長岡技術科学大学
2015年度先端GPGPUシミュレーション工学特論(全15回,大学院生対象講義)
第15回CPUとGPUの協調
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
・第1回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180326
・第2回 GPUによる並列計算の概念とメモリアクセス
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59180382
・第3回 GPUプログラム構造の詳細(threadとwarp)
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59180483
・第4回 GPUのメモリ階層の詳細(共有メモリ)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59180572
・第5回 GPUのメモリ階層の詳細(様々なメモリの利用)
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59180652
・第6回 プログラムの性能評価指針(Flop/Byte,計算律速,メモリ律速)
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59180736
・第7回 総和計算(Atomic演算)
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59180844
・第8回 偏微分方程式の差分計算(拡散方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59180918
・第9回 偏微分方程式の差分計算(移流方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59180982
・第10回 Poisson方程式の求解(線形連立一次方程式)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59181031
・第11回 数値流体力学への応用(支配方程式,CPUプログラム)
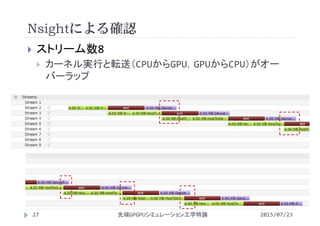
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59181134
・第12回 数値流体力学への応用(GPUへの移植)
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59181230
・第13回 数値流体力学への応用(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59181316
・第14回 複数GPUの利用
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59181367
・第15回 CPUとGPUの協調
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59181450
2015年度GPGPU実践基礎工学
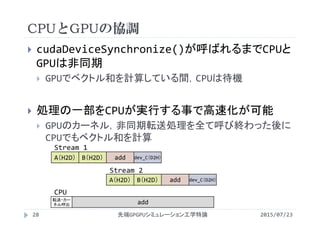
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3



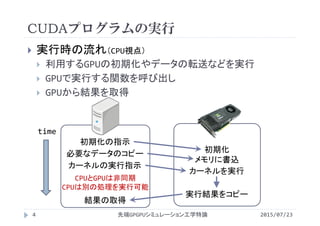









![ストリームを用いた並行実行
2015/07/23先端GPGPUシミュレーション工学特論16
ストリームの作成(具体的に番号を付けるわけではない)
cudaStreamCreate(cudaStream_t *);
ストリームの破棄
cudaStreamDestroy(cudaStream_t);
cudaStream_t stream1, stream2,stream[10];
cudaStreamCreate(&stream1); //個別の変数でストリームを管理することが可能
cudaStreamCreate(&stream2); //
for(int i=0;i<10;i++)
cudaStreamCreate(&stream[i]);//配列でストリームを管理することも可能
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
for(int i=0;i<10;i++)
cudaStreamDestroy(stream[i]);](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-16-320.jpg)



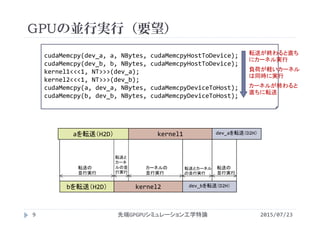
![#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
#define N (1024*1024*8)
#define Nbytes (N*sizeof(float))
#define NT 256
#define NB (N/NT)
//Streamの数=並行実行数
#define Stream 4
//カーネルは変更なし
__global__ void init
(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
//カーネルは変更なし
__global__ void add
(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
ベクトル和(ストリームの利用)
2015/07/23先端GPGPUシミュレーション工学特論21
vectoradd_stream.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-21-320.jpg)
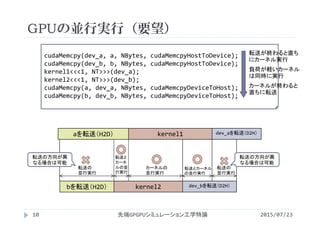
![int main(){
float *a,*b,*c;
int stm;
cudaStream_t stream[Stream];
//ページロックホストメモリを確保
float *host_a, *host_b, *host_c;
cudaHostAlloc((void **)&host_c,
