdx.y*blockDim.y
+ threadIdx.y;
out[j*Nx + i] = in[j*Nx + i];
out[i*Ny + j] = in[i*Ny + j];
}
int main(){
int *in,*out;
dim3 Thread(Tx,Ty,1),
Block(Nx/Tx,Ny/Ty,1);
cudaMalloc((void**)&in,Nbytes);
cudaMalloc((void**)&out,Nbytes);
init<<<Block, Thread>>>(in,out);
copy<<<Block, Thread>>>(in,out);
return 0;
}
2次元的な配列アクセスの優先方向
2015/05/07先端GPGPUシミュレーション工学特論61
simple_copy.cu
どちらが高速?](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-61-320.jpg)
![実行時間
2015/05/07先端GPGPUシミュレーション工学特論62
入力配列サイズ Nx×Ny = 4096×2048
スレッド数 Tx×Ty = 16×16
カーネル 実行時間 [ms]
copy(目標値) 0.802 / 1.57](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-62-320.jpg)
![2次元的な配列アクセスの優先方向
2015/05/07先端GPGPUシミュレーション工学特論63
2次元配列の場合
in[][],out[][]
Nx
Ny
j
i
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i][j]=in[i][j];
for(j=0;j<Ny;j++)
for(i=0;i<Nx;i++)
out[i][j]=in[i][j];](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-63-320.jpg)
![2次元的な配列アクセスの優先方向
2015/05/07先端GPGPUシミュレーション工学特論64
2次元配列の場合
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i][j]=in[i][j];
in[][],out[][]
Nx
Ny
j
i
for(j=0;j<Ny;j++)
for(i=0;i<Nx;i++)
out[i][j]=in[i][j];](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-64-320.jpg)
![2次元的な配列アクセスの優先方向
2015/05/07先端GPGPUシミュレーション工学特論65
2次元配列の1次元配列的表現(前回資料参照)
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i][j]=in[i][j];
in[],out[]
Nx
Ny
j
i
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i*Ny+j]=
in[i*Ny+j];](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-65-320.jpg)
![2次元的な配列アクセスの優先方向
2015/05/07先端GPGPUシミュレーション工学特論66
CUDAで2次元的に並列化してアクセスする場合
i = blockIdx.x*blockDim.x
+ threadIdx.x;
j = blockIdx.y*blockDim.y
+ threadIdx.y;
out[j*Nx+i]=in[j*Nx+i];
in[],out[]
Nx
Ny
j
i
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i*Ny+j]=
in[i*Ny+j];
threadIdx.x
threadIdx.y
threadIdx.xのスレッド群(threadIdx.yが一定)
が連続なメモリアドレスにアクセス](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-66-320.jpg)
![#include<stdio.h>
#define Nx 4096
#define Ny 2048
#define Nbytes (Nx*Ny*sizeof(int))
#define Tx 16
#define Ty 16
__global__
void init(int *in, int *out){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
int j = blockIdx.y*blockDim.y
+ threadIdx.y;
in[j*Nx + i] = j;
out[j*Nx + i] = ‐1;
}
__global__
void transpose(int *in, int *out){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
int j = blockIdx.y*blockDim.y
+ threadIdx.y;
out[i*Ny + j] = in[j*Nx + i];
}
int main(){
int *in,*out;
dim3 Thread(Tx,Ty,1),
Block(Nx/Tx,Ny/Ty,1);
cudaMalloc((void**)&in,Nbytes);
cudaMalloc((void**)&out,Nbytes);
init<<<Block, Thread>>>(in,out);
transpose<<<Block, Thread>>>
(in,out);
return 0;
}
GPUプログラム
2015/05/07先端GPGPUシミュレーション工学特論67
transpose.cu](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-67-320.jpg)
![実行時間
2015/05/07先端GPGPUシミュレーション工学特論68
入力配列サイズ Nx×Ny = 4096×2048
スレッド数 Tx×Ty = 16×16
カーネル 実行時間 [ms]
copy(目標値) 0.802 / 1.57
transpose 1.34](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-68-320.jpg)
![転置時のメモリアクセス
2015/05/07先端GPGPUシミュレーション工学特論69
読込はコアレスアクセス
書込はストライドアクセス
