CUDA Fortranによる格子ボルツマン法の高速化 ( http://www.slideshare.net/ssuserf87701/gpgpu-seminar-accelerataion-of-lattice-boltzmann-method-using-cuda-fortran )
補足資料 GPGPUとCUDA Fortran
長岡技術科学大学2015年度GPGPU講習会(2016年1月13日実施)
GPU未経験の留学生に向けて作成したCUDA Fortranについての資料です。
講義には長岡技術科学大学のGPGPUシステム(GROUSE)を利用しています。
開発環境
CPU Intel Xeon X5670 × 32
GPU NVIDIA Tesla M2050(Fermi世代) × 64
CUDA 4.0(諸般の事情によりバージョンアップされていません。)
PGI Fortran 11.3 (with CUDA 3.2)
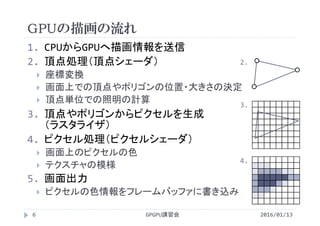
CUDA Fortran Advanced Topic
PGI CUDA FortranとGPU最適化ライブラリの一連携法
http://www.slideshare.net/ssuserf87701/pgi-cuda-fortrangpu
GPGPU講習会
・PyCUDA
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-pycuda
・CUDA Fortranによる格子ボルツマン法の高速化
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-accelerataion-of-lattice-boltzmann-method-using-cuda-fortran
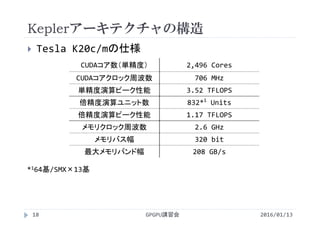
・補足資料 GPGPUとCUDA Fortran
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-gpgpu-and-cuda-fortran
・GPU最適化ライブラリの利用(その1,cuBLAS)
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-gpu-accelerated-libraries-1-of-3-cublas
・GPU最適化ライブラリの利用(その2,cuSPARSE)
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-gpu-accelerated-libraries-2-of-3-cusparse
・GPU最適化ライブラリの利用(その3,Thrust)
http://www.slideshare.net/ssuserf87701/gpgpu-seminar-gpu-accelerated-libraries-3-of-3-thrust
2015年度GPGPU実践基礎工学
・第1回 学際的分野における先端シミュレーション技術の歴史
http://www.slideshare.net/ssuserf87701/2015gpgpu1
2015年度GPGPU実践プログラミング
・第1回 GPGPUの歴史と応用例
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59179080
2015年度先端GPGPUシミュレーション工学特論
・第1回 先端シミュレーションおよび産業界におけるGPUの役割
http://www.slideshare.net/ssuserf87701/2015gpgpu1-59180313














![TOP500 List(2015, Nov.)
スーパーコンピュータの性能の世界ランキング
GPUを搭載したコンピュータは2基だけ
GPGPU講習会24
http://www.top500.org/より引用
2016/01/13
計算機名称(設置国) アクセラレータ
実効性能[PFlop/s]
/ピーク性能[PFlop/s]
消費電力[MW]
1 Tianhe‐2 (China) Intel Xeon Phi 33.9/54.9 17.8
2 Titan (U.S.A.) NVIDIA K20x 17.6/27.1 8.20
3 Sequoia (U.S.A.) − 17.2/20.1 7.90
4 K computer (Japan) − 10.5/11.3 12.7
5 Mira (U.S.A.) − 8.59/10.1 3.95
6 Trinity (U.S.A.) − 8.10/11.1
7 Piz Daint (Switzerland) NVIDIA K20x 6.27/7.79 2.33
8 Hazel Hen (Germany) ‐ 5.64/7.40
9 Shaheen II(Saudi Arabia) ‐ 5.54/7.24 2.83
10 Stampede (U.S.A.) Intel Xeon Phi 5.17/8.52 4.51](https://image.slidesharecdn.com/gpuseminarcudafortran-160307144626/85/GPGPU-Seminar-GPGPU-and-CUDA-Fortran-24-320.jpg)


