長岡技術科学大学
2015年度GPGPU実践プログラミング(全15回,学部4年対象講義)
第14回N体問題
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
・第2回 GPUのアーキテクチャとプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59179215
・第3回 GPGPUプログラミング環境
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59179255
・第3回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59183677
・第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59179449
・第5回 GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59179536
・第6回 パフォーマンス解析ツール
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59179577
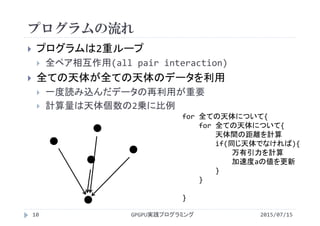
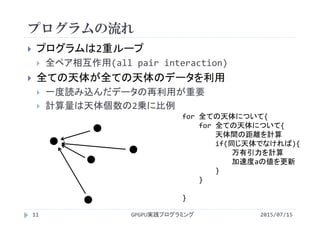
・第7回 総和計算
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59179639
・第8回 総和計算(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59179686
・第9回 行列計算(行列-行列積)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59179722
・第10回 行列計算(行列-行列積の高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59179759
・第11回 画像処理
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59179789
・第12回 偏微分方程式の差分計算
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59179972
・第13回 多粒子の運動
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59180018
・第14回 N体問題
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59180054
・第15回 GPU最適化ライブラリ
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59180086
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
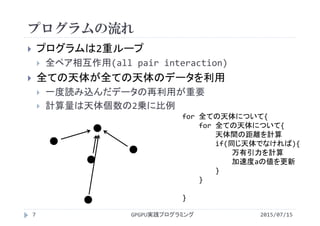
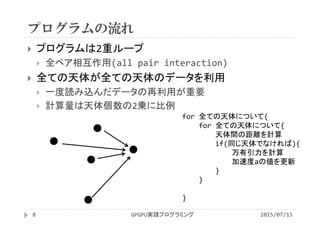
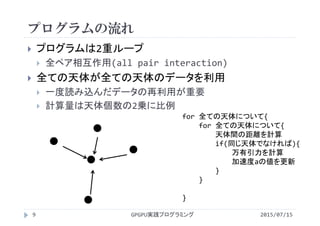
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3







![//初期値の設定
void initial(float *x,float *y,float *z,float *vx,float *vy,float *vz,float *m){
int i;
//乱数で配置を決定
//x,y座標,x,y方向速度が‐1~1の範囲に収まるように決定
srand(N);
for(i=0;i<N;i++){
x[i] = (float)rand()/RAND_MAX*2.0 ‐ 1.0;
y[i] = (float)rand()/RAND_MAX*2.0 ‐ 1.0;
z[i] = 0.0f;
m[i] = 1.0f;
vx[i] = (float)rand()/RAND_MAX*2.0 ‐ 1.0;
vy[i] = (float)rand()/RAND_MAX*2.0 ‐ 1.0;
vz[i] = 0.0f;
}
}
CPUプログラム
2015/07/15GPGPU実践プログラミング14
nbody.c](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-14-320.jpg)
![//時間積分
void integrate(float *x, float *y, float *z,
float *vx, float *vy, float *vz, float *ax, float *ay, float *az){
int i;
//Euler法で位置と速度を積分
//必ず位置の積分を先に実行
for(i=0;i<N;i++){
x[i] = x[i] + dt*vx[i];
y[i] = y[i] + dt*vy[i];
z[i] = z[i] + dt*vz[i];
vx[i] = vx[i] + dt*ax[i];
vy[i] = vy[i] + dt*ay[i];
vz[i] = vz[i] + dt*az[i];
}
}
CPUプログラム
2015/07/15GPGPU実践プログラミング15
nbody.c](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-15-320.jpg)
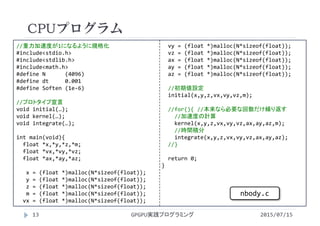
![//加速度の計算
void kernel(float *x, float *y, float *z,
float *vx, float *vy, float *vz,
float *ax, float *ay, float *az,
float *m){
int i,j;
float rx,ry,rz;
float dist2, dist6, invDist3,s;
for(i=0;i<N;i++){
ax[i] = 0.0f;
ay[i] = 0.0f;
az[i] = 0.0f;
}
for(i=0;i<N;i++){
for(j=0;j<N;j++){
//if(i==j)continue;
rx=x[j]‐x[i];
ry=y[j]‐y[i];
rz=z[j]‐z[i];
//2天体間の距離を計算
dist2 = rx*rx + ry*ry + rz*rz
+ Soften;//軟化パラメータ
// m/r^3 の計算
dist6 = dist2*dist2*dist2;
