Download as PDF, PPTX




{ return y +
a*x; }
);
do concurrent (i = 1:n)
y(i) = y(i) + a*x(i)
enddo
import cunumeric as np
…
def saxpy(a, x, y):
y[:] += a*x
#pragma acc data copy(x,y) {
...
std::transform(par, x, x+n, y, y,
[=](float x, float y){
return y + a*x;
});
...
}
#pragma omp target data map(x,y) {
...
std::transform(par, x, x+n, y, y,
[=](float x, float y){
return y + a*x;
});
...
}
__global__
void saxpy(int n, float a,
float *x, float *y) {
int i = blockIdx.x*blockDim.x +
threadIdx.x;
if (i < n) y[i] += a*x[i];
}
int main(void) {
...
cudaMemcpy(d_x, x, ...);
cudaMemcpy(d_y, y, ...);
saxpy<<<(N+255)/256,256>>>(...);
cudaMemcpy(y, d_y, ...);
ACCELERATED STANDARD LANGUAGES
ISO C++, ISO Fortran
INCREMENTAL PORTABLE OPTIMIZATION
OpenACC, OpenMP
PLATFORM SPECIALIZATION
CUDA](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-4-320.jpg)


![PILLARS OF STANDARD LANGUAGE PARALLELISM
7
Copyright (C) 2021 Bryce Adelstein Lelbach
Common Algorithms that Dispatch to
Vendor-Optimized Parallel Libraries
Tools to Write Your Own Parallel
Algorithms that Run Anywhere
sender auto
algorithm (sender auto s) {
return s | bulk(N,
[] (auto data) {
// ...
}
) | bulk(N,
[] (auto data) {
// ...
}
);
}
Mechanisms for Composing Parallel
Invocations into Task Graphs
sender auto
algorithm (sender auto s) {
return s | bulk(
[] (auto data) {
// ...
}
) | bulk(
[] (auto data) {
// ...
}
);
}](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-7-320.jpg)
![C++ with OpenMP
Ø Composable, compact and elegant
Ø Easy to read and maintain
Ø ISO Standard
Ø Portable – nvc++, g++, icpc, MSVC, …
Standard C++
#pragma omp parallel // OpenMP parallel region
{
#pragma omp for // OpenMP for loop
for (MInt i = 0; i < noCells; i++) { // Loop over all cells
if (timeStep % ipow2[maxLevel_ – clevel[i * distLevel]] == 0) { // Multi-grid loop
const MInt distStartId = i * nDist; // More offsets for 1D accesses // Local offsets
const MInt distNeighStartId = i * distNeighbors;
const MFloat* const distributionsStart = &[distributions[distStartId];
for (MInt j = 0; j < nDist – 1; j += 2) { // Unrolled loop distributions (factor 2)
if (neighborId[I * distNeighbors + j] > -1) { // First unrolled iteration
const MInt n1StartId = neighborId[distNeighStartId + j] * nDist;
oldDistributions[n1StartId + j] = distributionsStart[j]; // 1D access AoS format
}
if (neighborId[I * distNeighbors + j + 1] > -1) { // Second unrolled iteration
const MInt n2StartId = neighborId[distNeighStartId + j + 1] * nDist;
oldDistributions[n2StartId + j + 1] = distributionsStart[j + 1];
}
}
oldDistributions[distStartId + lastId] = distributionsStart[lastId]; // Zero-th distribution
}
}
}
std::for_each_n(par_unseq, start, noCells, [=](auto i) { // Parallel for
if (timeStep % IPOW2[maxLevel_ – a_level(i)] != 0) // Multi-level loop
return;
for (MInt j = 0; j < nDist; ++j) {
if (auto n = c_neighborId(i, j); n == -1) continue;
a_oldDistribution(n, j) = a_distribution(i, j); // SoA or AoS mem_fn
}
});
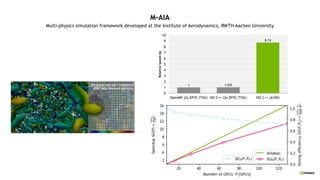
M-AIA WITH C++17 PARALLEL ALGORITHMS
Multi-physics simulation framework
from RWTH Aachen University
Ø Hierarchical grids, complex moving geometries
Ø Adaptive meshing, load balancing
Ø Numerical methods: FV, DG, LBM, FEM, Level-Set, ...
Ø Physics: aeroacoustics, combustion, biomedical, ...
Ø Developed by ~20 PhDs (Mech. Eng.), ~500k LOC++
Ø Programming model: MPI + ISO C++ parallelism](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-8-320.jpg)
![PILLARS OF STANDARD LANGUAGE PARALLELISM
11
Copyright (C) 2021 Bryce Adelstein Lelbach
With Senders & Receivers
Today
Common Algorithms that Dispatch to
Vendor-Optimized Parallel Libraries
Tools to Write Your Own Parallel
Algorithms that Run Anywhere
sender auto
algorithm (sender auto s) {
return s | bulk(N,
[] (auto data) {
// ...
}
) | bulk(N,
[] (auto data) {
// ...
}
);
}
Mechanisms for Composing Parallel
Invocations into Task Graphs
sender auto
algorithm (sender auto s) {
return s | bulk(
[] (auto data) {
// ...
}
) | bulk(
[] (auto data) {
// ...
}
);
}](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-11-320.jpg)
![SENDERS & RECEIVERS
Maxwell’s equations
template <ComputeSchedulerT, WriteSchedulerT>
auto maxwell_eqs(ComputeSchedulerT &scheduler, WriteSchedulerT &writer)
{
return repeat_n(
n_outer_iterations,
repeat_n(
n_inner_iterations,
schedule(scheduler)
| bulk(grid.cells, update_h(accessor))
| bulk(grid.cells, update_e(time, dt, accessor)))
| transfer(writer)
| then(dump_results(report_step, accessor)))
| then([]{ printf("simulation completen"); })
);
}
Simplify Work Across CPUs and
Accelerators
• Uniform abstraction between code and
diverse resources
• ISO standard
• Write once, run everywhere
•](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-12-320.jpg)