![Green500(2015, Nov.)
TOP3の計算機がそれぞれ異なるアクセラレータを搭載
インターネットのサービス提供に利用されている(と思わ
れる)計算機が大量にランクイン
GPGPU講習会30
http://www.green500.org/より引用
2016/01/13
計算機名称 アクセラレータ GFLOPS/W 消費電力[kW]
1 Shoubu PEZY‐SC 7.03 50.32
2 TSUBAME‐KFC NVIDIA Tesla K80 5.33 51.13
3 ASUS ESC4000 AMD FirePro S9150 5.27 57.15
4 Sugon Cluster NVIDIA Tesla K80 4.78 65.00
5 Xstream NVIDIA Tesla K80 4.11 190.0
6 Inspur TS10000 NVIDIA Tesla K40 3.86 58.00
7 Inspur TS10000 NVIDIA Tesla K40 3.78 110.0
8 Inspur TS10000 NVIDIA Tesla K40 3.78 110.0
9 Inspur TS10000 NVIDIA Tesla K40 3.78 110.0
10 Inspur TS10000 NVIDIA Tesla K40 3.78 110.0](https://image.slidesharecdn.com/gpuseminarcudafortran-160307144626/85/GPGPU-Seminar-GPGPU-and-CUDA-Fortran-30-320.jpg)




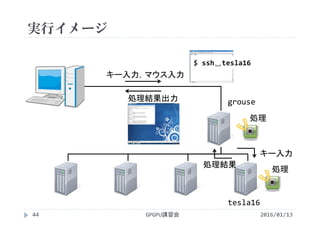
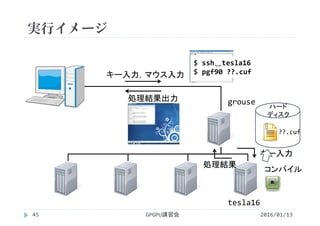
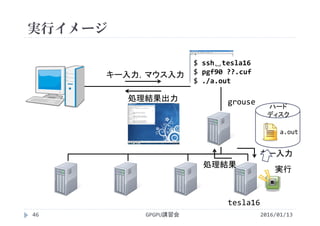
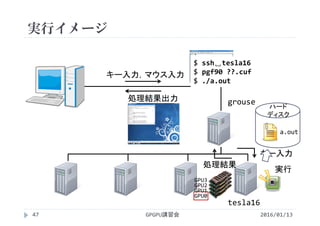












































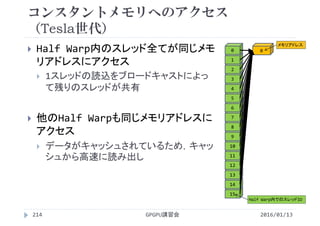
![実行結果
GPGPU講習会108
プロファイルの一連の流れ
method カーネルや関数(API)の名称
gputime GPU上で処理に要した時間(s単位)
cputime CPUで処理(=カーネル起動)に要した時間
実際の実行時間=cputime+gputime
occupancy GPUがどれだけ効率よく利用されているか
‐bash‐3.2$ pgf90 vectoradd_1thread.cuf プログラムをコンパイル
‐bash‐3.2$ export CUDA_PROFILE=1 環境変数CUDA_PROFILEを1にしてプロファイラを有効化
‐bash‐3.2$ ./a.out プログラムを実行(cuda_profile_0.logというファイルが作られる)
‐bash‐3.2$ cat cuda_profile_0.log cuda_profile_0.logの内容を画面に表示
# CUDA_PROFILE_LOG_VERSION 2.0
# CUDA_DEVICE 0 Tesla M2050
# TIMESTAMPFACTOR fffff5f0d8759ef8
method,gputime,cputime,occupancy
method=[ __pgi_dev_cumemset_4f ] gputime=[ 36.320 ] cputime=[ 16.000 ] occupancy=[ 1.000 ]
method=[ __pgi_dev_cumemset_4f ] gputime=[ 35.200 ] cputime=[ 8.000 ] occupancy=[ 1.000 ]
method=[ __pgi_dev_cumemset_4f ] gputime=[ 35.104 ] cputime=[ 7.000 ] occupancy=[ 1.000 ]
method=[ add ] gputime=[ 206041.375 ] cputime=[ 6.000 ] occupancy=[ 0.021 ]
2016/01/13](https://image.slidesharecdn.com/gpuseminarcudafortran-160307144626/85/GPGPU-Seminar-GPGPU-and-CUDA-Fortran-108-320.jpg)







