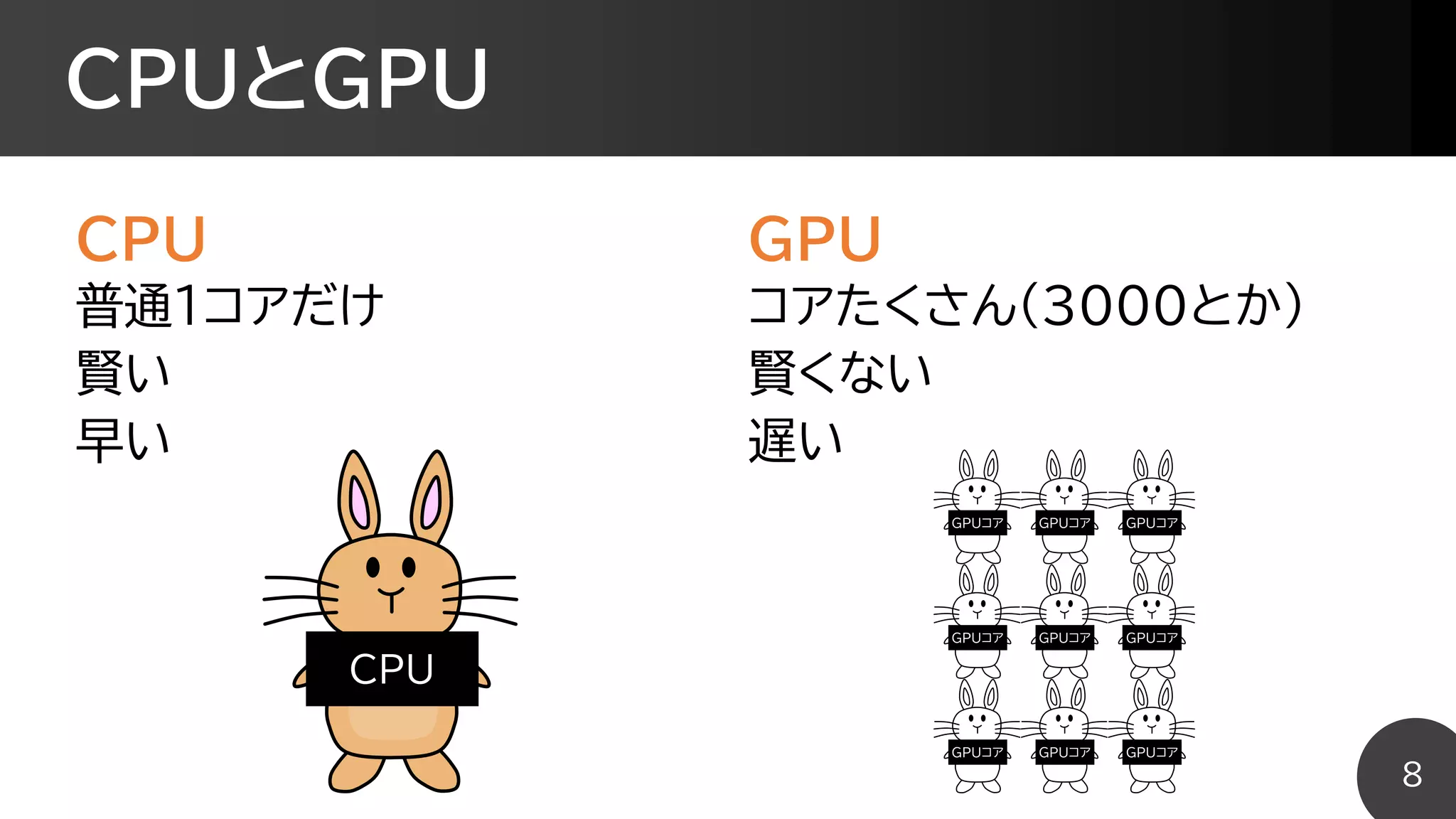
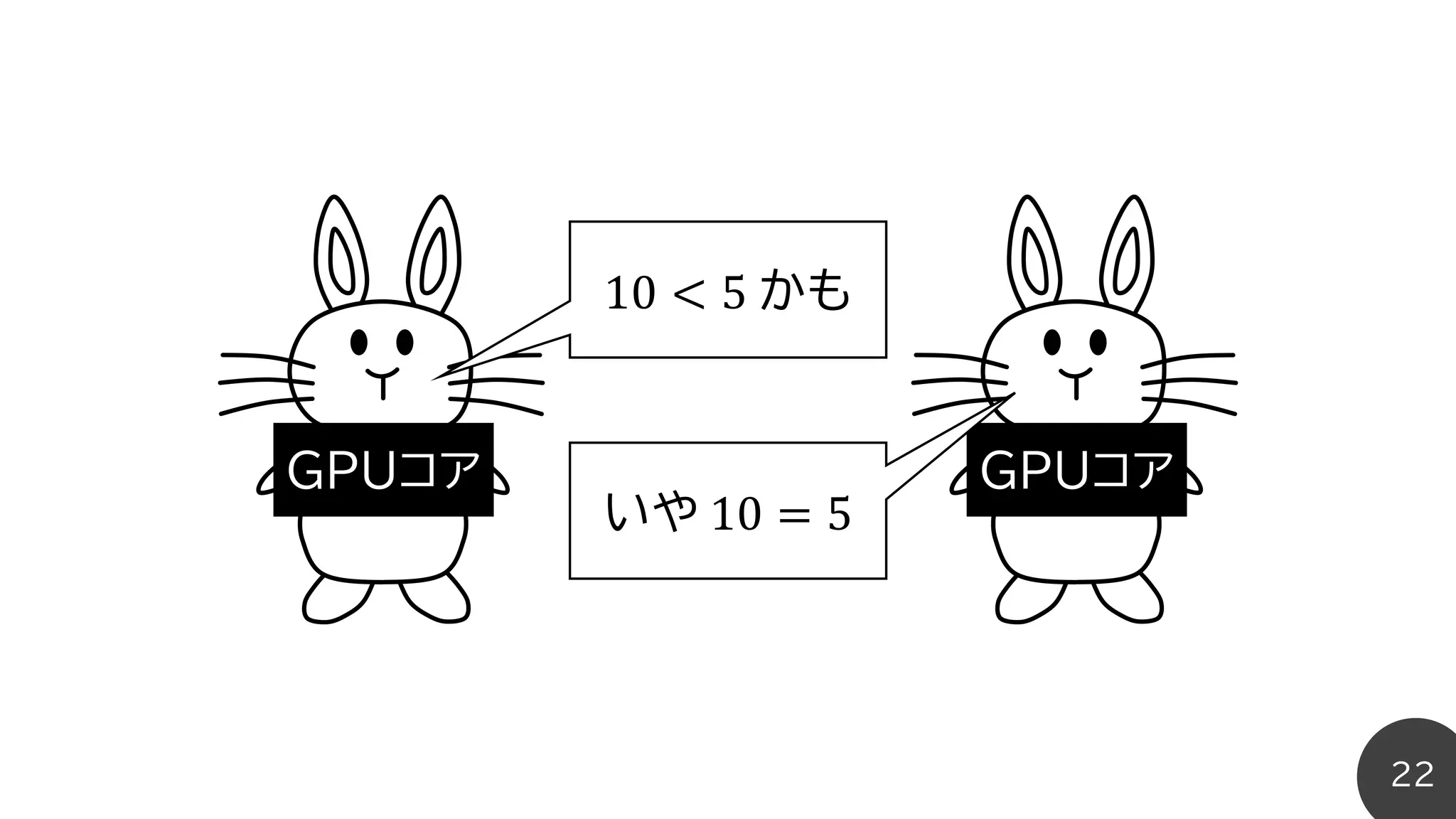
maxとminをビット演算で実装
int max(int a,int b){
if(a > b) return a;
else return b;
}
int max(int a, int b){
return ((-(a>b)) & a) + ((-(a<=b)) & b);
}
28
29.
maxとminをビット演算で実装
・ 𝑎 >𝑏 のとき
int max(int a, int b){
return ((-(a>b)) & a) + ((-(a<=b)) & b);
}
・ 𝑎 ≤ 𝑏 のとき
int max(int a, int b){
return ((-(a>b)) & a) + ((-(a<=b)) & b);
}
29
30.