キャッシュはメモリアクセスの改善には利用できない
in[]
out[]
out[i*Ny + j] = in[j*Nx + i];
・・・ ・・・ ・・・ ・・・ ・・・ ・・・ ・・・
・・・ ・・・ ・・・ ・・・ ・・・ ・・・ ・・・
Ny*sizeof(int)バイトの
ストライドアクセス](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-69-320.jpg)
![転置時のメモリアクセス
2015/05/07先端GPGPUシミュレーション工学特論70
読込はコアレスアクセス
書込は非コアレスアクセス
キャッシュはメモリアクセスの改善には利用できない
in[] out[]
threadIdx.xの群が連続
なメモリアドレスにアクセス
out[i*Ny + j] = in[j*Nx + i];
Ny
Nx
Nx
Ny
threadIdx.yの群が連続
なメモリアドレスにアクセス
threadIdx.y
threadIdx.y
threadIdx.x
threadIdx.x](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-70-320.jpg)
![in[]
共有メモリによるメモリアクセスの改善
2015/05/07先端GPGPUシミュレーション工学特論71
共有メモリは制約が緩い
一度グローバルメモリから共有メモリにコピー
ここは元々コアレスアクセス
out[]
threadIdx.y
threadIdx.x
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-71-320.jpg)
![in[]
共有メモリによるメモリアクセスの改善
2015/05/07先端GPGPUシミュレーション工学特論72
共有メモリは制約が緩い
共有メモリ内で転置
共有メモリからグローバルメモリへコアレスアクセス
out[]
threadIdx.y
threadIdx.x
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-72-320.jpg)
![グローバルメモリから共有メモリへの書込
2015/05/07先端GPGPUシミュレーション工学特論73
__shared__ int data[Tx][Ty]; //ブロック内のスレッドが使うサイズだけ宣言
int i = blockIdx.x*blockDim.x + threadIdx.x; //配列添字とスレッド番号の
int j = blockIdx.y*blockDim.y + threadIdx.y; //対応を計算
原点からのズレ
//グローバルメモリから共有メモリへコピー(コアレスアクセス)
data[threadIdx.x][threadIdx.y] = in[j*Nx + i];
__syncthreads(); //ブロック内の全スレッドがコピーを完了するのを待機
(0,0)
(0,1)
(0,2)
(0,3)
(1,0)
(1,1)
(1,2)
(1,3)
(2,0)
(2,1)
(2,2)
(2,3)
(3,0)
(3,1)
(2,3)
(3,3)
(0,0)
(1,0)
(2,0)
(3,0)
(0,1)
(1,1)
(2,1)
(3,1)
(0,2)
(1,2)
(2,2)
(3,2)
(0,3)
(1,3)
(2,3)
(3,3)
グローバルメモリから読み
込んだデータをそのまま共
有メモリへ書込み
blockIdx.x*blockDim.x=1*4
blockIdx.y*blockDim.y=0*4
threadIdx.x
threadIdx.y
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-73-320.jpg)
![共有メモリからグローバルメモリへの書込
2015/05/07先端GPGPUシミュレーション工学特論74
i = blockIdx.y*blockDim.y + threadIdx.x;
j = blockIdx.x*blockDim.x + threadIdx.y;
原点からのズレ
配列out[]の横幅(コピー時の書き方out[j*Nx + i] = in[j*Nx + i];と同じ)
out[j*Ny + i] = data[threadIdx.y][threadIdx.x];
(0,0)(1,0)(2,0)(3,0)
(0,1)(1,1)(2,1)(3,1)
(0,2)(1,2)(2,2)(3,2)
(0,3)(1,3)(2,3)(3,3)
(0,0)
(1,0)
(2,0)
(3,0)
(0,1)
(1,1)
(2,1)
(3,1)
(0,2)
(1,2)
(2,2)
(3,2)
(0,3)
(1,3)
(2,3)
(3,3)
各スレッドが共有メモリへ
アクセスする位置を転置
blockIdx.y*blockDim.y=0*4
blockIdx.x*blockDim.x=1*4
Ny
threadIdx.x
threadIdx.y
threadIdx.y
threadIdx.x
threadIdx.x,
threadIdx.y が
参照する次元が
入れ替わっている](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-74-320.jpg)
![__global__ void transpose_shared(int *in, int *,out){
__shared__ int data[Tx][Ty]; //ブロック内のスレッドが使うサイズだけ宣言
int i = blockIdx.x*blockDim.x + threadIdx.x; //配列添字とスレッド番号の
int j = blockIdx.y*blockDim.y + threadIdx.y; //対応を計算
//グローバルメモリから共有メモリへコピー(コアレスアクセス)
data[threadIdx.x][threadIdx.y] = in[j*Nx + i];
__syncthreads(); //ブロック内の全スレッドがコピーを完了するのを待機
i = blockIdx.y*blockDim.y + threadIdx.x;
j = blockIdx.x*blockDim.x + threadIdx.y;
out[j*Ny + i] = data[threadIdx.y][threadIdx.x];
}
共有メモリを利用するカーネル
2015/05/07先端GPGPUシミュレーション工学特論75
transpose_shared.cu](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-75-320.jpg)
![実行時間
2015/05/07先端GPGPUシミュレーション工学特論76
入力配列サイズ Nx×Ny = 4096×2048
スレッド数 Tx×Ty = 16×16
