PyCUDA - CUDA C以外の開発環境
長岡技術科学大学2015年度GPGPU講習会(2015年11月25日実施)
開発および講義には長岡技術科学大学のGPU搭載ラップトップPC(GROUSE2)を利用しています。
開発環境
Dell Precision M4600
CPU Intel Core i7 2.7GHz
メモリ 32GB
GPU NVIDIA Quadro 2000M
CUDA 6.5
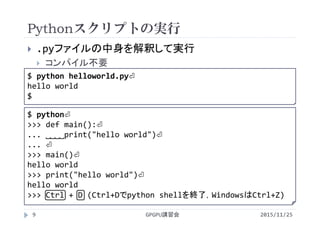
Visual Studio Community 2013
Python 3.4
GPGPU講習会
・PyCUDA
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-pycuda
・CUDA Fortranによる格子ボルツマン法の高速化
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-accelerataion-of-lattice-boltzmann-method-using-cuda-fortran
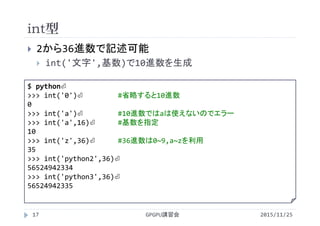
・補足資料 GPGPUとCUDA Fortran
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-gpgpu-and-cuda-fortran
・GPU最適化ライブラリの利用(その1,cuBLAS)
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-gpu-accelerated-libraries-1-of-3-cublas
・GPU最適化ライブラリの利用(その2,cuSPARSE)
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-gpu-accelerated-libraries-2-of-3-cusparse
・GPU最適化ライブラリの利用(その3,Thrust)
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-gpu-accelerated-libraries-3-of-3-thrust
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313




















![文字列へのアクセス
2015/11/25GPGPU講習会24
インデックスを使ったアクセス
変数名[インデックス]
範囲は0~文字列の長さ‐1 (C言語と同じ)
正の整数は先頭からの位置
負の整数は終端からの位置
>>> a = 'string'⏎ #文字列の長さは6なので,インデックスの範囲は0~5
>>> a[0]⏎
's'
>>> a[1]⏎
't'
>>> a[6]⏎ #エラー
>>> a[‐1]⏎ #実質の終端
'g'
>>> a[‐4]⏎
'r'](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-24-320.jpg)
![文字列へのアクセス
2015/11/25GPGPU講習会25
スライスを使ったアクセス
変数名[開始位置:終了位置:ストライド]
: だけ書けば全範囲
C言語のfor文の処理に類似
for(i=開始位置;i<終了位置;i+=ストライド)
>>> a = 'string'⏎ #文字列の長さは6なので,インデックスの範囲は0~5
>>> a[:]⏎
'string'
>>> a[5]⏎
'g'
>>> a[2:5]⏎ #5番目のインデックスを含むなら'g'まで出てくるはず
'rin'
>>> a[2:]⏎ #終端まで表示したいときは終了インデックスを書かない
'ring'](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-25-320.jpg)
![文字列の要素へのアクセス
2015/11/25GPGPU講習会26
スライスを使ったアクセス
変数名[開始位置:終了位置:ストライド]
: だけ書けば全範囲
C言語のfor文の処理に類似
for(i=開始位置;i<終了位置‐|負のインデックス|;i+=ストライド)
>>> a[:‐1]⏎ #開始インデックスを書かなければ先頭から
'strin'
>>> a[3:‐2]⏎ #for(i=3;i<6‐|‐2|;i+=1)
'i'
>>> a[1:5:3]⏎
'tn'
>>> a[::2]⏎ #先頭から終端まで1文字飛ばしで表示
'srn'](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-26-320.jpg)