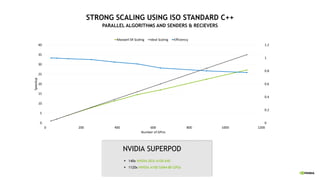
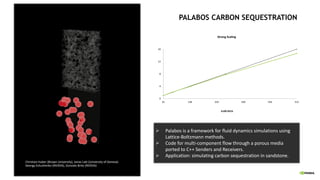



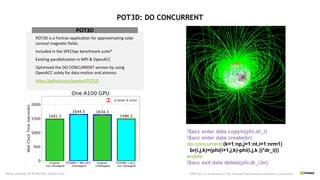

![PRODUCTIVITY
Sequential and Composable Code
§ Sequential semantics - no visible
parallelism or synchronization
§ Name-based global data – no partitioning
§ Composable – can combine with other
libraries and datatypes
def cg_solve(A, b, conv_iters):
x = np.zeros_like(b)
r = b - A.dot(x)
p = r
rsold = r.dot(r)
converged = False
max_iters = b.shape[0]
for i in range(max_iters):
Ap = A.dot(p)
alpha = rsold / (p.dot(Ap))
x = x + alpha * p
r = r - alpha * Ap
rsnew = r.dot(r)
if i % conv_iters == 0 and
np.sqrt(rsnew) < 1e-10:
converged = i
break
beta = rsnew / rsold
p = r + beta * p
rsold = rsnew](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-21-320.jpg)

