長岡技術科学大学
2015年度GPGPU実践プログラミング(全15回,学部4年対象講義)
第9回行列計算(行列-行列積)
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
・第2回 GPUのアーキテクチャとプログラム構造
http://www.slideshare.net/ssuserf87701/2015gpgpu2-59179215
・第3回 GPGPUプログラミング環境
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59179255
・第3回補足 GROUSEの利用方法
http://www.slideshare.net/ssuserf87701/2015gpgpu3-59183677
・第4回 GPUでの並列プログラミング(ベクトル和,移動平均,差分法)
http://www.slideshare.net/ssuserf87701/2015gpgpu4-59179449
・第5回 GPUのメモリ階層
http://www.slideshare.net/ssuserf87701/2015gpgpu5-59179536
・第6回 パフォーマンス解析ツール
http://www.slideshare.net/ssuserf87701/2015gpgpu6-59179577
・第7回 総和計算
http://www.slideshare.net/ssuserf87701/2015gpgpu7-59179639
・第8回 総和計算(高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu8-59179686
・第9回 行列計算(行列-行列積)
http://www.slideshare.net/ssuserf87701/2015gpgpu9-59179722
・第10回 行列計算(行列-行列積の高度な最適化)
http://www.slideshare.net/ssuserf87701/2015gpgpu10-59179759
・第11回 画像処理
http://www.slideshare.net/ssuserf87701/2015gpgpu11-59179789
・第12回 偏微分方程式の差分計算
http://www.slideshare.net/ssuserf87701/2015gpgpu12-59179972
・第13回 多粒子の運動
http://www.slideshare.net/ssuserf87701/2015gpgpu13-59180018
・第14回 N体問題
http://www.slideshare.net/ssuserf87701/2015gpgpu14-59180054
・第15回 GPU最適化ライブラリ
http://www.slideshare.net/ssuserf87701/2015gpgpu15-59180086
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません)
PGI Fortran 11.3




![i
k
i
j
k
j
[A] [C]
[B]
配列アクセスのイメージ
2015/06/10GPGPU実践プログラミング5
for(i=0;i<SIZE;i++){
for(j=0;j<SIZE;j++){
C[i][j] = 0;
for(k=0;k<SIZE;k++){
C[i][j] += A[i][k]*B[k][j];
}
}
}](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-5-320.jpg)
![1次元配列での行列の表現
2015/06/10GPGPU実践プログラミング6
1次元配列C[]を宣言し,整数型変数i,jを使って任意
の要素にアクセス
行方向がi(第1次元),列方向がj(第2次元)
画像処理など一般的な用途とは向きが異なる
水平(x,行)方向がi,垂直(y,列)方向がj
2次元配列の場合
1次元配列の場合
C[1][2] = 9
C[_______] = 9
SIZE=6
1*6 + 2
C[i][j] C[i*SIZE+j]
メモリアドレスが連続
i
j
1
7
2
8
3
9
4
10
5 6](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-6-320.jpg)
![#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#define SIZE 4096
#define Bytes (SIZE*SIZE*sizeof(float))
#define MILLISEC_PER_SEC 1000
#define FLOPS_TO_GFLOPS 1e‐9
void matmul(float *, float *, float *);
int main(void){
float *hA, *hB, *hC;
int i,j,k;
clock_t start_c, stop_c;
float time_s,time_ms;
float gflops;
hA = (float *)malloc(Bytes);
hB = (float *)malloc(Bytes);
hC = (float *)malloc(Bytes);
for(i=0;i<SIZE;i++){
for(k=0;k<SIZE;k++){
hA[i*SIZE + k]=(float)(i+1)*0.1f;
}
}
for(k=0;k<SIZE;k++){
for(j=0;j<SIZE;j++){
hB[k*SIZE + j]=(float)(j+1)*0.1f;
}
}
for(i=0;i<SIZE;i++){
for(j=0;j<SIZE;j++){
hC[i*SIZE + j] = 0.0f;
}
}
CPUプログラム
2015/06/10GPGPU実践プログラミング7
matmul.c](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-7-320.jpg)
![start_c = clock();
matmul(hA,hB,hC);
stop_c = clock();
time_s = (stop_c‐start_c)
/(float)CLOCKS_PER_SEC;
time_ms = time_s*MILLISEC_PER_SEC;
gflops = 2.0*SIZE*SIZE*SIZE/time_s
* FLOPS_TO_GFLOPS;
printf("%f ms¥n",time_ms);
printf("%f GFLOPS¥n",gflops);
return 0;
}
//行列-行列積
void matmul(float *A,float *B,float *C){
int i,j,k;
for(i=0; i<SIZE; i++){
for(j=0; j<SIZE; j++){
for(k=0; k<SIZE; k++){
C[i*SIZE+j] +=
A[i*SIZE+k]*B[k*SIZE+j];
}
}
}
}
CPUプログラム(続き)
2015/06/10GPGPU実践プログラミング8