maxとminをビット演算で実装
・ 𝑎 >𝑏 のとき
int max(int a, int b){
return ((-1) & a) + ((0) & b);
}
・ 𝑎 ≤ 𝑏 のとき
int max(int a, int b){
return ((0) & a) + ((-1) & b);
}
30
31.
maxとminをビット演算で実装
・ 𝑎 >𝑏 のとき
int max(int a, int b){
return ((・・・1111) & a) + ((・・・0000) & b);
}
・ 𝑎 ≤ 𝑏 のとき
int max(int a, int b){
return ((・・・0000) & a) + ((・・・1111) & b);
}
31
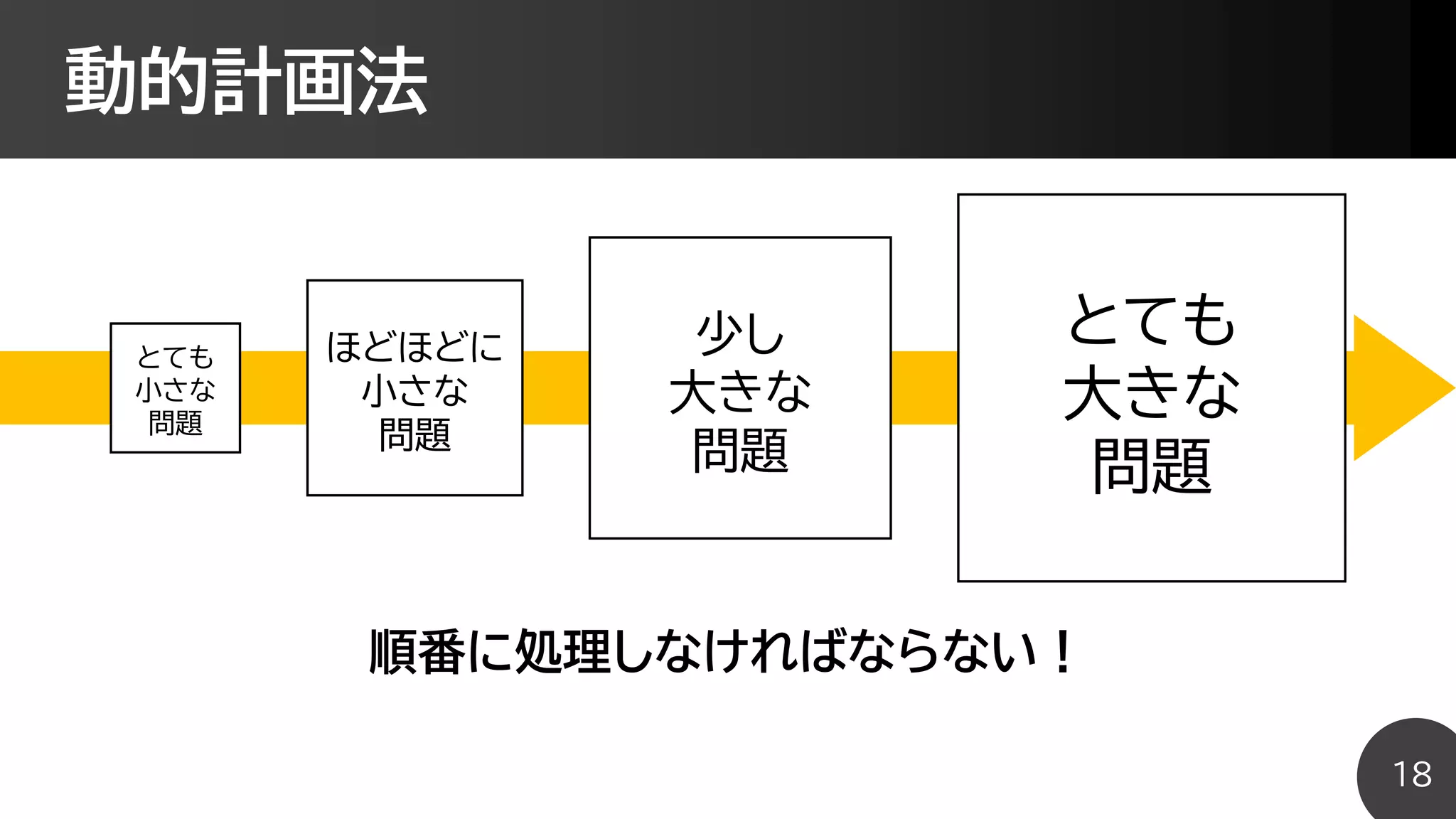
2進数表記










![並列化できる処理
int A[5000], B[5000], C[5000];
for(int i=0; i<5000; i++){
C[i] = A[i] + B[i];
}
12](https://image.slidesharecdn.com/slide-190829015758/75/slide-12-2048.jpg)
![並列化できる処理
int A[5000], B[5000], C[5000];
for(int i=0; i<5000; i++){
C[i] = A[i] + B[i];
}
13
GPUコア
……
C[0]=A[0]+B[0]
GPUコア
C[1]=A[1]+B[1]
GPUコア
C[2]=A[2]+B[2]
GPUコア
C[3]=A[3]+B[3]](https://image.slidesharecdn.com/slide-190829015758/75/slide-13-2048.jpg)
![並列化できない処理
int A[5002] = {1,1};
for(int i=0; i<5000; i++){
A[i+2] = A[i] + A[i+1];
}
14](https://image.slidesharecdn.com/slide-190829015758/75/slide-14-2048.jpg)
![並列化できない処理
int A[5002] = {1,1};
for(int i=0; i<5000; i++){
A[i+2] = A[i] + A[i+1];
}
逐次処理の必要あり → 並列化難しい
15](https://image.slidesharecdn.com/slide-190829015758/75/slide-15-2048.jpg)





















![ソースコード (抜粋)
#define BS 1000
__global__ void solve(int W, int *w, long long *v, long long *dp, int i){
int j = blockIdx.x*blockDim.x + threadIdx.x;
if(j >= W) return;
