Pythonを用いてExcelの累乗近似を再現する方法を調査した結果をまとめている.なぜ,Excelの累乗近似を再現するのか,どのようにそれを使うのかも説明している. 2019年3月23日オープンCAE勉強会@岐阜で発表
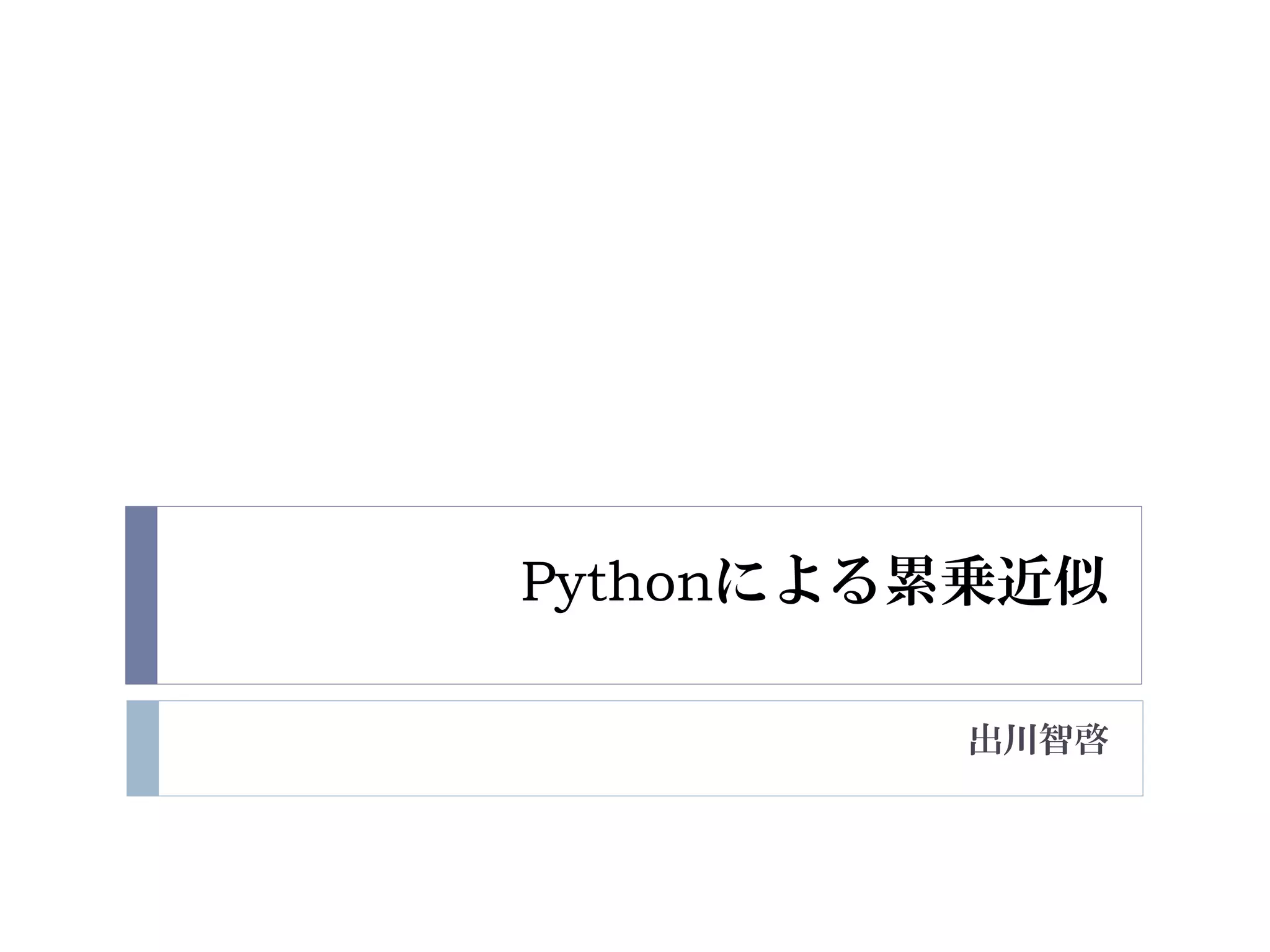

![Pythonによる非線形関数の近似
2019/03/23オープンCAE第68回勉強会@岐阜4
def nonlinear_fit(x, a, b, c):
return b*x**a + c
%matplotlib inline
import numpy as np
from scipy.optimize import curve_fit
from matplotlib import pyplot as plt
#井口氏の値
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
y = np.array([6, 12, 27, 50, 75, 108, 149, 198, 249, 303])
p_opt,cov = curve_fit(nonlinear_fit,x,y)
p_opt
array([ 2.01749389, 2.92169046, 1.17462894])](https://image.slidesharecdn.com/powerapproxisingpython-190505034820/85/Python-4-320.jpg)
![Pythonによる非線形関数の近似
2019/03/23オープンCAE第68回勉強会@岐阜5
fig,ax = plt.subplots()
ax.plot(x,y,lw=0,marker='o',clip_on=False)
ax.plot(x,y_fit(x,p_opt[0],p_opt[1],p_opt[2]),lw=1)
plt.show()
y_fit = np.vectorize(nonlinear_fit)](https://image.slidesharecdn.com/powerapproxisingpython-190505034820/85/Python-5-320.jpg)

