CUDA プログラミング
Basic CUDA C Language
✓ CUDA C Languageとは?
- CUDAのカーネルを書くための言語
- 文法はほぼC/C++、ただし標準Cライブラリ等は使用できない
✓ 文法要素
- __global__ void func(...)でfuncがカーネルとしてコンパイルされる
- __device__ void func(...)でfuncがデバイス関数
(カーネルから呼び出せる関数)としてコンパイルされる
#6 さて、CUDAスレッドとカーネルという言葉が出てきましたね。これについて説明します。\n\nGPUは、数万というCUDAスレッドを数百のCUDAコアで並列処理するという実行モデルを持っています。CUDAカーネルは、CUDAスレッドの処理内容を記述するためのもので、__global__という識別子を関数の先頭に付けると、それがCUDAカーネルになります。\n\n= Live =\nCUDAカーネルのスタブを書く\n
#7 さて、CUDAスレッドとカーネルという言葉が出てきましたね。これについて説明します。\n\nGPUは、数万というCUDAスレッドを数百のCUDAコアで並列処理するという実行モデルを持っています。CUDAカーネルは、CUDAスレッドの処理内容を記述するためのもので、__global__という識別子を関数の先頭に付けると、それがCUDAカーネルになります。\n\n= Live =\nCUDAカーネルのスタブを書く\n
#8 さて、CUDAスレッドとカーネルという言葉が出てきましたね。これについて説明します。\n\nGPUは、数万というCUDAスレッドを数百のCUDAコアで並列処理するという実行モデルを持っています。CUDAカーネルは、CUDAスレッドの処理内容を記述するためのもので、__global__という識別子を関数の先頭に付けると、それがCUDAカーネルになります。\n\n= Live =\nCUDAカーネルのスタブを書く\n
#9 さて、CUDAスレッドとカーネルという言葉が出てきましたね。これについて説明します。\n\nGPUは、数万というCUDAスレッドを数百のCUDAコアで並列処理するという実行モデルを持っています。CUDAカーネルは、CUDAスレッドの処理内容を記述するためのもので、__global__という識別子を関数の先頭に付けると、それがCUDAカーネルになります。\n\n= Live =\nCUDAカーネルのスタブを書く\n
#10 さて、CUDAスレッドとカーネルという言葉が出てきましたね。これについて説明します。\n\nGPUは、数万というCUDAスレッドを数百のCUDAコアで並列処理するという実行モデルを持っています。CUDAカーネルは、CUDAスレッドの処理内容を記述するためのもので、__global__という識別子を関数の先頭に付けると、それがCUDAカーネルになります。\n\n= Live =\nCUDAカーネルのスタブを書く\n
#11 さて、CUDA APIとCUDAの拡張構文についてですが、必要なのは全部でたった4つです。\nGPUは専用のメモリ空間を持っており、このメモリ空間のアロケーションに使用するのがcudaMallocとcudaFreeです。\nまた、CPU側のメモリとの間のデータのコピーはcudaMemcpyというAPIを使用します。\n\nそして、カーネルと呼ばれるGPUプログラムの呼び出しには、CUDAの拡張文法を使用します。\nこのようにアングルブラケットをカーネル関数の前に付け、nvccでコンパイルすると、\nカーネルの呼び出しとして解釈されます。\n\n= Live =\nCUDA APIを使用したホストコードを作成する\n
#12 CUDAカーネル内部では、いくつかの特殊な組み込み関数や変数が使用できます。今回は、threadIdxという組み込み変数のみを使用します。この変数は、そのカーネルを実行するCUDAスレッドのIDを格納しており、CUDAスレッドごとに違う変数を取得できます。\n\n= Live =\nカーネルを実装\n関数オブジェクトを実装し、関数に__device__識別子を付ける\n









![----左から続く----
#include <iostream>
#include <vector> // 2. 入力データ転送
// 4. カーネル実行 cudaMemcpy(d_a, &a[0], size*sizeof(float),
cudaMemcpyHostToDevice);
__global__ cudaMemcpy(d_b, &b[0], size*sizeof(float),
void vecadd(float *a, float *b, float *c) cudaMemcpyHostToDevice);
{
c[threadIdx.x] = a[threadIdx.x] dim3 grid_size = dim3(1, 1, 1);
+ b[threadIdx.x]; dim3 block_size = dim3(size, 1, 1);
}
// 3. カーネル呼び出し
int main(int argc, char *argv[])
{ vecadd<<<grid_size,
const int size = 16; block_size>>>(d_a, d_b, d_c);
std::vector<float> a(size, 1);
std::vector<float> b(size, 1); // 5. 出力データ転送
std::vector<float> c(size, 0); cudaMemcpy(&c[0], d_c, size*sizeof(float),
cudaMemcpyDeviceToHost);
float *d_a, *d_b, *d_c;
// 6. GPUメモリ破棄
// 1. GPUメモリ確保
cudaFree(d_a);
cudaMalloc(&d_a, size*sizeof(float)); cudaFree(d_b);
cudaMalloc(&d_b, size*sizeof(float)); cudaFree(d_c);
cudaMalloc(&d_c, size*sizeof(float));
for (int i=0; i<size; ++i)
{
----右へ続く---- std::cout << c[i] << std::endl;
}](https://image.slidesharecdn.com/nvseminar2012-120529193158-phpapp02/85/NVIDIA-Japan-Seminar-2012-13-320.jpg)