1.4倍
高速化*
*高速化率=基準となる実行時間/高速化したカーネルによる実行時間
カーネル 実行時間 [ms]
copy(目標値) 0.802 / 1.57
transpose 1.34
transpose_shared 0.977](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-76-320.jpg)
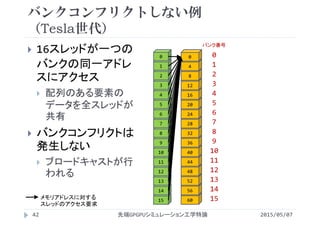
![2次元配列におけるバンクコンフリクト
(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論77
転置の計算
共有メモリにアクセス
する添字が入れ替わる
読込か書込のどちらか
でバンクコンフリクトが
発生
124
120
116
112
108
104
100
96
92
88
84
80
76
72
68
64
188
184
180
176
172
164
160
160
156
152
148
144
140
136
132
128
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
60
56
52
48
44
40
36
32
28
24
20
16
12
8
4
0
256
252
248
244
240
236
232
228
224
220
216
208
204
200
196
192
data[16][16]
・・・
Half Warp内でのスレッドID メモリアドレス
0
2
3
5
1
6
8
14
4
7
9
15
10
11
12
13
バンク番号](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-77-320.jpg)
![124
120
116
112
108
104
100
96
92
88
84
80
76
72
68
64
188
184
180
176
172
164
160
160
156
152
148
144
140
136
132
128
60
56
52
48
44
40
36
32
28
24
20
16
12
8
4
0
256
252
248
244
240
236
232
228
224
220
216
208
204
200
196
192
2次元配列におけるバンクコンフリクト
(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論78
transpose_shared.
cuの場合
読込のアクセス
書込のアクセス
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
メモリアドレスに対する
スレッドのアクセス要求
0
2
3
5
1
6
8
14
4
7
9
15
10
11
12
13
バンク番号
//16‐wayバンクコンフリクト
data[threadIdx.x][threadIdx.y]
・・・
バンク
コンフリクト
data[threadIdx.x][0]
data[threadIdx.y][threadIdx.x]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-78-320.jpg)
![124
120
116
112
108
104
100
96
92
88
84
80
76
72
68
188
184
180
176
172
164
160
160
156
152
148
144
140
136
132
60
56
52
48
44
40
36
32
28
24
20
16
12
8
4
256
252
248
244
240
236
232
228
224
220
216
208
204
200
196
2次元配列におけるバンクコンフリクト
(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論79
transpose_shared.
cuの場合
読込のアクセス
書込のアクセス
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
メモリアドレスに対する
スレッドのアクセス要求
0
2
3
5
1
6
8
14
4
7
9
15
10
11
12
13
バンク番号
//16‐wayバンクコンフリクト
data[threadIdx.x][threadIdx.y]
・・・
バンク
コンフリクト
data[threadIdx.y][threadIdx.x]
64 1280 192
data[threadIdx.x][1]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-79-320.jpg)
![124
120
116
112
108
104
100
96
92
88
84
80
76
72
68
64
188
184
180
176
172
164
160
160
156
152
148
144
140
136
132
128
60
56
52
48
44
40
36
32
28
24
20
16
12
8
4
0
256
252
248
244
240
236
232
228
224
220
216
208
204
200
196
192
2次元配列におけるバンクコンフリクト
(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論80
transpose_shared.
cuの場合
読込のアクセス
書込のアクセス
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
メモリアドレスに対する
スレッドのアクセス要求
0
2
3
5
1
6
8
14
4
7
9
15
10
11
12
13
バンク番号
data[threadIdx.x][threadIdx.y]
・・・
data[0][threadIdx.x]
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-80-320.jpg)
![124
120
116
112
108
104
100
96
92
88
84
80
76
72
68
188
184
180
176
172
164
160
160
156
152
148
144
140
136
132
60
56
52
48
44
40
36
32
28
24
20
16
12
8
4
256
252
248
244
240
236
232
228
224
220
216
208
204
200
196
2次元配列におけるバンクコンフリクト
(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論81
transpose_shared.
