長岡技術科学大学
2015年度先端GPGPUシミュレーション工学特論(全15回,大学院生対象講義)
第3回GPUプログラム構造の詳細�(threadとwarp)
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
・第1回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180326
・第2回 GPUによる並列計算の概念とメモリアクセス
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59180382
・第3回 GPUプログラム構造の詳細(threadとwarp)
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59180483
・第4回 GPUのメモリ階層の詳細(共有メモリ)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59180572
・第5回 GPUのメモリ階層の詳細(様々なメモリの利用)
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59180652
・第6回 プログラムの性能評価指針(Flop/Byte,計算律速,メモリ律速)
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59180736
・第7回 総和計算(Atomic演算)
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59180844
・第8回 偏微分方程式の差分計算(拡散方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59180918
・第9回 偏微分方程式の差分計算(移流方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59180982
・第10回 Poisson方程式の求解(線形連立一次方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59181031
・第11回 数値流体力学への応用(支配方程式,CPUプログラム)
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59181134
・第12回 数値流体力学への応用(GPUへの移植)
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59181230
・第13回 数値流体力学への応用(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59181316
・第14回 複数GPUの利用
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59181367
・第15回 CPUとGPUの協調
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59181450
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3

![GPUによる1次元的な並列処理
ベクトル和C=A+B
配列要素に対して計算順序の依存性がなく,最も単純に
並列化可能
・・・
・・・
・・・c[i]
a[i]
b[i]
+ + + + + +
2015/04/23先端GPGPUシミュレーション工学特論3](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-3-320.jpg)
![#include<stdlib.h>
#define N (1024*1024)
#define Nbytes (N*sizeof(float))
void init(float *a,float *b,float *c){
int i;
for(i=0; i<N; i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
}
void add(float *a,float *b,float *c){
int i;
for(i=0; i<N; i++)
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
a = (float *)malloc(Nbytes);
b = (float *)malloc(Nbytes);
c = (float *)malloc(Nbytes);
init(a,b,c);
add(a,b,c);
free(a);
free(b);
free(c);
return 0;
}
CPUプログラム(メモリの動的確保)
2015/04/23先端GPGPUシミュレーション工学特論4
vectoradd_malloc.c](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-4-320.jpg)





![iを一意に決定する
N=8, <<<2, 4>>>で実行
c[i]
a[i]
b[i]
+ + + + + + + +
gridDim.x=2
blockIdx.x=0 blockIdx.x=1
blockDim.x=4blockDim.x=4threadIdx.x=
0 1 2 3 0 1 2 3
threadIdx.x=
i= 0 1 2 3 4 5 6 7
= blockIdx.x*blockDim.x + threadIdx.x
2015/04/23先端GPGPUシミュレーション工学特論10](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-10-320.jpg)
![カーネルの書き換え
1スレッドが実行する処理になるよう変更
1スレッドがある添字 i の要素を担当
#define N (1024*1024)
#define Nbytes (N*sizeof(float))
__global__ void init(float *a, float *b, float *c){
int i=blockIdx.x*blockDim.x + threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
__global__ void add(float *a, float *b, float *c){
int i=blockIdx.x*blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}
2015/04/23先端GPGPUシミュレーション工学特論11](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-11-320.jpg)

![#define N (1024*1024)
#define Nbytes (N*sizeof(float))
__global__ void init(float *a,
float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
__global__ void add(float *a,
float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
int main(void){
float *a,*b,*c;
cudaMalloc((void **)&a, Nbytes);
cudaMalloc((void **)&b, Nbytes);
cudaMalloc((void **)&c, Nbytes);
init<<< N/256, 256>>>(a,b,c);
add<<< N/256, 256>>>(a,b,c);
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}
GPUで並列実行するプログラム
2015/04/23先端GPGPUシミュレーション工学特論13
vectoradd.cu](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-13-320.jpg)




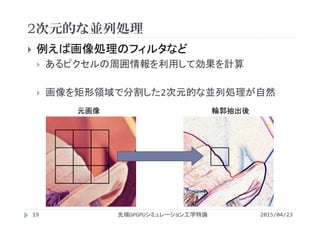
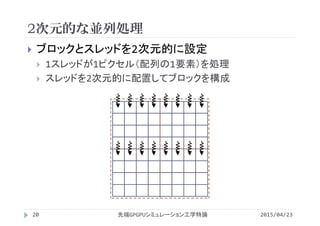
![想定されるカーネル
1スレッドが2次元配列の1要素を計算
1スレッドがある添字 i,j の要素を担当
#define Nx (1920)
#define Ny (1080)
__global__ void filter(...){
int i = ; //1スレッドが担当する配列要素の添字を決定
int j = ; //
picture[i][j] = ...;
}
2015/04/23先端GPGPUシミュレーション工学特論21](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-21-320.jpg)
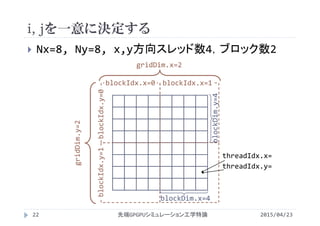
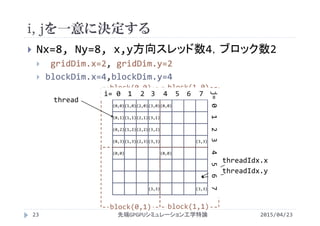