![繰り返し
2015/11/25GPGPU講習会33
for
処理をある一定回数繰り返す
C言語とは書き方が異なる
コンテナ
データの格納方法の一つ
for ループ内変数 in コンテナ:
˽˽˽˽繰り返し実行する処理
else:
˽˽˽˽ループ終了後(forループを実行しなかった場合)に行う処理
>>> x = [0,1,2,3,4]
>>> x[1]
1](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-33-320.jpg)
![繰り返し
2015/11/25GPGPU講習会34
>>> x = [0,1,2,3,4]⏎
>>> for i in x:⏎ #xの最初から最後まで変化させながら処理を実行
... ˽˽˽˽print(i)⏎ #print(x[i])と等価
... ⏎
0
1
2
3
4
>>> a = 'string'⏎ #文字列もコンテナの一種
>>> for i in a:⏎ #aの最初から最後まで変化させながら処理を実行
... ˽˽˽˽print(i)⏎ #print(a[i])と等価
... ⏎
s
t
r
i
n
g](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-34-320.jpg)
![繰り返し
2015/11/25GPGPU講習会35
決まった回数繰り返す
range()関数でコンテナを生成
range(終端) 0から終端‐1まで1ずつ変化するコンテナを生成
range(先頭,終端,ストライド)という使い方もできる(先頭から終端‐1ま
でストライドずつ変化するコンテナを生成)
>>> range(5)⏎
[0,1,2,3,4]
>>> range(1,5)⏎
[1,2,3,4]
>>> range(1,5,2)⏎
[1,3]
>>> sum=0⏎ #1から10までの合計を計算
>>> for i in range(1,11):⏎ #
... ˽˽˽˽sum+=i⏎ #
... ⏎
>>> sum⏎
55](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-35-320.jpg)






![NumPy
2015/11/25GPGPU講習会42
NumPyの利用方法
import numpy
NumPyの機能を利用するにはnumpy.を付ける必要がある
import numpy as np
numpyよりも記述量が少なく,他のモジュールと衝突することもない
>>> import numpy
>>> numpy.array([0,1,2,3])
array([0,1,2,3])
>>> import numpy as np
>>> np.array([0,1,2,3])
array([0,1,2,3])](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-42-320.jpg)
![1次元配列
2015/11/25GPGPU講習会43
定義とアクセス
>>> import numpy as np⏎
>>> x = np.array([0,1,2,3])⏎
>>> print(x)⏎
[0 1 2 3]
>>> x[3]⏎
3
>>> for i in range(4):⏎
... ˽˽˽˽print(x[i])⏎
... ⏎
0
1
2
3
>>>](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-43-320.jpg)
![1次元配列
2015/11/25GPGPU講習会44
演算
>>> import numpy as np⏎
>>> x = np.array([0,1,2,3])⏎
>>> y = np.array([4,5,6,7])⏎
>>> print(x+y)⏎
[ 4 6 8 10]
>>> print(x*y)⏎
[ 0 5 12 21]
>>> print(x.dot(y))⏎
38
>>> dot = 0⏎
>>> for i in range(4):⏎
... ˽˽˽˽dot += x[i]*y[i]⏎
... ⏎
>>> dot⏎
38](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-44-320.jpg)
![2次元配列
2015/11/25GPGPU講習会45
定義とアクセス
>>> import numpy as np⏎
>>> A = np.array([[1,2,3],[4,5,6],[7,8,9]])⏎
>>> print(A)⏎
[[1 2 3]
[4 5 6]
[7 8 9]]
>>> A[2][1]⏎
8
>>> for i in range(3):⏎
... ˽˽˽˽for j in range(3):⏎
... ˽˽˽˽˽˽˽˽print(A[i][j])⏎ #格納順序はj方向が優先
... ⏎ #行方向を固定して列方向に変化
1
2
:
9](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-45-320.jpg)
![2次元配列
2015/11/25GPGPU講習会46
演算
2次元配列は行列ではない
行列として取り扱いたい場合はarrayではなくmatrixを利用
>>> import numpy as np⏎
>>> A = np.array([[1,2,3],[4,5,6],[7,8,9]])⏎
>>> B = np.array([[10,11,12],[13,14,15],[16,17,18]])⏎
>>> print(A+B)⏎
[[11 13 15]
[17 19 21]
[23 25 27]]
>>> print(A*B)⏎ #行列‐行列積ではなく要素同士の積
[[ 10 22 36]
[ 52 70 90]
[112 136 162]]
>>>](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-46-320.jpg)
![配列情報の確認
2015/11/25GPGPU講習会47
変数名からarrayの情報を確認可能
ndim 次元
size 配列の要素数
shape 配列の形状(各次元の要素数)
dtype 配列要素の型
>>> import numpy as np⏎
>>> x = np.array([0,1,2,3])⏎
>>> x.ndim⏎
1
>>> x.size⏎
4
>>> x.shape⏎
(4,)
>>> x.dtype⏎
dtype('int32')](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-47-320.jpg)
![ベクトル和の計算
2015/11/25GPGPU講習会48
import numpy as np
def main():
N = 1024
a = np.ones(N) #N個の要素を持つ配列を確保し,1.0で初期化
b = np.empty_like(a) #aの形状と同じ配列を確保し,初期化はしない
c = np.zeros_like(a) #aの形状と同じ配列を確保し,0.0で初期化
b[:]=2. #b=2と書くと,配列bが破棄されてスカラ変数b(値は2)になる
c=a+b #[:]を書いて配列の演算であることを示す方がよいと思う
print(a)
print(b)
print(c)
if __name__ == "__main__":
main() vectoradd.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-48-320.jpg)
![配列の作り方
2015/11/25GPGPU講習会49
形状を指定して一定値で初期化(あるいは未初期化)
引数で指定された形状の配列を生成
_likeを付けると,引数として既存のarrayをとる
型はfloat型(C言語のdouble型)
empty() 全要素を初期化しない
zeros() 全要素を0.0で初期化
ones() 全要素を1.0で初期化
>>> import numpy as np⏎
>>> a = np.empty(1024)⏎
>>> a⏎
array([ 2.00229098e‐295, nan, 1.12646967e‐321, ...,
1.00000000e+000, 1.00000000e+000, 1.00000000e+000])
>>> b = np.zeros_like(a)⏎
>>> b⏎
array([ 0., 0., 0., ..., 0., 0., 0.])
>>> b.dtype⏎
dtype('float64')](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-49-320.jpg)
![配列の作り方
2015/11/25GPGPU講習会50
生成する数値の範囲と間隔を指定して生成
numpy.arange(始点,終点,間隔)
終点は含まれない
生成する数値の範囲と点数を指定して生成
numpy.linspace(始点,終点,点数)
終点を含む
>>> import numpy as np⏎
>>> np.arange(0, 3, 0.5)⏎
array([ 0. , 0.5, 1. , 1.5, 2. , 2.5])
>>> import numpy as np⏎
>>> np.linspace(0, 3, 7)⏎
array([ 0. , 0.5, 1. , 1.5, 2. , 2.5, 3. ])](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-50-320.jpg)