cuの場合
読込のアクセス
書込のアクセス
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
メモリアドレスに対する
スレッドのアクセス要求
0
2
3
5
1
6
8
14
4
7
9
15
10
11
12
13
バンク番号
・・・
64 1280 192
data[1][threadIdx.x]
data[threadIdx.x][threadIdx.y]
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-81-320.jpg)
![バンクコンフリクトの低減(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論82
解消は非常に簡単
配列を余分に確保してバ
ンクをずらす
data[16][16]
data[16__][16__]
210
15
14
13
12
11
10
9
8
7
6
5
4
3
2
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1 1
0 0
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
…
メモリアドレスに対する
スレッドのアクセス要求
バンク番号](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-82-320.jpg)
![バンクコンフリクトの低減(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論83
解消は非常に簡単
配列を余分に確保してバ
ンクをずらす
data[16][16]
data[16 ][16+1]
配列を余分に確保するこ
とをパディング(詰め物)
するという
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
…
210
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-83-320.jpg)
![1 2 30
バンクコンフリクトの低減(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論84
メモリパディングをした
場合
読込のアクセス
書込のアクセス
・・・
メモリアドレスに対する
スレッドのアクセス要求
//コンフリクトフリー
data[threadIdx.x][threadIdx.y]
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
2
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
data[threadIdx.x][0]
data[threadIdx.y][threadIdx.x]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-84-320.jpg)
![バンクコンフリクトの低減(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論85
メモリパディングをした
場合
読込のアクセス
書込のアクセス
メモリアドレスに対する
スレッドのアクセス要求 1 2 30
・・・
//コンフリクトフリー
data[threadIdx.x][threadIdx.y]
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
2
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
data[threadIdx.x][1]
data[threadIdx.y][threadIdx.x]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-85-320.jpg)
![バンクコンフリクトの低減(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論86
メモリパディングをした
場合
読込のアクセス
書込のアクセス
メモリアドレスに対する
スレッドのアクセス要求 1 2 30
・・・
data[threadIdx.x][threadIdx.y]
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
2
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
data[0][threadIdx.x]
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-86-320.jpg)
![バンクコンフリクトの低減(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論87
メモリパディングをした
場合
読込のアクセス
書込のアクセス
メモリアドレスに対する
スレッドのアクセス要求 1 2 30
・・・
data[threadIdx.x][threadIdx.y]
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
2
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
2
1
0
15
14
13
12
11
10
9
8
7
6
5
4
3
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
data[1][threadIdx.x]
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-87-320.jpg)
![2次元配列におけるバンクコンフリクト
(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論88
バンクの数が32に増加
配列要素数に応じてバンクが折りたたまれる
配列の2次元の要素数とバンクの数が同じ場合
0
12
8
25
6
38
4
0 1 2 3
16
14
4
27
2
40
0
4 5 6 7
32
16
0
28
8
41
6
8 9 10 11
48
17
6
30
4
43
2
12 13 14 15
data[8][32]
…
data[0][32]
data[1][32]
data[2][32]
data[3][32]
64
19
2
32
0
44
8
16 17 18 19
80
20
8
33
6
46
4
20 21 22 23
96
22
4
35
2
48
0
24 25 26 27
11
2
24
0
35
8
49
6
28 29 30 31
メモリアドレス
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
バンク番号
Warp内でのスレッドID](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-88-320.jpg)
![2次元配列におけるバンクコンフリクト
(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論89
バンクの数が32に増加
配列要素数に応じてバンクが折りたたまれる
配列の2次元の要素数とバンクの数が異なる場合
…
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
0
12
8
64
19
2
16
14
4
80
20
8
32
16
0
96
22
4
48
17
6
11
2
24
0
data[0][16]
data[1][16]
data[2][16]
data[3][16]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-89-320.jpg)
![16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2次元配列におけるバンクコンフリクト
(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論90
バンクの数が32に増加
配列要素数に応じてバンクが折りたたまれる
配列の2次元の要素数とバンクの数が異なる場合
