長岡技術科学大学
2015年度GPGPU実践基礎工学(全15回,学部3年対象講義)
第11回GPUでの並列�プログラミング(ベクトル和)
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
・第2回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu2
・第3回 GPUクラスタ上でのプログラミング(CUDA)
http://www.slideshare.net/ssuserf87701/2015gpgpu3
・第4回 CPUのアーキテクチャ
http://www.slideshare.net/ssuserf87701/2015gpgpu4
・第5回 ハードウェアによるCPUの高速化技術
http://www.slideshare.net/ssuserf87701/2015gpgpu5
・第6回 ソフトウェアによるCPUの高速化技術
http://www.slideshare.net/ssuserf87701/2015gpgpu6
・第7回 シングルコアとマルチコア
http://www.slideshare.net/ssuserf87701/2015gpgpu7
・第8回 並列計算の概念(プロセスとスレッド)
http://www.slideshare.net/ssuserf87701/2015gpgpu8
・第9回 GPUのアーキテクチャ
http://www.slideshare.net/ssuserf87701/2015gpgpu9
・第9回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59160061
・第10回 GPGPUのプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu10
・第11回 GPUでの並列プログラミング(ベクトル和)
http://www.slideshare.net/ssuserf87701/2015gpgpu11
・第12回 GPUによる画像処理
http://w ww.slideshare.net/ssuserf87701/2015gpgpu12
・第13回GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu13
・第14回 GPGPU組込開発環境
http://www.slideshare.net/ssuserf87701/2015gpgpu14
・第15回 GPGPUの開発環境(OpenCL)
http://www.slideshare.net/ssuserf87701/2015gpgpu15
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
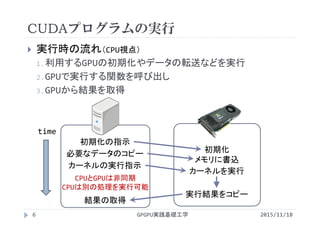
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3





![ベクトル和C=A+Bの計算
配列要素に対して計算順序の依存性がなく,最も単純に
並列化可能
配列a, b, cの配列要素番号iが同じ
・・・
・・・
・・・c[i]
a[i]
b[i]
+ + + + + +
GPGPU実践基礎工学7 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-7-320.jpg)
![#define N (1024*1024)
void init(float *a, float *b,
float *c){
int i;
for(i=0; i<N; i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
}
void add(float *a, float *b,
float *c){
int i;
for(i=0; i<N; i++)
c[i] = a[i] + b[i];
}
int main(void){
float a[N],b[N],c[N];
init(a,b,c);
add(a,b,c);
return 0;
}
CPUプログラム(メモリの静的確保)
GPGPU実践基礎工学
vectoradd.c
8 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-8-320.jpg)
![#include<stdlib.h>
#define N (1024*1024)
#define Nbytes (N*sizeof(float))
void init(float *a, float *b,
float *c){
int i;
for(i=0; i<N; i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
}
void add(float *a, float *b,
float *c){
int i;
for(i=0; i<N; i++)
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
a = (float *)malloc(Nbytes);
b = (float *)malloc(Nbytes);
c = (float *)malloc(Nbytes);
init(a,b,c);
add(a,b,c);
free(a);
free(b);
free(c);
return 0;
}
CPUプログラム(メモリの動的確保)
GPGPU実践基礎工学9
vectoradd_malloc.c
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-9-320.jpg)


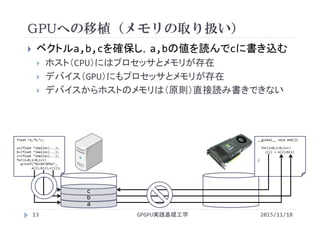
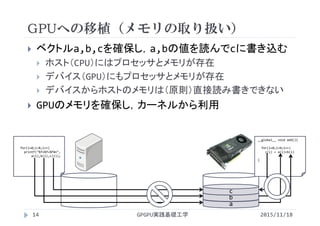