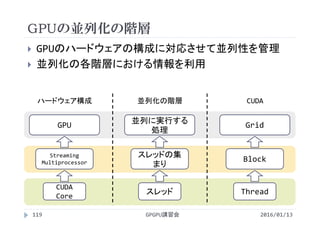



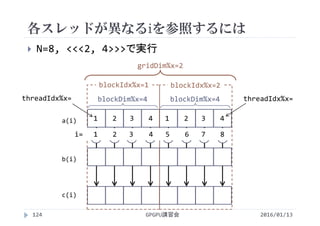
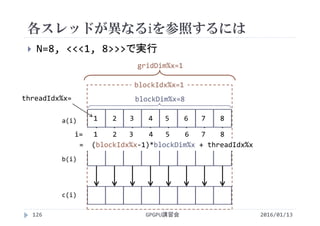
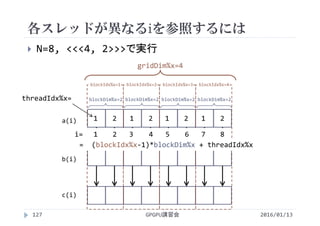
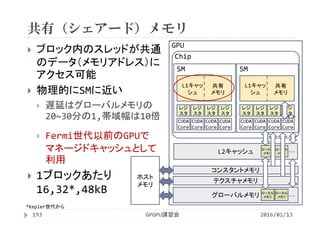
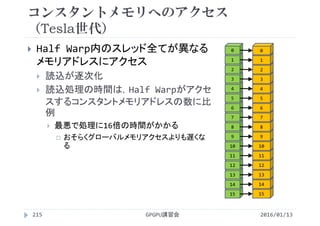
![各スレッドが異なるiを参照するには
CUDAでは並列化に階層がある
全体の領域(グリッド)をブロックに分割
ブロックの中をスレッドに分割
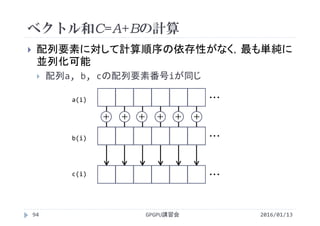
<<<2, 4>>>
ブロックの数 1ブロックあたりの
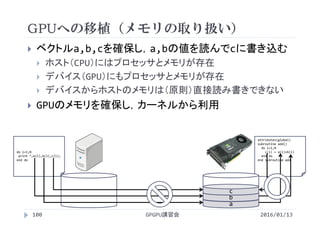
スレッドの数
ブロックの数×1ブロックあたりのスレッドの数=総スレッド数
2 × 4 = 8
GPGPU講習会123
[block] [thread/block] [thread]
2016/01/13](https://image.slidesharecdn.com/gpuseminarcudafortran-160307144626/85/GPGPU-Seminar-GPGPU-and-CUDA-Fortran-123-320.jpg)
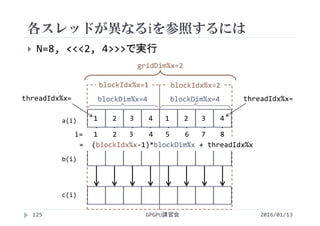


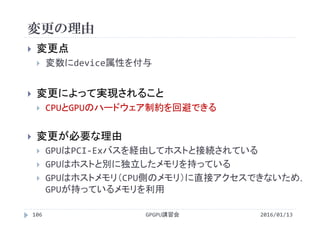
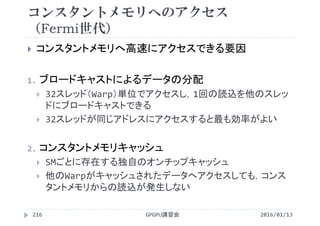
![処理時間の比較
配列の要素数 N=220
1ブロックあたりのスレッド数 256
GPUはマルチスレッドで処理しないと遅い
GPUを使えばどのような問題でも速くなるわけではない
並列に処理できるようプログラムを作成する必要がある
implementation Processing time [ms]
CPU (1 Thread) 4.55
GPU (1 Thread) 206
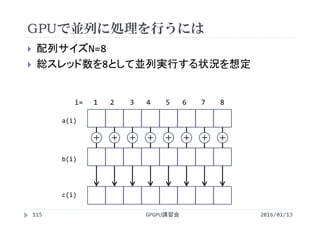
GPU (256 Threads) 0.115
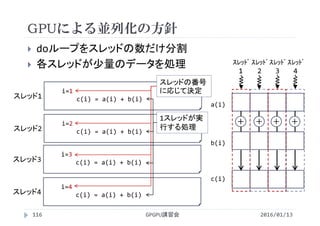
GPGPU講習会130 2016/01/13](https://image.slidesharecdn.com/gpuseminarcudafortran-160307144626/85/GPGPU-Seminar-GPGPU-and-CUDA-Fortran-130-320.jpg)




