More Related Content

KEY

PDF

PDF
準同型暗号の実装とMontgomery, Karatsuba, FFT の性能 
PDF

PDF

PDF
Pythonによる並列プログラミング -GPGPUも- 
KEY

PDF
What's hot

PDF

PDF

PPTX

PDF

PDF

PPTX

PDF

PDF
Wavelet matrix implementation 
PDF
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013 
PDF

PDF

PDF
汎用性と高速性を目指したペアリング暗号ライブラリ mcl 
PDF

PDF
Xeon PhiとN体計算コーディング x86/x64最適化勉強会6(@k_nitadoriさんの代理アップ) 
PDF

PDF
Chainer/CuPy v5 and Future (Japanese) 
PDF
Anaconda & NumbaPro 使ってみた 
PDF

PDF

PDF
Viewers also liked

PDF

PDF
Cuda fortranの利便性を高めるfortran言語の機能 
PDF

PDF
GPGPU Seminar (GPGPU and CUDA Fortran) 
PDF
AngularJSでデータビジュアライゼーションがしたい 
PDF
PGI CUDA FortranとGPU最適化ライブラリの一連携法 
PDF

PDF
アニメーション(のためのパフォーマンス)の基礎知識 
PDF
GPGPU Seminar (Accelerataion of Lattice Boltzmann Method using CUDA Fortran) 
PPTX
![[関東GPGPU勉強会#2] ライブラリを使って大規模疎行列線形方程式を解いてみよう](https://cdn.slidesharecdn.com/ss_thumbnails/kantogpgpu2-130608041648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[関東GPGPU勉強会#2] ライブラリを使って大規模疎行列線形方程式を解いてみよう 
PPTX

PDF

PDF

PDF

PDF
GPGPU Education at Nagaoka University of Technology: A Trial Run 
PDF

PDF
GDG DevFest Kobe Firebaseハンズオン勉強会 
PPT

PDF
Similar to PyOpenCLによるGPGPU入門 Tokyo.SciPy#4 編

PDF
![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介 
PDF
Introduction to OpenCL (Japanese, OpenCLの基礎) 
PDF
サイバーエージェントにおけるMLOpsに関する取り組み at PyDataTokyo 23 
PDF
1072: アプリケーション開発を加速するCUDAライブラリ 
PDF

PDF

PPTX
研究者のための Python による FPGA 入門 
PDF
ディープラーニングフレームワーク とChainerの実装 
KEY
NVIDIA Japan Seminar 2012 
PDF
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10) 
PPTX

PDF

PDF
High performance python computing for data science 
PDF
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング 
PDF
C base design methodology with s dx and xilinx ml 
PDF
Introduction to Chainer (LL Ring Recursive) 
PDF
Introduction to Chainer and CuPy 
PDF