dp[(i&1)*(W+1)+j] = dmax(dp[((i-1)&1)*(W+1)+j],
-(j>=w[i]) & (dp[dmax(0,((i-1)&1)*(W+1)+j-w[i])]+v[i]));
}
int main(){
(入力の受け取り,メモリのコピーなど)
solve0<<<(W +BS-1)/BS,BS>>>(W, dw, dv, dp, 0);
for(int i=1; i<N; i++){
cudaDeviceSynchronize();
solve<<<(W +BS-1)/BS,BS>>>(W, dw, dv, dp, i);
}
(答えの出力など)
}
41
CUDAの解説は
次以降の人の発表を聞いてね!](https://image.slidesharecdn.com/slide-190829015758/75/slide-41-2048.jpg)
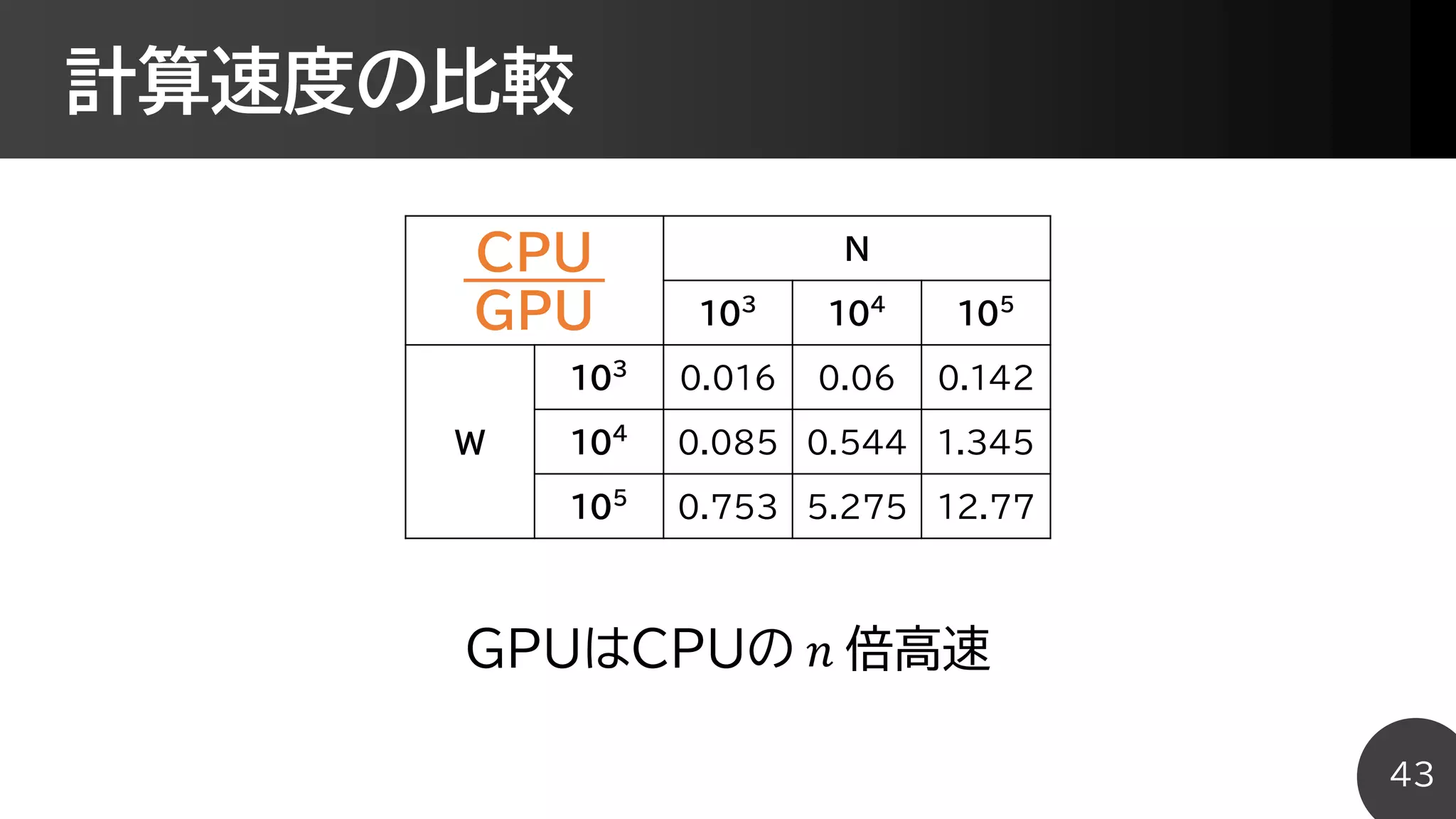
![計算速度の比較
CPU
N
103
104
105
W
103
3.579 20.32 187.5
104
19.00 175.6 1746
105
178.7 1720 17064
GPU
N
103
104
105
W
103
219.1 319.4 1323
104
222.9 322.9 1299
105
237.5 326.1 1336
42
各20種のテストケースで計測した平均値 [単位:ms]](https://image.slidesharecdn.com/slide-190829015758/75/slide-42-2048.jpg)



![計算速度の比較 (N=105)
47
0
5000
10000
15000
20000
1e3 1e4 1e5
W
GPU
CPU
[単位:ms]](https://image.slidesharecdn.com/slide-190829015758/75/slide-47-2048.jpg)
![計算速度の比較 (N=105)
48
0
5000
10000
15000
20000
1e3 1e4 1e5
W
GPU
CPU
[単位:ms]](https://image.slidesharecdn.com/slide-190829015758/75/slide-48-2048.jpg)
![計算速度の比較 (N=105)
49
0
5000
10000
15000
20000
1e3 1e4 1e5
W
GPU
CPU
[単位:ms]](https://image.slidesharecdn.com/slide-190829015758/75/slide-49-2048.jpg)
![計算速度の比較 (N=105)
50
0
5000
10000
15000
20000
1e3 1e4 1e5
W
GPU
CPU
[単位:ms]
GPUすごい!](https://image.slidesharecdn.com/slide-190829015758/75/slide-50-2048.jpg)








![ソースコード (抜粋)
