算術演算
加減算
addx, y // x ← x + y;
sub x, y // x ← x – y;
carryつき加減算
adc x, y // x ← x + y + CF; 繰り上がりを加味
sbb x, y // x ← x – y – CF; 繰り下がりを加味
乗算
64bit x 64bit → 128bit
mul x // [rdx:rax] ← x * rax (rax, rdxレジスタ固定)
除算
128bit / 64bit = 64bit あまり 64bit
div x // [rdx:rax] / x ; 商 : rax, あまり : rdx
/ 2810
11.
条件比較
演算結果に応じてフラグが変わる
フラグに応じて条件分岐する
こういうコードはこんな感じ
jg (jmp if greater), jge(jmp if greater or equal)などなど
/ 2811
if (x >= y) {
Aの作業
} else {
Bの作業
}
cmp x, y // x-yの計算結果をCFに反映(CF = x >= y ? 0 : 1)
jnc LABEL_A // jmp to LABEL_A if no carry
Bの作業
jmp NEXT
LABEL_A:
Aの作業
NEXT:










![算術演算
加減算
add x, y // x ← x + y;
sub x, y // x ← x – y;
carryつき加減算
adc x, y // x ← x + y + CF; 繰り上がりを加味
sbb x, y // x ← x – y – CF; 繰り下がりを加味
乗算
64bit x 64bit → 128bit
mul x // [rdx:rax] ← x * rax (rax, rdxレジスタ固定)
除算
128bit / 64bit = 64bit あまり 64bit
div x // [rdx:rax] / x ; 商 : rax, あまり : rdx
/ 2810](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-10-320.jpg)



![256bit加算
記法
xi, yi, ziなどは64bitレジスタを表す
[x3:x2:x1:x0]で256bit整数を表す(x0が最下位の64bit)
256bit整数z[]に256bit整数x[]を足すコードは次の通り
注意
z[], x[]が256bitフルに入ってると結果が257bitになる
今回はpを254bitに選んだため0 <= x, z < pならあふれない
他にも様々な箇所で桁あふれがおきないため処理の簡略化が可能
そのためセキュリティレベルが128bitではなく127bit
/ 2815
// [z3:z2:z1:z0] += [x3:x2:x1:x0]
add z0, x0
adc z1, x1 // carryつき
adc z2, x2 // carryつき
adc z3, x3 // carryつき](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-15-320.jpg)
![256bit加算を関数にする
呼び出し規約にしたがってレジスタを使う
なかなか面倒
XbyakのStackFrameを使うとある程度抽象化、自動化可能
LLVMはより汎用的にできる
/ 2816
//addNC(uint64_t z[4],const uint64_t x[4],const uint64_t y[4]);
void gen_AddNC() {
Xbyak::util::StackFrame sf(this, 3); //引数3個の関数
const Xbyak::Reg64& z = sf.p[0]; // 一つ目の引数
const Xbyak::Reg64& x = sf.p[1]; // 二つ目の引数
const Xbyak::Reg64& y = sf.p[2]; // 三つ目の引数
mov(rax, ptr [x]);
add(rax, ptr [y]);
mov(ptr [z], rax);
for (int i = 1; i < 3; i++) {
mov(rax, ptr [x + i * 8]);
adc(rax, ptr [y + i * 8]);
mov(ptr [z + i * 8], rax);
} }](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-16-320.jpg)
![gen_addNCの結果
WindowsとLinuxのそれぞれに応じたコード生成
StackFrameはスタックを確保したり一時変数を使ったり、
rcx, rdxを特別扱いする指定もできる
自動的にレジスタの退避復元をおこなう
/ 2817
// Windows(引数はrcx,rdx,r8の順)
mov rax,ptr [rdx]
add rax,ptr [r8]
mov ptr [rcx],rax
mov rax,ptr [rdx+8]
adc rax,ptr [r8+8]
mov ptr [rcx+8],rax
mov rax,ptr [rdx+10h]
adc rax,ptr [r8+10h]
mov ptr [rcx+10h],rax
ret
// Linux(引数はrdi,rsi,rdxの順)
mov rax,ptr [rsi]
add rax,ptr [rdx]
mov ptr [rdi],rax
mov rax,ptr [rsi+0x8]
adc rax,ptr [rdx+0x8]
mov ptr [rdi+0x8],rax
mov rax,ptr [rsi+0x10]
adc rax,ptr [rdx+0x10]
mov ptr [rdi+0x10],rax
ret](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-17-320.jpg)
![Fp::addの実装
addNCした結果zがz>=pならばpを引く
if (z >= p) z -= p;
アセンブラレベルでの比較の方法
z=[z3:z2:z1:z0]とx=[x3:x2:x1:x0]はどちらが大きいか
1. 頭から比較する
分岐がきわめて多くなる
連続する分岐命令は好まれない
2. 引いてから考える
分岐は1回
/ 2818
cmp z3, x3
ja z_gt_x // z3 > x3
jb otherwise // z3 < x3
cmp z2, x2 // here z3 == x3
ja z_gt_x // z2 > x2
jb otherwise // z2 < x2
...
z_gt_x:
...
otherwise:tmp_z = z // zの値を退避(mov x 4)
subNC z, p // 引いてみる(z -= p)
jnc .next // z >= 0ならnextへ
z = tmp_z // zの値を復元(mov x 4)
.next:](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-18-320.jpg)

