長岡技術科学大学
2015年度GPGPU実践プログラミング(全15回,学部4年対象講義)
第8回総和計算(高度な最適化)
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
・第2回 GPUのアーキテクチャとプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59179215
・第3回 GPGPUプログラミング環境
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59179255
・第3回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59183677
・第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59179449
・第5回 GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59179536
・第6回 パフォーマンス解析ツール
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59179577
・第7回 総和計算
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59179639
・第8回 総和計算(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59179686
・第9回 行列計算(行列-行列積)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59179722
・第10回 行列計算(行列-行列積の高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59179759
・第11回 画像処理
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59179789
・第12回 偏微分方程式の差分計算
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59179972
・第13回 多粒子の運動
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59180018
・第14回 N体問題
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59180054
・第15回 GPU最適化ライブラリ
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59180086
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3


![リダクション(Reduction,換算)
2015/06/03GPGPU実践プログラミング3
配列の全要素から一つの値を抽出
総和,総積,最大値,最小値など
ベクトル和や移動平均,差分法とは処理が異なる
リダクションの特徴
データ参照が大域的
計算順序は交換可能
出力が一つ
出力は並列に計算できない
並列化に工夫が必要
sum
a[i]
+ + + + + +](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-3-320.jpg)
![総和計算の並列化
2015/06/03GPGPU実践プログラミング4
リダクションの並列性
並列性なし
i=0の処理が終了しないとi=1の処理ができない
リダクションの並列化
リダクションの特徴に適した並列化が必要
Parallel Reduction
for(i=0;i<N;i++){
sum += idata[i];
}](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-4-320.jpg)
![総和計算の並列化
2015/06/03GPGPU実践プログラミング5
リダクションの並列化
演算順序の変更による並列性の確保
カスケード計算(associative fan‐in algorithm)
sum
a[i]
カスケード計算
加算の結合法則を利用
乗算や比較でも利用可能
配列要素数が2の冪乗以外では適用
に工夫が必要
変数に浮動小数を用いる場合は値が
一致しないことがある
sum
a[i]
+ + + +
+ +
+](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-5-320.jpg)







![__global__ void reduction4(int *idata,int *odata){
int i = blockIdx.x*blockDim.x + threadIdx.x;//スレッドと配列要素の対応
int tx = threadIdx.x; //スレッド番号
int stride; //”隣”の配列要素までの距離
int j; //各stepで総和計算を行うスレッドが
//アクセスする配列要素番号
__shared__ volatile int s_idata[NT]; //共有メモリの宣言
s_idata[tx] = idata[i]; //グローバルメモリから共有メモリへデータをコピー
__syncthreads(); //共有メモリのデータは全スレッドから参照されるので同期を取る
for(stride = 1; stride <= blockDim.x/2; stride<<=1){
j = 2*stride * tx; //総和計算を行うスレッド番号とアクセスする配列要素の決定
if(j<blockDim.x){
s_idata[j] += s_idata[j+stride];
}
__syncthreads();
}
if(tx==0) odata[blockIdx.x] = s_idata[tx];
}
GPUプログラム(Ver.4)
2015/06/03GPGPU実践プログラミング14
reduction4.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-14-320.jpg)
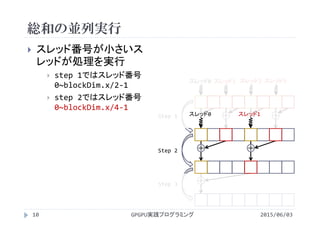
![各Stepでの総和計算(Step 1)
2015/06/03GPGPU実践プログラミング15
処理を行うスレッドとアクセスする配列
要素を決定
連続なスレッドが2*stride間隔で配列にア
クセス
スレッド0がs_idata[0(=2*1 * 0)]
スレッド1がs_idata[2(=2*1 * 1)]
スレッド2がs_idata[4(=2*1 * 2)]
スレッド3がs_idata[6(=2*1 * 3)]
jがblockDim.x(=配列要素数N)より小さく
なるスレッドが「自身が読み込む配列要素i
の値」と「隣の配列要素の値」を加算
+ + + +
+ +
+
stride
が1の段
for(stride = 1; stride <= blockDim.x/2;
stride<<=1){
j = 2*stride * tx;
if(j<blockDim.x){
s_idata[j]+=s_idata[j+stride];
}
__syncthreads();
}
スレッド0 スレッド1 スレッド2 スレッド3](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-15-320.jpg)
![各Stepでの総和計算(Step 2)
2015/06/03GPGPU実践プログラミング16
処理を行うスレッドとアクセスする配列
要素を決定
連続なスレッドが2*stride間隔で配列にア
クセス
スレッド0がs_idata[0(=2*2 * 0)]
スレッド1がs_idata[4(=2*2 * 1)]
jがblockDim.x(=配列要素数N)より小さく
なるスレッドが「自身が読み込む配列要素i
の値」と「隣の配列要素の値」を加算
+ + + +
+ +
+
stride
が2の段
for(stride = 1; stride <= blockDim.x/2;
stride<<=1){
j = 2*stride * tx;
if(j<blockDim.x){
s_idata[j]+=s_idata[j+stride];
}
__syncthreads();
}
スレッド0 スレッド1](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-16-320.jpg)
![各Stepでの総和計算(Step 3)
2015/06/03GPGPU実践プログラミング17
処理を行うスレッドとアクセスする配列
要素を決定
連続なスレッドが2*stride間隔で配列にア
クセス
スレッド0がs_idata[0(=2*4 * 0)]
jがblockDim.x(=配列要素数N)より小さく
なるスレッドが「自身が読み込む配列要素i
の値」と「隣の配列要素の値」を加算
+ + + +
+ +
+stride
が4の段
スレッド0
for(stride = 1; stride <= blockDim.x/2;
stride<<=1){
j = 2*stride * tx;
if(j<blockDim.x){
s_idata[j]+=s_idata[j+stride];
}
__syncthreads();
}](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-17-320.jpg)
![各Stepでの総和計算(結果の書き出し)
2015/06/03GPGPU実践プログラミング18
スレッド0が総和を出力用変数odataに
書き込んで終了
+ + + +
+ +
+
if(tx==0) odata[blockIdx.x] = s_idata[0];
スレッド0](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-18-320.jpg)
![実行時間
2015/06/03GPGPU実践プログラミング
カーネル
N=512 N=1024
実行時間
[s]
データ転送
[GB/s]
実行時間
[s]
データ転送
[GB/s]
0 54.6 0.035 121 0.032
1 9.73 0.196 12.8 0.297
2 10.9 0.175 15.9 0.240
4 10.8 0.177 14.8 0.258
5
6
7
8
19](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-19-320.jpg)
![Ver.4の問題点
2015/06/03GPGPU実践プログラミング20
各スレッドが最初にアクセスする共有メモリが偶数
スレッド0がs_idata[0],スレッド1がs_idata[2],スレッド2が
s_idata[4]...
2‐wayバンクコンフリクトが発生
l1_shared_bank_conflictをプロファイラで確認
l1_shared_bank_conflict=[465]
スレッド番号やアクセスする配列要素の位置がわかりにくい
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
0
12
8
0 1 2 3
16
14
4
4 5 6 7
32
16
0
8 9 10 11
48
17
6
12 13 14 15
64
19
2
16 17 18 19
80
20
8
20 21 22 23
96
22
4
24 25 26 27
11
2
24
0
28 29 30 31バンク番号
バンク
コンフリクト](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-20-320.jpg)