matmul.c](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-8-320.jpg)
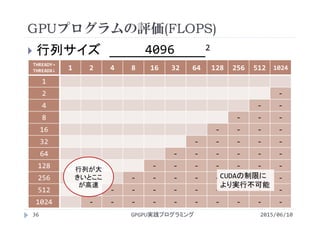
![行列-行列積の計算量
2015/06/10GPGPU実践プログラミング9
計算能力FLOPS[flop/s]
for(i=0;i<SIZE;i++){
for(j=0;j<SIZE;j++){
C[i][j] = 0;
for(k=0;k<SIZE;k++){
C[i][j] += A[i][k]*B[k][j];
}
}
}
FLOPS=SIZE×SIZE×SIZE×2/実行時間](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-9-320.jpg)

![for(i=0;i<SIZE;i++){
for(j=0;j<SIZE;j++){
C[i*SIZE j] = 0;
for(k=0;k<SIZE;k++){
C[i*SIZE+j]
+= A[i*SIZE+k]*B[k*SIZE+j];
}
}
}
GPUプログラム(1スレッド版)
i
k
i
j
k
j
[A] [C]
[B]
2015/06/10GPGPU実践プログラミング11](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-11-320.jpg)
![2次元的な配列アクセスの優先方向
2015/06/10GPGPU実践プログラミング12
2次元配列の場合
in[][],out[][]
Ny
Nx
i
j
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i][j]=in[i][j];
for(j=0;j<Ny;j++)
for(i=0;i<Nx;i++)
out[i][j]=in[i][j];](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-12-320.jpg)
![2次元的な配列アクセスの優先方向
2015/06/10GPGPU実践プログラミング13
2次元配列の場合
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i][j]=in[i][j];
in[][],out[][]
for(j=0;j<Ny;j++)
for(i=0;i<Nx;i++)
out[i][j]=in[i][j];
Ny
Nx
i
j](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-13-320.jpg)
![2次元的な配列アクセスの優先方向
2015/06/10GPGPU実践プログラミング14
2次元配列の1次元配列的表現
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i][j]=in[i][j];
in[],out[]
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i*Ny+j]=
in[i*Ny+j];
Ny
Nx
i
j](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-14-320.jpg)
![2次元的な配列アクセスの優先方向
2015/06/10GPGPU実践プログラミング15
CUDAで2次元的に並列化してアクセスする場合
i = blockIdx.x*blockDim.x
+ threadIdx.x;
j = blockIdx.y*blockDim.y
+ threadIdx.y;
out[j*Nx+i]=in[j*Nx+i];
in[],out[]
for(i=0;i<Nx;i++)
for(j=0;j<Ny;j++)
out[i*Ny+j]=
in[i*Ny+j];
threadIdx.y
threadIdx.x
Ny
Nx
i
j](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-15-320.jpg)
![for(j=0;j<SIZE;j++){ //ループを入れ替え
for(i=0;i<SIZE;i++){ //
C[i+SIZE*j] = 0;
for(k=0;k<SIZE;k++){
C[i+SIZE*j]
+= A[i+SIZE*k]*B[k+SIZE*j];
}
}
}
GPUプログラム(1スレッド版)
i
k
i
j
k
j
[A] [C]
[B]
2015/06/10GPGPU実践プログラミング16](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-16-320.jpg)
![#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#define SIZE 4096
#define Bytes (SIZE*SIZE*sizeof(float))
#define MILLISEC_PER_SEC 1000
#define FLOPS_TO_GFLOPS 1e‐9
void matmul(float *, float *, float *);
int main(void){
float *hA, *hB, *hC;
int i,j,k;
clock_t start_c, stop_c;
float time_s,time_ms;
float gflops;
hA = (float *)malloc(Bytes);
hB = (float *)malloc(Bytes);
hC = (float *)malloc(Bytes);
for(k=0;k<SIZE;k++){ //ループを入れ替え
for(i=0;i<SIZE;i++){//
hA[i+SIZE*k]=(float)(k+1)*0.1f;
}
}
for(j=0;j<SIZE;j++){ //ループを入れ替え
for(k=0;k<SIZE;k++){//
hB[k+SIZE*j]=(float)(k+1)*0.1f;
}
}
for(j=0;j<SIZE;j++){ //ループを入れ替え
for(i=0;i<SIZE;i++){//
hC[i+SIZE*j] = 0.0f;
}
}
CPUプログラム(GPU移植用修正版)
2015/06/10GPGPU実践プログラミング17
matmul2.c](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-17-320.jpg)
![start_c = clock();
matmul(hA,hB,hC);
stop_c = clock();
time_s = (stop_c‐start_c)
/(float)CLOCKS_PER_SEC;
time_ms = time_s*MILLISEC_PER_SEC;
gflops = 2.0*SIZE*SIZE*SIZE/time_s
* FLOPS_TO_GFLOPS;
printf("%f ms¥n",time_ms);
printf("%f GFLOPS¥n",gflops);
return 0;