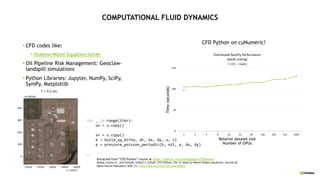
{
return y + a*x;
}
);
import cunumeric as np
…
def saxpy(a, x, y):
y[:] += a*x
do concurrent (i = 1:n)
y(i) = y(i) + a*x(i)
enddo
ISO C++ ISO Fortran Python
CPU GPU
nvc++ -stdpar=multicore
nvfortran –stdpar=multicore
legate –cpus 16 saxpy.py
nvc++ -stdpar=gpu
nvfortran –stdpar=gpu
legate –gpus 1 saxpy.py](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-24-320.jpg)
![LERN MORE
GTC2022 sessions
§ No More Porting: Coding for GPUs with Standard C++, Fortran, and Python [S41496]
§ Shifting through the Gears of GPU Programming Understanding Performance and Portability Trade-offs [S41620]
§ C++ Standard Parallelism [S41960]
§ Future of Standard and CUDA C++ [S41961]
§ Connect with Experts: Standard and CUDA C++ User Forum [CWE41949]
§ From Directives to DO CONCURRENT: A Case Study in Standard Parallelism [S41318]
§ Evaluating Your Options for Accelerated Numerical Computing in Pure Python [S41645]
Blogs
§ Developing Accelerated Code with Standard Language Parallelism
§ Accelerating Standard C++ with GPUs Using stdpar
§ Accelerating Fortran DO CONCURRENT with GPUs and the NVIDIA HPC SDK
§ Bringing Tensor Cores to Standard Fortran
§ Accelerating Python on GPUs with nvc++ and Cython](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-25-320.jpg)




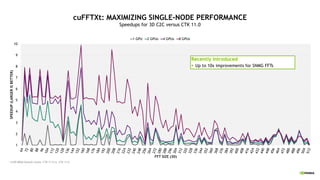

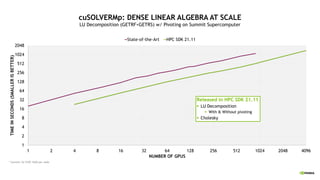
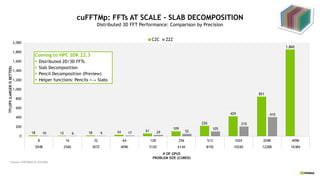
![13 14
22 25 27
30 37 41
51
68
79
78.2
104
135
147
122
158
260
278
134
176
394
527
0
100
200
300
400
500
600
1024 2048 4096 8192
TFLOPS
(LARGER
IS
BETTER)
PROBLEM SIZE (CUBED)
32 64 128 256 512 1024 2048
cuFFTMp: FFTs AT SCALE - PENCIL DECOMPOSITION
Distributed 3D FFT Performance: C2C Comparison by GPU Count
* Selene: A100 80GB @ 1410 MHz
Coming to HPC SDK 22.3
§ Distributed 2D/3D FFTs
§ Slab Decomposition
§ Pencil Decomposition (Preview)
§ Helper functions: Pencils <→
Slabs
[S41494] A Deep Dive into the Latest HPC Software
# of GPUs](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-34-320.jpg)

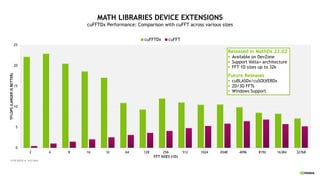
![LERN MORE
GTC2022 sessions
§ An Explanation of Slab and Pencil Decomposition Performance Across Supercomputing Clusters [S41153]
§ Recent Developments in NVIDIA Math Libraries [S41491]
§ Connect with Experts: NVIDIA Math Libraries [CWE41721]
§ Connect with Experts: Thrust, CUB, and libcu++ User Forum [CWE41948]
§ NVSHMEM: CUDA-Integrated Communication for NVIDIA GPUs (a Magnum IO session) [S41044]
Examples
§ CUDA Library Samples: https://github.com/NVIDIA/CUDALibrarySamples
MathDx 22.02
§ https://developer.nvidia.com/mathdx](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-37-320.jpg)