__global__ void solve(int *d, int *state, int *num, int *dp, int V, int i){
int j = blockIdx.x*blockDim.x + threadIdx.x;
if(j >= num[i]*V) return;
int k = j % V; j /= V;
if(!((state[j*V+i]>>k)&1)) return;
for(int l=0; l<V; l++)
dp[state[j*V+i]*V+k] = dmin(dp[state[j*V+i]*V+k], dp[(state[j*V+i]^(1<<k))*V+l]+d[l*V+k]);
}
int main(){
(入力の受け取りなど)
for(int i=0; i<V+1; i++) num[i] = 0
for(int i=0; i<(1<<V); i++){
int c = 0;
for(int j=1; j<(1<<V); j<<=1)
if(i&j) c++;
state[num[c]*V+c] = i;
num[c]++;
}
(メモリのコピーなど)
for(int i=0; i<=V; i++){
solve<<<(num[i]*V +BS-1)/BS,BS>>>(dd, dstate, dnum, dp, V, i);
cudaDeviceSynchronize();
}
(答えの出力など)
}
60
CUDAの解説は
次以降の人の発表を聞いてね!](https://image.slidesharecdn.com/slide-190829015758/75/slide-60-2048.jpg)
![計算速度の比較
CPU
V time V time V time
2 1.9 11 2.15 20 690.2
3 1.75 12 2.75 21 1563.6
4 1.85 13 4.05 22 3498.8
5 1.7 14 6.7 23 7826.6
6 1.55 15 13.4 24 17303
7 1.75 16 27.35 25 37929
8 1.85 17 58.4 26 81735
9 1.8 18 131
10 2.1 19 297.35
GPU
V time V time V time
2 150 11 151.5 20 221.4
3 152 12 151.3 21 297.5
4 150.35 13 153.3 22 405.05
5 151.65 14 153.2 23 691.55
6 150.2 15 155.5 24 1296.6
7 150.05 16 154.3 25 2597.6
8 152.2 17 158.55 26 5356.5
9 151.6 18 166.2
10 151.6 19 183.5
61
各20種のテストケースで計測した平均値 [単位:ms]](https://image.slidesharecdn.com/slide-190829015758/75/slide-61-2048.jpg)
![計算速度の比較 (V≦22)
62
0
1000
2000
3000
4000
2 4 6 8 10 12 14 16 18 20 22
CPU
GPU