}
//行列-行列積
void matmul(float *A,float *B,float *C){
int i,j,k;
for(j=0;j<SIZE;j++){ //ループを入れ替え
for(i=0;i<SIZE;i++){//
for(k=0; k<SIZE; k++){
C[i+SIZE*j] +=
A[i+SIZE*k]*B[k+SIZE*j];
}
}
}
}
CPUプログラム(GPU移植用修正版)
2015/06/10GPGPU実践プログラミング18
matmul2.c](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-18-320.jpg)



![//1スレッドが全ての要素を計算
#define THREADX 1
#define THREADY 1
#define BLOCKX 1
#define BLOCKY 1
__global__ void matmulGPU(float *A, float *B, float *C){
int i,j,k;
for(j=0; j<SIZE; j++){ //ループを入れ替え
for(i=0; i<SIZE; i++){ //
for(k=0; k<SIZE; k++){
//C[i*SIZE+j] += A[i*SIZE+k]*B[k*SIZE+j];
C[i+SIZE*j] += A[i+SIZE*k]*B[k+SIZE*j];
}
}
}
}
GPUプログラム(行列-行列積カーネル)
2015/06/10GPGPU実践プログラミング22
mm1.cu](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-22-320.jpg)




![1スレッドが1要素の計算を担当
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
i
k
i
j
k
j
[A] [C]
[B]
THREADX
THREADY
2015/06/10GPGPU実践プログラミング27
for(i=0;i<SIZE;i++){
for(j=0;j<SIZE;j++){
for(k=0;k<SIZE;k++){
C[i+SIZE*j]
+= A[i+SIZE*k]*B[k+SIZE*j];
}
}
}](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-27-320.jpg)
![1スレッドが1要素の計算を担当
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
i
k
i
j
k
j
[A] [C]
[B]
THREADX
THREADY
2015/06/10GPGPU実践プログラミング28
for(i=0;i<SIZE;i++){
for(j=0;j<SIZE;j++){
for(k=0;k<SIZE;k++){
C[i+SIZE*j]
+= A[i+SIZE*k]*B[k+SIZE*j];
}
}
}](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-28-320.jpg)
![1スレッドが1要素の計算を担当
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
i
k
i
j
k
j
[A] [C]
[B]
THREADX
THREADY
2015/06/10GPGPU実践プログラミング29
for(i=0;i<SIZE;i++){
for(j=0;j<SIZE;j++){
for(k=0;k<SIZE;k++){
C[i+SIZE*j]
+= A[i+SIZE*k]*B[k+SIZE*j];
}
}
}](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-29-320.jpg)
![1スレッドが1要素の計算を担当
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
i
k
i
j
k
j
[A] [C]
[B]
THREADX
THREADY
2015/06/10GPGPU実践プログラミング30
for(i=0;i<SIZE;i++){
for(j=0;j<SIZE;j++){
for(k=0;k<SIZE;k++){
C[i+SIZE*j]
+= A[i+SIZE*k]*B[k+SIZE*j];
}
}
}](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-30-320.jpg)
![//1スレッド(i,j)がCijの計算を担当
#define THREADX 16
#define THREADY 16
#define BLOCKX (SIZE/THREADX)
#define BLOCKY (SIZE/THREADY)
__global__ void matmulGPU(float *A, float *B, float *C){
int i,j,k;
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
C[i*SIZE + j]=0.0f;
for(k=0; k<SIZE; k++){
C[i+SIZE*j] += A[i+SIZE*k] * B[k+SIZE*j];
}
}
GPUプログラム(行列-行列積カーネル)
2015/06/10GPGPU実践プログラミング31
mm2.cu](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-31-320.jpg)
![//1スレッド(i,j)がCijの計算を担当
#define THREADX 16
#define THREADY 16
#define BLOCKX (SIZE/THREADX)
#define BLOCKY (SIZE/THREADY)
__global__ void matmulGPU(float *A, float *B, float *C){
int i,j,k;
float sum = 0.0f; ・・・レジスタを使う
i = blockIdx.x*blockDim.x + threadIdx.x;
j = blockIdx.y*blockDim.y + threadIdx.y;
for(k=0; k<SIZE; k++){
sum += A[i+SIZE*k] * B[k+SIZE*j]; ・・・レジスタを使うことでグローバル
} メモリへのアクセス回数を減らす
C[i+SIZE*j] = sum; ・・・レジスタからグローバルメモリへ
} 代入
GPUプログラム(行列-行列積カーネル)
2015/06/10GPGPU実践プログラミング32
mm2.cu](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-32-320.jpg)

![GPUプログラムのパラメータチューニング
2015/06/10GPGPU実践プログラミング34
1スレッドが1点の計算を担当
i行j列の計算を担当
スレッドの割り当て方で性能が変化
どのような割り当て方がいいのか?
