













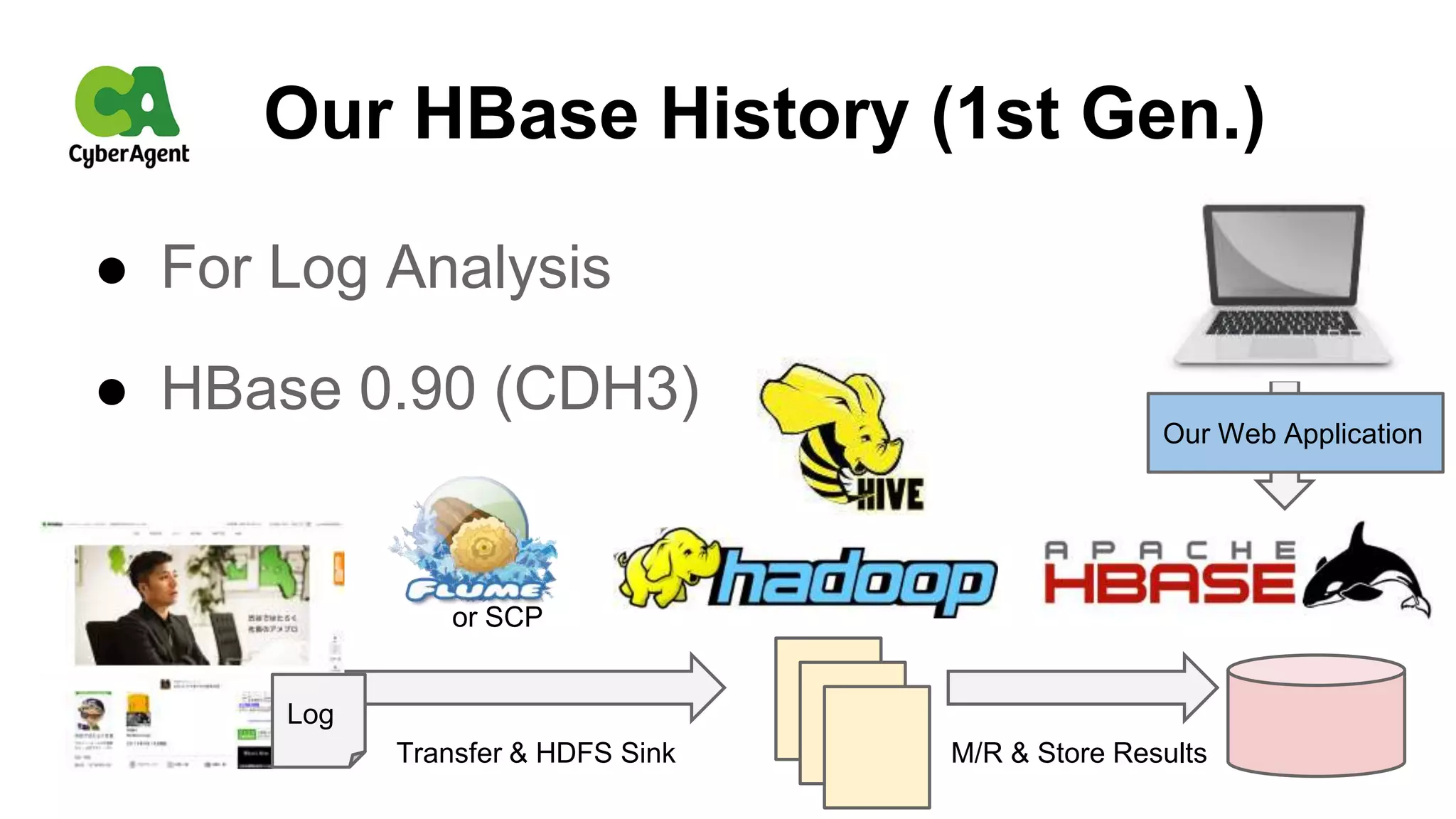