![Pythonによる累乗近似の再現
2019/03/23オープンCAE第68回勉強会@岐阜7
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
y = np.array([6, 12, 27, 50, 75, 108, 149, 198, 249, 303])
p_opt2,cov = curve_fit(loglog_fit,x,y)
p_opt2
array([ 1.79238713, 4.45246989])
def loglog_fit(x, a, b,):
return a*x + np.log(b)](https://image.slidesharecdn.com/powerapproxisingpython-190505034820/85/Python-7-320.jpg)
![Pythonによる非線形関数の近似
2019/03/23オープンCAE第68回勉強会@岐阜8
fig,ax = plt.subplots()
ax.plot(x,y,lw=0,marker='o',clip_on=False)
ax.plot(x,p_opt2[1]*x**p_opt2[0],lw=1)
plt.show()](https://image.slidesharecdn.com/powerapproxisingpython-190505034820/85/Python-8-320.jpg)
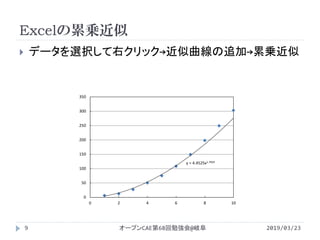

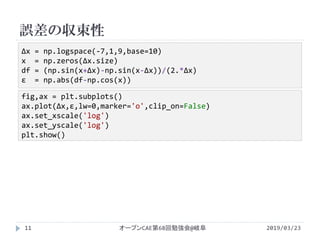
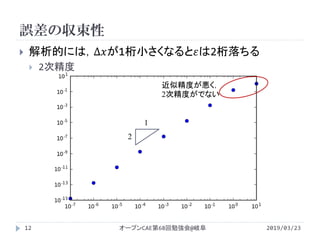
![誤差の収束次数の調査
2019/03/23オープンCAE第68回勉強会@岐阜13
p_opt,cov = curve_fit(nonlinear_fit,Δx,ɛ)
ɛ_fit = np.vectorize(nonlinear_fit)
p_opt
def nonlinear_fit(x,a,b): #非線形回帰
return b*x**a
lower_bounds = (-np.inf,0.) #logに負の値が入らないように
upper_bounds = (np.inf,np.inf) #下限と上限を設定
p_opt2,cov = curve_fit(loglog_fit,np.log(Δx),np.log(ɛ),¥
bounds=(lower_bounds,upper_bounds))
ɛ_loglogfit = p_opt2[1]*Δx**p_opt2[0]
p_opt2
def loglog_fit(x,a,b): #対数を取って線形回帰
return a*x + np.log(b)
array([ 0.84009246, 0.15243934])
array([ 1.91900884, 0.06969248])](https://image.slidesharecdn.com/powerapproxisingpython-190505034820/85/Python-13-320.jpg)
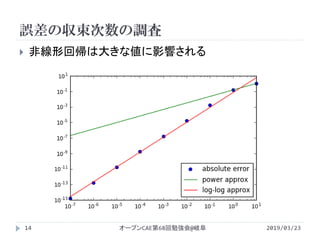
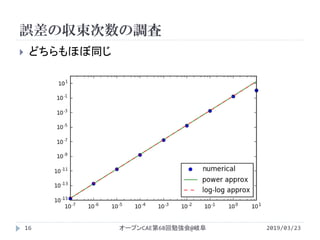
![誤差の収束次数の調査
2019/03/23オープンCAE第68回勉強会@岐阜15
近似するデータの範囲を選べば同じ結果が出てくる
明らかに傾きがおかしい結果を使わない
p_opt,cov = curve_fit(nonlinear_fit,Δx[:-2],ɛ[:-2])
ɛ_fit = np.vectorize(nonlinear_fit)
p_opt2,cov = curve_fit(loglog_fit,np.log(Δx[:-2]),¥
np.log(ɛ[:-2]),¥
bounds=((-np.inf,0.),(np.inf,np.inf)))
ɛ_loglogfit = p_opt2[1]*Δx**p_opt2[0]](https://image.slidesharecdn.com/powerapproxisingpython-190505034820/85/Python-15-320.jpg)





![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Live-Streaming Fraud Detection: A Heterogeneous Graph Neural Network A...](https://cdn.slidesharecdn.com/ss_thumbnails/live-streamingfrauddetectionaheterogeneousgraphneuralnetworkapproach-220325040823-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)

