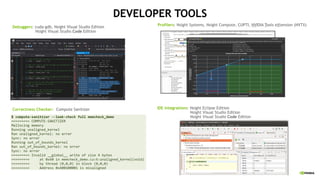




![CORRECTNESS TOOLS FEATURES
§OptiX support in Compute Sanitizer
§ Automatically find correctness issues in OptiX workloads
§Core Dump support in Compute Sanitizer
§ Generate core dumps on detected issues
§5x performance increase in core dump
generation
========= COMPUTE-SANITIZER
========= Invalid __global__ write of size 1 bytes
========= at 0x4d70 in
/home/cuda/optixBasic/draw_solid_color.cu:69:__raygen__dra
w_solid_color_0xebf766b2f0642d4e
========= by thread (0,0,0) in block (0,0,0)
========= Address 0x7f878f900403 is out of bounds
========= and is 262,132 bytes after the nearest
allocation at 0x7f878f8c0400 of size 16 bytes
========= Device Frame:NVIDIA internal [0x430]
========= Saved host backtrace up to driver entry
point at kernel launch time
========= Host Frame: [0x60fbaa]
========= in /lib/x86_64-linux-
gnu/libnvoptix.so.1
========= Host Frame:optix_stubs.h:568:optixLaunch
[0xe1ff]
========= in
/home/cuda/optixBasic/optixBasic
========= Host
Frame:/home/cuda/optixBasic/optixBasic.cpp:227:main
[0xb735]
========= in
/home/cuda/optixBasic/optixBasic
========= Host
Frame:../sysdeps/nptl/libc_start_call_main.h:58:__libc_sta
rt_call_main [0x2dfd0]
========= in /lib/x86_64-linux-
gnu/libc.so.6
========= Host Frame:../csu/libc-
start.c:379:__libc_start_main [0x2e07d]
========= in /lib/x86_64-linux-
gnu/libc.so.6
========= Host Frame: [0x8dde]
========= in
/home/cuda/optixBasic/optixBasic](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-45-320.jpg)








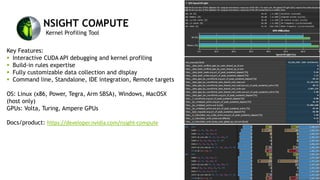

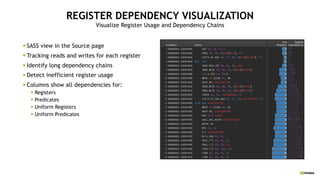
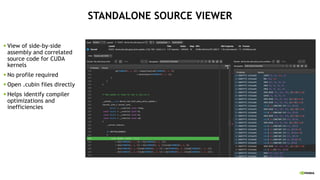
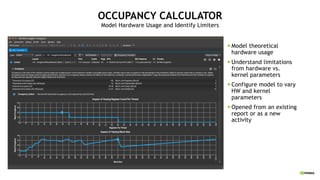

![LERN MORE
GTC2022 sessions
§ Optimizing Communication with Nsight Systems Network Profiling [S41500]
§ Latest Updates to CUDA Developer Tools [D4121]
§ How to Understand and Optimize Shared Memory Accesses using Nsight Compute [S41723]
§ Connect with Experts: What’s in Your CUDA Toolbox? Profiling, Optimization, and Debugging Tools [CWE41541]
§ What, Where, and Why? Use CUDA Developer Tools to Detect, Locate, and Explain Bugs and Bottlenecks [S41493]
Nsight Systems Documentation
§ https://docs.nvidia.com/nsight-systems/
Nsight Compute Documentation
§ https://docs.nvidia.com/nsight-compute/](https://image.slidesharecdn.com/naruhikothpc-software-220428063808/85/NVIDIA-HPC-61-320.jpg)



The document discusses NVIDIA's High Performance Computing (HPC) software and its integration with standard programming languages such as C++, Fortran, and Python, focusing on accelerated computing and relevant libraries, tools, and development practices. It covers multi-GPU support, parallel algorithms, user guides, and showcases applications in various fields including fluid dynamics and climate modeling. Additionally, it highlights advancements in modern Fortran features and the performance benefits of utilizing NVIDIA's HPC SDK for efficient code execution across CPUs and GPUs.






































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