invDist3 = 1.0/sqrt(dist6);
s = m[j]*invDist3;
//天体jによる加速度を加算
ax[i] = ax[i] + rx*s;
ay[i] = ay[i] + ry*s;
az[i] = az[i] + rz*s;
}
}
}
CPUプログラム
2015/07/15GPGPU実践プログラミング16
nbody.c](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-16-320.jpg)


![#define NT 1
#define NB 1
//加速度の計算
__global__ void kernel(float *x,float *y,
float *z,float *vx, float *vy,
float *vz,float *ax, float *ay,
float *az,float *m){
int i,j;
float rx,ry,rz;
float dist2, dist6, invDist3,s;
for(i=0;i<N;i++){
ax[i] = 0.0f;
ay[i] = 0.0f;
az[i] = 0.0f;
}
for(i=0;i<N;i++){
for(j=0;j<N;j++){
if(i==j)continue;
rx=x[j]‐x[i];
ry=y[j]‐y[i];
rz=z[j]‐z[i];
//2天体間の距離を計算
dist2 = rx*rx + ry*ry + rz*rz;
// m/r^3 の計算
dist6 = dist2*dist2*dist2;
invDist3 = 1.0/sqrt(dist6);
s = m[j]*invDist3;
//天体jによる加速度を加算
ax[i] = ax[i] + rx*s;
ay[i] = ay[i] + ry*s;
az[i] = az[i] + rz*s;
}
}
}
GPUプログラム(1スレッド版)
2015/07/15GPGPU実践プログラミング19
kernel0.cu](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-19-320.jpg)
![//時間積分
__global__ void integrate(float *x, float *y, float *z,
float *vx, float *vy, float *vz, float *ax, float *ay, float *az){
int i;
for(i=0;i<N;i++){
x[i] = x[i] + dt*vx[i];
y[i] = y[i] + dt*vy[i];
z[i] = z[i] + dt*vz[i];
vx[i] = vx[i] + dt*ax[i];
vy[i] = vy[i] + dt*ay[i];
vz[i] = vz[i] + dt*az[i];
}
}
GPUプログラム(1スレッド版)
2015/07/15GPGPU実践プログラミング20
kernel0.cu](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-20-320.jpg)
![実行時間
2015/07/15GPGPU実践プログラミング
天体の個数 N = 4096
21
カーネル 実行時間 [ms]
1スレッド実行 33×103](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-21-320.jpg)
![#define NT 1
#define NB 1
//加速度の計算
__global__ void kernel(float *x,float *y,
float *z,float *vx, float *vy,
float *vz,float *ax, float *ay,
float *az,float *m){
int i,j;
float rx,ry,rz;
float dist2, dist6, invDist3,s;
for(i=0;i<N;i++){
ax[i] = 0.0f;
ay[i] = 0.0f;
az[i] = 0.0f;
}
for(i=0;i<N;i++){
for(j=0;j<N;j++){
rx=x[j]‐x[i];
ry=y[j]‐y[i];
rz=z[j]‐z[i];
//2天体間の距離を計算
dist2 = rx*rx + ry*ry + rz*rz
+Soften;
// m/r^3 の計算
dist6 = dist2*dist2*dist2;
invDist3 = 1.0/sqrt(dist6);
s = m[j]*invDist3;
//天体jによる加速度を加算
ax[i] = ax[i] + rx*s;
ay[i] = ay[i] + ry*s;
az[i] = az[i] + rz*s;
}
}
}
GPUプログラム(1スレッド版,if消去)
2015/07/15GPGPU実践プログラミング22
kernel1.cu](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-22-320.jpg)
![実行時間
2015/07/15GPGPU実践プログラミング
天体の個数 N = 4096
23
カーネル 実行時間 [ms]
1スレッド実行 33×103
1スレッド実行(ifの消去) 29×103](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-23-320.jpg)
![1スレッドが天体一つの加速度を計算
2015/07/15GPGPU実践プログラミング24
天体のデータを1次元配列で保持
加速度を求めたい天体iのforループ
相互作用の計算のために参照される天体jのループ
x[i]
x[j]
加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-24-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング25
ベクトル和と本質的には同じ
・・・
・・・
・・・c[i]
a[i]
b[i]
+
for(i=0;i<N;i++){
c[i]=a[i]+b[i];
}
+ + + + +](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-25-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング26
1スレッドが一つの配列添字を計算
・・・
・・・
・・・c[i]
a[i]
b[i]
i=blockIdx.x*blockDim.x+threadIdx.x;
c[i]=a[i]+b[i];