![//カーネル以外はreduction4.cuと同じ
__global__ void reduction5(int *idata,int *odata){
int i = blockIdx.x*blockDim.x + threadIdx.x;//スレッドと配列要素の対応
int tx = threadIdx.x; //スレッド番号
int stride; //”隣”の配列要素までの距離
__shared__ volatile int s_idata[NT]; //共有メモリの宣言
s_idata[tx] = idata[i]; //グローバルメモリから共有メモリへデータをコピー
__syncthreads(); //共有メモリのデータは全スレッドから参照されるので同期を取る
//ストライドをblockDim.x/2からループ毎に1/2
for(stride = blockDim.x/2; stride >= 1; stride>>=1){
if(tx < stride){ //ストライドよりスレッド番号が小さいスレッドのみ計算に参加
s_idata[tx] += s_idata[tx+stride];
}
__syncthreads();
}
if(tx==0) odata[blockIdx.x] = s_idata[tx];
}
GPUプログラム(Ver.5)
2015/06/03GPGPU実践プログラミング23
reduction5.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-23-320.jpg)
![各Stepでの総和計算(Step 1)
2015/06/03GPGPU実践プログラミング24
ストライドをblockDim.x/2(=配列要素
数/2)からループ毎に1/2倍に狭める
処理を行うスレッドとアクセスする配列
要素を決定
ストライドよりもスレッド番号が小さいスレッド
連続なスレッドが連続な配列要素にアクセス
スレッド0がs_idata[0]とs_idata[0+4]
スレッド1がs_idata[1]とs_idata[1+4]
スレッド2がs_idata[2]とs_idata[2+4]
スレッド3がs_idata[3]とs_idata[3+4]
stride
が4の段
for(stride = blockDim.x/2; stride >= 1;
stride>>=1){
if(tx < stride){
s_idata[tx]+=s_idata[tx+stride];
}
__syncthreads();
}
T0
+ + + +
+ +
+
T1 T2 T3](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-24-320.jpg)
![+ + + +
+ +
+
各Stepでの総和計算(Step 2)
2015/06/03GPGPU実践プログラミング25
処理を行うスレッドとアクセスする配列
要素を決定
ストライドよりもスレッド番号が小さいスレッド
連続なスレッドが連続な配列要素にアクセス
スレッド0がs_idata[0]とs_idata[0+2]
スレッド1がs_idata[1]とs_idata[1+2]
stride
が2の段
for(stride = blockDim.x/2; stride >= 1;
stride>>=1){
if(tx < stride){
s_idata[tx]+=s_idata[tx+stride];
}
__syncthreads();
}
T0 T1](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-25-320.jpg)
![各Stepでの総和計算(Step 3)
2015/06/03GPGPU実践プログラミング26
処理を行うスレッドとアクセスする配列
要素を決定
ストライドよりもスレッド番号が小さいスレッド
連続なスレッドが連続な配列要素にアクセス
スレッド0がs_idata[0]とs_idata[0+1]
stride
が1の段
for(stride = blockDim.x/2; stride >= 1;
stride>>=1){
if(tx < stride){
s_idata[tx]+=s_idata[tx+stride];
}
__syncthreads();
} + + + +
+ +
+
T0](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-26-320.jpg)
![実行時間
2015/06/03GPGPU実践プログラミング
カーネル
N=512 N=1024
実行時間
[s]
データ転送
[GB/s]
実行時間
[s]
データ転送
[GB/s]
0 54.6 0.035 121 0.032
1 9.73 0.196 12.8 0.297
2 10.9 0.175 15.9 0.240
4 10.8 0.177 14.8 0.258
5 6.91 0.276 8.70 0.438
6
7
8
27](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-27-320.jpg)