…
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
data[2][16]
data[3][16]
バンク番号](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-90-320.jpg)

![16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2次元配列におけるバンクコンフリクト
(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論92
バンクの数が32に増加
配列要素数に応じてバンクが折りたたまれる
配列の2次元の要素数とバンクの数が異なる場合
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
コンフリクトフリー
…](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-92-320.jpg)
![16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2次元配列におけるバンクコンフリクト
(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論93
転置の計算
共有メモリにアクセスする添字が入れ替わる
読込か書込のどちらかでバンクコンフリクトが発生
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
…](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-93-320.jpg)
![16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2次元配列におけるバンクコンフリクト
(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論94
transpose_shared.cuの場合
読込のアクセス
書込のアクセス
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
//8‐wayバンクコンフリクト
data[threadIdx.x][threadIdx.y]
data[threadIdx.y][threadIdx.x]
…
data[threadIdx.x][0] data[threadIdx.x][1]
バンク
コンフリクト
バンク
コンフリクト
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-94-320.jpg)
![16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2次元配列におけるバンクコンフリクト
(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論95
transpose_shared.cuの場合
読込のアクセス
書込のアクセス
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
//8‐wayバンクコンフリクト
data[threadIdx.x][threadIdx.y]
…
data[threadIdx.x][2] data[threadIdx.x][3]
バンク
コンフリクト
バンク
コンフリクト
data[threadIdx.y][threadIdx.x]
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-95-320.jpg)
![16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2次元配列におけるバンクコンフリクト
(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論96
transpose_shared.cuの場合
読込のアクセス
書込のアクセス
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
data[threadIdx.x][threadIdx.y]
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]
…
data[0][threadIdx.x] data[1][threadIdx.x]
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-96-320.jpg)
![16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
2次元配列におけるバンクコンフリクト
(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論97
transpose_shared.cuの場合
読込のアクセス
書込のアクセス
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
data[threadIdx.x][threadIdx.y]
…
data[2][threadIdx.x] data[3][threadIdx.x]
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-97-320.jpg)
![バンクコンフリクトの低減(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論98
配列を余分に確保してバンクをずらす
data[16][16]
data[16][16+1]
data[16][17]
0 16 32 48 64
追加分の配列要素
80 96 11
2
12
8
14
4
16
0
17
6
19
2
20
8
22
4
24
0
25
6
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
…
data[0][17]
data[1][17]
data[2][17]
data[3][17]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-98-320.jpg)
![19 20 21 22 23 24 25 26 27 28 29 30 31 0 1
17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
バンクコンフリクトの低減(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論99
配列を余分に確保してバンクをずらす
data[16][16]
data[16][16+1]
data[16][17]
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
1 2 3
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
…
data[0][17]
data[1][17]
data[2][17]
data[3][17]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-99-320.jpg)
![19 20 21 22 23 24 25 26 27 28 29 30 31 0 11 2 3
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
バンクコンフリクトの低減(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論100
メモリパディングをした場合
読込のアクセス
書込のアクセス
//コンフリクトフリー
data[threadIdx.x][threadIdx.y]
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][17]
data[0][17]
data[1][17]
data[2][17]
data[3][17]
data[threadIdx.x][0] data[threadIdx.x][1]
…