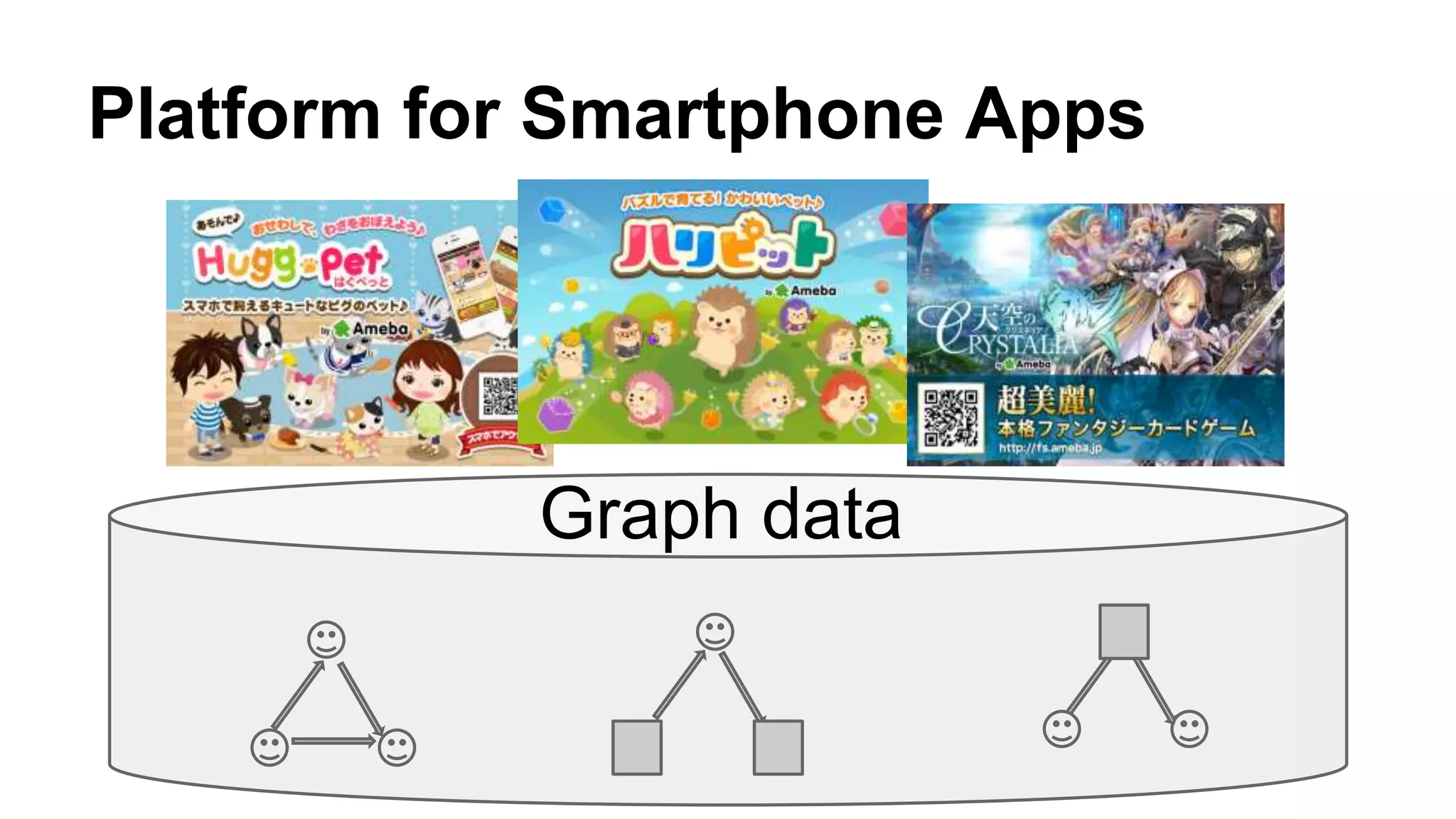



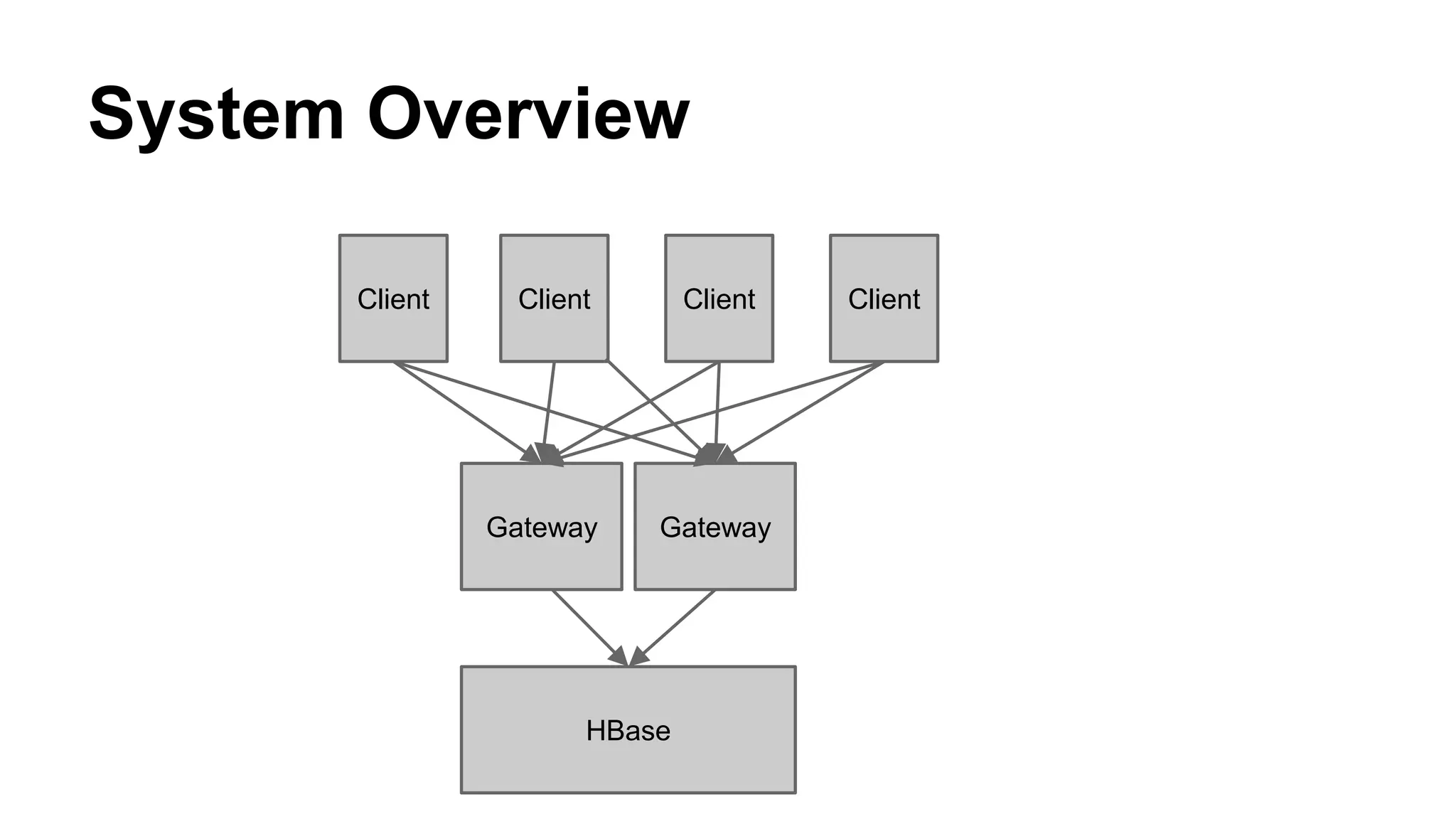
