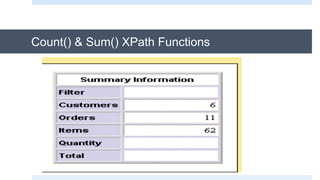
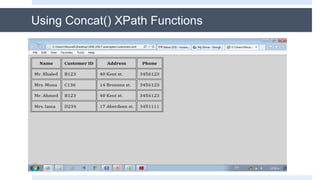
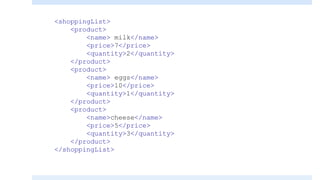
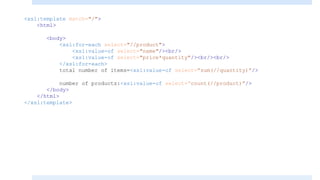
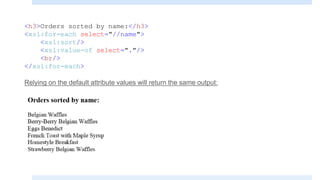
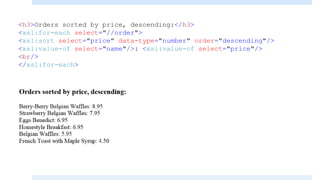
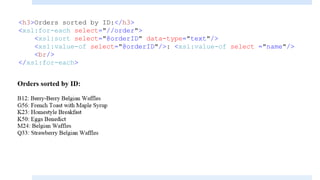
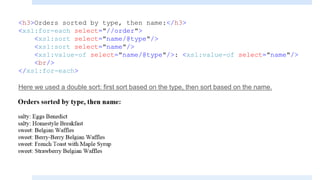
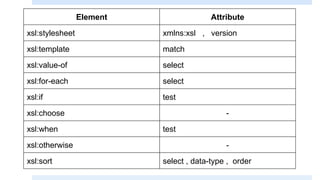
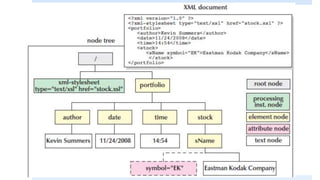
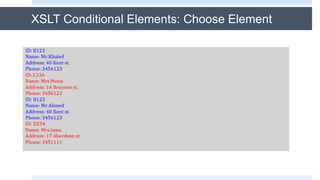
The document discusses XSLT (Extensible Stylesheet Language Transformations), which is used to transform XML documents into other formats like HTML, PDF, etc. It explains some key XSLT elements and concepts:
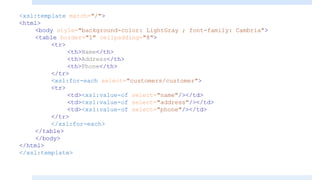
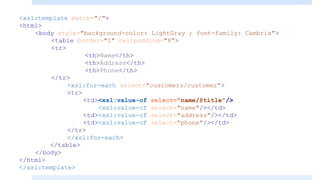
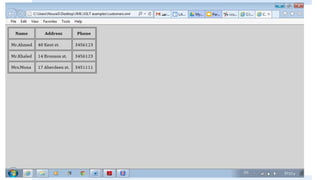
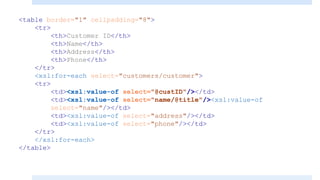
1. The <template> element matches XML elements and applies styles.
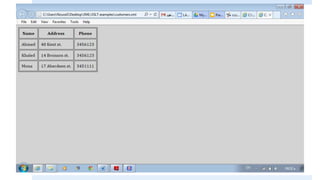
2. The <value-of> element inserts node values from the XML.
3. The <for-each> element loops through multiple occurrences of an element.
It also covers selecting attributes with XPath, using conditional elements like <if> and <choose>, and predicates to filter nodes. XSLT allows XML data to be transformed and presented in different formats.









