GPGPU実践プログラミングの実施結果
2016/06/01第21回計算工学講演会33
受講学生数 9人
単位取得学生数 8人
達成度自己評価(全学生の平均値)
受講前
受講後
項目 目標
a
GPUのアーキテクチャを理解し,CPUのアーキテクチャとの違いを
説明できる.
b
GPGPUのプログラム構造を理解し,並列化の概念をCPUの並列
化と対応付けて説明できる.
c GPGPUのメモリ階層を理解し,その特性を説明できる.
d
GPGPUでの高速化手法を理解し,適切なアルゴリズムを選択し,
その理由をアーキテクチャと関連付けて説明できる.
e 数値計算をGPUへ実装し,その性能を評価できる.
f 各種ライブラリの使用方法を取得し,実際にプログラムを作成し,
その性能を評価できる.
g パフォーマンス解析ツールの使用方法を習得し,プログラムの
性能を評価し,その情報を基に性能を改善できる.
a
b
f
de
g
c
8人が平成26年度の講義を受講,単位取得
理解度
先端GPGPUシミュレーション工学特論の実施結果
2016/06/01第21回計算工学講演会35
受講学生数 16人
単位取得学生数 14人
達成度自己評価(全学生の平均値)
項目 目標
a 産業界におけるGPUの役割を説明できる.
b
GPUプログラミングでのメモリの最適な使用方法を理解し,適切
なメモリを選択できる.
c 分岐条件におけるパフォーマンス低下の理由を理解し,回避方
法や適切な実装方法を説明できる.
d 数値計算の高速化手法を修得し,プログラムを作成して実行し,
その性能を評価できる.
e
CPUとGPUの協調プログラミングを修得し,プログラムを作成する
事ができる.
2人が平成25,26年度の講義を受講,単位取得,
9人が平成25年度の講義を受講,単位取得
a
b
d
e
c
理解度
受講前
受講後
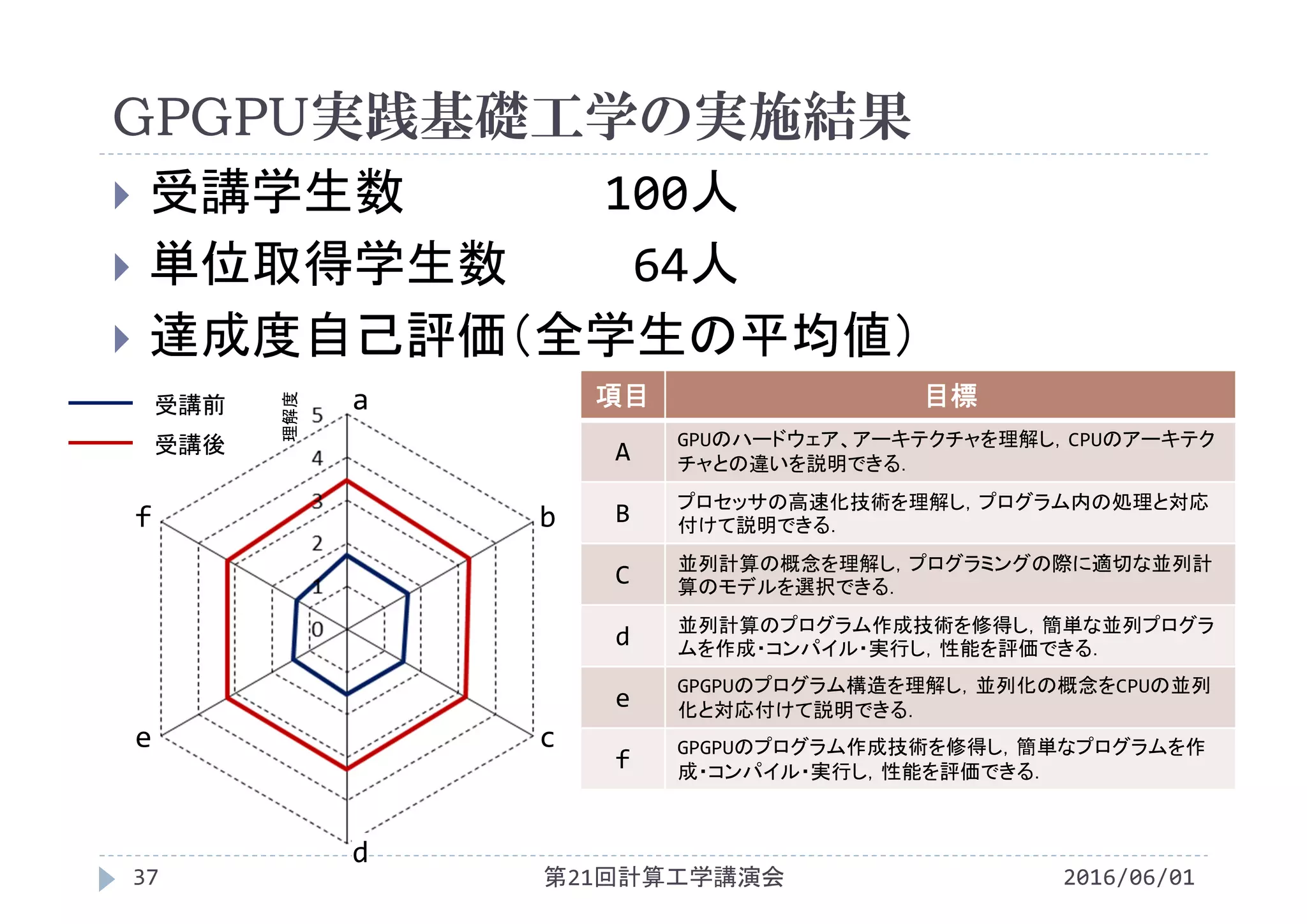
GPGPU実践基礎工学の実施結果
2016/06/01第21回計算工学講演会37
受講学生数 100人
単位取得学生数 64人
達成度自己評価(全学生の平均値)
受講前
受講後
a
bf
d
e c
理解度
項目 目標
A
GPUのハードウェア、アーキテクチャを理解し,CPUのアーキテク
チャとの違いを説明できる.
B プロセッサの高速化技術を理解し,プログラム内の処理と対応
付けて説明できる.
C 並列計算の概念を理解し,プログラミングの際に適切な並列計
算のモデルを選択できる.
d 並列計算のプログラム作成技術を修得し,簡単な並列プログラ
ムを作成・コンパイル・実行し,性能を評価できる.
e
GPGPUのプログラム構造を理解し,並列化の概念をCPUの並列
化と対応付けて説明できる.
f
GPGPUのプログラム作成技術を修得し,簡単なプログラムを作
成・コンパイル・実行し,性能を評価できる.












































































![[関東GPGPU勉強会#2] ライブラリを使って大規模疎行列線形方程式を解いてみよう](https://cdn.slidesharecdn.com/ss_thumbnails/kantogpgpu2-130608041648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










































