長岡技術科学大学
2015年度先端GPGPUシミュレーション工学特論(全15回,大学院生対象講義)
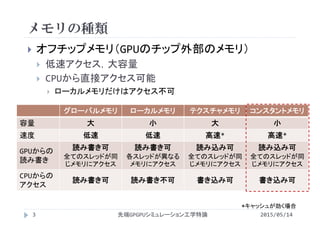
第5回GPUのメモリ階層の詳細�(様々なメモリの利用)�
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
・第1回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180326
・第2回 GPUによる並列計算の概念とメモリアクセス
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59180382
・第3回 GPUプログラム構造の詳細(threadとwarp)
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59180483
・第4回 GPUのメモリ階層の詳細(共有メモリ)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59180572
・第5回 GPUのメモリ階層の詳細(様々なメモリの利用)
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59180652
・第6回 プログラムの性能評価指針(Flop/Byte,計算律速,メモリ律速)
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59180736
・第7回 総和計算(Atomic演算)
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59180844
・第8回 偏微分方程式の差分計算(拡散方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59180918
・第9回 偏微分方程式の差分計算(移流方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59180982
・第10回 Poisson方程式の求解(線形連立一次方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59181031
・第11回 数値流体力学への応用(支配方程式,CPUプログラム)
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59181134
・第12回 数値流体力学への応用(GPUへの移植)
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59181230
・第13回 数値流体力学への応用(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59181316
・第14回 複数GPUの利用
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59181367
・第15回 CPUとGPUの協調
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59181450
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
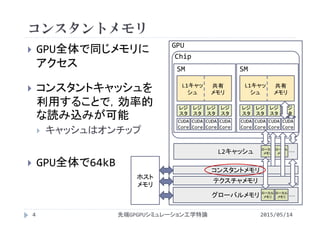
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3


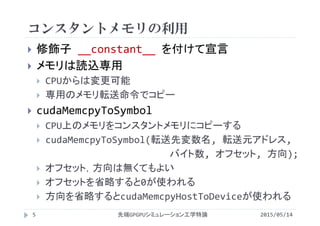

![コンスタントメモリの宣言
サイズは静的に決定
__constant__ 型 変数名;
__constant__ 型 変数名[要素数];
配列としても宣言可能
要素数はコンパイル時に確定している必要がある
cudaMalloc()やcudaFree()は不要
グローバル変数として宣言し,複数のカーネルから
アクセス
読込専用のメモリならではの使い方
書込可能なメモリでは厳禁
2015/05/14先端GPGPUシミュレーション工学特論7](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-7-320.jpg)


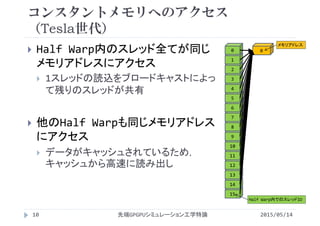




![コンスタントメモリ利用の例
2015/05/14先端GPGPUシミュレーション工学特論
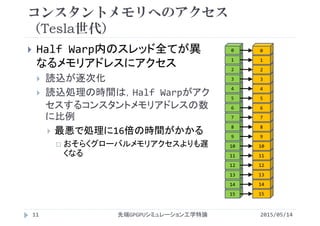
ベクトル和
ベクトルAとBの値が全て同じ
コンスタントメモリにデータを一つ置き,全スレッドが参照
・・・
・・・
・・・c[i]
a[i]
b[i]
+ + + + +
・・・c[i]
a
b
+
16](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-16-320.jpg)
![#define N (8*1024) //64kBに収める
#define Nbytes (N*sizeof(float))
#define NT (256)
#define NB (N/NT)
__global__ void init(float *a,
float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
__global__ void add(float *a,
float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
cudaMalloc((void **)&a, Nbytes);
cudaMalloc((void **)&b, Nbytes);
cudaMalloc((void **)&c, Nbytes);
init<<< NB, NT>>>(a,b,c);
add<<< NB, NT>>>(a,b,c);
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}
GPUプログラム(グローバルメモリ利用)
2015/05/14先端GPGPUシミュレーション工学特論
vectoradd.cu
17](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-17-320.jpg)
![#define N (8*1024) //64kBに収める
#define Nbytes (N*sizeof(float))
#define NT (256)
#define NB (N/NT)
__constant__ float a[N],b[N];
__global__ void init(float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = 0.0f;
}
__global__ void add(float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
int main(void){
float *c;
float *host_a,*host_b;
int i;
host_a=(float *)malloc(Nbytes);
host_b=(float *)malloc(Nbytes);
cudaMalloc((void **)&c,Nbytes);
for(i=0;i<N;i++){
host_a[i] = 1.0f;
host_b[i] = 2.0f;
}
cudaMemcpyToSymbol
(a,host_a,Nbytes);
cudaMemcpyToSymbol
(b,host_b,Nbytes);
init<<< NB, NT>>>(c);
add<<< NB, NT>>>(c);
return 0;
}
コンスタントメモリ(単純な置き換え)
2015/05/14先端GPGPUシミュレーション工学特論
vectoradd_constant.cu
18](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-18-320.jpg)
![実行時間
2015/05/14先端GPGPUシミュレーション工学特論
入力配列サイズ N = 213
スレッド数 NT = 256
各スレッドがコンスタントメモリの異なるアドレスにアクセス
すると,グローバルメモリよりも遅くなる
カーネル 実行時間 [ms]
vectoradd 7.65×10‐3
vectoradd_constant 1.01×10‐2
19](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-19-320.jpg)
![#define N (8*1024) //64kBに収める
#define Nbytes (N*sizeof(float))
#define NT (256)
#define NB (N/NT)
__constant__ float a, b;
__global__ void init(float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = 0.0f;
}
__global__ void add(float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a + b;
}
int main(void){
float *c;
float host_a,host_b;
host_a=1.0f;
host_b=2.0f;
cudaMalloc((void **)&c,Nbytes);
//host_a,host_bが配列ではないので
//アドレスを取り出すために&を付ける
cudaMemcpyToSymbol
(a,&host_a,sizeof(float));
cudaMemcpyToSymbol
(b,&host_b,sizeof(float));
init<<< NB, NT>>>(c);
add<<< NB, NT>>>(c);
return 0;
}
コンスタントメモリ(同一アドレス参照)
2015/05/14先端GPGPUシミュレーション工学特論
vectoradd_broadcast.cu
20](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-20-320.jpg)
![実行時間
2015/05/14先端GPGPUシミュレーション工学特論
入力配列サイズ N = 213
スレッド数 NT = 256
各スレッドがコンスタントメモリの同一アドレスにアクセスす
ると高速化
カーネル 実行時間 [ms]
vectoradd 7.65×10‐3
vectoradd_constant 1.01×10‐2
vectoradd_broadcast 7.55×10‐3
21](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-21-320.jpg)
![実行時間
2015/05/14先端GPGPUシミュレーション工学特論
入力配列サイズ N = 220
スレッド数 NT = 256
配列サイズが多くなると,コンスタントメモリの利用が有効
定数を参照する場合,#defineで定義した方が高速に実
行できるので使いどころが難しい
畳み込みのような処理を行うカーネル内で,全スレッドが
同じ係数テーブルにアクセスするような場合に有効
カーネル 実行時間 [ms]
vectoradd 0.116
vectoradd_broadcast 0.042
22](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-22-320.jpg)