+ + + + + +](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-26-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング27
加速度の計算
・・・x[j]
for(i=0;i<N;i++){
for(j=0;j<N;j++){
加速度を積算
}
}
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
jのループ
i=0](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-27-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング28
加速度の計算
・・・x[j]
for(i=0;i<N;i++){
for(j=0;j<N;j++){
加速度を積算
}
}
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
jのループ
i=1](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-28-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング29
加速度の計算
・・・x[j]
for(i=0;i<N;i++){
for(j=0;j<N;j++){
加速度を積算
}
}
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
jのループ
i=2](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-29-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング30
加速度の計算
・・・x[j]
for(i=0;i<N;i++){
for(j=0;j<N;j++){
加速度を積算
}
}
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
jのループ
i=3](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-30-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング31
加速度の計算
・・・x[j]
for(i=0;i<N;i++){
for(j=0;j<N;j++){
加速度を積算
}
}
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
jのループ
i=4](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-31-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング32
加速度の計算
・・・x[j]
for(i=0;i<N;i++){
for(j=0;j<N;j++){
加速度を積算
}
}
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
jのループ
i=5](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-32-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング33
ベクトル和と同様に1スレッドが一つの天体を計算
i=blockIdx.x*blockDim.x+threadIdx.x;
for(j=0;j<N;j++){
加速度を積算
}
・・・x[j]
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
複数のスレッド(異なるiをもつ)が
一斉にx[j(=0)]の値を読込](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-33-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング34
ベクトル和と同様に1スレッドが一つの天体を計算
i=blockIdx.x*blockDim.x+threadIdx.x;
for(j=0;j<N;j++){
加速度を積算
}
・・・x[j]
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
複数のスレッド(異なるiをもつ)が
一斉にx[j(=1)]の値を読込](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-34-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング35
ベクトル和と同様に1スレッドが一つの天体を計算
i=blockIdx.x*blockDim.x+threadIdx.x;
for(j=0;j<N;j++){
加速度を積算
}
・・・x[j]
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
複数のスレッド(異なるiをもつ)が
一斉にx[j(=2)]の値を読込](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-35-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング36
ベクトル和と同様に1スレッドが一つの天体を計算
i=blockIdx.x*blockDim.x+threadIdx.x;
for(j=0;j<N;j++){
加速度を積算
}
・・・x[j]
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
複数のスレッド(異なるiをもつ)が
一斉にx[j(=3)]の値を読込](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-36-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング37
ベクトル和と同様に1スレッドが一つの天体を計算
i=blockIdx.x*blockDim.x+threadIdx.x;
for(j=0;j<N;j++){
加速度を積算
}
・・・x[j]
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
複数のスレッド(異なるiをもつ)が
一斉にx[j(=4)]の値を読込](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-37-320.jpg)