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
threadIdx.x
threadIdx.y
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1
data[threadIdx.y][threadIdx.x]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-100-320.jpg)
![19 20 21 22 23 24 25 26 27 28 29 30 31 0 11 2 3
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
バンクコンフリクトの低減(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論101
メモリパディングをした場合
読込のアクセス
書込のアクセス
//コンフリクトフリー
data[threadIdx.x][threadIdx.y]
data[threadIdx.y][threadIdx.x]
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][17]
data[0][17]
data[1][17]
data[2][17]
data[3][17]
data[threadIdx.x][2] data[threadIdx.x][3]
…
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
threadIdx.x
threadIdx.y
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-101-320.jpg)
![19 20 21 22 23 24 25 26 27 28 29 30 31 0 11 2 3
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
バンクコンフリクトの低減(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論102
メモリパディングをした場合
読込のアクセス
書込のアクセス
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][17]
data[0][17]
data[1][17]
data[2][17]
data[3][17]
data[threadIdx.x][threadIdx.y]
//2‐wayバンクコンフリクト
data[threadIdx.y][threadIdx.x]
data[0][threadIdx.x] data[1][threadIdx.x]
…
バンク
コンフリクト
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
threadIdx.x
threadIdx.y
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-102-320.jpg)
![19 20 21 22 23 24 25 26 27 28 29 30 31 0 11 2 3
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 1
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
バンクコンフリクトの低減(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論103
メモリパディングをした場合
読込のアクセス
書込のアクセス
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][17]
data[0][17]
data[1][17]
data[2][17]
data[3][17]
data[threadIdx.x][threadIdx.y]
//2‐wayバンクコンフリクト
data[threadIdx.y][threadIdx.x]
data[2][threadIdx.x] data[3][threadIdx.x]
…
バンク
コンフリクト
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
threadIdx.x
threadIdx.y
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-103-320.jpg)
![__global__ void transpose_reducebankconflict(int *in, int *,out){
__shared__ int data[Tx][Ty+1]; //バンクコンフリクトを回避
int i = blockIdx.x*blockDim.x + threadIdx.x; //配列添字とスレッド番号の
int j = blockIdx.y*blockDim.y + threadIdx.y; //対応を計算
//グローバルメモリから共有メモリへコピー(コアレスアクセス)
data[threadIdx.x][threadIdx.y] = in[j*Nx + i];
__syncthreads(); //ブロック内の全スレッドがコピーを完了するのを待機
i = blockIdx.y*blockDim.y + threadIdx.x;
j = blockIdx.x*blockDim.x + threadIdx.y;
out[j*Ny + i] = data[threadIdx.y][threadIdx.x];
}
バンクコンフリクトを低減したカーネル
2015/05/07先端GPGPUシミュレーション工学特論104
transpose_reducebankconflict.cu](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-104-320.jpg)
![実行時間
2015/05/07先端GPGPUシミュレーション工学特論105
入力配列サイズ Nx×Ny = 4096×2048
スレッド数 Tx×Ty = 16×16
1.1倍
高速化*
カーネル 実行時間 [ms]
copy(目標値) 0.802 / 1.57
transpose 1.34
transpose_shared 0.977
transpose_reducebankconflict 0.926
*高速化率=基準となる実行時間/高速化したカーネルによる実行時間](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-105-320.jpg)
![2次元的な配列アクセスの優先方向
2015/05/07先端GPGPUシミュレーション工学特論106
CUDAで2次元的に並列化してアク
セスする場合
threadIdx.xのスレッド群(threadI
dx.yが一定)が連続なメモリアドレス
にアクセス
C言語の多次元配列
2次元目の要素が連続になるようメモ
リに確保
transpose_shared.cuの共有メ
モリの使い方は不適切
in[],out[]
Nx
Ny
j
i
threadIdx.x
threadIdx.y
data[Tx][Ty]
Tx
Ty
j
i
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-106-320.jpg)
![2次元的な配列アクセスの優先方向
2015/05/07先端GPGPUシミュレーション工学特論107
共有メモリの宣言の変更
1次元目と2次元目を入れ替え
data[Tx][Ty]
data[Ty][Tx]
配列参照
1次元目の添字はthreadIdx.yを利用
2次元目の添字はthreadIdx.xを利用
threadIdx.xのスレッド群(threadIdx.
yが一定)が連続なメモリアドレスにアク
セス
data[Tx][Ty]
Tx
Ty
j
i
threadIdx.x
threadIdx.y
data[Ty][Tx]
Ty
Tx
i
j
threadIdx.y
threadIdx.x](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-107-320.jpg)
![__global__ void transpose_shared(int *in, int *,out){