![#include <iostream>
__global__
void vecadd(float *a, float *b, float *c)
{
c[threadIdx.x] = a[threadIdx.x] + b[threadIdx.x];
}
int main(int argc, char *argv[])
{
const int size = 16;
float *a, *b, *c;
cudaMallocHost(&a, size*sizeof(float));
cudaMallocHost(&b, size*sizeof(float));
for (int i=0; i<size; ++i) { a[i] = b[i] = 1; c[i] = 0; }
cudaMallocHost(&c, size*sizeof(float));
dim3 grid_size = dim3(1, 1, 1);
dim3 block_size = dim3(size, 1, 1);
vecadd<<<grid_size, block_size>>>(a, b, c);
for (int i=0; i<size; ++i) std::cout << c[i] << std::endl; 注意:GT200アーキテクチャ
すごく簡単](https://image.slidesharecdn.com/nvseminar2012-120529193158-phpapp02/85/NVIDIA-Japan-Seminar-2012-22-320.jpg)
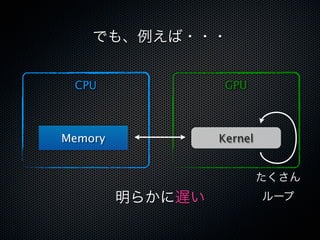
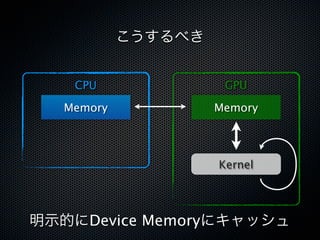



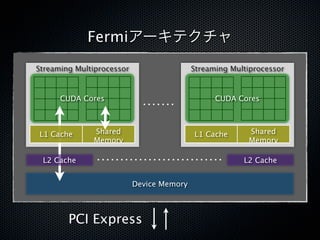
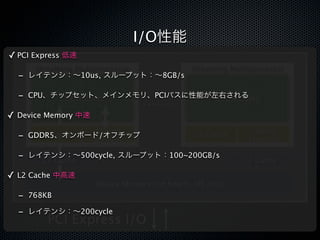
![CacheとShared Memory
✓ 違い
- L1/L2キャッシュによるキャッシュは暗黙的に行われる
- Shared Memoryはカーネル中で明示的に使う
✓ Shared Memoryの使い方
- 変数修飾子__shared__をつける
__global__
void kernel(float *ptr) {
__shared__ float buf[16]; Shared Memoryの宣言とロード
buf[16] = ptr[threadIdx.x];
...
__syncthreads(); 同期命令
...](https://image.slidesharecdn.com/nvseminar2012-120529193158-phpapp02/85/NVIDIA-Japan-Seminar-2012-30-320.jpg)

![愚直な一手
__global__
void matmul_naive(float *a, float *b, float *c, int matrix_size)
{
const unsigned int xidx = blockIdx.x * blockDim.x + threadIdx.x;
const unsigned int yidx = blockIdx.y * blockDim.y + threadIdx.y;
float accumulator = 0.0;
for (int i=0; i<matrix_size; ++i)
{
accumulator += a[yidx*matrix_size+i] * b[i*matrix_size+xidx];
}
c[yidx*matrix_size+xidx] = accumulator;
1. 計算結果の行列Cの要素ごとに1スレッドを割り当てる
- 16x16のスレッドからなる、(matrix_size/16)x(matrix_size/16)のブロッ
ク
2. xidx, yidxは行列Cの要素の添字になる](https://image.slidesharecdn.com/nvseminar2012-120529193158-phpapp02/85/NVIDIA-Japan-Seminar-2012-32-320.jpg)


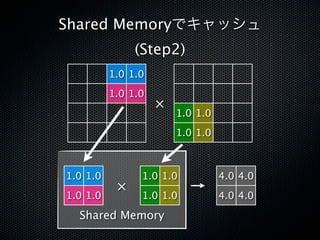
![スマートな一手
__global__
void matmul_shared(float *a, float *b, float *c, int matrix_size)
{
const unsigned int xidx = blockIdx.x * blockDim.x + threadIdx.x;
const unsigned int yidx = blockIdx.y * blockDim.y + threadIdx.y;
float accumulator = 0.0;
for (int i=0; i<matrix_size; i+=16)
{ Shared Memoryの宣言とロー
__shared__ float sub_a[16][16];
__shared__ float sub_b[16][16];
sub_a[threadIdx.y][threadIdx.x] = a[yidx*matrix_size+(i+threadIdx.x)];
sub_b[threadIdx.y][threadIdx.x] = b[(i+threadIdx.y)*matrix_size+xidx];
Shared Memoryへの
__syncthreads();
for (int j=0; j<16; ++j)
{
accumulator += sub_a[threadIdx.y][j] * sub_b[j][threadIdx.x];
}
Shared Memoryからの
__syncthreads();
}](https://image.slidesharecdn.com/nvseminar2012-120529193158-phpapp02/85/NVIDIA-Japan-Seminar-2012-36-320.jpg)





![[4.20版] UE4におけるLoadingとGCのProfilingと最適化手法](https://cdn.slidesharecdn.com/ss_thumbnails/ue4loadgcprofilingoptimization420-180802153630-thumbnail.jpg?width=640&height=640&fit=bounds)


















