![全スレッドを加算に参加させる総和計算
2015/06/03GPGPU実践プログラミング29
スレッド数を1/2に削減
共有メモリサイズも1/2
グローバルメモリから共有
メモリへのコピーと初回の
加算を同時に実行
ブロック数は変更無し
これまでの「1スレッドが
一つの配列要素にアクセ
ス」という概念を発展
理解できれば脱初級者
T0
+ +
+
Step 1
Step 2
Step 3
T1 T2 T3
s_idata[i]
idata[i]
+ + + +
共
有
メ
モ
リ
グ
ロ
ー
バ
ル
メ
モ
リ](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-29-320.jpg)

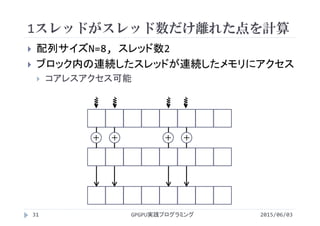

![配列の要素番号iの計算
N=12, <<<3, 4>>>で実行
c[i]
a[i]
b[i]
0 1 2 3 0 1
+ + + + + +
2 3
+ +
gridDim.x=3
blockDim.x=4
2015/06/03GPGPU実践プログラミング33
0 1 2 3
+ + + +
blockDim.x=4 blockDim.x=4
blockIdx.x=0 blockIdx.x=1 blockIdx.x=2
threadIdx.x=
i= 0 1 2 3 4 5 6 7 8 9 10 11
= blockIdx.x*blockDim.x + threadIdx.x](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-33-320.jpg)
![配列の要素番号iの計算
N=12, <<<3, 2>>>で実行
2015/06/03GPGPU実践プログラミング34
c[i]
a[i]
b[i]
0 1 0 1
+ + + +
gridDim.x=3
blockDim.x=2
0 1
+ +
blockDim.x=2 blockDim.x=2
blockIdx.x=0 blockIdx.x=1 blockIdx.x=2
threadIdx.x=
i= 0 1 2 3 4 5 6 7 8 9 10 11](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-34-320.jpg)

![配列の要素番号iの計算
1点目の計算
2015/06/03GPGPU実践プログラミング36
c[i]
a[i]
b[i]
0 1 0 1
+ + + +
gridDim.x=3
0 1
+ +
blockIdx.x=0 blockIdx.x=1 blockIdx.x=2
threadIdx.x=
i= 0 1 2 3 4 5 6 7 8 9 10 11
= blockIdx.x*(blockDim.x*2) + threadIdx.x
1スレッドが計
算する点の数
blockDim.x=2 blockDim.x=2 blockDim.x=2](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-36-320.jpg)
![+ + + + +
配列の要素番号iの計算
2点目の計算
2015/06/03GPGPU実践プログラミング37
c[i]
a[i]
b[i]
0 1 0 1
gridDim.x=3
0 1
blockIdx.x=0 blockIdx.x=1 blockIdx.x=2
threadIdx.x=
+i= 0 1 2 3 4 5 6 7 8 9 10 11
= blockIdx.x*(blockDim.x*2) + threadIdx.x+2
1点目と2点目の間隔
=スレッド数
blockDim.x=2 blockDim.x=2 blockDim.x=2](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-37-320.jpg)

![//#define NT (N/2)
//#define NB (N/NT/2)
__global__ void reduction4(int *idata,int *odata){
int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;//スレッドと配列要素の対応
int tx = threadIdx.x; //スレッド番号
int stride; //”隣”の配列要素までの距離
__shared__ volatile int s_idata[NT]; //NTは定義の時点で1/2倍されている
//グローバルメモリから共有メモリへデータをコピー.1スレッドが2点読み込んで加算
s_idata[tx] = idata[i] + idata[i+blockDim.x]; //blockDim.xは1スレッドが読み込む
__syncthreads(); //1点目と2点目の間隔
for(stride = blockDim.x/2; stride >= 1; stride>>=1){
if(tx < stride){
s_idata[tx] = s_idata[tx]+s_idata[tx+stride];
}
__syncthreads();
}
if(tx==0) odata[blockIdx.x] = s_idata[tx];
}
GPUプログラム(Ver.6)
2015/06/03GPGPU実践プログラミング39
reduction6.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-39-320.jpg)
![各Stepでの総和計算(Step 1)
2015/06/03GPGPU実践プログラミング40
グローバルメモリから共有メモリへデー
タをコピー
1スレッドが2点読み込んで加算
1点目と2点目の間隔はスレッド数(=NT=
blockDim.x)と等しい
スレッド0がidata[0]とidata[0+4]
スレッド1がidata[1]とidata[1+4]
スレッド2がidata[2]とidata[2+4]
スレッド3がidata[3]とidata[3+4]
stride
が4の段
__shared__ volatile int s_idata[NT];
s_idata[tx] = idata[i] + idata[i+blockDim.x];
__syncthreads();
T0
+ + + +
+ +
+
T1 T2 T3
s_idata[i]
idata[i]](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-40-320.jpg)
![+ + + +
+ +
+
各Stepでの総和計算(Step 2)
2015/06/03GPGPU実践プログラミング41
ストライドを1/2倍しながら,処理を実行
するスレッドを決定
ストライドよりもスレッド番号が小さいスレッド
連続なスレッドが連続な配列要素にアクセス
スレッド0がs_idata[0]とs_idata[0+2]
スレッド1がs_idata[1]とs_idata[1+2]
総和の計算はVer.5と同じ
stride
が2の段
for(stride = blockDim.x/2; stride >= 1;
stride>>=1){
if(tx < stride){
s_idata[tx]=s_idata[tx]+s_idata[tx+stride];
}
__syncthreads();
}
T0 T1](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-41-320.jpg)
![各Stepでの総和計算(Step 3)
2015/06/03GPGPU実践プログラミング42
ストライドを1/2倍しながら,処理を実行
するスレッドを決定
ストライドよりもスレッド番号が小さいスレッド
連続なスレッドが連続な配列要素にアクセス
スレッド0がs_idata[0]とs_idata[0+1]
総和の計算はVer.5と同じ
stride
が1の段
for(stride = blockDim.x/2; stride >= 1;
stride>>=1){
if(tx < stride){
s_idata[tx]=s_idata[tx]+s_idata[tx+stride];
}
__syncthreads();
} + + + +
+ +
+
T0](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-42-320.jpg)
![実行時間
2015/06/03GPGPU実践プログラミング
カーネル
N=512 N=1024
実行時間
[s]
データ転送
[GB/s]
実行時間
[s]
データ転送
[GB/s]
0 54.6 0.035 121 0.032
1 9.73 0.196 12.8 0.297
2 10.9 0.175 15.9 0.240
4 10.8 0.177 14.8 0.258
5 6.91 0.276 8.70 0.438
6 6.40 0.298 7.07 0.540
7
8
43](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-43-320.jpg)