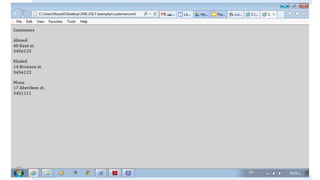
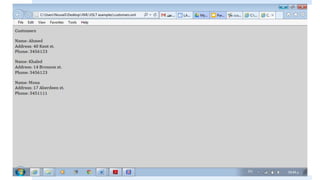
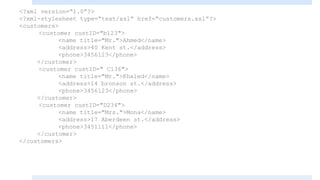
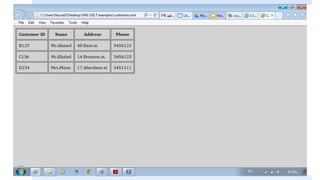
![The “value-of” element
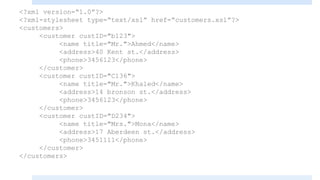
The value-of element extracts a value from the XML document. Since we have
3 customers in our example, only the first value was extracted.
If we specifically wanted the second customer, the Xpath expression would be:
customers/customer[2]](https://image.slidesharecdn.com/xmlpart5-161217122447/85/Xml-part5-17-320.jpg)
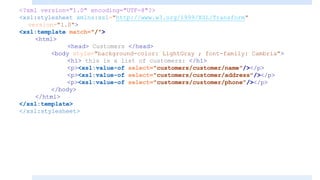
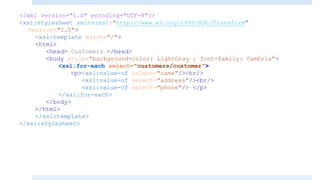
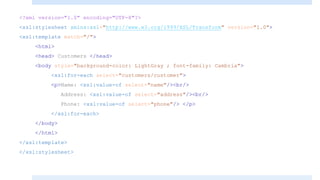
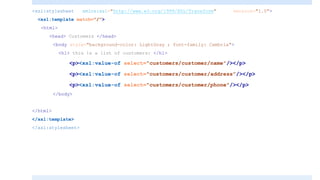
![<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:template match="/">
<html>
<head> Customers </head>
<body style="background-color: LightGray ; font-family: Cambria">
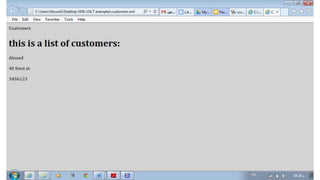
<h1> this is a list of customers: </h1>
<p><xsl:value-of select="customers/customer[2]/name"/></p>
<p><xsl:value-of select="customers/customer[2]/address"/></p>
<p><xsl:value-of select="customers/customer[2]/phone"/></p>
</body>
</html>
</xsl:template>
</xsl:stylesheet>](https://image.slidesharecdn.com/xmlpart5-161217122447/85/Xml-part5-18-320.jpg)




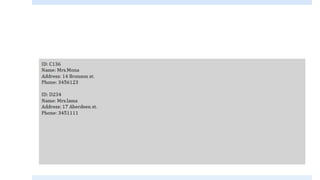
![Using the Double-forward Slash “//”
When we have more than one occurrence of the same element, XPath
will return the first one it finds.
If we want to specify which occurrence we want, we specify it:
//selected-node[3]
If we want to loop over all occurrences, we use the “for-each” element.](https://image.slidesharecdn.com/xmlpart5-161217122447/85/Xml-part5-35-320.jpg)








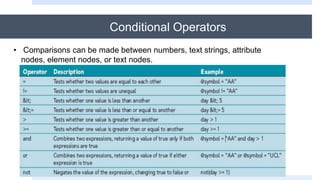

![Working with Predicates
A predicate is part of a location path that tests for a condition and references the
node set that fulfills that condition. The general syntax for a predicate is
node [expression]
Example:
name[3] Select the third name element in customers.
name[@title = ‘Mr.’]( match all the name who title is Mr.)
sName[@symbol = "AA" or @symbol="UCL”] (matches all sName elements
whose symbol attribute is equal to either “AA” or “UCL”.)](https://image.slidesharecdn.com/xmlpart5-161217122447/85/Xml-part5-50-320.jpg)
![Predicates and Using XPath Functions
A predicate can contain XPath functions:
last() returns the last node in the node tree
Example: book[last()] returns the last book
position() returns the position value of the node
Example: book[position()>=2 and position()<=5] returns
the second, third, fourth and fifth book
*note: book[position()=2] is equivalent to book[2]](https://image.slidesharecdn.com/xmlpart5-161217122447/85/Xml-part5-51-320.jpg)