それはなぜか?
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロックTHREADX
THREADY](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-34-320.jpg)
![GPUプログラムのパラメータチューニング
2015/06/10GPGPU実践プログラミング35
1スレッドが1点の計算を担当
i行j列の計算を担当
スレッドの割り当て方で性能が変化
どのような割り当て方がいいのか?
それはなぜか?
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロックTHREADX
THREADY](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-35-320.jpg)


![共有メモリによるデータ再利用
2015/06/10GPGPU実践プログラミング39
各スレッドは異なる[A]の行(i)にアクセス
[B]の列(j)は同じ
列の読み込みはSIZE回(i=0,1,・・・,SIZE‐1)
全てのスレッドが同じ列をSIZE回読込
[B]の再利用で高速化できるのでは?
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロックTHREADX
THREADY](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-39-320.jpg)
![i
k
i
j
k
j
[A] [C]
[B]
共有メモリによるデータ再利用
2015/06/10GPGPU実践プログラミング40
各スレッドは異なる[A]の行(i)にアクセス
[B]の列(j)は同じ
Bk,jだけでなくスレッド数分(Bk,j, Bk+1,j,・・・)
読み込んでどこかに保持
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロックTHREADX
THREADY](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-40-320.jpg)
![共有メモリによるデータ再利用
2015/06/10GPGPU実践プログラミング41
各スレッドは異なる[A]の行(i)にアクセス
[B]の列(j)は同じ
Bk,jだけでなくスレッド数分(Bik,j, Bk+1,j,・・・)
読み込んでどこかに保持
保持したデータから読み出し
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロックTHREADX
THREADY](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-41-320.jpg)
![//1スレッド(i,j)がCijの計算を担当
//共有メモリによるデータ再利用版
#define THREADX 256
#define THREADY 1
#define BLOCKX (SIZE/THREADX)
#define BLOCKY (SIZE/THREADY)
__global__ void matmulGPU
(float *A, float *B, float *C){
int i,j,k;
float sum=0.0f;
int tx;
__shared__ float sB[THREADX];
i = blockIdx.x*blockDim.x+threadIdx.x;
j = blockIdx.y*blockDim.y+threadIdx.y;
tx= threadIdx.x;
for(k=0; k<SIZE; k+=THREADX){
sB[tx] = B[(k+tx)+SIZE*j];
__syncthreads();
for(int w = 0;w<THREADX;w++){
sum += A[i+SIZE*(k+w)]*sB[w];
}
__syncthreads();
}
C[i+SIZE*j] = sum;
}
GPUプログラム(行列-行列積カーネル)
2015/06/10GPGPU実践プログラミング43
mm3.cu](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-43-320.jpg)
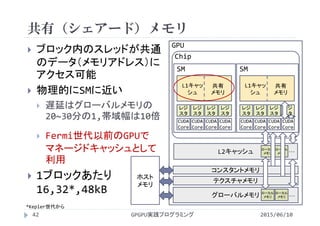
![共有メモリの宣言
2015/06/10GPGPU実践プログラミング44
1ブロック内でデータを共有
スレッド(0,0)がBk,j,スレッド(1,0)が
Bk+1,j,・・・にアクセス
必要な要素数は行方向のスレッド分
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロックTHREADX
THREADY
THREADX
THREADX
THREADX
__shared__ float sB[THREADX];](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-44-320.jpg)
![共有メモリへ代入
2015/06/10GPGPU実践プログラミング45
i
k
i
j
k
j
[A] [C]
[B]
for(k=0; k<SIZE; k+=THREADX){
sB[tx] = B[(k+tx)+SIZE*j]; //k=0
__syncthreads(); //同期を取る
for(int w = 0;w<THREADX;w++){
sum += A[i+SIZE*(k+w)]*sB[w];
}
__syncthreads();
}
C[i+SIZE*j] = sum;
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
共有メモリ
tx=
0
1
2
THREADX](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-45-320.jpg)
![for(k=0; k<SIZE; k+=THREADX){
sB[tx] = B[(k+tx)+SIZE*j]; //k=0
__syncthreads();
for(int w = 0;w<THREADX;w++){