PDF
2015年度GPGPU実践基礎工学 第15回 GPGPU開発環境�(OpenCL) More from Yosuke Onoue

KEY
What's New In Python 3.3をざっと眺める 
PDF
asm.jsとWebAssemblyって実際なんなの? 
PPTX

PDF
AngularJSとD3.jsによるインタラクティブデータビジュアライゼーション 
PDF

PPTX
Recently uploaded

PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf 
PDF
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026 
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研) 
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf 
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S... 
PDF
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf PyOpenCLによるGPGPU入門 Tokyo.SciPy#4 編
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
インストール 2
pip installnumpy
pip install mako
pip install pyopencl
OpenCLのインストール先が標準以外の場合、
OpenGL連携を有効にするなどの場合は
~/.aksetup-defaults.py を作成
http://d.hatena.ne.jp/likr/20120604#1338786247
- 15.
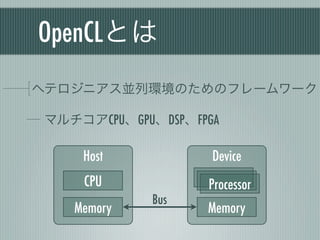
ContextとCommandQueue
create_some_context() 1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
実行時にデバイスと 3
4 import pyopencl as cl
プラットフォームを 5 import numpy
6
選択 7 # Contextの作成
8 ctx = cl.create_some_context()
CommandQueue 9
10 # CommandQueueの作成
host - device間の制御 11 queue = cl.CommandQueue(ctx)
[onoue@localhost test]$ python sample.py
Choose device(s):
[0] <pyopencl.Device 'Tesla C2050' on 'NVIDIA CUDA' at 0xfd4000>
[1] <pyopencl.Device 'GeForce GT 240' on 'NVIDIA CUDA' at 0xc85df0>
Choice, comma-separated [0]:0
- 16.
- 17.
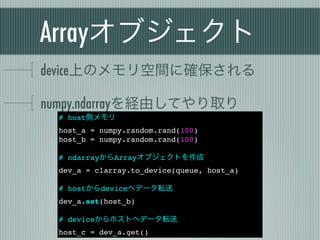
Arrayを直接生成する
host - device間のデータ転送はコストがかかる
簡単なデータ生成はdeviceで行うのが効率的
a = clarray.empty(queue, 100, numpy.float32)
b = clarray.zeros(queue, 100, numpy.float32)
c = clarray.arange(queue, 0, 1000, 10, dtype=numpy.float32)
d = clrandom.rand(queue, 100, numpy.float32)
- 18.
- 19.
- 20.
- 21.
リダクション
sum
GPU上で効率よく計算するには
テクニックが必要な処理が min
関数として提供
max
- 22.
- 23.
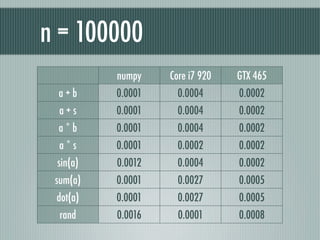
n = 100000
numpy Core i7 920 GTX 465
a+b 0.0001 0.0004 0.0002
a+s 0.0001 0.0004 0.0002
a*b 0.0001 0.0004 0.0002
a*s 0.0001 0.0002 0.0002
sin(a) 0.0012 0.0004 0.0002
sum(a) 0.0001 0.0027 0.0005
dot(a) 0.0001 0.0027 0.0005
rand 0.0016 0.0001 0.0008
- 24.
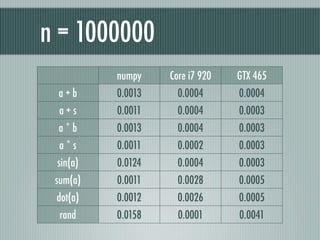
n = 1000000
numpy Core i7 920 GTX 465
a+b 0.0013 0.0004 0.0004
a+s 0.0011 0.0004 0.0003
a*b 0.0013 0.0004 0.0003
a*s 0.0011 0.0002 0.0003
sin(a) 0.0124 0.0004 0.0003
sum(a) 0.0011 0.0028 0.0005
dot(a) 0.0012 0.0026 0.0005
rand 0.0158 0.0001 0.0041
- 25.
- 26.
- 27.
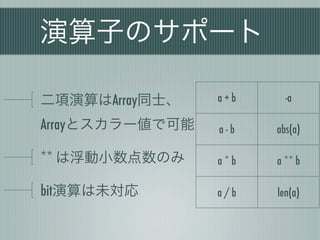
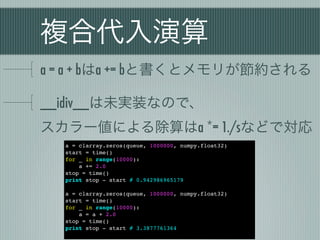
複合代入演算
a = a+ bはa += bと書くとメモリが節約される
__idiv__は未実装なので、
スカラー値による除算はa *= 1./sなどで対応
a = clarray.zeros(queue, 1000000, numpy.float32)
start = time()
for _ in range(10000):
a += 2.0
stop = time()
print stop - start # 0.942986965179
a = clarray.zeros(queue, 1000000, numpy.float32)
start = time()
for _ in range(10000):
a = a + 2.0
stop = time()
print stop - start # 3.3877761364
- 28.
数学関数の場合
clmathの関数は新しいメモリを確保する
インプレースに演算するにはElementwiseKernel
from pyopencl.elementwiseimport ElementwiseKernel
k = ElementwiseKernel(ctx, 'float* a', 'a[i] = sin(a[i]);')
a = clarray.zeros(queue, 1000000, numpy.float32)
start = time()
for _ in range(10000):
k(a)
stop = time()
print stop - start # 0.979743003845
a = clarray.zeros(queue, 1000000, numpy.float32)
start = time()
for _ in range(10000):
a = clmath.sin(a)
stop = time()
print stop - start # 3.34474182129
- 29.
カーネル関数の適用
dataメソッドでBufferオブジェクトを取得
import pyopencl as cl
from pyopencl import clrandom
import numpy
ctx = cl.create_some_context(False)
queue = cl.CommandQueue(ctx)
prg = cl.Program(ctx, '''//CL//
__kernel void add2(__global float* a)
{
const int i = get_global_id(0);
a[i] += 2;
}
''').build()
a = clrandom.rand(queue, 1000, numpy.float32)
prg.add2(queue, a.shape, None, a.data)
- 30.
- 31.
- 32.
- 33.
- 34.
参考資料 2
改訂新版 OpenCL入門1.2対応
マルチコアCPU・GPUのための並列プログラミング
http://www.amazon.co.jp/dp/4844331728
The OpenCL Specification Version 1.2
http://www.khronos.org/registry/cl/specs/opencl-1.2.pdf
PyOpenCL
http://mathema.tician.de/software/pyopencl
PyOpenCLハンズオン in kyoto.py 資料
http://pykyoto201109-pyopencl.s3-website-ap-northeast-1.amazonaws.com/pyopencl.html
- 35.














