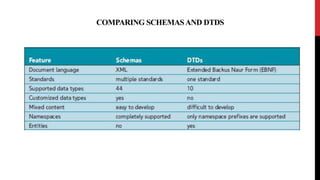
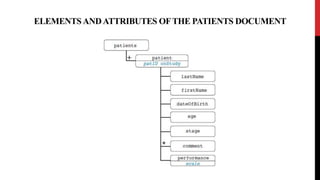
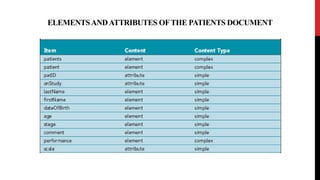
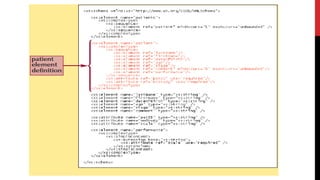
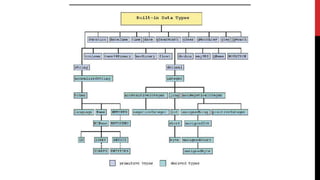
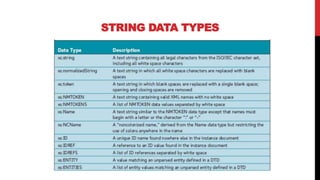
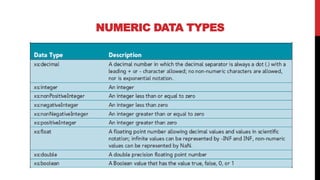
XML schemas provide a more powerful way to define the structure and content of XML documents compared to DTDs. Schemas support data types, namespaces, and more complex definitions of elements and attributes. The main elements used in schemas are:
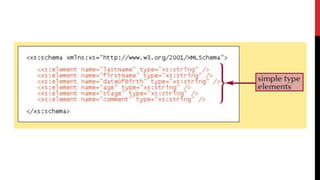
1. <xs:schema> which defines the root element and namespace for a schema.
2. <xs:element> and <xs:attribute> which define elements and attributes with attributes like name, type, and occurrence.
3. <xs:complexType> which defines complex element types with child elements, attributes, and mixed content.
Schemas allow precise specification of XML documents' structure through elements, attributes, data types and occurrence to enable validation of