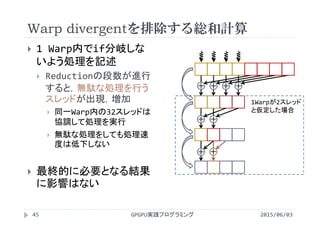

![__global__ void reduction7(int *idata,int *odata){
int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;//スレッドと配列要素の対応
int tx = threadIdx.x; //スレッド番号
int stride; //”隣”の配列要素までの距離
//入力データの数に応じて必要な共有メモリサイズが変化
__shared__ volatile int s_idata[smemSize];
//グローバルメモリから共有メモリへデータをコピー.1スレッドが2点読み込んで加算
s_idata[tx] = idata[i] + idata[i+blockDim.x];
__syncthreads();
//ストライドが32より大きい(=処理を実行するスレッドが32以上)場合にループ内の処理を実行
for(stride = blockDim.x/2; stride > 32; stride>>=1){
if(tx < stride){
s_idata[tx] = s_idata[tx]+s_idata[tx+stride];
}
__syncthreads();
}
GPUプログラム(Ver.7)
2015/06/03GPGPU実践プログラミング47
reduction7.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-47-320.jpg)
![//処理を実行するスレッドが32(1 Warp内の0~31)になると処理を切替
//0~31スレッド全てが協調してif文内の処理を実行するため,__syncthreads();が不要
if(tx<32){
if(blockDim.x>=64) s_idata[tx] += s_idata[tx+32]; //if(blockDim.x>=??)は
if(blockDim.x>=32) s_idata[tx] += s_idata[tx+16]; //入力データ数が64以下の条件
if(blockDim.x>=16) s_idata[tx] += s_idata[tx+ 8]; //で正しく結果を求めるために必要
if(blockDim.x>= 8) s_idata[tx] += s_idata[tx+ 4]; //
if(blockDim.x>= 4) s_idata[tx] += s_idata[tx+ 2]; //
if(blockDim.x>= 2) s_idata[tx] += s_idata[tx+ 1]; //
}
if(tx==0) odata[blockIdx.x] = s_idata[0];
}
GPUプログラム(Ver.7)
2015/06/03GPGPU実践プログラミング48
reduction7.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-48-320.jpg)
![1 Warp内での総和計算
2015/06/03GPGPU実践プログラミング49
スレッド数(=ストライド)が1 Warp以下
になるまでの処理はこれまでと同じ
1 Warp内で分岐せず,32スレッドが加
算を実行
計算を進行すると無意味な値が配列内に書
き込まれる
必要な値(部分和や総和)には影響しない
同期が不要
同期待ち時間が解消されて高速化?
if(tx<32){
if(blockDim.x>=64) s_idata[tx]+=s_idata[tx+32];
if(blockDim.x>=32) s_idata[tx]+=s_idata[tx+16];
if(blockDim.x>=16) s_idata[tx]+=s_idata[tx+ 8];
if(blockDim.x>= 8) s_idata[tx]+=s_idata[tx+ 4];
if(blockDim.x>= 4) s_idata[tx]+=s_idata[tx+ 2];
if(blockDim.x>= 2) s_idata[tx]+=s_idata[tx+ 1];
}
+ + + +
+ +
+
1Warpが4スレッド
と仮定した場合
+ +
+ + +](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-49-320.jpg)