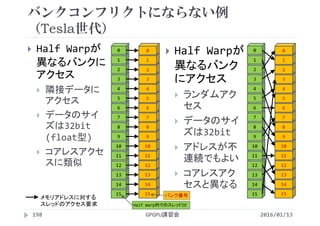
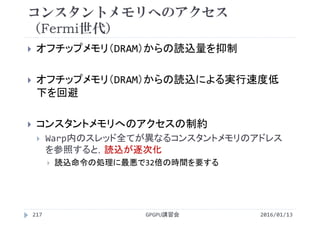
![性能比較
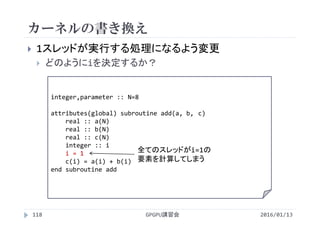
2016/01/13GPGPU講習会135
1ブロックあたりのスレッド数が増加すると性能が向上
スレッド数を多くしすぎると性能が低下
CUDA CとCUDA Fortranで同じ傾向を示す
スレッド数が多いほど処理時間は短いが,多すぎると遅くなる
Number of
Threads/Block
Processing time [ms]
C Fortran
32 0.276 0.280
64 0.169 0.170
128 0.128 0.130
256 0.119 0.116
512 0.120 0.117
1024 0.151 0.146](https://image.slidesharecdn.com/gpuseminarcudafortran-160307144626/85/GPGPU-Seminar-GPGPU-and-CUDA-Fortran-135-320.jpg)









![実行結果
GPGPU講習会150
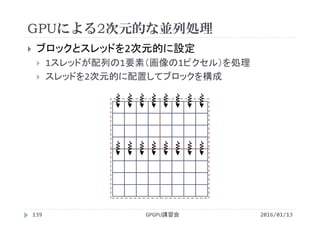
2次元版
カーネル スレッド数 実行時間[s]
add 16×16(=256) 155
2016/01/13
# CUDA_PROFILE_LOG_VERSION 2.0
# CUDA_DEVICE 0 Tesla M2050
# TIMESTAMPFACTOR fffff5f14d408b28
method,gputime,cputime,occupancy
:
method=[ add ] gputime=[ 154.976 ] cputime=[ 6.000 ] occupancy=[ 1.000 ]](https://image.slidesharecdn.com/gpuseminarcudafortran-160307144626/85/GPGPU-Seminar-GPGPU-and-CUDA-Fortran-150-320.jpg)
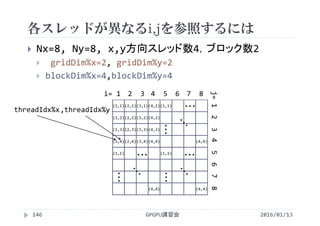
![実行結果
GPGPU講習会151
1次元版(vectoradd.cuf)
カーネル スレッド数 実行時間[s]
add 256 113
# CUDA_PROFILE_LOG_VERSION 2.0
# CUDA_DEVICE 0 Tesla M2050
# TIMESTAMPFACTOR fffff5f0d1572620
method,gputime,cputime,occupancy
:
method=[ add ] gputime=[ 114.816 ] cputime=[ 6.000 ] occupancy=[ 1.000 ]
2016/01/13](https://image.slidesharecdn.com/gpuseminarcudafortran-160307144626/85/GPGPU-Seminar-GPGPU-and-CUDA-Fortran-151-320.jpg)