![差分法による1階微分の計算
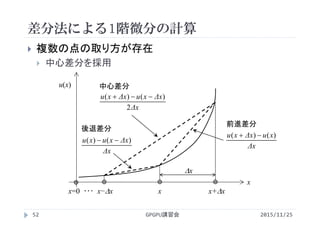
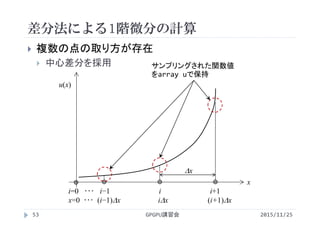
2015/11/25GPGPU講習会54
複数の点の取り方が存在
中心差分を採用
u[i]
i
i=0 ・・・ i−1 i i+1
dx
サンプリングされた関数値
をarray uで保持
u[i]
u[i‐1]
u[i+1]
中心差分
(u[i+1]‐u[i‐1])/(2*dx)](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-54-320.jpg)
![差分法による1階微分の計算
計算領域内部
dudx[i]=(u[i+1]‐u[i‐1])/(2.*dx)
dudx[i]
u[i]
+ + + +
2015/11/25GPGPU講習会55
Δx2
1
×−1](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-55-320.jpg)
![差分法による1階微分の計算
境界条件(関数値が無いため処理を変更)
dudx[0] =(‐3*u[0] +4*u[1] ‐u[2] )/(2.*dx)
dudx[‐1]=( 3*u[‐1]‐4*u[‐2]+u[‐3])/(2.*dx)
2階微分値が一定と仮定して関数を補外した事に相当
dudx[i]
u[i]
+
2015/11/25GPGPU講習会56
Δx2
1
×−3 ×4 ×−1](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-56-320.jpg)
![差分法による1階微分の計算
境界条件(関数値が無いため処理を変更)
dudx[0] =(‐3*u[0] +4*u[1] ‐u[2] )/(2.*dx)
dudx[‐1]=( 3*u[‐1]‐4*u[‐2]+u[‐3])/(2.*dx)
2階微分値が一定と仮定して関数を補外した事に相当
dudx[i]
u[i]
+
2015/11/25GPGPU講習会57
Δx2
1
×−4 ×3](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-57-320.jpg)