![共有メモリの要素数の決定
2015/06/03GPGPU実践プログラミング53
配列要素数が64以下(スレッド数が32[1warp]以下)
配列外参照を回避するため,共有メモリを大きめに確保
+ + + +
+ +
+
+ +
+ + +
+ + + +
+ +
+
+ +
+ + +
1Warp8スレッド,
N=16を想定
スレッド数8
(1Warp)
共有メモリの要
素数8
Ver.6までと同
じように宣言す
ると,配列外参
照が発生
グローバルメモリから共有メモリへ
コピー+加算
16‐>88‐>44‐>2](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-53-320.jpg)
![共有メモリの要素数の決定
2015/06/03GPGPU実践プログラミング54
配列要素数が64以下(スレッド数が32[1warp]以下)
配列外参照を回避するため,共有メモリを大きめに確保
+ + + +
+ +
+
+ +
+ + +
+ + + +
+ +
+
+ +
+ + +
1Warp8スレッド,
N=16を想定
スレッド数8
(1Warp)
共有メモリの要
素数8
Ver.6までと同
じように宣言す
ると,配列外参
照が発生
グローバルメモリから共有メモリへ
コピー+加算
無駄な計算に
伴って発生する
配列外参照
16‐>88‐>44‐>2](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-54-320.jpg)
![共有メモリの要素数の決定
2015/06/03GPGPU実践プログラミング55
配列要素数が64以下(スレッド数が32[1warp]以下)
配列外参照を回避するため,共有メモリを大きめに確保
+ + + +
+ +
+
+ +
+ + +
+ + + +
+ +
+
+ +
+ + +
1Warp8スレッド,
N=16を想定
スレッド数8
(1Warp)
共有メモリの要
素数8+4
+4は配列外参
照に備えて余分
に確保される分
スレッド数の1/2
グローバルメモリから共有メモリへ
コピー+加算
配列外参照に
備えて余分に
確保
16‐>88‐>44‐>2](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-55-320.jpg)

![実行時間
2015/06/03GPGPU実践プログラミング
カーネル
N=512 N=1024
実行時間
[s]
データ転送
[GB/s]
実行時間
[s]
データ転送
[GB/s]
0 54.6 0.035 121 0.032
1 9.73 0.196 12.8 0.297
2 10.9 0.175 15.9 0.240
4 10.8 0.177 14.8 0.258
5 6.91 0.276 8.70 0.438
6 6.40 0.298 7.07 0.540
7 5.28 0.361 5.82 0.655
57](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-57-320.jpg)


![template
2015/06/03GPGPU実践プログラミング60
型以外のテンプレートパラメータ
コンパイル時に値が決まる定数や式をテンプレート引数として
関数に渡すことが可能
型以外のテンプレートパラメータのみを指定することも可能
template<int smemSize>
__global__ void reduction(int *idata, int *odata){
...
__shared__ volatile int s_idata[smemSize];
...
}
int main(void){
...
reduction<64><<<NB, NT>>>(idata, odata);
...
}](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-60-320.jpg)

![//blockArraySize(1ブロックが処理する配列要素数=スレッド数の2倍)をテンプレートパラメータ
//としてテンプレート関数を記述
template <unsigned int blockArraySize>
__global__ void reduction8(int *idata, int *odata){
int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;//スレッドと配列要素の対応
int tx = threadIdx.x; //スレッド番号
//入力データの数に応じて必要な共有メモリサイズが変化
__shared__ volatile int s_idata[smemSize];
if(blockArraySize == 1) return; //1ブロックあたりに処理する配列要素が1なら
//関数を終了
//グローバルメモリから共有メモリへデータをコピー.1スレッドが2点読み込んで加算
s_idata[tx] = idata[i] + idata[i+blockDim.x];
__syncthreads();
GPUプログラム(Ver.8)
2015/06/03GPGPU実践プログラミング62
reduction8.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-62-320.jpg)
![if(blockArraySize >= 2048){
if(tx < 512){ s_idata[tx] += s_idata[tx+512];} __syncthreads();
}
if(blockArraySize >= 1024){
if(tx < 256){ s_idata[tx] += s_idata[tx+256];} __syncthreads();
}
if(blockArraySize >= 512){
if(tx < 128){ s_idata[tx] += s_idata[tx+128];} __syncthreads();
}
if(blockArraySize >= 256){
if(tx < 64){ s_idata[tx] += s_idata[tx+ 64];} __syncthreads();
}
if(tx<32){
if(blockArraySize >= 128) s_idata[tx] += s_idata[tx+32];
if(blockArraySize >= 64) s_idata[tx] += s_idata[tx+16];
if(blockArraySize >= 32) s_idata[tx] += s_idata[tx+ 8];
if(blockArraySize >= 16) s_idata[tx] += s_idata[tx+ 4];
if(blockArraySize >= 8) s_idata[tx] += s_idata[tx+ 2];
if(blockArraySize >= 4) s_idata[tx] += s_idata[tx+ 1];
}
if(tx==0) odata[blockIdx.x] = s_idata[tx];
}
GPUプログラム(Ver.8)
2015/06/03GPGPU実践プログラミング63
reduction8.cu
blockArraySizeはコンパイル時に
確定するため,if文は最適化される](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-63-320.jpg)


![__shared__ volatile int s_idata[512];
s_idata[i] = idata[i] + idata[i+blockDim.x]; //1024‐>512
__syncthreads();
if(tx < 256){ s_idata[tx] += s_idata[tx+256];} __syncthreads(); //512‐>256
if(tx < 128){ s_idata[tx] += s_idata[tx+128];} __syncthreads(); //256‐>128
if(tx < 64){ s_idata[tx] += s_idata[tx+ 64];} __syncthreads(); //128‐> 64
if(tx<32){
s_idata[tx] += s_idata[tx+32]; // 64‐> 32
s_idata[tx] += s_idata[tx+16]; // 32‐> 16
s_idata[tx] += s_idata[tx+ 8]; // 16‐> 8
s_idata[tx] += s_idata[tx+ 4]; // 8‐> 4
s_idata[tx] += s_idata[tx+ 2]; // 4‐> 2
s_idata[tx] += s_idata[tx+ 1]; // 2‐> 1
}
if(tx==0) odata[0] = s_idata[tx];
実体化されたカーネル(あくまで予想)
2015/06/03GPGPU実践プログラミング66](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-66-320.jpg)
![実行時間
2015/06/03GPGPU実践プログラミング
カーネル
N=512 N=1024
実行時間
[s]
データ転送
[GB/s]
実行時間
[s]
データ転送
[GB/s]
0 54.6 0.035 121 0.032
1 9.73 0.196 12.8 0.297
2 10.9 0.175 15.9 0.240
4 10.8 0.177 14.8 0.258
5 6.91 0.276 8.70 0.438
6 6.40 0.298 7.07 0.540
7 5.28 0.361 5.82 0.655
8 5.15 0.370 5.60 0.681
67](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-67-320.jpg)