![GPUによる並列処理の方針
2015/07/15GPGPU実践プログラミング38
ベクトル和と同様に1スレッドが一つの天体を計算
i=blockIdx.x*blockDim.x+threadIdx.x;
for(j=0;j<N;j++){
加速度を積算
}
・・・x[j]
・・・x[i]加速度を求めたい
天体
相互作用の計算の
ために参照される
天体
複数のスレッド(異なるiをもつ)が
一斉にx[j(=5)]の値を読込](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-38-320.jpg)
![#define NT 256
#define NB (N/NT)
//加速度の計算
__global__ void kernel(float *x,float *y,
float *z,float *vx, float *vy,
float *vz,float *ax, float *ay,
float *az,float *m){
int i,j;
float rx,ry,rz;
float dist2, dist6, invDist3,s;
i = blockDim.x*blockIdx.x+threadIdx.x;
for(j=0;j<N;j++){
rx=x[j]‐x[i];
ry=y[j]‐y[i];
rz=z[j]‐z[i];
//2天体間の距離を計算
dist2 = rx*rx + ry*ry + rz*rz
+ Soften;//軟化パラメータ
// m/r^3 の計算
dist6 = dist2*dist2*dist2;
invDist3 = 1.0/sqrt(dist6);
s = m[j]*invDist3;
//天体jによる加速度を加算
ax[i] = ax[i] + rx*s;
ay[i] = ay[i] + ry*s;
az[i] = az[i] + rz*s;
}
}
GPUプログラム(1スレッドが天体一つを計算)
2015/07/15GPGPU実践プログラミング39
kernel2.cu](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-39-320.jpg)
![//時間積分
__global__ void integrate(float *x, float *y, float *z,
float *vx, float *vy, float *vz, float *ax, float *ay, float *az){
int i=blockIdx.x*blockDim.x + threadIdx.x;
x[i] = x[i] + dt*vx[i];
y[i] = y[i] + dt*vy[i];
z[i] = z[i] + dt*vz[i];
vx[i] = vx[i] + dt*ax[i];
vy[i] = vy[i] + dt*ay[i];
vz[i] = vz[i] + dt*az[i];
}
GPUプログラム(1スレッドが天体一つを計算)
2015/07/15GPGPU実践プログラミング40
kernel2.cu](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-40-320.jpg)
![実行時間
2015/07/15GPGPU実践プログラミング
天体の個数 N = 4096
スレッド数 NT = 256
41
カーネル 実行時間 [ms]
1スレッド実行 33×103
1スレッド実行(ifの消去) 29×103
1スレッド1天体 7.63](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-41-320.jpg)
![#define NT 256
#define NB (N/NT)
//加速度の計算
__global__ void kernel(float *x,float *y,
float *z,float *vx, float *vy,
float *vz,float *ax, float *ay,
float *az,float *m){
int i,j;
float rx,ry,rz;
float dist2, dist6, invDist3,s;
//加速度のデータをレジスタに置く
float r_ax, r_ay, r_az;
i = blockDim.x*blockIdx.x+threadIdx.x;
r_ax = r_ay = r_az = 0.0f;
for(j=0;j<N;j++){
rx=x[j]‐x[i];
ry=y[j]‐y[i];
rz=z[j]‐z[i];
//2天体間の距離を計算
dist2 = rx*rx + ry*ry + rz*rz
+ Soften;//軟化パラメータ
// m/r^3 の計算
dist6 = dist2*dist2*dist2;
invDist3 = 1.0/sqrt(dist6);
s = m[j]*invDist3;
//天体jによる加速度を加算
r_ax = r_ax + rx*s;
r_ay = r_ay + ry*s;
r_az = r_az + rz*s;
}
ax[i] = r_ax;
ay[i] = r_ay;
az[i] = r_az;
}
GPUプログラム(レジスタ利用)
2015/07/15GPGPU実践プログラミング42
kernel3.cu](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-42-320.jpg)
![実行時間
2015/07/15GPGPU実践プログラミング
天体の個数 N = 4096
スレッド数 NT = 256
43
カーネル 実行時間 [ms]
1スレッド実行 33×103
1スレッド実行(ifの消去) 29×103
1スレッド1天体 7.63
レジスタ利用 4.49](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-43-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
・・・
共有メモリ
blockIdx.x=0 blockIdx.x=1
2015/07/15GPGPU実践プログラミング44
i= 0 1 2 3 4 5 6 7
threadIdx.x= 0 1 2 3 0 1 2 3
x[0] x[1] x[2]x[3] x[0] x[1] x[2]x[3]
j= 0 1 2 3 4 5 6 7
j=0+threadIdx.x
j=0+threadIdx.x
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-44-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