![差分法による1階微分の計算
2015/11/25GPGPU講習会59
def diff(u,dx):
dudx = np.empty_like(u)
dudx[ 0] = (‐3.*u[ 0] + 4.*u[ 1] ‐ u[ 2] )/(2.*dx)
dudx[1:‐1] = (u[2:]‐ u[:‐2])/(2.*dx) #スライスは終端を含まない
dudx[‐1] = ( 3.*u[‐1] ‐ 4.*u[‐2] + u[‐3] )/(2.*dx)
return dudx
if __name__ == "__main__":
main()
differentiate.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-59-320.jpg)
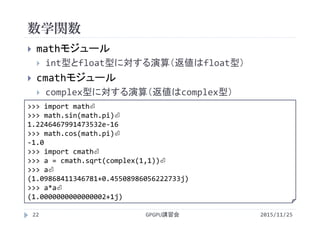
![NumPyの数学関数
2015/11/25GPGPU講習会60
sin,cosなどmathモジュールと同じ関数を提供
配列を引数に渡すと,全ての配列要素に対して関数を
適用し,結果を配列で返す
>>> import numpy as np⏎
>>> import math⏎
>>> x = np.linspace(0,2*np.pi,5)⏎
>>> x⏎
array([ 0. , 1.57079633, 3.14159265, 4.71238898,
6.28318531])
>>> math.sin(x[0])⏎
0.0
>>> math.sin(x)⏎ #エラー
>>> np.sin(x)⏎
array([ 0.00000000e+00, 1.00000000e+00, 1.22464680e‐16,
‐1.00000000e+00, ‐2.44929360e‐16])](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-60-320.jpg)
![実行結果
2015/11/25GPGPU講習会61
結果の確認
どの程度理論値と一致しているかを図で視覚的に確認
ファイル出力関数を書いて,gnuplotで・・・
グラフ描画ライブラリを利用
$ python differentiate.py⏎
[ 1.27323954e+000 3.89817183e‐017 ‐6.36619772e‐001 1.38338381e‐321
1.27323954e+000]
[ 1.00000000e+00 6.12323400e‐17 ‐1.00000000e+00 ‐1.83697020e‐16
1.00000000e+00]
$](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-61-320.jpg)

![差分法による計算結果のプロット
2015/11/25GPGPU講習会64
import numpy as np
from matplotlib import pyplot as pl
def main():
:(これ以前は同じなので省略)
pl.plot(x,dudx, label='Computational')
X = np.linspace(0,Lx,101)
pl.plot(X, np.cos(X), label = 'Analytical')
pl.xlim(0,Lx)
pl.ylim(‐1.3,1.3)
pl.xlabel('$x$')
pl.ylabel(r'$¥frac{d}{dx}¥sin x')
pl.xticks([0,np.pi/2,np.pi,1.5*np.pi,2*np.pi],
[r'$0$',r'$¥pi/2$',r'$¥pi$',r'$1.5¥pi$',r'$2¥pi$'])
pl.legend(loc='best')
pl.show()
:(これ以後は同じなので省略) differentiate.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-64-320.jpg)
![実行結果
2015/11/25GPGPU講習会65
$ python differentiate.py⏎
[ 1.27323954e+000 3.89817183e‐017 ‐6.36619772e‐001 1.38338381e‐321
1.27323954e+000]
[ 1.00000000e+00 6.12323400e‐17 ‐1.00000000e+00 ‐1.83697020e‐16
1.00000000e+00]
$](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-65-320.jpg)





![移流方程式の計算
2015/11/25GPGPU講習会71
def diff(u, dx):
Nx = u.size
d_u_dx = np.zeros(Nx)
d_u_dx[0] = (u[1] ‐ u[‐2] )/(2.*dx) #周期境界条件を採用
d_u_dx[1:‐1] = (u[2:]‐ u[:‐2])/(2.*dx)
d_u_dx[‐1] = (u[1] ‐ u[‐2] )/(2.*dx) #周期境界条件を採用
return d_u_dx
if __name__ == '__main__':
main()
convection.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-71-320.jpg)