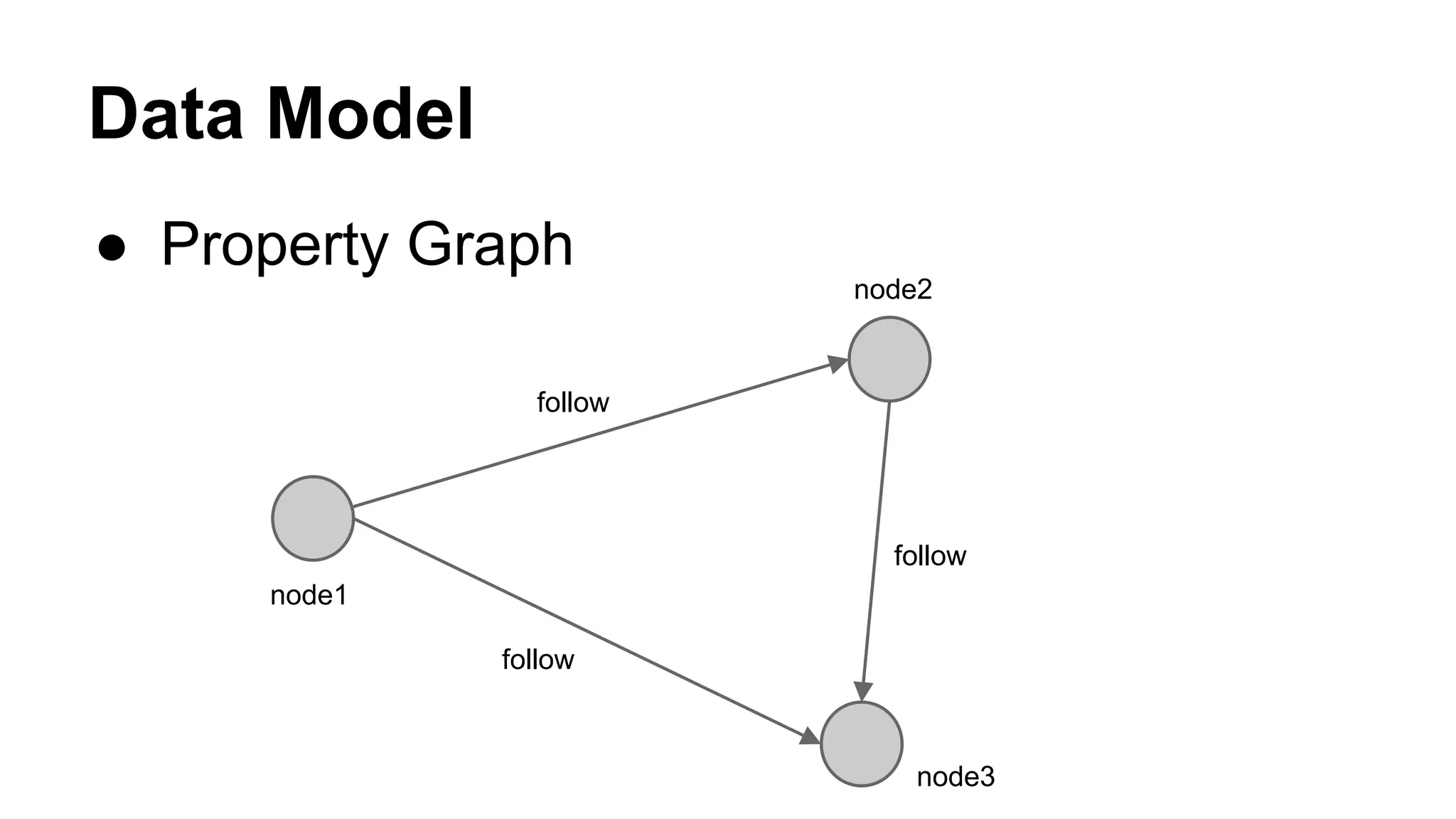