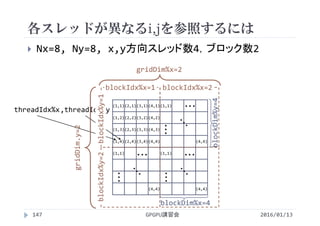
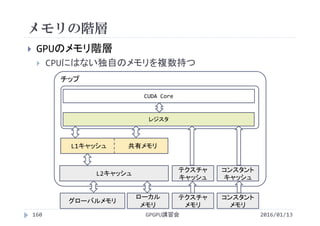
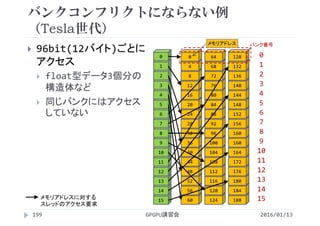
![ベクトル和(2次元並列版)の実行結果
GPGPU講習会153
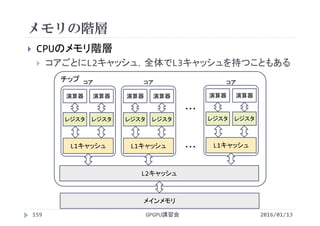
x,y方向スレッド数による実行時間の変化
1ブロックあたりのスレッド数を256に固定
2016/01/13
スレッド数 実行時間[s]
1×256 1136
2×128 601
4× 64 341
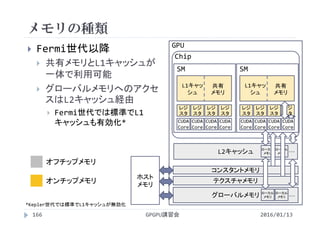
8× 32 213
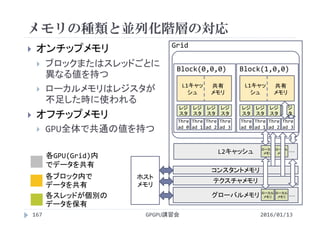
16× 16 155
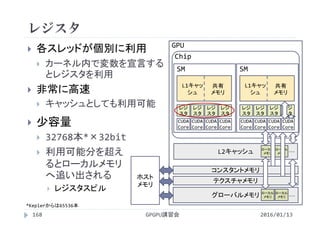
32× 8 119
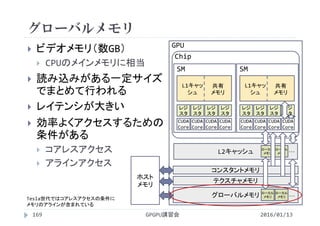
64× 4 135
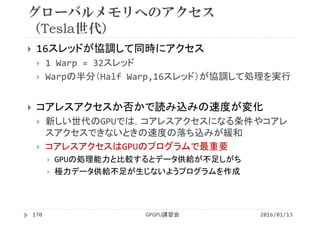
128× 2 121
256× 1 116
1次元の場合
とほぼ同じ](https://image.slidesharecdn.com/gpuseminarcudafortran-160307144626/85/GPGPU-Seminar-GPGPU-and-CUDA-Fortran-153-320.jpg)







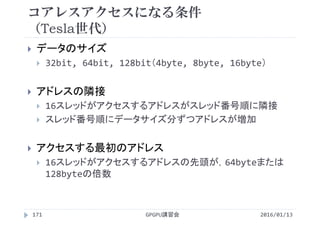
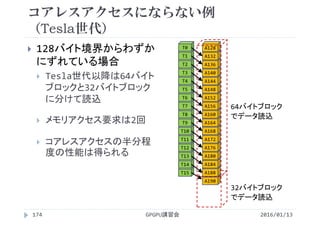

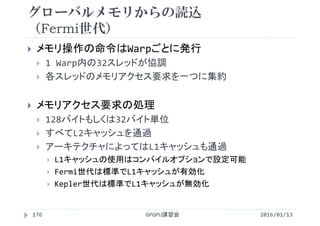

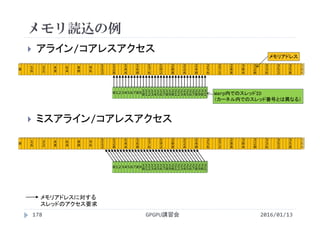
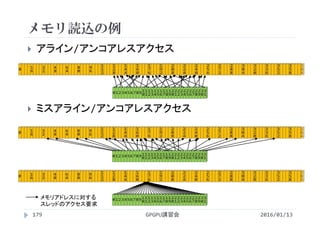







































![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL Hacks 実装]Playing FPS Games with Deep Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-180202050350-thumbnail.jpg?width=640&height=640&fit=bounds)































