__shared__ int data[Tx][Ty]; //ブロック内のスレッドが使うサイズだけ宣言
int i = blockIdx.x*blockDim.x + threadIdx.x; //配列添字とスレッド番号の
int j = blockIdx.y*blockDim.y + threadIdx.y; //対応を計算
//グローバルメモリから共有メモリへコピー(コアレスアクセス)
data[threadIdx.x][threadIdx.y] = in[j*Nx + i];
__syncthreads(); //ブロック内の全スレッドがコピーを完了するのを待機
i = blockIdx.y*blockDim.y + threadIdx.x;
j = blockIdx.x*blockDim.x + threadIdx.y;
out[j*Ny + i] = data[threadIdx.y][threadIdx.x];
}
共有メモリを利用するカーネル
2015/05/07先端GPGPUシミュレーション工学特論108
transpose_shared.cu](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-108-320.jpg)
![__global__ void transpose_shared(int *in, int *,out){
__shared__ int data[Ty][Tx]; //ブロック内のスレッドが使うサイズだけ宣言
int i = blockIdx.x*blockDim.x + threadIdx.x; //配列添字とスレッド番号の
int j = blockIdx.y*blockDim.y + threadIdx.y; //対応を計算
//グローバルメモリから共有メモリへコピー(コアレスアクセス)
data[threadIdx.y][threadIdx.x] = in[j*Nx + i];
__syncthreads(); //ブロック内の全スレッドがコピーを完了するのを待機
i = blockIdx.y*blockDim.y + threadIdx.x;
j = blockIdx.x*blockDim.x + threadIdx.y;
out[j*Ny + i] = data[threadIdx.x][threadIdx.y];
}
共有メモリの添字を交換したカーネル
2015/05/07先端GPGPUシミュレーション工学特論109
transpose_shared_indexchange.cu](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-109-320.jpg)
![124
120
116
112
108
104
100
96
92
88
84
80
76
72
68
64
188
184
180
176
172
164
160
160
156
152
148
144
140
136
132
128
60
56
52
48
44
40
36
32
28
24
20
16
12
8
4
0
256
252
248
244
240
236
232
228
224
220
216
208
204
200
196
192
配列添字を入れ替えた場合の共有メモリへ
のアクセス(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論110
配列添字を入れ替え
た場合
読込のアクセス
書込のアクセス
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
メモリアドレスに対する
スレッドのアクセス要求
0
2
3
5
1
6
8
14
4
7
9
15
10
11
12
13
バンク番号
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]
・・・
data[0][threadIdx.x]
data[threadIdx.x][threadIdx.y]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-110-320.jpg)
![124
120
116
112
108
104
100
96
92
88
84
80
76
72
68
188
184
180
176
172
164
160
160
156
152
148
144
140
136
132
60
56
52
48
44
40
36
32
28
24
20
16
12
8
4
256
252
248
244
240
236
232
228
224
220
216
208
204
200
196
配列添字を入れ替えた場合の共有メモリへ
のアクセス(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論111
配列添字を入れ替え
た場合
読込のアクセス
書込のアクセス
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
メモリアドレスに対する
スレッドのアクセス要求
0
2
3
5
1
6
8
14
4
7
9
15
10
11
12
13
バンク番号
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]
・・・
data[threadIdx.x][threadIdx.y]
64 1280 192
data[1][threadIdx.x]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-111-320.jpg)
![124
120
116
112
108
104
100
96
92
88
84
80
76
72
68
64
188
184
180
176
172
164
160
160
156
152
148
144
140
136
132
128
60
56
52
48
44
40
36
32
28
24
20
16
12
8
4
0
256
252
248
244
240
236
232
228
224
220
216
208
204
200
196
192
配列添字を入れ替えた場合の共有メモリへ
のアクセス(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論112
配列添字を入れ替え
た場合
読込のアクセス
書込のアクセス
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
メモリアドレスに対する
スレッドのアクセス要求
0
2
3
5
1
6
8
14
4
7
9
15
10
11
12
13
バンク番号
data[threadIdx.y][threadIdx.x]
・・・
data[threadIdx.x][0]
//16‐wayバンクコンフリクト
data[threadIdx.x][threadIdx.y]
バンク
コンフリクト](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-112-320.jpg)
![124
120
116
112
108
104
100
96
92
88
84
80
76
72
68
188
184
180
176
172
164
160
160
156
152
148
144
140
136
132
60
56
52
48
44
40
36
32
28
24
20
16
12
8
4
256
252
248
244
240
236
232
228
224
220
216
208
204
200
196
配列添字を入れ替えた場合の共有メモリへ
のアクセス(Tesla世代)
2015/05/07先端GPGPUシミュレーション工学特論113
配列添字を入れ替え
た場合
読込のアクセス
書込のアクセス
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
・・・
メモリアドレスに対する
スレッドのアクセス要求
0
2
3
5
1
6
8
14
4
7
9
15
10
11
12
13
バンク番号
・・・
data[threadIdx.y][threadIdx.x]
//16‐wayバンクコンフリクト
data[threadIdx.x][threadIdx.y]
バンク
コンフリクト
64 1280 192