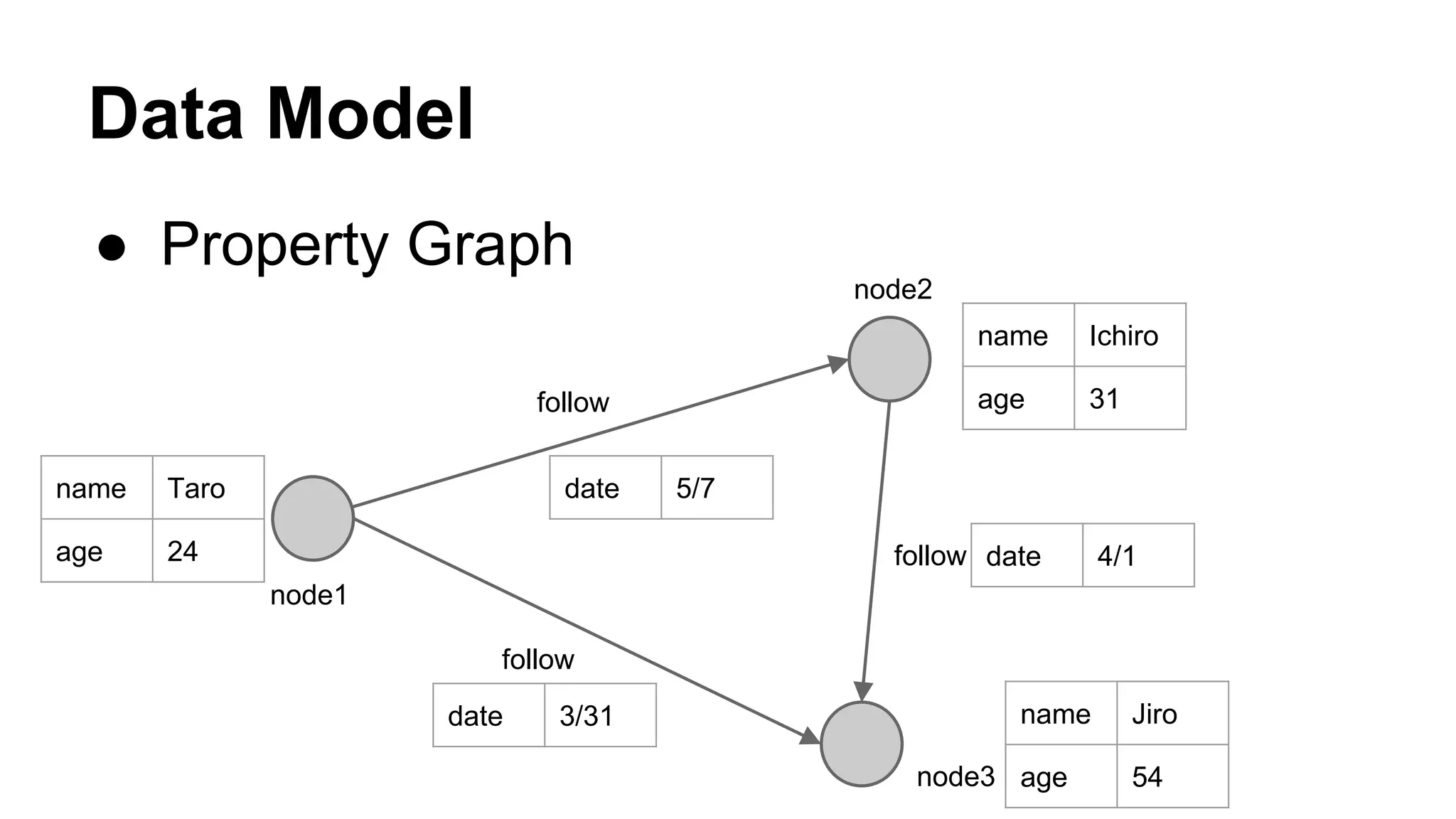










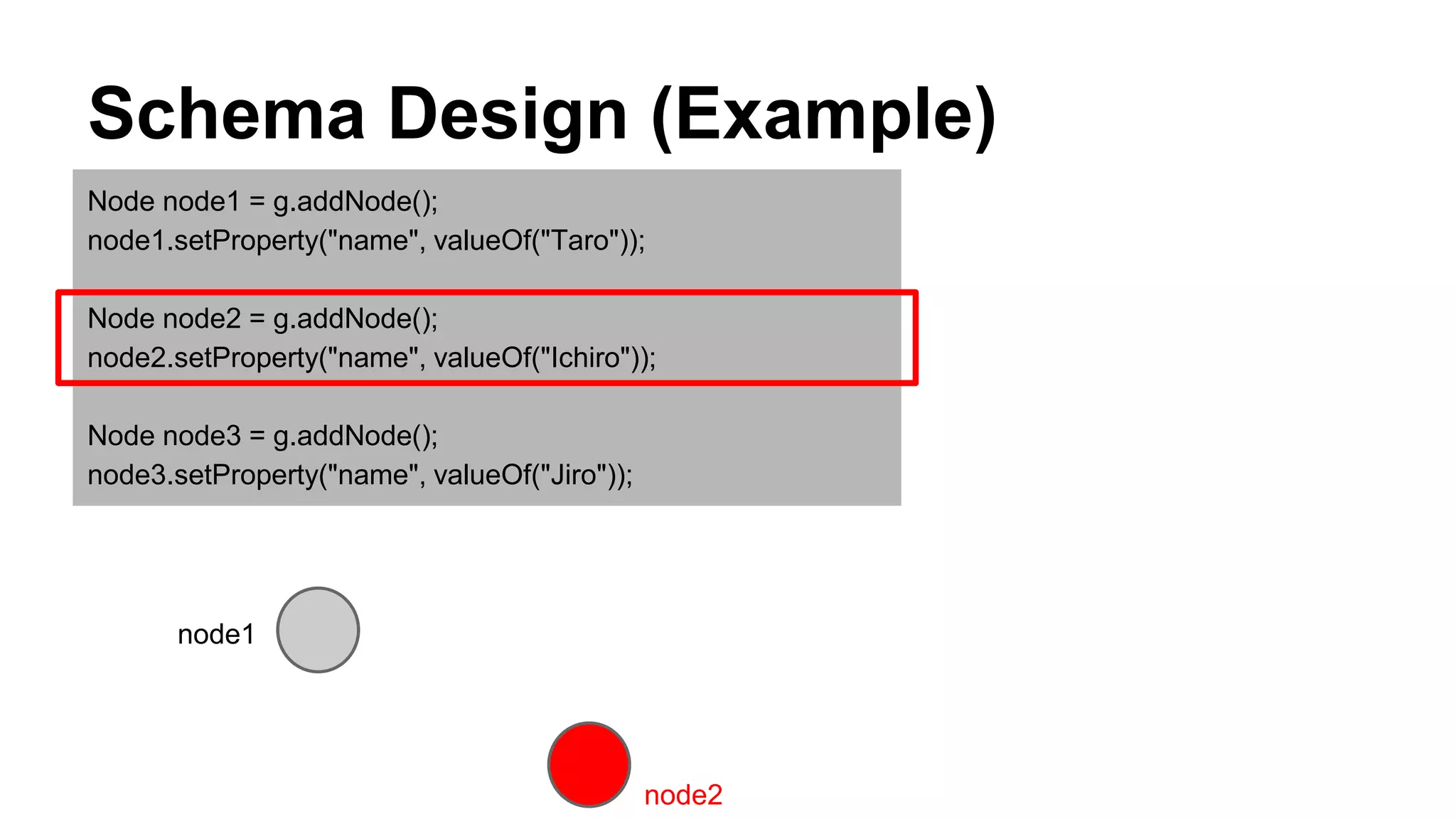