blockIdx.x=0 blockIdx.x=1
i=0~3の天体と
j=0~3の天体で
加速度を計算
i=4~7の天体と
j=0~3の天体で
加速度を計算
2015/07/15GPGPU実践プログラミング45
x[0] x[1] x[2]x[3] x[0] x[1] x[2]x[3]
j= 0 1 2 3 4 5 6 7
i= 0 1 2 3 4 5 6 7
・・・
threadIdx.x= 0 1 2 3 0 1 2 3
・・・
x[j]を保持する
共有メモリ](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-45-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
blockIdx.x=0 blockIdx.x=1
i=0~3の天体と
j=0~3の天体で
加速度を計算
i=4~7の天体と
j=0~3の天体で
加速度を計算
2015/07/15GPGPU実践プログラミング46
x[0] x[1] x[2]x[3] x[0] x[1] x[2]x[3]
j= 0 1 2 3 4 5 6 7
i= 0 1 2 3 4 5 6 7
x[j]を保持する
共有メモリ
・・・
threadIdx.x= 0 1 2 3 0 1 2 3
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-46-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
blockIdx.x=0 blockIdx.x=1
i=0~3の天体と
j=0~3の天体で
加速度を計算
i=4~7の天体と
j=0~3の天体で
加速度を計算
2015/07/15GPGPU実践プログラミング47
x[0] x[1] x[2]x[3] x[0] x[1] x[2]x[3]
j= 0 1 2 3 4 5 6 7
i= 0 1 2 3 4 5 6 7
x[j]を保持する
共有メモリ
・・・
threadIdx.x= 0 1 2 3 0 1 2 3
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-47-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
blockIdx.x=0 blockIdx.x=1
i=0~3の天体と
j=0~3の天体で
加速度を計算
i=4~7の天体と
j=0~3の天体で
加速度を計算
2015/07/15GPGPU実践プログラミング48
x[0] x[1] x[2]x[3] x[0] x[1] x[2]x[3]
j= 0 1 2 3 4 5 6 7
i= 0 1 2 3 4 5 6 7
x[j]を保持する
共有メモリ
・・・
threadIdx.x= 0 1 2 3 0 1 2 3
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-48-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
x[j]を保持する
共有メモリ
blockIdx.x=0 blockIdx.x=1
2015/07/15GPGPU実践プログラミング49
i= 0 1 2 3 4 5 6 7
x[4] x[5] x[6]x[7] x[4] x[5] x[6]x[7]
j= 0 1 2 3 4 5 6 7
j=4(=NT)+threadIdx.x
j=4(=NT)+threadIdx.x
・・・
threadIdx.x= 0 1 2 3 0 1 2 3
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-49-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
blockIdx.x=0 blockIdx.x=1
i=0~3の天体と
j=4~7の天体で
加速度を計算
i=4~7の天体と
j=4~7の天体で
加速度を計算
2015/07/15GPGPU実践プログラミング50
j= 0 1 2 3 4 5 6 7
i= 0 1 2 3 4 5 6 7
x[4] x[5] x[6]x[7] x[4] x[5] x[6]x[7] x[j]を保持する
共有メモリ
・・・
threadIdx.x= 0 1 2 3 0 1 2 3
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-50-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
blockIdx.x=0 blockIdx.x=1
i=0~3の天体と
j=4~7の天体で
加速度を計算
i=4~7の天体と
j=4~7の天体で
加速度を計算
2015/07/15GPGPU実践プログラミング51
j= 0 1 2 3 4 5 6 7
i= 0 1 2 3 4 5 6 7
x[4] x[5] x[6]x[7] x[4] x[5] x[6]x[7] x[j]を保持する
共有メモリ
・・・
threadIdx.x= 0 1 2 3 0 1 2 3
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-51-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
blockIdx.x=0 blockIdx.x=1
i=0~3の天体と
j=4~7の天体で
加速度を計算
i=4~7の天体と
j=4~7の天体で
加速度を計算
2015/07/15GPGPU実践プログラミング52
j= 0 1 2 3 4 5 6 7
i= 0 1 2 3 4 5 6 7
x[4] x[5] x[6]x[7] x[4] x[5] x[6]x[7] x[j]を保持する
共有メモリ
・・・
threadIdx.x= 0 1 2 3 0 1 2 3
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-52-320.jpg)
![GPUプログラム(共有メモリによる再利用)
x[i]
x[j]
blockIdx.x=0 blockIdx.x=1
i=0~3の天体と
j=4~7の天体で
加速度を計算
i=4~7の天体と
j=4~7の天体で
加速度を計算
2015/07/15GPGPU実践プログラミング53
j= 0 1 2 3 4 5 6 7
i= 0 1 2 3 4 5 6 7
x[4] x[5] x[6]x[7] x[4] x[5] x[6]x[7] x[j]を保持する
共有メモリ
・・・
threadIdx.x= 0 1 2 3 0 1 2 3