![#include<stdio.h>
#include<stdlib.h>
#define N (1024)
#define Nbytes (N*sizeof(int))
#define NPB (512) //1ブロックが部分和を計算する配列要素数(Number of Points per Block)
#define NT (NPB/2) //1ブロックあたりのスレッド数
#define NB (N/NPB) //ブロック数
//関数形式マクロで共有メモリサイズを決定
#define smemSize(x) ( ((x)>32)*x + ((x)<=32)*((x)+(x)/2) )
template <unsigned int blockArraySize>
__global__ void reduction9(int *idata,int *odata){
//共有メモリの宣言以外,内容はVer.8と同じなので省略
__shared__ volatile int s_idata[smemSize(blockArraySize/2)];
}
void init(int *idata){
//初期化の内容は同じなので省略
}
GPUプログラム(Ver.9)
2015/06/03GPGPU実践プログラミング69
reduction9.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-69-320.jpg)



![#include<stdio.h>
#include<stdlib.h>
#define N (1024)
#define Nbytes (N*sizeof(int))
#define NPB (512) //1ブロックが部分和を計算する配列要素数(Number of Points per Block)
#define NT (NPB/2) //1ブロックあたりのスレッド数
#define NB (N/NPB) //ブロック数
template <unsigned int blockArraySize>
__global__ void reduction9(int *idata,int *odata){
//共有メモリの宣言以外,内容はVer.8と同じなので省略
extern __shared__ volatile int s_idata[];
}
void reduction(int *idata, int *odata, int numBlock, int numThread){
//内容は2枚後のスライド
}
void init(int *idata){
//初期化の内容は同じなので省略
}
GPUプログラム(Ver.9.1)
2015/06/03GPGPU実践プログラミング73
reduction9switch.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-73-320.jpg)



![実行時間
2015/06/03GPGPU実践プログラミング
入力データの個数N = 8192
1ブロックあたりのスレッド数NT=256
カーネル 実行時間 [s] データ転送[GB/s]
3.2 16.3 1.88
9.1 7.81 3.92
77](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-77-320.jpg)
![#include<stdio.h>
#include<stdlib.h>
#define N (1024*1024*8)
#define Nbytes ((unsigned int)N*sizeof(int))
#include"kernel3.cu"
//#include"kernel4.cu"
//#include"kernel5.cu"
//#include"kernel6.cu"
//#include"kernel7.cu"
//#include"kernel8.cu"
//#include"kernel9.cu"
void init(int *idata){//初期化
int i;
for(i=0;i<N;i++){
idata[i] = 1;
}
}
大きな配列の総和
2015/06/03GPGPU実践プログラミング
Ver.3.4との組合せ
78
reduction.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-78-320.jpg)