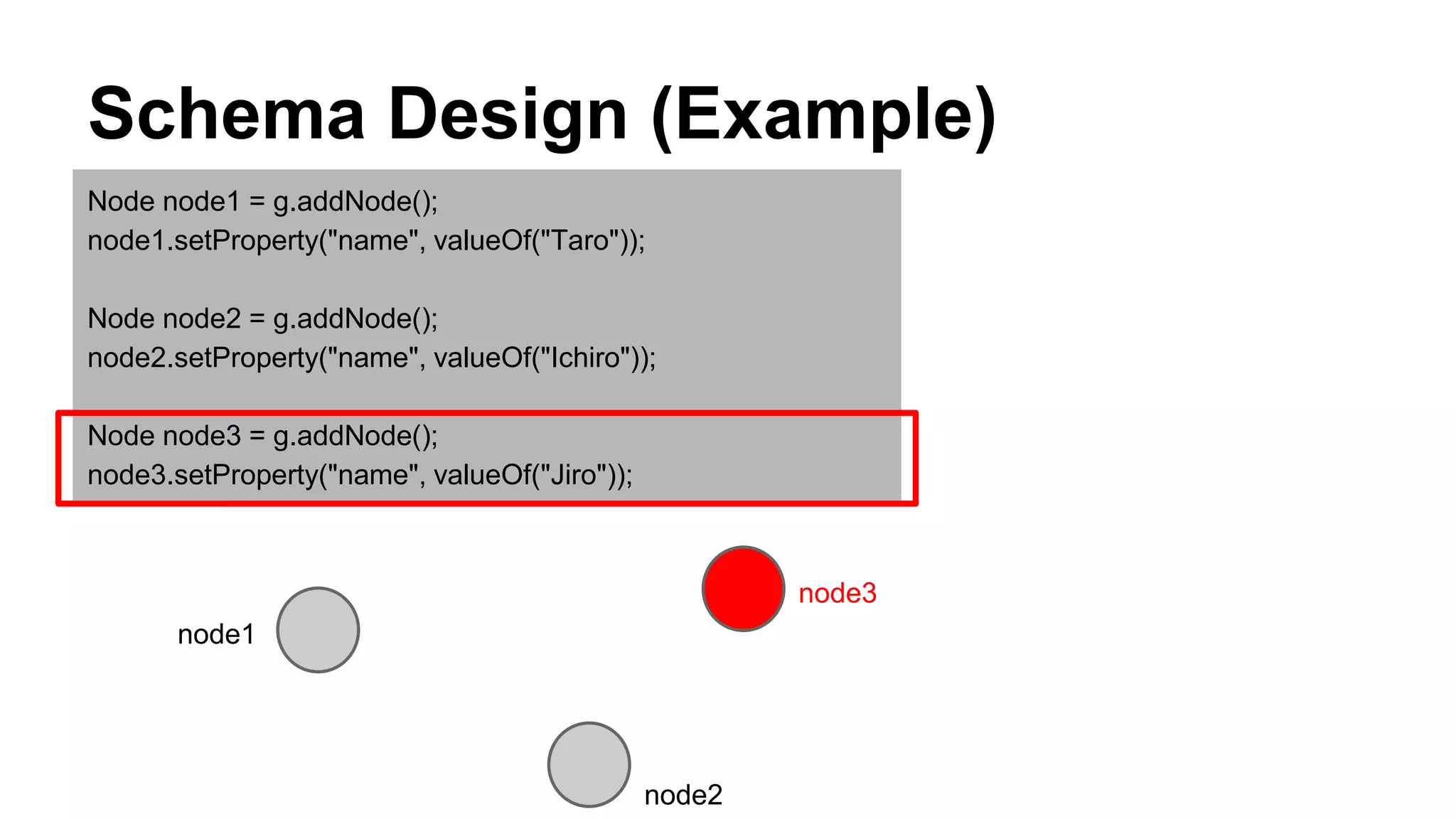