Nbytes, cudaHostAllocDefault);
cudaHostAlloc((void **)&host_a,
Nbytes, cudaHostAllocDefault);
cudaHostAlloc((void **)&host_b,
Nbytes, cudaHostAllocDefault);
for(int i=0;i<N;i++){
host_a[i] = 1.0f;
host_b[i] = 2.0f;
host_c[i] = 0;
}
for(stm=0;stm<Stream;stm++){
cudaStreamCreate(&stream[stm]);
}
cudaMalloc( (void **)&a, Nbytes);
cudaMalloc( (void **)&b, Nbytes);
cudaMalloc( (void **)&c, Nbytes);
ベクトル和(ストリームの利用)
2015/07/23先端GPGPUシミュレーション工学特論22
vectoradd_stream.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-22-320.jpg)
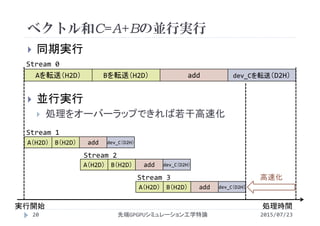
![double time_start = omp_get_wtime();
for(stm=0;stm<Stream;stm++){
int idx = stm*N/Stream;
cudaMemcpyAsync(&a[idx], &host_a[idx], Nbytes/Stream, cudaMemcpyHostToDevice,
stream[stm]);
cudaMemcpyAsync(&b[idx], &host_b[idx], Nbytes/Stream, cudaMemcpyHostToDevice,
stream[stm]);
add<<< NB/Stream, NT, 0 ,stream[stm]>>>(&a[idx],&b[idx],&c[idx]);
cudaMemcpyAsync(&host_c[idx], &c[idx], Nbytes/Stream, cudaMemcpyDeviceToHost,
stream[stm]);
}
cudaDeviceSynchronize();
double time_end = omp_get_wtime();
ベクトル和(ストリームの利用)
2015/07/23先端GPGPUシミュレーション工学特論23
vectoradd_stream.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-23-320.jpg)
![double sum=0;
for(int i=0;i<N;i++)sum+=host_c[i];
printf("%f¥n",sum/N);
printf("elapsed time = %f sec¥n",
time_end‐time_start);
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaFree(a);
cudaFree(b);
cudaFree(c);
for(stm=0;stm<Stream;stm++){
cudaStreamDestroy(stream[stm]);
}
return 0;
}
ベクトル和(ストリームの利用)
2015/07/23先端GPGPUシミュレーション工学特論24
vectoradd_stream.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-24-320.jpg)
![実行結果
2015/07/23先端GPGPUシミュレーション工学特論25
配列の要素数 N=223
1ブロックあたりのスレッド数 256
OpenMPの関数を用いて実行時間を測定
コンパイルにはオプション‐Xcompiler ‐fopenmpが必要
ストリーム数 実行時間[ms]
1 17.5
2 15.5
4 14.5
8 14.1
16 14.0
ストリーム数
実行時間[ms]](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-25-320.jpg)
![プロファイラによる確認
2015/07/23先端GPGPUシミュレーション工学特論26
ストリーム数4
メモリ転送とベクトル和を4セット実行
# CUDA_PROFILE_LOG_VERSION 2.0
# CUDA_DEVICE 0 Tesla M2050
# TIMESTAMPFACTOR fffff60a9ac44950
timestamp,method,gputime,cputime,occupancy
timestamp=[ 92925.000 ] method=[ memcpyHtoDasync ] gputime=[ 1403.488 ] cputime=[ 16.000 ]
timestamp=[ 92948.000 ] method=[ memcpyHtoDasync ] gputime=[ 1410.880 ] cputime=[ 5.000 ]
timestamp=[ 92977.000 ] method=[ _Z3addPfS_S_ ] gputime=[ 253.472 ] cputime=[ 23.000 ] occupancy=[ 1.000 ]
timestamp=[ 93005.000 ] method=[ memcpyDtoHasync ] gputime=[ 1520.448 ] cputime=[ 6.000 ]
timestamp=[ 93014.000 ] method=[ memcpyHtoDasync ] gputime=[ 1931.936 ] cputime=[ 6.000 ]
timestamp=[ 93021.000 ] method=[ memcpyHtoDasync ] gputime=[ 1414.272 ] cputime=[ 5.000 ]
timestamp=[ 93029.000 ] method=[ _Z3addPfS_S_ ] gputime=[ 253.248 ] cputime=[ 8.000 ] occupancy=[ 1.000 ]
timestamp=[ 93038.000 ] method=[ memcpyDtoHasync ] gputime=[ 1521.216 ] cputime=[ 5.000 ]