sum += A[i+SIZE*(k+w)]*sB[w];
}
__syncthreads();
}
C[i+SIZE*j] = sum;
共有メモリから読込
2015/06/10GPGPU実践プログラミング46
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
共有メモリ
w
w
00+0
THREADX](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-46-320.jpg)
![共有メモリから読込
2015/06/10GPGPU実践プログラミング47
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
共有メモリ
for(k=0; k<SIZE; k+=THREADX){
sB[tx] = B[(k+tx)+SIZE*j]; //k=0
__syncthreads();
for(int w = 0;w<THREADX;w++){
sum += A[i+SIZE*(k+w)]*sB[w];
}
__syncthreads();
}
C[i+SIZE*j] = sum; w
w
THREADX
10+1](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-47-320.jpg)
![共有メモリから読込
2015/06/10GPGPU実践プログラミング48
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
共有メモリ
for(k=0; k<SIZE; k+=THREADX){
sB[tx] = B[(k+tx)+SIZE*j]; //k=0
__syncthreads();
for(int w = 0;w<THREADX;w++){
sum += A[i+SIZE*(k+w)]*sB[w];
}
__syncthreads();//同期を取る
}
C[i+SIZE*j] = sum; w
w
THREADX
20+2](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-48-320.jpg)
![共有メモリへ代入
2015/06/10GPGPU実践プログラミング49
i
k
i
j
k
j
[A] [C]
[B]
for(k=0; k<SIZE; k+=THREADX){
sB[tx] = B[(k+tx)+SIZE*j]; //k=3
__syncthreads(); //同期を取る
for(int w = 0;w<THREADX;w++){
sum += A[i+SIZE*(k+w)]*sB[w];
}
__syncthreads();
}
C[i+SIZE*j] = sum;
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
共有メモリ
tx=
0
1
2
THREADX](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-49-320.jpg)
![共有メモリから読込
2015/06/10GPGPU実践プログラミング50
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
共有メモリ
for(k=0; k<SIZE; k+=THREADX){
sB[tx] = B[(k+tx)+SIZE*j]; //k=3
__syncthreads();
for(int w = 0;w<THREADX;w++){
sum += A[i+SIZE*(k+w)]*sB[w];
}
__syncthreads();
}
C[i+SIZE*j] = sum;
w
w
THREADX
03+0](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-50-320.jpg)
![共有メモリから読込
2015/06/10GPGPU実践プログラミング51
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
共有メモリ
for(k=0; k<SIZE; k+=THREADX){
sB[tx] = B[(k+tx)+SIZE*j]; //k=3
__syncthreads();
for(int w = 0;w<THREADX;w++){
sum += A[i+SIZE*(k+w)]*sB[w];
}
__syncthreads();
}
C[i+SIZE*j] = sum; w
w
THREADX
13+1](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-51-320.jpg)
![共有メモリから読込
2015/06/10GPGPU実践プログラミング52
i
k
i
j
k
j
[A] [C]
[B]
1スレッドの計算担当
1スレッドのメモリ
アクセス範囲
1ブロック
共有メモリ
for(k=0; k<SIZE; k+=THREADX){
sB[tx] = B[(k+tx)+SIZE*j]; //k=3
__syncthreads();
for(int w = 0;w<THREADX;w++){
sum += A[i+SIZE*(k+w)]*sB[w];
}
__syncthreads();//同期を取る
}
C[i+SIZE*j] = sum; w
w
THREADX
23+2](https://image.slidesharecdn.com/gpgpuprogramming09-160307051728/85/2015-GPGPU-9-52-320.jpg)






![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[関東GPGPU勉強会#2] ライブラリを使って大規模疎行列線形方程式を解いてみよう](https://cdn.slidesharecdn.com/ss_thumbnails/kantogpgpu2-130608041648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



