![1次元による配列で2次元配列の表現
2015/04/23先端GPGPUシミュレーション工学特論25
mallocやcudaMallocは1次元配列を宣言
2次元配列の宣言は不可能
1次元配列を宣言し,2次元配列的に参照
2次元配列の場合
1次元配列の場合
picutre[1][2] = 11
picture[_______] = 11
Nx=8
1*8 + 2
picture[i][j] picture[i*Ny+j]
j
i
1
2
3
4
5
9
10
11
12
6
7
8
picture[Nx][Ny]
Ny=8](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-25-320.jpg)
![想定されるカーネル
1スレッドが2次元配列の1要素を計算
1スレッドがある添字 i,j の要素を担当
#define Nx (1920)
#define Ny (1080)
__global__ void filter(...){
int i = blockIdx.x*blockDim.x + threadIdx.x;
int j = blockIdx.y*blockDim.y + threadIdx.y;
picture[i*Ny + j] = ...;
}
2015/04/23先端GPGPUシミュレーション工学特論26
picture[j*Nx + i] = ... の方が適切
第4回GPUのメモリ階層の詳細(共有メモリ)を参照の事](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-26-320.jpg)

![#define Nx (1024)
#define Ny (1024)
#define Nbytes (Nx*Ny*sizeof(float))
#define NTx (16)
#define NTy (16)
#define NBx (Nx/NTx)
#define NBy (Ny/NTy)
__global__ void init(float *a, float *b,
float *c){
int i = blockIdx.x*blockDim.x + threadIdx.x;
int j = blockIdx.y*blockDim.y + threadIdx.y;
int ij = i*Ny + j;
a[ij] = 1.0;
b[ij] = 2.0;
c[ij] = 0.0;
}
__global__ void add(float *a, float *b,
float *c){
int i = blockIdx.x*blockDim.x + threadIdx.x;
int j = blockIdx.y*blockDim.y + threadIdx.y;
int ij = i*Ny + j;
c[ij] = a[ij] + b[ij];
}
int main(void){
float *a,*b,*c;
dim3 thread(NTx, NTy, 1);
dim3 block(NBx, NBy, 1);
cudaMalloc( (void **)&a, Nbytes);
cudaMalloc( (void **)&b, Nbytes);
cudaMalloc( (void **)&c, Nbytes);
init<<< block, thread >>>(a,b,c);
add<<< block, thread >>>(a,b,c);
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}
ベクトル和(2次元並列版)
2015/04/23先端GPGPUシミュレーション工学特論28
vectoradd2d.cu
int ij=j*Nx+iの方が適切
int ij=j*Nx+iの方が適切](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-28-320.jpg)
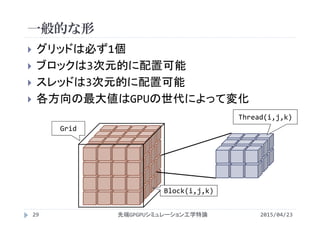


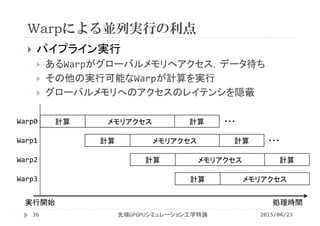

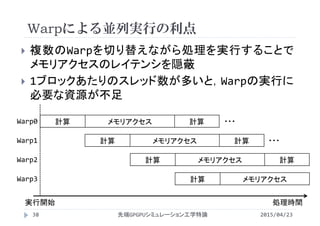

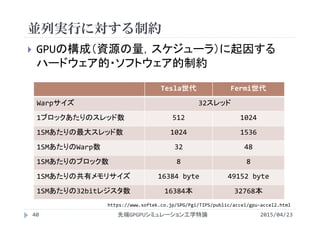


![並列実行に対する制約
2015/04/23先端GPGPUシミュレーション工学特論43
並列実行されるブロックの数
1ブロックあたりの共有メモリやレジスタの使用量で制限
1ブロックあたりのスレッド数がNt
1ブロックが共有メモリをS[byte]利用していると
49152/S [block/SM]
1スレッドがレジスタをR[本]利用していると
32768/(Nt×R) [block/SM]
並列実行されるブロック数
min{8, 48/(Nt/32), 49152/S, 32768/(Nt×R)}
太字:利用するGPUによって決定
下線:ユーザの設定によって決定
斜体:処理内容やコンパイラによって決定](https://image.slidesharecdn.com/advancedgpgpu03-160307055357/85/2015-GPGPU-3-GPU-thread-warp-39-320.jpg)