長岡技術科学大学
2015年度GPGPU実践基礎工学(全15回,学部3年対象講義)
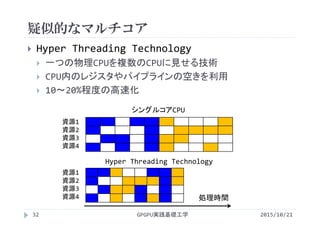
第7回シングルコアとマルチコア
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
・第2回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu2
・第3回 GPUクラスタ上でのプログラミング(CUDA)
http://www.slideshare.net/ssuserf87701/2015gpgpu3
・第4回 CPUのアーキテクチャ
http://www.slideshare.net/ssuserf87701/2015gpgpu4
・第5回 ハードウェアによるCPUの高速化技術
http://www.slideshare.net/ssuserf87701/2015gpgpu5
・第6回 ソフトウェアによるCPUの高速化技術
http://www.slideshare.net/ssuserf87701/2015gpgpu6
・第7回 シングルコアとマルチコア
http://www.slideshare.net/ssuserf87701/2015gpgpu7
・第8回 並列計算の概念(プロセスとスレッド)
http://www.slideshare.net/ssuserf87701/2015gpgpu8
・第9回 GPUのアーキテクチャ
http://www.slideshare.net/ssuserf87701/2015gpgpu9
・第9回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59160061
・第10回 GPGPUのプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu10
・第11回 GPUでの並列プログラミング(ベクトル和)
http://www.slideshare.net/ssuserf87701/2015gpgpu11
・第12回 GPUによる画像処理
http://w ww.slideshare.net/ssuserf87701/2015gpgpu12
・第13回GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu13
・第14回 GPGPU組込開発環境
http://www.slideshare.net/ssuserf87701/2015gpgpu14
・第15回 GPGPUの開発環境(OpenCL)
http://www.slideshare.net/ssuserf87701/2015gpgpu15
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3




![TOP500 List(2015, Jun.)
http://www.top500.org/lists/2015/6/
GPGPU実践基礎工学6
計算機名称(設置国) アクセラレータ
実効性能[PFlop/s]
/ピーク性能
[PFlop/s]
消費電力[MW]
1 Tianhe‐2 (China) Intel Xeon Phi 33.9/54.9 17.8
2 Titan (U.S.A.) NVIDIA K20x 17.6/27.1 8.20
3 Sequoia (U.S.A.) − 17.2/20.1 7.90
4 K computer (Japan) − 10.5/11.3 12.7
5 Mira (U.S.A.) − 8.59/10.1 3.95
6 Piz Daint (Switzerland) NVIDIA K20x 6.27/7.79 2.33
7 Shaheen II(Saudi Arabia) 5.54/7.24 2.83
8 Stampede (U.S.A.) Intel Xeon Phi 5.17/8.52 4.51
9 JUQUEEN (Germany) − 5.01/5.87 2.30
10 Vulcan (U.S.A.) − 4.29/5.03 1.97
2015/10/21](https://image.slidesharecdn.com/gpgpubasic07-160306181136/85/2015-GPGPU-7-6-320.jpg)


![CPUの理論性能
GPGPU実践基礎工学9
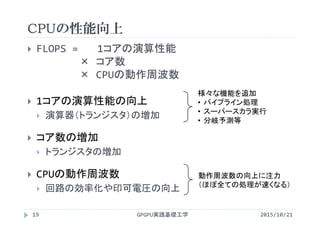
公式
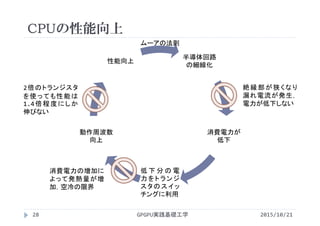
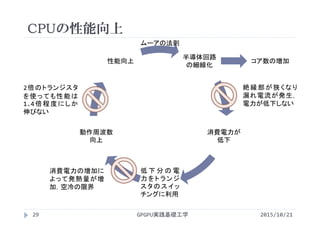
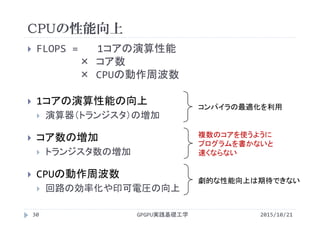
FLOPS = 1コアの演算性能 [?]
× コア数 [core]
× CPUの動作周波数 [Hz=clock/sec]
1コアの演算性能
=1度に発行出来る浮動小数点演算命令
単位は[Floating Point Operations/clock/core]
性能の評価には動作周波数だけでなく,1コアが1クロックで
発行できる命令数が重要
2015/10/21](https://image.slidesharecdn.com/gpgpubasic07-160306181136/85/2015-GPGPU-7-9-320.jpg)




















![コプロセッサ,アクセラレータ
GPGPU実践基礎工学41
万能的な能力を求められるCPUとは異なり,専用の役割
だけをこなす
性能あたりのパフォーマンスが高い
消費電力,体積,購入額
2015/10/21
System
Effective
Speed
[Gflops]
Cost/speed
[$/Gflops]
Power/speed
[Watt/Gflops]
Size/speed
[liter/Gflops]
Xeon E5430
(Dual Quad‐
Core)
115 21.0 3.7 0.39
PLAYSTATION3 157 2.8 1.3 0.06
GeForce
9800GTX
569 2.6 0.5 0.05
MDGRAPE‐3 355 32.8 0.7 0.07
成見哲,濱田剛,小西史一,アクセラレータによる粒子法シミュレーションの加速,情報処理,50(2),pp.129‐139(2009).
best
second best](https://image.slidesharecdn.com/gpgpubasic07-160306181136/85/2015-GPGPU-7-41-320.jpg)















































