![ContextとCommandQueue
create_some_context() 1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
実行時にデバイスと 3
4 import pyopencl as cl
プラットフォームを 5 import numpy
6
選択 7 # Contextの作成
8 ctx = cl.create_some_context()
CommandQueue 9
10 # CommandQueueの作成
host - device間の制御 11 queue = cl.CommandQueue(ctx)
[onoue@localhost test]$ python sample.py
Choose device(s):
[0] <pyopencl.Device 'Tesla C2050' on 'NVIDIA CUDA' at 0xfd4000>
[1] <pyopencl.Device 'GeForce GT 240' on 'NVIDIA CUDA' at 0xc85df0>
Choice, comma-separated [0]:0](https://image.slidesharecdn.com/scipy201206-120616034905-phpapp01/85/PyOpenCL-GPGPU-Tokyo-SciPy-4-15-320.jpg)







![数学関数の場合
clmathの関数は新しいメモリを確保する
インプレースに演算するにはElementwiseKernel
from pyopencl.elementwise import ElementwiseKernel
k = ElementwiseKernel(ctx, 'float* a', 'a[i] = sin(a[i]);')
a = clarray.zeros(queue, 1000000, numpy.float32)
start = time()
for _ in range(10000):
k(a)
stop = time()
print stop - start # 0.979743003845
a = clarray.zeros(queue, 1000000, numpy.float32)
start = time()
for _ in range(10000):
a = clmath.sin(a)
stop = time()
print stop - start # 3.34474182129](https://image.slidesharecdn.com/scipy201206-120616034905-phpapp01/85/PyOpenCL-GPGPU-Tokyo-SciPy-4-28-320.jpg)
![カーネル関数の適用
dataメソッドでBufferオブジェクトを取得
import pyopencl as cl
from pyopencl import clrandom
import numpy
ctx = cl.create_some_context(False)
queue = cl.CommandQueue(ctx)
prg = cl.Program(ctx, '''//CL//
__kernel void add2(__global float* a)
{
const int i = get_global_id(0);
a[i] += 2;
}
''').build()
a = clrandom.rand(queue, 1000, numpy.float32)
prg.add2(queue, a.shape, None, a.data)](https://image.slidesharecdn.com/scipy201206-120616034905-phpapp01/85/PyOpenCL-GPGPU-Tokyo-SciPy-4-29-320.jpg)



![参考資料 1
CUDA プログラミング入門(白山工業 森野編)
http://www.youtube.com/user/NVIDIAJapan
はじめてのCUDAプログラミング
ー脅威の開発環境[GPU+CUDA]を使いこなす!
http://www.amazon.co.jp/dp/4777514773
PyCUDAの紹介 - PythonとAWSですぐ始めるGPUコンピューティング
http://www.slideshare.net/likr/pycuda](https://image.slidesharecdn.com/scipy201206-120616034905-phpapp01/85/PyOpenCL-GPGPU-Tokyo-SciPy-4-33-320.jpg)