![PyCUDAのデモ
2015/11/25GPGPU講習会75
PyCUDAのチュートリアルにあるdemo.py
4×4の配列に乱数を代入し,それをGPUで2倍して返却
import pycuda.gpuarray as gpuarray
import pycuda.driver as cuda
import pycuda.autoinit
import numpy
a_gpu = gpuarray.to_gpu(numpy.random.randn(4,4).astype(numpy.float32))
a_doubled = (2*a_gpu).get()
print(a_doubled)
print(a_gpu)
[[ 0.51360393 1.40589952 2.25009012 3.02563429]
[‐0.75841576 ‐1.18757617 2.72269917 3.12156057]
[ 0.28826082 ‐2.92448163 1.21624792 2.86353827]
[ 1.57651746 0.63500965 2.21570683 ‐0.44537592]]
[[ 0.25680196 0.70294976 1.12504506 1.51281714]
[‐0.37920788 ‐0.59378809 1.36134958 1.56078029]
[ 0.14413041 ‐1.46224082 0.60812396 1.43176913]
[ 0.78825873 0.31750482 1.10785341 ‐0.22268796]]
PyCUDA/demo.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-75-320.jpg)
![CUDA Cで書くと
2015/11/25GPGPU講習会76
#include<stdio.h>
#include<stdlib.h>
#define nbytes (4*4*sizeof(float))
__global__ void doublify(float *a){
int i = blockIdx.x*blockDim.x + threadIdx.x;
a[i] *= 2.0f;
}
int main(void){
float *a = (float *)malloc(nbytes);
float *a_gpu;
cudaMalloc((void **)&a_gpu , nbytes);
for(int i=0;i<4*4;i++)
a[i] = (float)rand()/RAND_MAX;
cudaMemcpy(a_gpu, a, nbytes, cudaMemcpyHostToDevice);
doublify<<<4,4>>>(a_gpu);
float *a_doubled = (float *)malloc(nbytes);
cudaMemcpy(a_doubled, a_gpu, nbytes, cudaMemcpyDeviceToHost);
return 0;
}](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-76-320.jpg)











![Elementwise Operationを利用したy=sin(x)
2015/11/25GPGPU講習会89
import numpy as np
import pycuda.gpuarray as gpuarray
from pycuda.elementwise import ElementwiseKernel #pycuda.cumathから置き換え
import pycuda.autoinit
N = 2**20
Lx = 2*np.pi
sin_kernel = ElementwiseKernel(
"float *y, float *x", #引数
"y[i] = sin(x[i])", #1要素に対する処理(引数の全要素に適用)
"elementwise_sin") #名前
x = np.linspace(0, Lx, N).astype(np.float32)
dev_x = gpuarray.to_gpu(x)
dev_y = gpuarray.empty_like(dev_x)
sin_kernel(dev_y, dev_x)
y = dev_y.get()
PyCUDA/elementwise1.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-89-320.jpg)
![2変数以上のElementwise Operation
2015/11/25GPGPU講習会90
import numpy as np
import pycuda.gpuarray as gpuarray
from pycuda.elementwise import ElementwiseKernel #pycuda.cumathから置き換え
import pycuda.autoinit
N = 2**20
x = np.ones(N).astype(np.float32)
y = np.zeros_like(x)
z = np.zeros_like(x)
y[:]=2.0
saxpby_kernel = ElementwiseKernel(
"float a, float *x, flato b, float *y, float *z", #引数
"z[i] = a*x[i]+b*y[i]", #1要素に対する処理(引数の全要素に適用)
"linear_combination") #名前
dev_x = gpuarray.to_gpu(x)
dev_y = gpuarray.to_gpu(y)
saxpby_kernel(1.0, dev_x, 2.0, dev_y, dev_z)
z = dev_z.get()
PyCUDA/elementwise2.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-90-320.jpg)


![SourceModuleを利用したy=sin(x)
2015/11/25GPGPU講習会93
import numpy as np
import pycuda.gpuarray as gpuarray
from pycuda.compiler import SourceModule #ElementwiseKernelから置き換え
import pycuda.autoinit
N = 2**20
Lx = 2*np.pi
module = SourceModule("""
__global__ void sin_kernel(float *y, float *x)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
y[i] = sin(x[i]);
}
""")
sin = module.get_function("sin_kernel") #実行するカーネルを決定
block = (256, 1, 1) #並列実行時のパラメータを設定
grid = (N//block[0], 1, 1) #単純な除算を行うとパラメータがfloatになり,エラーが発生
x = np.linspace(0, Lx, N).astype(np.float32)
dev_x = gpuarray.to_gpu(x)
dev_y = gpuarray.empty_like(dev_x)
sin(dev_y, dev_x, grid = grid, block = block)
y = dev_y.get()
PyCUDA/sourcemdule.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-93-320.jpg)