![#include<stdlib.h>
#define N (1024*1024)
#define Nbytes (N*sizeof(float))
void init(float *a, float *b,
float *c){
int i;
for(i=0; i<N; i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
}
void add(float *a, float *b,
float *c){
int i;
for(i=0; i<N; i++)
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
a = (float *)malloc(Nbytes);
b = (float *)malloc(Nbytes);
c = (float *)malloc(Nbytes);
init(a,b,c);
add(a,b,c);
free(a);
free(b);
free(c);
return 0;
}
CPUプログラム(メモリの動的確保)
GPGPU実践基礎工学16
vectoradd_malloc.c
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-16-320.jpg)
![#define N (1024*1024)
#define Nbytes (N*sizeof(float))
__global__ void init(float *a,float *b,
float *c){
int i;
for(i=0; i<N; i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
}
__global__ void add(float *a,float *b,
float *c){
int i;
for(i=0; i<N; i++)
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
cudaMalloc((void **)&a, Nbytes);
cudaMalloc((void **)&b, Nbytes);
cudaMalloc((void **)&c, Nbytes);
init<<< 1, 1>>>(a,b,c);
add<<< 1, 1>>>(a,b,c);
cudaDeviceSynchronize();
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}
GPUプログラム(1スレッド実行版)
GPGPU実践基礎工学
vectoradd_1thread.cu
17 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-17-320.jpg)
![#define N (1024*1024)
#define Nbytes (N*sizeof(float))
__global__ void init(float *a,float *b,
float *c){
int i;
for(i=0; i<N; i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
}
__global__ void add(float *a,float *b,
float *c){
int i;
for(i=0; i<N; i++)
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
cudaMalloc((void **)&a, Nbytes);
cudaMalloc((void **)&b, Nbytes);
cudaMalloc((void **)&c, Nbytes);
init<<< 1, 1>>>(a,b,c);
add<<< 1, 1>>>(a,b,c);
cudaDeviceSynchronize();
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}
GPUプログラム(1スレッド実行版)
GPGPU実践基礎工学18 2015/11/18
vectoradd_1thread.cu
GPUカーネルの
目印
並列実行の度
合を指定
GPUカーネルの
目印
GPUのメモリに
確保
確保したメモリ
を解放](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-18-320.jpg)
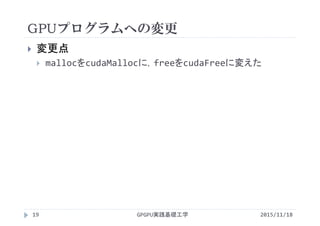


![実行結果
GPGPU実践基礎工学22
プロファイルの一連の流れ
method カーネルや関数(API)の名称
gputime GPU上で処理に要した時間(s単位)
cputime CPUで処理(=カーネル起動)に要した時間
実際の実行時間=cputime+gputime
occupancy GPUがどれだけ効率よく利用されているか
‐bash‐3.2$ nvcc vectoradd_1thread.cu プログラムをコンパイル(実行ファイルa.outが作られる)
‐bash‐3.2$ export CUDA_PROFILE=1 環境変数CUDA_PROFILEを1にしてプロファイラを有効化
‐bash‐3.2$ ./a.out プログラムを実行(cuda_profile_0.logというファイルが作られる)
‐bash‐3.2$ cat cuda_profile_0.log cuda_profile_0.logの内容を画面に表示
# CUDA_PROFILE_LOG_VERSION 2.0
# CUDA_DEVICE 0 Tesla M2050
# TIMESTAMPFACTOR fffff5f8a8002b58
method,gputime,cputime,occupancy
method=[ _Z4initPfS_S_ ] gputime=[ 201039.484 ] cputime=[ 17.000 ] occupancy=[ 0.021 ]
method=[ _Z3addPfS_S_ ] gputime=[ 205958.375 ] cputime=[ 6.000 ] occupancy=[ 0.021 ]
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-22-320.jpg)
![実行結果
GPGPU実践基礎工学23
計算が正しく行われているかの確認
配列c[]の値が全て3.0になっていれば正しい
printfを使って表示
大量に画面表示されて煩わしい
GPUのカーネルには実行時間の制限がある
配列c[]の値の平均を計算
平均が3.0になっていれば正しく実行できているだろうと推察
配列c[]の平均をGPUで計算するのは難しい
CPUで配列c[]の平均を計算
CPUはGPUのメモリを直接読み書きできない
専用の命令を使ってGPUからCPUへコピー
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-23-320.jpg)

![#define N (1024*1024)
#define Nbytes (N*sizeof(float))
__global__
void init(float *a,float *b,float *c){
for(int i=0; i<N; i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
}
__global__
void add(float *a,float *b, float *c){
for(int i=0; i<N; i++)
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
float *host_c, sum=0.0f;
cudaMalloc((void **)&a, Nbytes);
cudaMalloc((void **)&b, Nbytes);
cudaMalloc((void **)&c, Nbytes);
host_c = (float *)malloc(Nbytes);
init<<< 1, 1>>>(a,b,c);
add<<< 1, 1>>>(a,b,c);
cudaMemcpy(host_c,c,Nbytes,
cudaMemcpyDeviceToHost);
for(int i=0;i<N;i++)
sum += host_c[i];
printf("average:%f¥n",sum/N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
free(host_c);
return 0;
}
GPUプログラム(cudaMemcpy利用)
GPGPU実践基礎工学
vectoradd_copy.cu
25 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-25-320.jpg)