・・・](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-53-320.jpg)
![#define NT 256
#define NB (N/NT)
//加速度の計算
__global__ void kernel(…){
int i,j;
float rx,ry,rz;
float dist2, dist6, invDist3,s;
//加速度と座標のデータをレジスタに置く
float r_ax,r_ay,r_az,r_x,r_y,r_z;
__shared__ float
s_x[NT],s_y[NT],s_z[NT],s_m[NT];
i = blockDim.x*blockIdx.x+threadIdx.x;
r_ax = r_ay = r_az = 0.0f;
r_x = x[i];
r_y = y[i];
r_z = z[i];
for(j=0;j<N;j+=NT){
s_x[threadIdx.x] = x[j+threadIdx.x];
s_y[threadIdx.x] = y[j+threadIdx.x];
s_z[threadIdx.x] = z[j+threadIdx.x];
s_m[threadIdx.x] = m[j+threadIdx.x];
__syncthreads();
for(js = 0;js<NT;js++){
rx=s_x[js]‐r_x;
ry=s_y[js]‐r_y;
rz=s_z[js]‐r_z;
//2天体間の距離を計算
dist2 = rx*rx + ry*ry + rz*rz
+ Soften;//軟化パラメータ
// m/r^3 の計算
dist6 = dist2*dist2*dist2;
invDist3 = 1.0/sqrt(dist6);
s = s_m[js]*invDist3;
//天体jによる加速度を加算
r_ax = r_ax + rx*s;
r_ay = r_ay + ry*s;
r_az = r_az + rz*s;
}
}
ax[i] = r_ax;
ay[i] = r_ay;
az[i] = r_az;
}
GPUプログラム(共有メモリによる再利用)
2015/07/15GPGPU実践プログラミング54
kernel4.cu](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-54-320.jpg)
![実行時間
2015/07/15GPGPU実践プログラミング
天体の個数 N = 4096
スレッド数 NT = 256
カーネル 実行時間 [ms]
1スレッド実行 33×103
1スレッド実行(ifの消去) 29×103
1スレッド1天体 7.63
レジスタ利用 4.49
共有メモリ利用 4.27
55](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-55-320.jpg)
![#define NT 256
#define NB (N/NT)
//加速度の計算
__global__ void kernel(…){
int i,j;
float rx,ry,rz;
float dist2, dist6, invDist3,s;
//加速度と座標のデータをレジスタに置く
float r_ax,r_ay,r_az,r_x,r_y,r_z;
__shared__ float
s_x[NT],s_y[NT],s_z[NT],s_m[NT];
i = blockDim.x*blockIdx.x+threadIdx.x;
r_ax = r_ay = r_az = 0.0f;
r_x = x[i];
r_y = y[i];
r_z = z[i];
for(j=0;j<N;j+=NT){
s_x[threadIdx.x] = x[j+threadIdx.x];
s_y[threadIdx.x] = y[j+threadIdx.x];
s_z[threadIdx.x] = z[j+threadIdx.x];
s_m[threadIdx.x] = m[j+threadIdx.x];
__syncthreads();
#pragma unroll
for(js = 0;js<NT;js++){
rx=s_x[js]‐r_x;
ry=s_y[js]‐r_y;
rz=s_z[js]‐r_z;
//2天体間の距離を計算
dist2 = rx*rx + ry*ry + rz*rz
+ Soften;//軟化パラメータ
// m/r^3 の計算
dist6 = dist2*dist2*dist2;
invDist3 = 1.0/sqrt(dist6);
s = s_m[js]*invDist3;
//天体jによる加速度を加算
r_ax = r_ax + rx*s;
r_ay = r_ay + ry*s;
r_az = r_az + rz*s;
}
}
ax[i] = r_ax;
ay[i] = r_ay;
az[i] = r_az;
}
GPUプログラム(ループアンロール)
2015/07/15GPGPU実践プログラミング56
kernel5.cu](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-56-320.jpg)
![実行時間
2015/07/15GPGPU実践プログラミング
天体の個数 N = 4096
スレッド数 NT = 256
カーネル 実行時間 [ms]
1スレッド実行 33×103
1スレッド実行(ifの消去) 29×103
1スレッド1天体 7.63
レジスタ利用 4.49
共有メモリ利用 4.27
共有メモリ利用+ループアンロール 3.50
57](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-57-320.jpg)
![実行時間
2015/07/15GPGPU実践プログラミング
天体の個数 N = 65536
スレッド数 NT = 256
共有メモリを単純に利用しただけでは遅くなる
共有メモリを利用することは高速化に有効
「共有メモリを利用するために追加される処理」が遅くなる要因
58
カーネル 実行時間 [ms]
1スレッド1天体 916
レジスタ利用 638
共有メモリ利用 646
共有メモリ利用+ループアンロール 499](https://image.slidesharecdn.com/gpgpuprogramming14-160307053120/85/2015-GPGPU-14-N-58-320.jpg)






















![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)












