![Fp::subの実装
subNCした結果が負ならpを足す
addと違ってsubNCした時のCFを見ればよいので比較不要
分岐を使った実装
cmovを使った実装
0クリア
cmov + メモリロード
加算
結構命令数が多いので分岐に対してそれほどメリットがない
cmovを使わない実装
命令数は同じだが
cmovよりは速い@sandy
/ 2820
// z -= xの直後
jnc .next
z[] += p[]
.next:
t[] = 0
cmovc t[] p[] //t[] = CF ? p[0] : 0
z[] += t[]
sbb t, t // t = CF ? -1 : 0
and t[], p[] // t = CF ? p : 0
z[] += t[]](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-20-320.jpg)
![256ビット加減算の命令順序
メモリから読んで演算する二つの方式
方式A(メモリまとめ読み) 方式B(メモリと演算を交互に)
実験によるとどちらが速いかCPUにより異なる
Opteron, i7は方式Aが速い Westmereは方式Bが速かった
out of orderだから関係ないと思ったが1%弱違った
実行時のCPU判別によりいずれかを選択
上記方式はコード全般にわたって適用される
/ 2821
z0 ← x[0]
z1 ← x[1]
z2 ← x[2]
z3 ← x[3]
z0 ← z0 + y[0]
z1 ← z1 + y[1] with carry
z2 ← z2 + y[2] with carry
z3 ← z3 + y[3] with carry
z0 ← x[0]
z0 ← z0 + y[0]
z1 ← x[1]
z1 ← z1 + y[1] with carry
z2 ← x[2]
z2 ← z2 + y[2] with carry
z3 ← x[3]
z3 ← z3 + y[3] with carry](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-21-320.jpg)
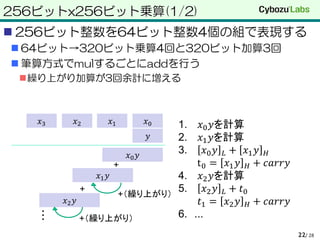
を計算
2. それらをまとめて加算
↓
加算は4回
𝑥3 𝑥2 𝑥1 𝑥0
𝑦
𝑥0 𝑦
𝑥1 𝑦
𝑥2 𝑦
𝑥3 𝑦
加算が終わるまでどこかに
保持する必要がある](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-23-320.jpg)
![256ビットx256ビット乗算 for Haswell
HaswellではCFを変更しないmulxが導入された
加算(add, adc)しつつ乗算を繰り返しおこなえる
必要なレジスタ数が減る
退避、復元のためのmov命令が減る
Montgomery reductionにも適用可能
ペアリング全体で13%の高速化
1.33Mclkから1.17Mclkへ(@Core i7 4700MQ 2.4GHz)
/ 2824
mov(a, ptr [py]); | ↓
mul(x); | mul(x);
mov(t0, a); | mov(t3, a);
mov(t1, d); | mov(a, x);
mov(a, ptr [py + 8]); | mov(x, d);
mul(x); | mul(qword [py + 24]);
mov(t, a); | add(t1, t);
mov(t2, d); | adc(t2, t3);
mov(a, ptr [py + 16]);| adc(x, a);
↓ | adc(d, 0);
mov(d, x);
mulx(t1, t0, ptr [py]);
mulx(t2, a, ptr [py + 8]);
add(t1, a);
mulx(x, a, ptr [py + 16]);
adc(t2, a);
mulx(d, a, ptr [py + 24]);
adc(x, a);
adc(d, 0);](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-24-320.jpg)

![記法の簡便さと演算性能
z = x + y;とFp::add(z, x, y);
一般的に前者の方が書きやすく可読性も高い
しかし隠れた一時変数の生成とコピーに注意する
x + yの結果をtmpに保存
してz = tmpを実行
方針
最初は数式を書きやすい
前者で始める
動くことがわかったら
一時変数や移動を減らす
ように後者に置き換える
式Templateによる一時変数
除去テクニックはあるが
正直使いにくい、挙動を
把握しにくいため勧めない
/ 2827
// Fp::add(z, x, y);
lea r8,[y]
lea rdx,[x]
lea rcx,[z]
call [mie::Fp::add]
// z = x + y;
lea r8,[rbp+7]
lea rdx,[rbp-19h]
lea rcx,[rbp-39h]
call [mie::Fp::add]
movaps xmm0,[rbp-39h] //データ移動
movaps [rbp+37h],xmm0
movaps xmm1,[rbp-29h]
movaps [rbp+47h],xmm1](https://image.slidesharecdn.com/ate-130706075734-phpapp02/85/optimal-Ate-pairing-27-320.jpg)