![#define N (1024*1024)
#define Nbytes (N*sizeof(float))
__global__ void add(float *a, float x,
float *b, float y, float *c){
for(int i=0; i<N; i++)
c[i] = x*a[i] + y*b[i];
}
int main(void){
float *a,*b,*c;
float *host_a, *host_b, *host_c;
float x=1.0f, y=2.0f;
cudaMalloc((void **)&a, Nbytes);
cudaMalloc((void **)&b, Nbytes);
cudaMalloc((void **)&c, Nbytes);
host_a = (float *)malloc(Nbytes);
host_b = (float *)malloc(Nbytes);
host_c = (float *)malloc(Nbytes);
for(int i=0; i<N; i++){
host_a[i] = 1.0;
host_b[i] = 2.0;
}
cudaMemcpy(a,host_a,Nbytes,
cudaMemcpyHostToDevice);
cudaMemcpy(b,host_b,Nbytes,
cudaMemcpyHostToDevice);
add<<< 1, 1>>>(a, x, b, y, c);
cudaMemcpy(host_c,c,Nbytes,
cudaMemcpyDeviceToHost);
cudaFree(a);
cudaFree(b);
cudaFree(c);
free(host_a);
free(host_b);
free(host_c);
return 0;
}
GPUプログラム
GPGPU実践基礎工学
vectoradd_copy_twoway.cu
27 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-27-320.jpg)
![CUDAでカーネルを作成するときの制限
GPGPU実践基礎工学28
x,yはCPU側のメモリに存在
値渡し
CPU→GPUへ値がコピーされる
host_a,host_b,host_c
もCPU側のメモリに存在
ポインタ渡し(変数のアドレス
を渡す)
GPUは渡されたメモリアドレス
が分かってもCPUのメモリに
アクセスできない
__global__ void add(float *a, float x,
float *b, float y, float *c){
for(int i=0; i<N; i++)
c[i] = x*a[i] + y*b[i];
}
int main(void){
float *a,*b,*c;
float *host_a,host_b,host_c;
float x=1.0, y=2.0;
:
add<<< 1, 1>>>(a, x, b, y, c);
//add<<< 1, 1>>>(host_a, x,
host_b, y,host_c);
:
}
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-28-320.jpg)

![GPUで並列に処理を行うには
配列サイズN=8
総スレッド数を8として並列実行する状況を想定
GPGPU実践基礎工学30
c[i]
a[i]
b[i]
+ + + + + + + +
i= 0 1 2 3 4 5 6 7
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-30-320.jpg)
![GPUによる並列化の方針
forループをスレッドの数だけ分割
各スレッドが少量のデータを処理
i=0
c[i] = a[i] + b[i];スレッド0
c[i]
a[i]
b[i]
+ + + +
スレッド
0
スレッド
2
スレッド
1
スレッド
3
i=1
c[i] = a[i] + b[i];スレッド1
i=2
c[i] = a[i] + b[i];スレッド2
i=3
c[i] = a[i] + b[i];スレッド3
スレッドの番号
に応じて決定
1スレッドが実
行する処理
GPGPU実践基礎工学31 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-31-320.jpg)
![カーネルの書き換え
1スレッドが実行する処理になるよう変更
1スレッドがある添字 i の要素を担当
#define N (8)
#define Nbytes (N*sizeof(float))
__global__ void init(float *a, float *b, float *c){
int i=...;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
__global__ void add(float *a, float *b, float *c){
int i=...;
c[i] = a[i] + b[i];
}
GPGPU実践基礎工学32
1スレッドがあるiの担当となり,変数
の初期化と足し算の計算を実行
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-32-320.jpg)
![カーネルの書き換え
1スレッドが実行する処理になるよう変更
どのようにiを決定するか?
#define N (8)
#define Nbytes (N*sizeof(float))
__global__ void init(float *a, float *b, float *c){
int i=0;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
__global__ void add(float *a, float *b, float *c){
int i=0;
c[i] = a[i] + b[i];
}
全てのスレッドがi=0の
要素を計算してしまう
GPGPU実践基礎工学33 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-33-320.jpg)
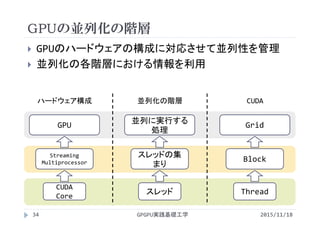