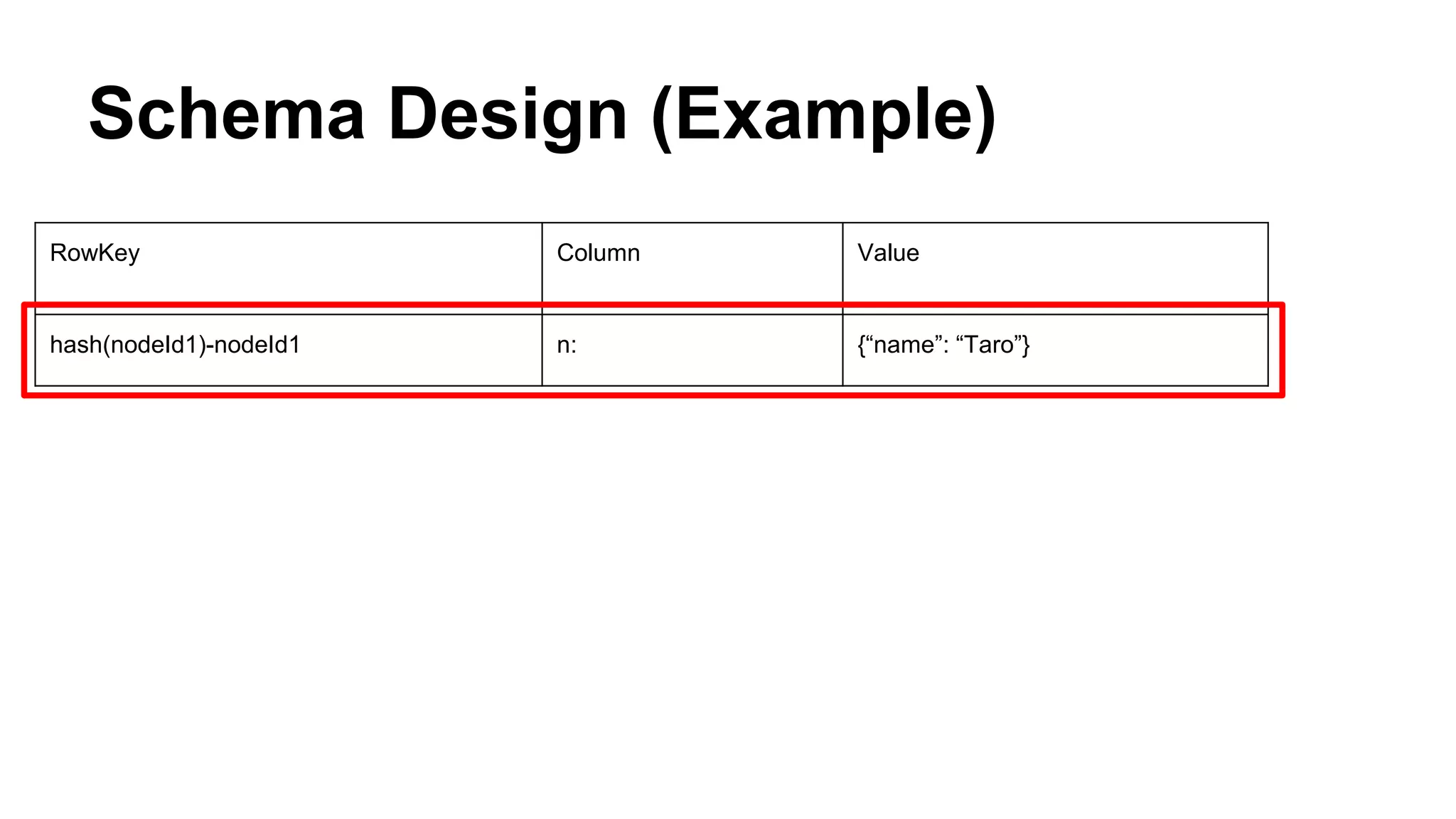
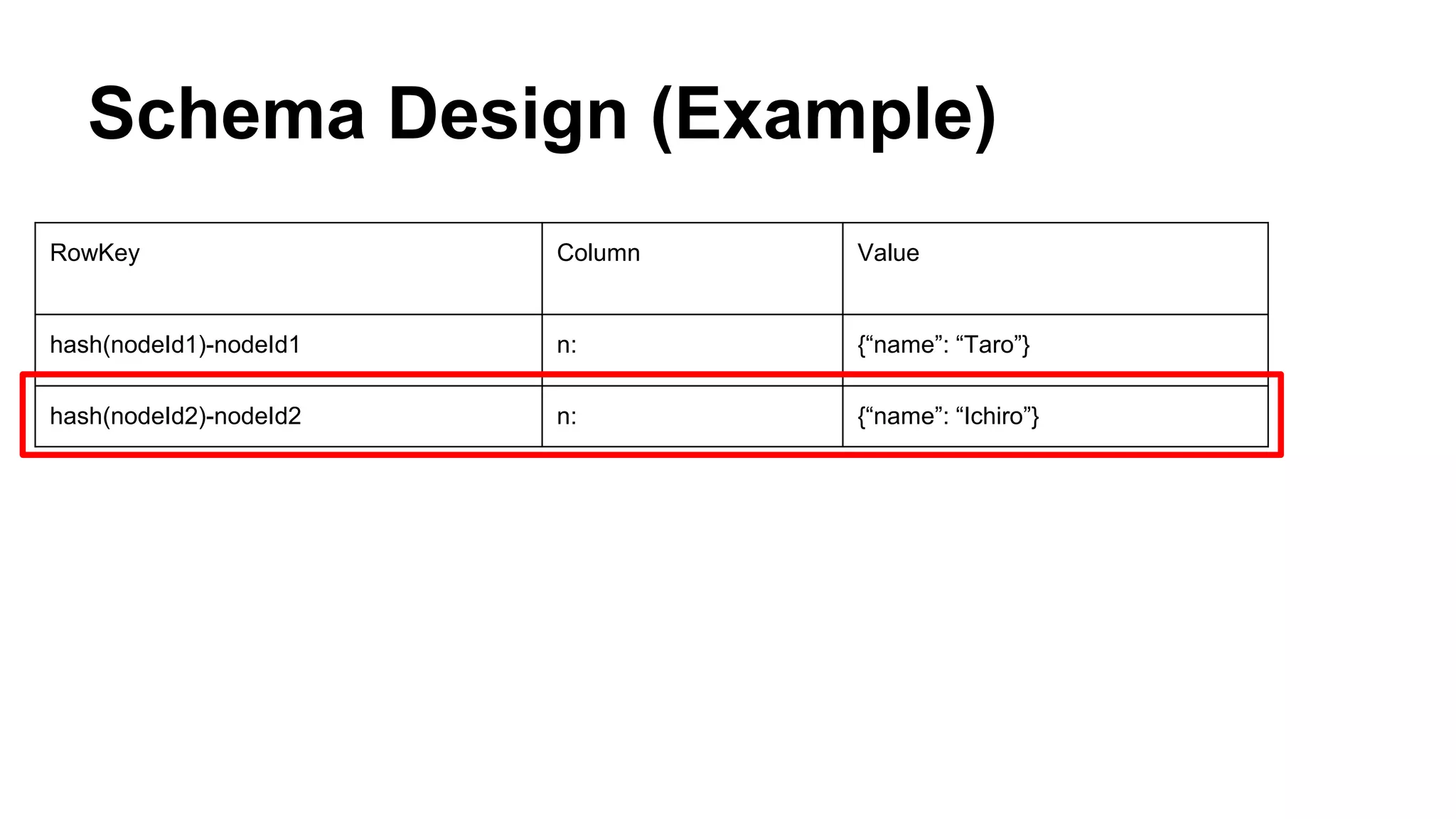