![CUDA Cカーネルの取り込み
2015/11/25GPGPU講習会102
from pycuda.compiler import SourceModule
import pycuda.autoinit
module = SourceModule("""
#include "hello_kernel.cu" //kernel.cuという名前は利用不可
""",include_dirs=['C:¥Python34¥PyCUDA'])#hello_kernel.cuの場所を指定
hello = module.get_function("hello_threads") #("hello_thread")
block = (4, 1, 1)
grid = (2, 1, 1)
hello(block = block, grid = grid)
#include<stdio.h>
__global__ void hello_thread()
{
printf("hello thread¥n");
}
__global__ void hello_threads()
{
printf("gridDim.x=%d,blockIdx.x=%d,blockDim.x=%d,threadIdx.x=%d¥n",
gridDim.x, blockIdx.x, blockDim.x, threadIdx.x);
}
PyCUDA/HelloThreads_incl.py
PyCUDA/hello_kernel.cu](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-102-320.jpg)
![CUDA Cプログラムの取り込み
2015/11/25GPGPU講習会103
ベクトル和C=A+B
配列A, B, Cで参照する配列要素番号iが同じ
各スレッドがある配列添字iを処理
・・・
・・・
・・・c[i]
a[i]
b[i]
+ + + + + +
スレッド0 スレッド2スレッド1 スレッド3 ・・・](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-103-320.jpg)
![CUDA Cプログラムの取り込み
2015/11/25GPGPU講習会104
VectorAddimport numpy as np
import pycuda.gpuarray as gpuarray
import pycuda.autoinit
from pycuda.compiler import SourceModule
#main関数の外で定義
module = SourceModule("""
__global__ void init(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x + threadIdx.x;
a[i] = 1.f;
b[i] = 2.f;
c[i] = 0.f;
}
__global__ void add(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}
""")
PyCUDA/vectoradd.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-104-320.jpg)



![CPUとGPUの実行時間の比較
2015/11/25GPGPU講習会108
import numpy as np
import pycuda.gpuarray as gpuarray
import pycuda.autoinit
from pycuda.compiler import SourceModule
import pycuda.driver as cuda #cudaEventを利用
import time #time()を利用
module = SourceModule("""
__global__ void init(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x + threadIdx.x;
a[i] = 1.f;
b[i] = 2.f;
c[i] = 0.f;
}
__global__ void add(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}
""")
PyCUDA/vectoradd_time.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-108-320.jpg)
![CPUとGPUの実行時間の比較
2015/11/25GPGPU講習会109
def init(a, b, c,N):
for i in range(N):
a[i] = 1.
b[i] = 2.
c[i] = 0.
def add(a, b, c,N):
for i in range(N):
c[i] = a[i] + b[i]
def main():
N = 2**20
Nt = 2**8
Nb = N//Nt
a = np.zeros(N).astype(np.float32)
b = np.zeros(N).astype(np.float32)
c = np.zeros(N).astype(np.float32)
init(a,b,c,N)
start_s = time.time()
add(a,b,c,N)
end_s = time.time()
print((end_s‐start_s)*1e+3,"msec") #395 msec
PyCUDA/vectoradd_time.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-109-320.jpg)


![デバイス変数の確保とメモリ転送の簡略化
2015/11/25GPGPU講習会112
: (省略)
def main():
N = 2**20
Nt = 2**8
Nb = N//Nt
a = np.zeros(N).astype(np.float32)
b = np.zeros(N).astype(np.float32)
c = np.zeros(N).astype(np.float32)
a[:] = 1.
b[:] = 2.
global module
add = module.get_function("add")
#デバイス変数を確保せず,カーネル実行時にメモリを自動で転送
add(cuda.InOut(a), cuda.InOut(b), cuda.InOut(c), grid=(Nb,1),block=(Nt,1,1))
print(c)
if __name__ == "__main__":
main()
PyCUDA/vectoradd_inout.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-112-320.jpg)