timestamp=[ 93045.000 ] method=[ memcpyHtoDasync ] gputime=[ 1935.456 ] cputime=[ 6.000 ]
timestamp=[ 93053.000 ] method=[ memcpyHtoDasync ] gputime=[ 1417.152 ] cputime=[ 6.000 ]
timestamp=[ 93060.000 ] method=[ _Z3addPfS_S_ ] gputime=[ 252.352 ] cputime=[ 7.000 ] occupancy=[ 1.000 ]
timestamp=[ 93068.000 ] method=[ memcpyDtoHasync ] gputime=[ 1566.624 ] cputime=[ 6.000 ]
timestamp=[ 93076.000 ] method=[ memcpyHtoDasync ] gputime=[ 1978.208 ] cputime=[ 6.000 ]
timestamp=[ 93083.000 ] method=[ memcpyHtoDasync ] gputime=[ 1414.528 ] cputime=[ 6.000 ]
timestamp=[ 93090.000 ] method=[ _Z3addPfS_S_ ] gputime=[ 225.568 ] cputime=[ 8.000 ] occupancy=[ 1.000 ]
timestamp=[ 93099.000 ] method=[ memcpyDtoHasync ] gputime=[ 1319.040 ] cputime=[ 6.000 ]](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-26-320.jpg)
![#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
#define N (1024*1024*8)
#define Nbytes (N*sizeof(float))
#define NT 256
#define NB (N/NT)
//Streamの数=並行実行数
#define Stream 4
//CPUのStream分担数
//GPUはStream‐CPU分の数だけ並行処理を実行
#define CPU 1
//カーネルは変更なし
__global__ void init
(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
//カーネルは変更なし
__global__ void add
(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
ベクトル和(CPU・GPU協調)
2015/07/23先端GPGPUシミュレーション工学特論29
vectoradd_coop.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-29-320.jpg)
![int main(){
float *a,*b,*c;
int stm;
cudaStream_t stream[Stream];
float *host_a, *host_b, *host_c;
cudaHostAlloc((void **)&host_c,
Nbytes, cudaHostAllocDefault);
cudaHostAlloc((void **)&host_a,
Nbytes, cudaHostAllocDefault);
cudaHostAlloc((void **)&host_b,
Nbytes, cudaHostAllocDefault);
for(int i=0;i<N;i++){
host_a[i] = 1.0f;
host_b[i] = 2.0f;
host_c[i] = 0;
}
for(stm=0;stm<Stream‐CPU;stm++){
cudaStreamCreate(&stream[stm]);
}
cudaMalloc( (void **)&a, Nbytes);
cudaMalloc( (void **)&b, Nbytes);
cudaMalloc( (void **)&c, Nbytes);
ベクトル和(CPU・GPU協調)
2015/07/23先端GPGPUシミュレーション工学特論30
vectoradd_coop.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-30-320.jpg)
![double time_start = omp_get_wtime();
for(stm=0;stm<Stream‐CPU;stm++){
int idx = stm*N/Stream;
cudaMemcpyAsync(&a[idx], &host_a[idx], Nbytes/Stream, cudaMemcpyHostToDevice,
stream[stm]);
cudaMemcpyAsync(&b[idx], &host_b[idx], Nbytes/Stream, cudaMemcpyHostToDevice,
stream[stm]);
add<<< NB/Stream, NT, 0 ,stream[stm]>>>(&a[idx],&b[idx],&c[idx]);
cudaMemcpyAsync(&host_c[idx], &c[idx], Nbytes/Stream, cudaMemcpyDeviceToHost,
stream[stm]);
}
for(int i=(Stream‐CPU)*N/Stream;i<N;i++)
host_c[i] = host_a[i] + host_b[i];
cudaDeviceSynchronize();
double time_end = omp_get_wtime();
ベクトル和(CPU・GPU協調)
2015/07/23先端GPGPUシミュレーション工学特論31
vectoradd_coop.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-31-320.jpg)
![double sum=0;
for(int i=0;i<N;i++)sum+=host_c[i];
printf("%f¥n",sum/N);