![各スレッドが異なるiを参照するには
CUDAでは並列化に階層がある
全体の領域(グリッド)をブロックに分割
ブロックの中をスレッドに分割
<<<2, 4>>>
ブロックの数 1ブロックあたりの
スレッドの数
ブロックの数×1ブロックあたりのスレッドの数=総スレッド数
2 × 4 = 8
GPGPU実践基礎工学37
[block] [thread/block] [thread]
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-37-320.jpg)
![各スレッドが異なるiを参照するには
N=8, <<<2, 4>>>で実行
c[i]
a[i]
b[i]
+ + + + + + + +
gridDim.x=2
blockIdx.x=0 blockIdx.x=1
blockDim.x=4blockDim.x=4threadIdx.x=
0 1 2 3 0 1 2 3
threadIdx.x=
GPGPU実践基礎工学38
i= 0 1 2 3 4 5 6 7
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-38-320.jpg)
![各スレッドが異なるiを参照するには
N=8, <<<2, 4>>>で実行
c[i]
a[i]
b[i]
+ + + + + + + +
gridDim.x=2
blockIdx.x=0 blockIdx.x=1
blockDim.x=4blockDim.x=4threadIdx.x=
0 1 2 3 0 1 2 3
threadIdx.x=
i= 0 1 2 3 4 5 6 7
= blockIdx.x*blockDim.x + threadIdx.x
GPGPU実践基礎工学39 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-39-320.jpg)
![各スレッドが異なるiを参照するには
N=8, <<<1, 8>>>で実行
c[i]
a[i]
b[i]
+ + + + + + + +
gridDim.x=1
blockIdx.x=0
blockDim.x=8threadIdx.x=
0 1 2 3 4 5 6 7
i= 0 1 2 3 4 5 6 7
= blockIdx.x*blockDim.x + threadIdx.x
2015/11/18GPGPU実践基礎工学40](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-40-320.jpg)
![各スレッドが異なるiを参照するには
N=8, <<<4, 2>>>で実行
c[i]
a[i]
b[i]
+ + + + + + + +
gridDim.x=4
blockIdx.x=0
blockDim.x=2threadIdx.x=
0 1 0 1 0 1 0 1
2015/11/18GPGPU実践基礎工学41
blockIdx.x=1
blockDim.x=2
blockIdx.x=2
blockDim.x=2
blockIdx.x=3
blockDim.x=2
= blockIdx.x*blockDim.x + threadIdx.x
i= 0 1 2 3 4 5 6 7](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-41-320.jpg)
![カーネルの書き換え
1スレッドが実行する処理になるよう変更
1スレッドがある添字 i の要素を担当
#define N (8)
#define Nbytes (N*sizeof(float))
__global__ void init(float *a, float *b, float *c){
int i=blockIdx.x*blockDim.x + threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
__global__ void add(float *a, float *b, float *c){
int i=blockIdx.x*blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}
GPGPU実践基礎工学42 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-42-320.jpg)
![#define N (1024*1024)
#define Nbytes (N*sizeof(float))
__global__ void init(float *a,
float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
__global__ void add(float *a,
float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
cudaMalloc((void **)&a, Nbytes);
cudaMalloc((void **)&b, Nbytes);
cudaMalloc((void **)&c, Nbytes);
init<<< N/256, 256>>>(a,b,c);
add<<< N/256, 256>>>(a,b,c);
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}
GPUで並列実行するプログラム
GPGPU実践基礎工学
vectoradd.cu
43 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-43-320.jpg)
![処理時間の比較
配列の要素数 N=220
1ブロックあたりのスレッド数 256
GPUはマルチスレッドで処理しないと遅い
GPUを使えばどのような問題でも速くなるわけではない
並列に処理できるようプログラムを作成する必要がある
implementation
Processing time [ms]
init add
CPU (1 Thread) 4.15 4.55
GPU (1 Thread) 201 206
GPU (256 Threads) 0.108 0.112
GPGPU実践基礎工学44 2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-44-320.jpg)



![#define N (1024*1024)
#define NT (256) //この数字を変更
#define NB (N/NT)
#define Nbytes (N*sizeof(float))
__global__ void init(float *a,
float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
__global__ void add(float *a,
float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
cudaMalloc((void **)&a, Nbytes);
cudaMalloc((void **)&b, Nbytes);
cudaMalloc((void **)&c, Nbytes);
init<<< NB, NT>>>(a,b,c);
add<<< NB, NT>>>(a,b,c);
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}
並列度の変更によるチューニング
GPGPU実践基礎工学48
#defineでNB,NTを定義,変更して実行
vectoradd_param.cu
2015/11/18](https://image.slidesharecdn.com/gpgpubasic11-160306182147/85/2015-GPGPU-11-GPU-48-320.jpg)













































