![C++の機能(Template)の利用
2015/11/25GPGPU講習会115
module = SourceModule("""
template <class T>
__device__ T add_func(T x, T y){
return (x+y);
}
extern "C" {
__global__ void init(float *a, float * b, float *c){
int i = blockIdx.x*blockDim.x + threadIdx.x;
a[i] = 1.0f;
b[i] = 2.0f;
c[i] = 0.0f;
}
__global__ void add(float *a, float * b, float * c){
int i = blockIdx.x*blockDim.x + threadIdx.x;
c[i] = add_func<float>(a[i],b[i]);
}
}
""", no_extern_c=True)
PyCUDA/vectoradd_tmpl.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-115-320.jpg)



![移流方程式の計算
2015/11/25GPGPU講習会119
import numpy as np
import pycuda.gpuarray as gpuarray
import pycuda.autoinit
from pycuda.compiler import SourceModule
import pycuda.driver as cuda
convection_kernel_template = """
#define Nx (%(Nx)s) //Pythonスクリプト内で設定した値を反映させる
#define dx (%(dx)s) //
#define C (%(C)s) //
#define dt (%(dt)s) //
__global__ void convection(float *u, float *uNew){ //通常のCUDA Cカーネルを取り込む
int i = blockIdx.x*blockDim.x + threadIdx.x;
float d_u_dx;
if (i == 0){
d_u_dx = (u[i+1] ‐ u[Nx‐2])/(2.0f*dx); //周期境界条件を設定
}
else if (0 < i && i < Nx‐1){
d_u_dx = (u[i+1] ‐ u[ i‐1])/(2.0f*dx);
}
else if (i == Nx‐1){
d_u_dx = (u[1] ‐ u[ i‐1])/(2.0f*dx); //周期境界条件を設定
}
uNew[i] = u[i] ‐ C*dt*d_u_dx; //移流方程式を時間積分
}
""" PyCUDA/convection.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-119-320.jpg)
![移流方程式の計算
2015/11/25GPGPU講習会120
def main():
Lx = 2. #計算領域の長さ
Nx = 2**10 #離散点の数
dx = Lx/(Nx‐1) #離散点の間隔
C = 1. #移流速度
dt = 0.01*dx/C #時間積分の間隔
Lt = 2. #計算終了時間
Nt = int(Lt/dt) #積分回数
numThreads = 128 #1ブロックあたりのスレッド数の上限
convection_kernel = convection_kernel_template % {'Nx':Nx, 'dx':dx, 'C':C, 'dt':dt }
module = SourceModule(convection_kernel)
convection = module.get_function('convection')
block = (min((numThreads,Nx)),1,1) #並列実行パラメータの設定
grid = (Nx//block[0],1,1) #
t = 0. #初期値の設定
x = np.linspace(0, Lx, Nx).astype(np.float32) #
u = ( 0.5*(1‐np.cos(2.*np.pi*(x‐C*t)/Lx)) )**3 #
X = np.linspace(0,Lx, (Nx‐1)*10+1) #解析解の設定
u_analytical = ( 0.5*(1‐np.cos(2.*np.pi*(X‐C*t)/Lx)) )**3
3
2
cos1
2
1
xL
x
u
3
exact
)(2
cos1
2
1
xL
tCx
u
PyCUDA/convection.py](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-120-320.jpg)

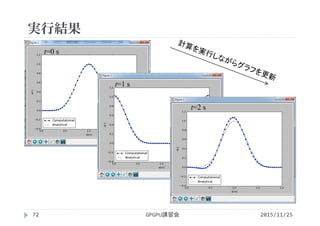
![実行時間の比較
2015/11/25GPGPU講習会122
Nx(x方向の離散点の点数=配列要素数)
25,210,215,220
1ステップあたりの実行時間を算出
CPUはtime()で測定
GPUはcudaEventで測定
複数step時間進行させ,要した時間/実行step数
Nx CPU実行
[ms/step]
GPU実行
[ms/step]
25 0.010 0.102
210 0.024 0.119
215 0.535 0.137
220 24.9 1.82](https://image.slidesharecdn.com/gpuseminarpycuda-160307142758/85/GPGPU-Seminar-PyCUDA-122-320.jpg)










![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)









