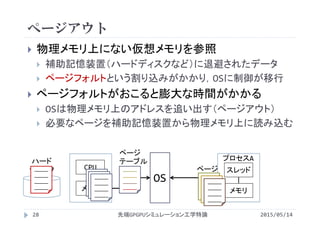





![データ転送の性能
2015/05/14先端GPGPUシミュレーション工学特論
入力配列サイズ N = 226
ページロックメモリの利用により転送速度が約2倍に向上
相対的に遅かったGPU→CPUの転送が特に高速化
メモリ
実行時間 [ms]
CPU to GPU / GPU to CPU
転送速度 [GB/s]
CPU to GPU / GPU to CPU
ページング可能 99.1 / 117 2.5 / 2.1
ページロック 44.8 / 42.1 5.6 / 5.9
36](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-36-320.jpg)



![データ転送の性能
2015/05/14先端GPGPUシミュレーション工学特論
入力配列サイズ N = 226
フラグによって性能が変わるが,どれも大して高速化しない
メモリ
実行時間 [ms]
CPU to GPU / GPU to CPU
転送速度 [GB/s]
CPU to GPU / GPU to CPU
ページング可能 99.1 / 117 2.5 / 2.1
cudaHostRegister
Default
76.4 / 85.2 3.3 / 2.9
cudaHostRegister
Portable
81.0 / 125 3.1 / 2.0
cudaHostRegister
Mapped
93.1 / 122 2.7 / 2.1
40](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-40-320.jpg)





![#define N (1024*1024)
#define Nbytes (N*sizeof(float))
#define NT (256)
#define NB (N/NT)
void init(float *a, float *b, float *c){
int i;
for(i=0;i<N;i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
}
__global__
void add(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
int main(){
float *a,*b,*c;
float *dev_a,*dev_b,*dev_c;
cudaEvent_t start,stop;
float elapsed_time_ms = 0.0f;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaHostAlloc((void **)&a, Nbytes,
cudaHostAllocDefault);
cudaHostAlloc((void **)&b, Nbytes,
cudaHostAllocDefault);
cudaHostAlloc((void **)&c, Nbytes,
cudaHostAllocDefault);
cudaMalloc((void **)&dev_a, Nbytes);
cudaMalloc((void **)&dev_b, Nbytes);
cudaMalloc((void **)&dev_c, Nbytes);
初期化と転送も含めたベクトル和
2015/05/14先端GPGPUシミュレーション工学特論
vectoradd_host.cu
46](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-46-320.jpg)

![#define N (1024*1024)
#define Nbytes (N*sizeof(float))
#define NT (256)
#define NB (N/NT)
__global__
void init(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
__global__
void add(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
int main(){
float *a,*b,*c;
float *dev_a,*dev_b,*dev_c;
cudaEvent_t start,stop;
float elapsed_time_ms = 0.0f;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaSetDevice(0);
cudaSetDeviceFlags(cudaDeviceMapHost);
cudaHostAlloc( (void **)&a, Nbytes,
cudaHostAllocWriteCombined |
cudaHostAllocMapped);
cudaHostAlloc( (void **)&b, Nbytes,
cudaHostAllocWriteCombined |
cudaHostAllocMapped);
cudaHostAlloc( (void **)&c, Nbytes,
cudaHostAllocWriteCombined |
cudaHostAllocMapped);
ゼロコピーによるベクトル和
2015/05/14先端GPGPUシミュレーション工学特論
vectoradd_zerocopy.cu
48](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-48-320.jpg)

![実行時間(初期化とベクトル和+転送)
2015/05/14先端GPGPUシミュレーション工学特論
入力配列サイズ N = 220
スレッド数 NT = 256
ゼロコピーは全てCPUで実行するよりは早い
全てGPUで実行するよりかなり遅い
カーネル 実行時間 [ms]
全てCPUで実行 8.74
全てGPUで実行 0.249
vectoradd_host 7.88
vectoradd_zerocopy 3.44
50
−ベクトル和
+転送](https://image.slidesharecdn.com/advancedgpgpu05-160307055806/85/2015-GPGPU-5-GPU-50-320.jpg)

























































































