Download to read offline







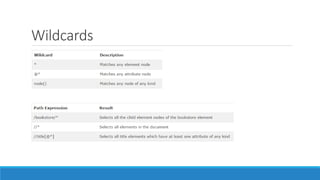
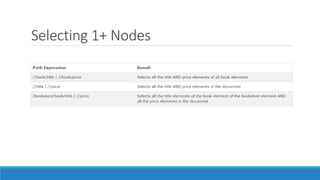
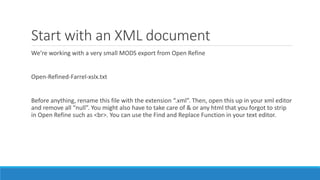



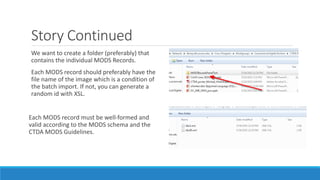




The document provides an introduction to XSL 2.0, focusing on its components like XSLT, XPath, and XSL-FO for transforming and formatting XML documents. It outlines the structure of XML documents, the importance of nodes, and the process of creating individual MODS records from a source XML. The document also emphasizes the need for well-formed and valid output according to specified guidelines.























































