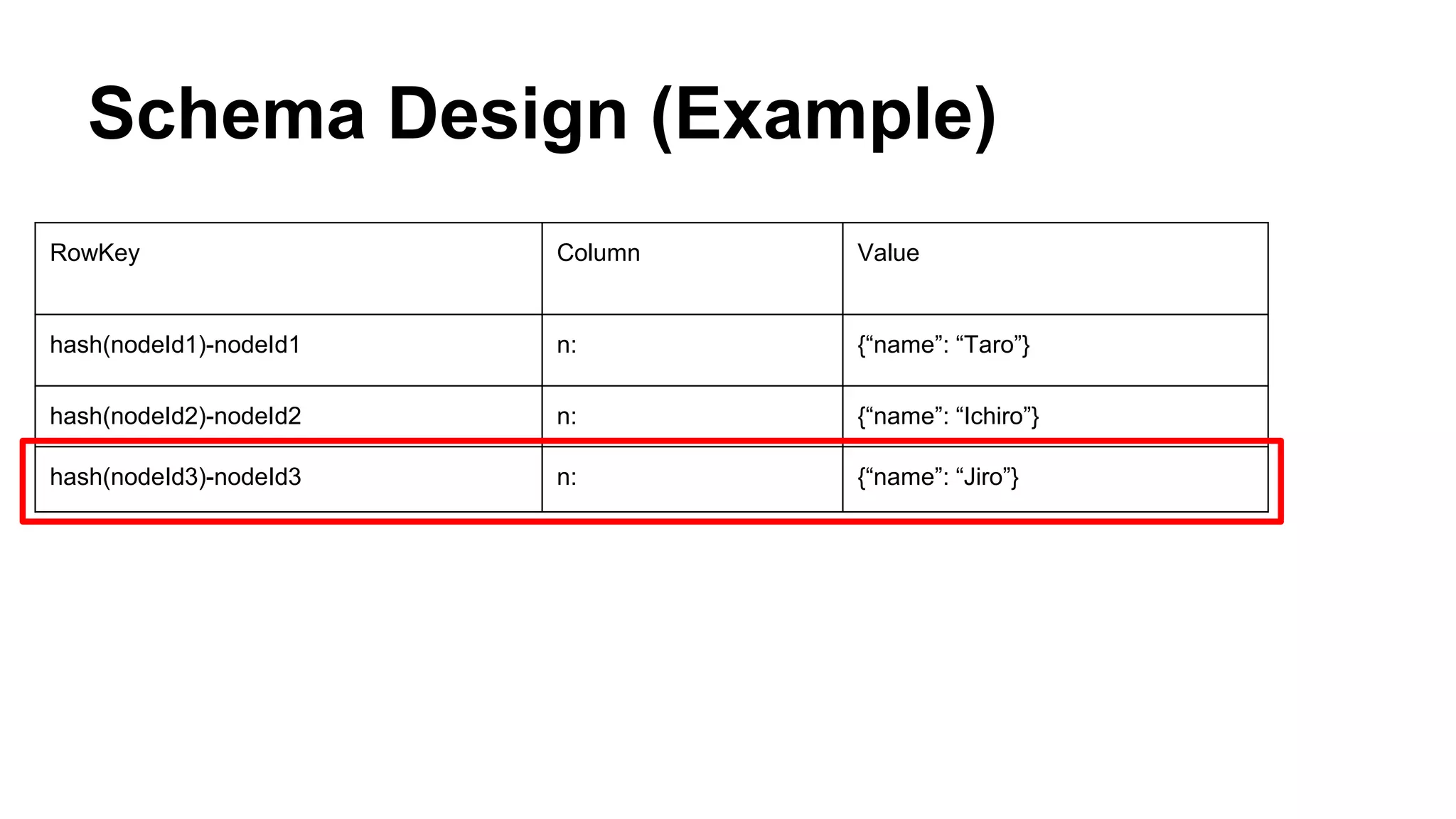