![#define NT (256)
#define NB (N/NT)
__global__ void reduction_kernel(int *idata, int *odata){
int i = blockIdx.x*blockDim.x + threadIdx.x;
int tx = threadIdx.x;
int stride;
extern __shared__ volatile int s_idata[];
s_idata[tx] = idata[i];
__syncthreads();
for(stride = 1; stride <= blockDim.x/2; stride<<=1){
if(tx%(2*stride) == 0){
s_idata[tx] = s_idata[tx]+s_idata[tx+stride];
}
__syncthreads();
}
if(tx==0) odata[blockIdx.x] = s_idata[tx];
}
kernel3
2015/06/03GPGPU実践プログラミング81
kernel3.cu
スレッド :不連続
ストライド:ステップ毎に増加](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-81-320.jpg)
![#define NT (256)
#define NB (N/NT)
__global__ void reduction_kernel(int *idata, int *odata){
int i = blockIdx.x*blockDim.x + threadIdx.x;
int tx = threadIdx.x;
int j;
int stride;
extern __shared__ volatile int s_idata[];
s_idata[tx] = idata[i];
__syncthreads();
for(stride = 1; stride <= blockDim.x/2; stride<<=1){
j = 2*stride * tx;
if(j < blockDim.x){
s_idata[j] = s_idata[j]+s_idata[j+stride];
}
__syncthreads();
}
if(tx==0) odata[blockIdx.x] = s_idata[tx];
}
kernel4
2015/06/03GPGPU実践プログラミング82
kernel4.cu
スレッド :小さい順に連続
ストライド:ステップ毎に増加](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-82-320.jpg)
![#define NT (256)
#define NB (N/NT)
__global__ void reduction_kernel(int *idata, int *odata){
int i = blockIdx.x*blockDim.x + threadIdx.x;
int tx = threadIdx.x;
int stride;
extern __shared__ volatile int s_idata[];
s_idata[tx] = idata[i];
__syncthreads();
for(stride = blockDim.x/2; stride >= 1; stride>>=1){
if(tx < stride){
s_idata[tx] = s_idata[tx]+s_idata[tx+stride];
}
__syncthreads();
}
if(tx==0) odata[blockIdx.x] = s_idata[0];
}
kernel5
2015/06/03GPGPU実践プログラミング83
kernel5.cu
スレッド :小さい順に連続
ストライド:ステップ毎に減少](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-83-320.jpg)
![int reduction(int *idata){
int numBlock, numThread, smemSize;
int *odata;
int result;
numThread = NT;
smemSize = numThread*sizeof(int);
numBlock = NB;
cudaMalloc( (void **)&odata,
numBlock*sizeof(int));
reduction_kernel<<< numBlock, numThread,
smemSize>>>(idata, odata);
while(numBlock>NT){
numBlock /= NT;
reduction_kernel<<< numBlock, numThread,
smemSize>>>(odata, odata);
}
numThread = numBlock;
smemSize = numThread*sizeof(int);
numBlock = 1;
if(numThread>1)
reduction_kernel<<< numBlock, numThread,
smemSize>>>(odata, odata);
cudaMemcpy(&result, &odata[0],
sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(odata);
return result;
}
kernel3,4,5
2015/06/03GPGPU実践プログラミング84
kernel[3‐5].cu
Ver.3.4から変更無し](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-84-320.jpg)
![#define NPB (512)
#define NT (NPB/2)
#define NB (N/NPB)
__global__ void reduction_kernel(int *idata, int *odata){
int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
int tx = threadIdx.x;
int stride;
extern __shared__ volatile int s_idata[];
s_idata[tx] = idata[i] + idata[i+blockDim.x];
__syncthreads();
for(stride = blockDim.x/2; stride >= 1; stride>>=1){
if(tx < stride){
s_idata[tx] = s_idata[tx]+s_idata[tx+stride];
}
__syncthreads();
}
if(tx==0) odata[blockIdx.x] = s_idata[0];
}
kernel6
2015/06/03GPGPU実践プログラミング85
kernel6.cu
+スレッド数を1/2に削減スレッド :小さい順に連続
ストライド:ステップ毎に増加](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-85-320.jpg)
![int reduction(int *idata){
int numBlock, numThread, smemSize;
int *odata;
int result;
numThread = NT;
smemSize = numThread*sizeof(int);
numBlock = NB;
cudaMalloc( (void **)&odata,
numBlock*sizeof(int));
reduction_kernel<<< numBlock, numThread,
smemSize>>>(idata, odata);
while(numBlock>NPB){
numBlock /= NPB;
reduction_kernel<<< numBlock, numThread,
smemSize>>>(odata, odata);
}
numThread = numBlock/2;
smemSize = numThread*sizeof(int);
numBlock = 1;
if(numThread>1)
reduction_kernel<<< numBlock, numThread,
smemSize>>>(odata, odata);
cudaMemcpy(&result, &odata[0],
sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(odata);
return result;
}
kernel6
2015/06/03GPGPU実践プログラミング86
kernel6.cu
スレッド数と1ブロックが処理する配列要素数を区別](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-86-320.jpg)
![#define NPB (512)
#define NT (NPB/2)
#define NB (N/NPB)
__global__ void reduction_kernel(int *idata, int *odata){
int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
int tx = threadIdx.x;
int stride;
extern __shared__ volatile int s_idata[];
s_idata[tx] = idata[i] + idata[i+blockDim.x];
__syncthreads();
for(stride = blockDim.x/2; stride > 32; stride>>=1){
if(tx < stride){
s_idata[tx] += s_idata[tx+stride];
}
__syncthreads();
}
kernel7
2015/06/03GPGPU実践プログラミング87
kernel7.cu
+Warp内の処理を展開
スレッド :小さい順に連続
ストライド:ステップ毎に増加
+スレッド数を1/2に削減](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-87-320.jpg)
![if(tx<32){
if(blockDim.x>=64)s_idata[tx] += s_idata[tx+32];
if(blockDim.x>=32)s_idata[tx] += s_idata[tx+16];
if(blockDim.x>=16)s_idata[tx] += s_idata[tx+ 8];
if(blockDim.x>= 8)s_idata[tx] += s_idata[tx+ 4];
if(blockDim.x>= 4)s_idata[tx] += s_idata[tx+ 2];
if(blockDim.x>= 2)s_idata[tx] += s_idata[tx+ 1];
}
if(tx==0) odata[blockIdx.x] = s_idata[tx];
}
kernel7
2015/06/03GPGPU実践プログラミング88
kernel7.cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-88-320.jpg)
![int reduction(int *idata){
int numBlock, numThread, smemSize;
int *odata;
int result;
numThread = NT;