[単位:ms]](https://image.slidesharecdn.com/slide-190829015758/75/slide-62-2048.jpg)
![計算速度の比較 (V≦22)
63
0
1000
2000
3000
4000
2 4 6 8 10 12 14 16 18 20 22
CPU
GPU
GPUは起動に
時間がかかる
[単位:ms]](https://image.slidesharecdn.com/slide-190829015758/75/slide-63-2048.jpg)
![計算速度の比較 (V≦26)
64
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
2 4 6 8 10 12 14 16 18 20 22 24 26
CPU
GPU
[単位:ms]](https://image.slidesharecdn.com/slide-190829015758/75/slide-64-2048.jpg)
![計算速度の比較 (V≦26)
65
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
2 4 6 8 10 12 14 16 18 20 22 24 26
CPU
GPU
CPU82秒
GPU5秒
約16倍高速!
[単位:ms]](https://image.slidesharecdn.com/slide-190829015758/75/slide-65-2048.jpg)
![計算速度の比較 (V≦26)
66
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
2 4 6 8 10 12 14 16 18 20 22 24 26
[単位:ms]
GPU
CPU
CPU82秒
GPU5秒
約16倍高速!
https://umaibou.jp/product/](https://image.slidesharecdn.com/slide-190829015758/75/slide-66-2048.jpg)
![計算速度の比較 (V≦26)
67
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
2 4 6 8 10 12 14 16 18 20 22 24 26
[単位:ms]
GPU
CPU
CPU82秒
GPU5秒
約16倍高速!
https://umaibou.jp/product/](https://image.slidesharecdn.com/slide-190829015758/75/slide-67-2048.jpg)





















![[DL輪読会]Inverse Constrained Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20210709icrl-210709021811-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)





