printf("elapsed time = %f sec¥n",
time_end‐time_start);
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaFree(a);
cudaFree(b);
cudaFree(c);
for(stm=0;stm<Stream‐CPU;stm++){
cudaStreamDestroy(stream[stm]);
}
return 0;
}
ベクトル和(CPU・GPU協調)
2015/07/23先端GPGPUシミュレーション工学特論32
vectoradd_coop.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-32-320.jpg)

![実行結果
2015/07/23先端GPGPUシミュレーション工学特論34
ストリーム
数
CPU
負荷割合
実行時間
[ms]
1
0 (GPU) 17.6
1 (CPU) 36.4
2
0.0 15.5
0.5 18.3
1.0 36.4
4
0.00 14.5
0.25 11.2
0.50 18.3
0.75 27.4
1.00 36.3
ストリーム
数
CPU
負荷割合
実行時間
[ms]
8
0.000 14.1
0.125 12.5
0.250 10.8
0.375 13.8
0.500 18.3
0.625 22.9
0.750 27.4
0.875 31.9
1.000 36.3](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-34-320.jpg)
![実行結果
2015/07/23先端GPGPUシミュレーション工学特論35
ストリーム
数
CPU
負荷割合
実行時間
[ms]
16
0.0000 14.0
0.0625 13.1
0.1250 12.2
0.1875 11.5
0.2500 10.6
0.3125 11.6
0.3750 13.9
0.4375 16.2
0.5000 18.4
ストリーム
数
CPU
負荷割合
実行時間
[ms]
16
0.5625 20.6
0.6250 22.9
0.6875 25.1
0.7500 27.5
0.8125 29.6
0.8750 31.9
0.9375 34.3
1.0000 36.3
grouseではCPUが全体の処理の1/4を処理すると最も効率が良い](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-35-320.jpg)
![実行結果
2015/07/23先端GPGPUシミュレーション工学特論36
CPU負荷割合
実行時間[ms]
ストリーム数](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-36-320.jpg)
![OpenMP
2015/07/23先端GPGPUシミュレーション工学特論38
並列に処理を実行させる箇所に指示句(ディレクティ
ブ)を挿入
for文の並列化
ディレクティブを一行追加(#pragma omp ~)
#pragma omp parallel for
for(int i=0; i<N; i++)
C[i] = A[i] + B[i]](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-38-320.jpg)
![#include<stdio.h>
#include<stdlib.h>
#define N (1024*1024)
#define Nbytes (N*sizeof(float))
int main(){
float *a,*b,*c;
int i;
a = (float *)malloc(Nbytes);
b = (float *)malloc(Nbytes);
c = (float *)malloc(Nbytes);
for(i=0; i<N; i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
for(i=0; i<N; i++)
c[i] = a[i] + b[i];
for(i=0; i<N; i++)
printf("%f+%f=%f¥n",
a[i],b[i],c[i]);
return 0;
}
逐次(並列化前)プログラム
2015/07/23先端GPGPUシミュレーション工学特論39](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-39-320.jpg)
![並列化プログラム
2015/07/23先端GPGPUシミュレーション工学特論40
#include<stdio.h>
#include<stdlib.h>
#define N (1024*1024)
#define Nbytes (N*sizeof(float))
int main(){
float *a,*b,*c;
int i;
a = (float *)malloc(Nbytes);
b = (float *)malloc(Nbytes);
c = (float *)malloc(Nbytes);
#pragma omp parallel
{
#pragma omp for
for(i=0; i<N; i++){
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
#pragma omp for
for(i=0; i<N; i++)
c[i] = a[i] + b[i];
}
for(i=0; i<N; i++)
printf("%f+%f=%f¥n",
a[i],b[i],c[i]);
return 0;
}](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-40-320.jpg)





![#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
#define N (1024*1024*8)
#define Nbytes (N*sizeof(float))
#define NT 256
#define NB (N/NT)
#define Stream 4
#define CPU 2
#define Threads 12
//カーネルは変更なし
__global__ void init
(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