data[threadIdx.x][1]](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-113-320.jpg)
![配列添字を入れ替えた場合の共有メモリへ
のアクセス(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論114
配列添字を入れ替えた場合
読込のアクセス
書込のアクセス
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]
data[threadIdx.x][threadIdx.y]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
data[0][threadIdx.x] data[1][threadIdx.x]
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-114-320.jpg)
![配列添字を入れ替えた場合の共有メモリへ
のアクセス(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論115
配列添字を入れ替えた場合
読込のアクセス
書込のアクセス
//コンフリクトフリー
data[threadIdx.y][threadIdx.x]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
data[2][threadIdx.x] data[3][threadIdx.x]
data[threadIdx.x][threadIdx.y]
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-115-320.jpg)
![配列添字を入れ替えた場合の共有メモリへ
のアクセス(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論116
配列添字を入れ替えた場合
読込のアクセス
書込のアクセス
data[threadIdx.y][threadIdx.x]
//8‐wayバンクコンフリクト
data[threadIdx.x][threadIdx.y]
…
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
…
data[threadIdx.x][0] data[threadIdx.x][1]
バンク
コンフリクト
バンク
コンフリクト
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-116-320.jpg)
![配列添字を入れ替えた場合の共有メモリへ
のアクセス(Fermi世代)
2015/05/07先端GPGPUシミュレーション工学特論117
配列添字を入れ替えた場合
読込のアクセス
書込のアクセス
data[threadIdx.y][threadIdx.x]
…
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
data[16][16]
data[0][16]
data[1][16]
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15data[2][16]
data[3][16]
data[threadIdx.x][2] data[threadIdx.x][3]
バンク
コンフリクト
バンク
コンフリクト
//8‐wayバンクコンフリクト
data[threadIdx.x][threadIdx.y]
0
0
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
11
0
12
0
13
0
14
0
15
0
0
1
1
1
2
1
3
1
4
1
5
1
6
1
7
1
8
1
9
1
10
1
11
1
12
1
13
1
14
1
15
1
threadIdx.x
threadIdx.y](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-117-320.jpg)
![実行時間
2015/05/07先端GPGPUシミュレーション工学特論118
入力配列サイズ Nx×Ny = 4096×2048
スレッド数 Tx×Ty = 16×16
カーネル 実行時間 [ms]
copy(目標値) 0.802 / 1.57
transpose 1.34
transpose_shared 0.977
transpose_reducebankconflict 0.926
transpose_shared_indexchange 0.939
有意に
高速化](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-118-320.jpg)
![__global__ void transpose_reducebankconflict(int *in, int *,out){
__shared__ int data[Ty][Tx+1]; //バンクコンフリクトを回避
int i = blockIdx.x*blockDim.x + threadIdx.x; //配列添字とスレッド番号の
int j = blockIdx.y*blockDim.y + threadIdx.y; //対応を計算
//グローバルメモリから共有メモリへコピー(コアレスアクセス)
data[threadIdx.y][threadIdx.x] = in[j*Nx + i];
__syncthreads(); //ブロック内の全スレッドがコピーを完了するのを待機
i = blockIdx.y*blockDim.y + threadIdx.x;
j = blockIdx.x*blockDim.x + threadIdx.y;
out[j*Ny + i] = data[threadIdx.x][threadIdx.y];
}
共有メモリの添字を交換,パディングした
カーネル
2015/05/07先端GPGPUシミュレーション工学特論119
transpose_reducebankconflict_indexchange.cu](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-119-320.jpg)
![実行時間
2015/05/07先端GPGPUシミュレーション工学特論120
入力配列サイズ Nx×Ny = 4096×2048
スレッド数 Tx×Ty = 16×16
カーネル 実行時間 [ms]
copy(目標値) 0.802 / 1.57
transpose 1.34
transpose_shared 0.977
transpose_reducebankconflict 0.926
transpose_shared_indexchange 0.939
transpose_reducebankconflict
_indexchange 0.926
ほぼ同じ](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-120-320.jpg)
![付録 書込と読込のアクセスの影響
2015/05/07先端GPGPUシミュレーション工学特論121
スレッド数(Tx×Ty=16×16)で配列サイズを変更
読込と書込でコアレス・ストライドアクセスが変化
書込がコアレスアクセスになる方が高速になる傾向
GPUでは書込をキャッシュできないことが理由と思われる
カーネル
実行時間 [ms]
4096×2048 2048×1024 1024×512
copy(目標値)
(rw:コアレス/rw:ストライド)
0.802/1.57 0.202/0.389 0.055/0.103
transpose
(r:コアレス,w:ストライド)
1.39 0.348 0.089
simple_transpose
(r:ストライド,w:コアレス)
1.13 0.289 0.077](https://image.slidesharecdn.com/advancedgpgpu04-160307055610/85/2015-GPGPU-4-GPU-121-320.jpg)







![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)



























