smemSize = numThread*sizeof(int);
if(numThread<=32)
smemSize += (numThread/2)*sizeof(int);
numBlock = NB;
cudaMalloc( (void **)&odata,
numBlock*sizeof(int));
reduction_kernel<<< numBlock, numThread,
smemSize>>>(idata, odata);
while(numBlock>NPB){
numBlock /= NPB;
reduction_kernel<<< numBlock, numThread,
smemSize>>>(odata, odata);
}
numThread = numBlock/2;
smemSize = numThread*sizeof(int);
if(numThread<=32)
smemSize += (numThread/2)*sizeof(int);
numBlock = 1;
if(numThread>1)
reduction_kernel<<< numBlock, numThread,
smemSize>>>(odata, odata);
cudaMemcpy(&result, &odata[0],
sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(odata);
return result;
}
kernel7
2015/06/03GPGPU実践プログラミング89
kernel7.cu
スレッド数に応じて共有メモリ要素数を変更](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-89-320.jpg)
![#define NPB (512)
#define NT (NPB/2)
#define NB (N/NPB)
template <unsigned int blockArraySize>
__global__ void reduction_kernel(int *idata, int *odata){
int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
int tx = threadIdx.x;
extern __shared__ volatile int s_idata[];
s_idata[tx] = idata[i] + idata[i+blockDim.x];
__syncthreads();
kernel8,9
2015/06/03GPGPU実践プログラミング90
kernel[8‐9].cu
+template
による展開+Warp内の処理を展開
スレッド :小さい順に連続
ストライド:ステップ毎に増加
+スレッド数を1/2に削減](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-90-320.jpg)
![if(blockArraySize >= 2048){
if(tx < 512){ s_idata[tx] += s_idata[tx+512];} __syncthreads();
}
if(blockArraySize >= 1024){
if(tx < 256){ s_idata[tx] += s_idata[tx+256];} __syncthreads();
}
if(blockArraySize >= 512){
if(tx < 128){ s_idata[tx] += s_idata[tx+128];} __syncthreads();
}
if(blockArraySize >= 256){
if(tx < 64){ s_idata[tx] += s_idata[tx+ 64];} __syncthreads();
}
if(tx<32){
if(blockArraySize >= 128)s_idata[tx] += s_idata[tx+32];
if(blockArraySize >= 64)s_idata[tx] += s_idata[tx+16];
if(blockArraySize >= 32)s_idata[tx] += s_idata[tx+ 8];
if(blockArraySize >= 16)s_idata[tx] += s_idata[tx+ 4];
if(blockArraySize >= 8)s_idata[tx] += s_idata[tx+ 2];
if(blockArraySize >= 4)s_idata[tx] += s_idata[tx+ 1];
}
if(tx==0) odata[blockIdx.x] = s_idata[tx];
}
kernel8,9
2015/06/03GPGPU実践プログラミング91
kernel[8‐9].cu](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-91-320.jpg)
![int reduction(int *idata){
int numBlock, numThread, smemSize;
int *odata;
int result;
numThread = NT;
if(numThread<=32)
smemSize += (numThread/2)*sizeof(int);
numBlock = NB;
cudaMalloc( (void **)&odata,
numBlock*sizeof(int));
reduction_kernel<NPB><<< numBlock, numThread,
smemSize>>>(idata, odata);
while(numBlock>NPB){
numBlock /= NPB;
reduction_kernel<NPB><<< numBlock,
numThread, smemSize>>>(odata, odata);
}
numThread = numBlock/2;
smemSize = numThread*sizeof(int);
if(numThread<=32)
smemSize += (numThread/2)*sizeof(int);
numBlock = 1;
if(numThread>1)
//数字を何らかの方法で確定する必要がある
reduction_kernel<32><<< numBlock, numThread,
smemSize>>>(odata, odata);
cudaMemcpy(&result, &odata[0],
sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(odata);
return result;
}
kernel8
2015/06/03GPGPU実践プログラミング92
kernel8.cu
templateパラメータの記述(最終ステップのパラメータを
何らかの方法で確定する必要がある)](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-92-320.jpg)
![int reduction(int *idata){
int numBlock, numThread;
int *odata;
int result;
numThread = NT;
numBlock = NB;
cudaMalloc( (void **)&odata,
numBlock*sizeof(int));
invokeReductionKernel(idata, odata,
numBlock, numThread);
while(numBlock>NPB){
numBlock /= NPB;
invokeReductionKernel(odata, odata,
numBlock, numThread);
}
numThread = numBlock/2;
numBlock = 1;
if(numThread>1)
invokeReductionKernel(odata, odata,
numBlock, numThread);
cudaMemcpy(&result, &odata[0],
sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(odata);
return result;
}
kernel9
2015/06/03GPGPU実践プログラミング93
kernel9.cu
switch文によるtemplateパラメータの列挙
(新たに関数を一つ導入)](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-93-320.jpg)
![void invokeReductionKernel(int *idata, int *odata, int numBlock, int numThread){
int smemSize = sizeof(idata[0])*numThread;
if(numThread<=32) smemSize += sizeof(idata[0])*numThread/2;
switch(numThread){
case 1024:
reduction_kernel<1024*2><<< numBlock, numThread , smemSize >>>(idata, odata);
break;
case 512:
reduction_kernel< 512*2><<< numBlock, numThread , smemSize >>>(idata, odata);
break;
case 256:
reduction_kernel< 256*2><<< numBlock, numThread , smemSize >>>(idata, odata);
break;
case 128:
reduction_kernel< 128*2><<< numBlock, numThread , smemSize >>>(idata, odata);
break;
case 64:
reduction_kernel< 64*2><<< numBlock, numThread , smemSize >>>(idata, odata);
break;
case 32:
reduction_kernel< 32*2><<< numBlock, numThread , smemSize >>>(idata, odata);
break;
kernel9
2015/06/03GPGPU実践プログラミング94
kernel9.cu
スレッド数に応じて適切なtemplateパラメータを選択し,
カーネルを起動する関数](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-94-320.jpg)

![実行時間
2015/06/03GPGPU実践プログラミング
配列要素数N=223
1ブロックあたりのスレッド数 256
理論ピークバンド幅 148 GB/s
カーネル 実行時間 [s] データ転送[GB/s]
3 474×10 6.59
4 248×10 12.6
5 183×10 17.1
6 939 33.3
7 706 44.3
8 519 60.2
9 515 60.7
96
×1.91
×1.36
×1.95
×1.33
×1.36
高速化](https://image.slidesharecdn.com/gpgpuprogramming08-160307051550/85/2015-GPGPU-8-96-320.jpg)























































