a[i] = 1.0;
b[i] = 2.0;
c[i] = 0.0;
}
//カーネルは変更なし
__global__ void add
(float *a, float *b, float *c){
int i = blockIdx.x*blockDim.x
+ threadIdx.x;
c[i] = a[i] + b[i];
}
ベクトル和(CPUをOpenMPで並列化)
2015/07/23先端GPGPUシミュレーション工学特論46
vectoradd_coop_omp.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-46-320.jpg)
![int main(){
float *a,*b,*c;
int stm;
cudaStream_t stream[Stream];
float *host_a, *host_b, *host_c;
cudaHostAlloc((void **)&host_c,
Nbytes, cudaHostAllocDefault);
cudaHostAlloc((void **)&host_a,
Nbytes, cudaHostAllocDefault);
cudaHostAlloc((void **)&host_b,
Nbytes, cudaHostAllocDefault);
for(int i=0;i<N;i++){
host_a[i] = 1.0f;
host_b[i] = 2.0f;
host_c[i] = 0;
}
for(stm=0;stm<Stream‐CPU;stm++){
cudaStreamCreate(&stream[stm]);
}
cudaMalloc( (void **)&a, Nbytes);
cudaMalloc( (void **)&b, Nbytes);
cudaMalloc( (void **)&c, Nbytes);
omp_set_num_threads(Threads);
double time_start = omp_get_wtime();
#pragma omp parallel
{
ベクトル和(CPUをOpenMPで並列化)
2015/07/23先端GPGPUシミュレーション工学特論47
vectoradd_coop_omp.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-47-320.jpg)
![#pragma omp single nowait
{
for(stm=0;stm<Stream‐CPU;stm++){
int idx = stm*N/Stream;
cudaMemcpyAsync(&a[idx], &host_a[idx], Nbytes/Stream,
cudaMemcpyHostToDevice,stream[stm]);
cudaMemcpyAsync(&b[idx], &host_b[idx], Nbytes/Stream,
cudaMemcpyHostToDevice,stream[stm]);
add<<< NB/Stream, NT, 0 ,stream[stm]>>>(&a[idx],&b[idx],&c[idx]);
cudaMemcpyAsync(&host_c[idx], &c[idx], Nbytes/Stream,
cudaMemcpyDeviceToHost,stream[stm]);
}
#pragma omp for
for(int i=(Stream‐CPU)*N/Stream;i<N;i++)
host_c[i] = host_a[i] + host_b[i];
}
} //#pragma omp parallelの終端
ベクトル和(CPUをOpenMPで並列化)
2015/07/23先端GPGPUシミュレーション工学特論48
vectoradd_coop_omp.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-48-320.jpg)
![cudaDeviceSynchronize();
double time_end = omp_get_wtime();
double sum=0;
for(int i=0;i<N;i++)sum+=host_c[i];
printf("%f¥n",sum/N);
printf("elapsed time = %f sec¥n",
time_end‐time_start);
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaFree(a);
cudaFree(b);
cudaFree(c);
for(stm=0;stm<Stream‐CPU;stm++){
cudaStreamDestroy(stream[stm]);
}
return 0;
}
ベクトル和(CPUをOpenMPで並列化)
2015/07/23先端GPGPUシミュレーション工学特論49
vectoradd_coop_omp.cu](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-49-320.jpg)

![実行結果(CPUスレッドごとに最速となる条件)
2015/07/23先端GPGPUシミュレーション工学特論51
スレッド数が多くなると実行時間が実行毎に変化
1スレッドCPU+GPU協調版のような評価ができない
CPUスレッド数 ストリーム数 CPU負荷割合 実行時間[ms]
1 16 0.1875 11.4
2 16 0.3125 9.82
3 16 0.4375 8.32
4 16 0.4375 8.23
5 2 0.5000 10.1
6 16 0.3750 9.18
7 16 0.6875 8.89
8 16 0.6250 8.70
9 4 0.7500 8.87
10 16 0.7500 8.76
11 16 0.5625 10.3
12 16 0.4375 17.8
スレッド数の増加と
ともに,CPUの負荷
割合も増加させる
と高速化に有効](https://image.slidesharecdn.com/advancedgpgpu15-160307061916/85/2015-GPGPU-15-CPU-GPU-51-320.jpg)
























































































