[ option forubuntu on Windows10 ]
1. Xserver install
a. VcXsrv (https://sourceforge.net/projects/vcxsrv/)
2. マウスでコピー&ペースト (ref)
a. ウィンドウタイトルバーで右クリック
b. メニューから編集
並列計算とMPI (Message PassingInterface)
並列計算のメリット
1. 大規模数値計算
2. 高速化も期待
MPI : 並列コンピューティング利用するための標準化された規格
1. CPU間のデータの送受信などを規定
2. FreeFem++ にいくつかのコマンドを実装
3. よく使う変数:
a. mpisize : The total number of processes,
b. mpirank : the id-number of my current process in (0,..., mpisize-1)
14.
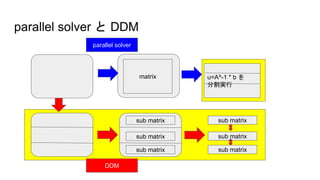
parallel solver とDDM
matrix u=A^-1 * b を
分割実行
sub matrix
sub matrix
sub matrix
sub matrix
sub matrix
sub matrix
parallel solver
DDM
15.
Parallel Solver
行列ソルバーを並列版に変更
1. directsolver
a. MUMPS (MUltifrontal Massively Parallel sparse direct Solver)
b. SuperLU (Supernodal LU)
2. Krylov (iterative) solver
a. pARMS (parallel Algebraic Recursive Multilevel Solvers)
b. HIPS (Hierarchical Iterative Parallel Solver)
c. HYPRE (Parallel solvers for sparse linear systems featuring multigrid methods)
● メリット:プログラムは殆どそのまま
● デメリット:メインプログラムのほとんどは並列化されない
行列計算のみ
メインプログラム
16.
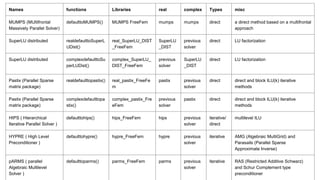
Names functions Librariesreal complex Types misc
MUMPS (MUltifrontal
Massively Parallel Solver)
defaulttoMUMPS() MUMPS FreeFem mumps mumps direct a direct method based on a multifrontal
approach
SuperLU distributed realdefaulttoSuperL
UDist()
real_SuperLU_DIST
_FreeFem
SuperLU
_DIST
previous
solver
direct LU factorization
SuperLU distributed complexdefaulttoSu
perLUDist()
complex_SuperLU_
DIST_FreeFem
previous
solver
SuperLU
_DIST
direct LU factorization
Pastix (Parallel Sparse
matrix package)
realdefaulttopastix() real_pastix_FreeFe
m
pastix previous
solver
direct direct and block ILU(k) iterative
methods
Pastix (Parallel Sparse
matrix package)
complexdefaulttopa
stix()
complex_pastix_Fre
eFem
previous
solver
pastix direct direct and block ILU(k) iterative
methods
HIPS ( Hierarchical
Iterative Parallel Solver )
defaulttohips() hips_FreeFem hips previous
solver
iterative/
direct
multilevel ILU
HYPRE ( High Level
Preconditioner )
defaulttohypre() hypre_FreeFem hypre previous
solver
iterative AMG (Algebraic MultiGrid) and
Parasails (Parallel Sparse
Approximate Inverse)
pARMS ( parallel
Algebraic Multilevel
Solver )
defaulttoparms() parms_FreeFem parms previous
solver
iterative RAS (Restricted Additive Schwarz)
and Schur Complement type
preconditioner
Problem 1
行列版を作り,problem 版と行列版の速度を比較してみよう
$FreeFem++ RD2-ai-bs-prob.edp
it = 1000, t = 1, Averaged Time=XXXXX(ms)
$ FreeFem++ RD2-ai-bs-matrix.edp
it = 1000, t = 1, Averaged Time=XXXXX(ms)











![[ option for ubuntu on Windows10 ]
1. Xserver install
a. VcXsrv (https://sourceforge.net/projects/vcxsrv/)
2. マウスでコピー&ペースト (ref)
a. ウィンドウタイトルバーで右クリック
b. メニューから編集](https://image.slidesharecdn.com/8pc-180215061433/85/8-pc-11-320.jpg)






![行列 での記述
fespace Vh(Th,Pk);
Vh u,uu,uold;
Vh v,vv,vold;
Vh b1, b2; // RHS
// Definition of weak-form of RD eqs.
varf RD1(u,uu)
= int2d(Th)(u * uu + dt * du * (grad(u)' * grad(uu)));
varf RHS1(unused,uu) = int2d(Th)(uold * uu + dt * f(uold, vold) * uu);
varf RD2(v,vv)
= int2d(Th)(v * vv + dt * dv * (grad(v)' * grad(vv)));
varf RHS2(unused,vv) = int2d(Th)(vold * vv + dt * g(uold, vold) * vv);
matrix a1=RD1(Vh,Vh,solver=CG,init=0);
matrix a2=RD2(Vh,Vh,solver=CG,init=0);
/// Main loop
for (it=1;it<=itmax;it++)
{
t=dt*it;
real cpu0=clock();
uold=u; vold=v;
b1[] = RHS1(0,Vh);
b2[] = RHS2(0,Vh);
u[] = a1^-1*b1[];
v[] = a2^-1*b2[];
real cpu1=clock()-cpu0;
cpuTotal += cpu1;
…
}](https://image.slidesharecdn.com/8pc-180215061433/85/8-pc-20-320.jpg)
![右辺の扱い
problem RD1 (u,uu,solver=CG,init=0)
= int2d(Th)(u * uu + dt * du * (grad(u)' * grad(uu)))
- int2d(Th)(uold * uu + dt * f(uold, vold) * uu);
ー>
varf RD1(u,uu)
= int2d(Th)(u * uu + dt * du * (grad(u)' * grad(uu)));
varf RHS1(unused,uu) = int2d(Th)(uold * uu + dt * f(uold, vold) * uu);
b1[] = RHS1(0,Vh);](https://image.slidesharecdn.com/8pc-180215061433/85/8-pc-21-320.jpg)




![DDM に挑戦: PETSc 版 (DDM-1) mesh 生成
int[int] arrayIntersection; // ranks of neighboring subdomains
int[int][int] restrictionIntersection(0); // local-to-neighbors renumbering
real[int] D; // partition of unity
{
meshN ThGlobal = cube(10 * getARGV("-global", 5), getARGV("-global", 5),
getARGV("-global", 5), [10 * x, y, z], label = LL); // global メッシュの生成
build(Th, ThBorder, ThGlobal, fakeInterface, s, overlap, D, arrayIntersection,
restrictionIntersection, Wh, Pk, comm, excluded); // local メッシュの生成
}](https://image.slidesharecdn.com/8pc-180215061433/85/8-pc-27-320.jpg)

![(DDM-3)
// matrix A の partition 情報を用いて,b = M * u[]
dmv(A, M, u[], b); // distributed matrix vector product
// 分散データからプロット (自作)
plotDDM1(Th, u[], Pk, def, real,
{cmm="u t="+t,value=true,fill=1,wait=0,ps="RD2-ai-bs_u"+it+".eps"});](https://image.slidesharecdn.com/8pc-180215061433/85/8-pc-29-320.jpg)










![射頻電子 - [第二章] 傳輸線理論](https://cdn.slidesharecdn.com/ss_thumbnails/ch2-150613065059-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[関東GPGPU勉強会#2] ライブラリを使って大規模疎行列線形方程式を解いてみよう](https://cdn.slidesharecdn.com/ss_thumbnails/kantogpgpu2-130608041648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)