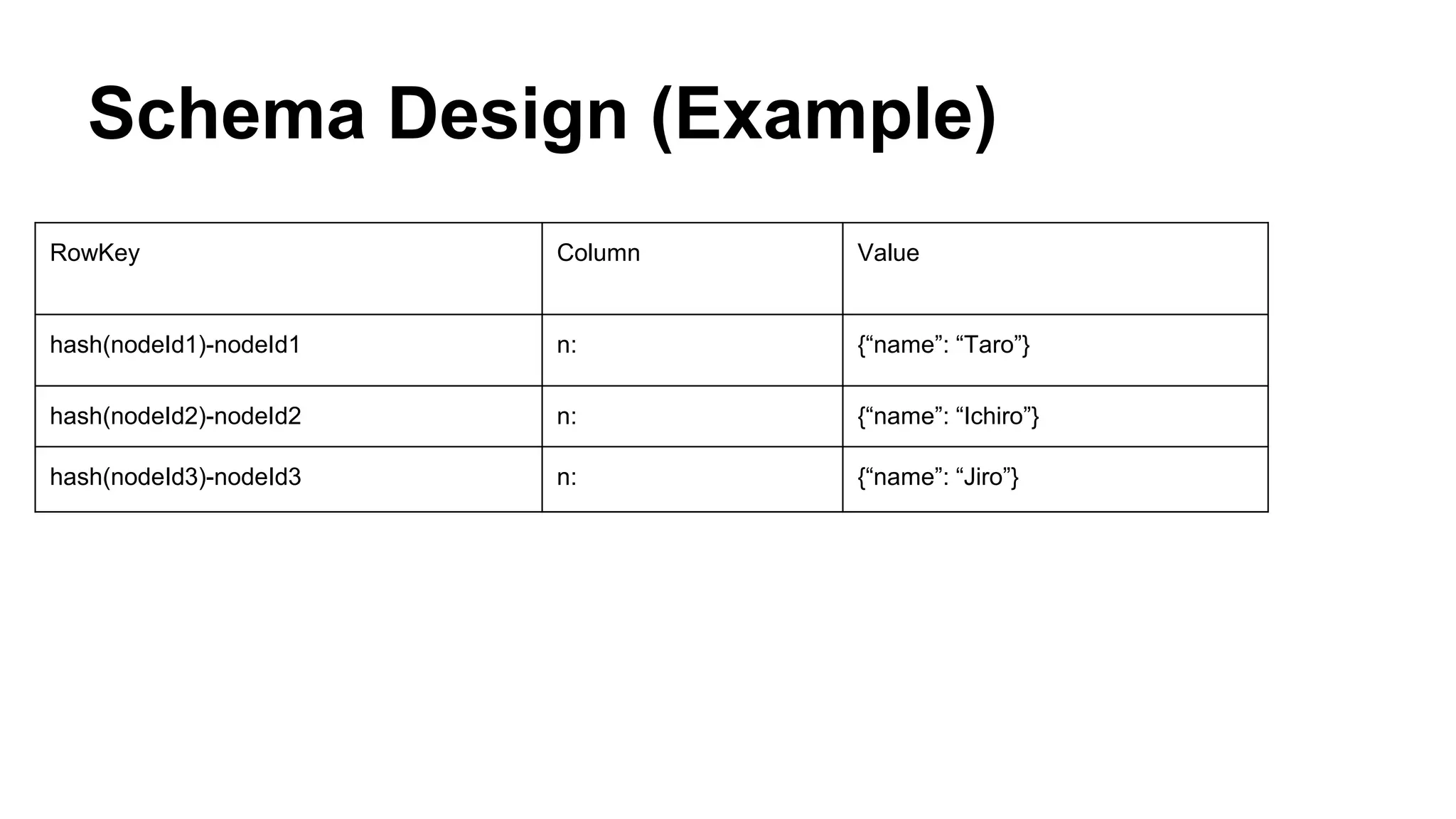
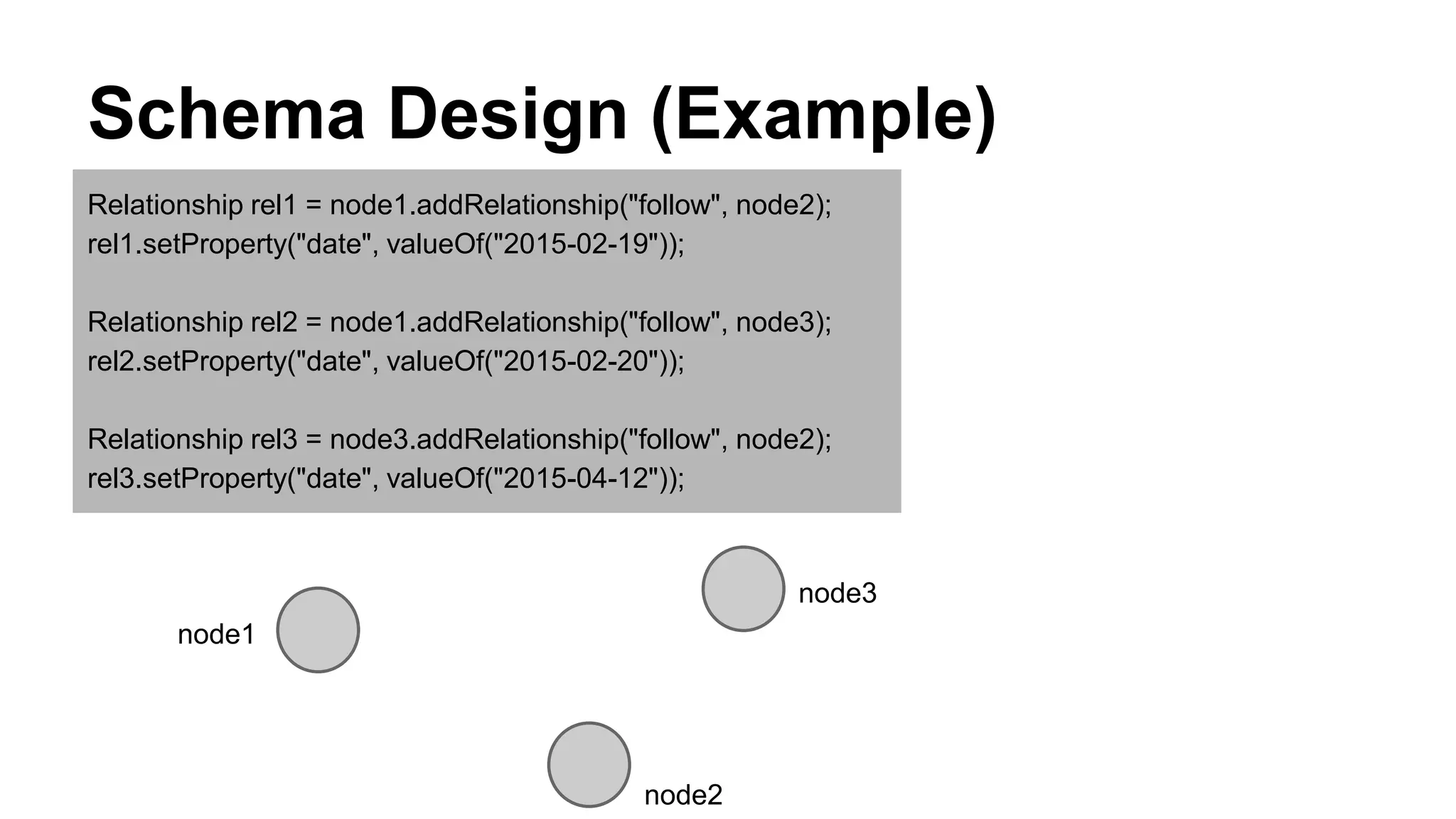
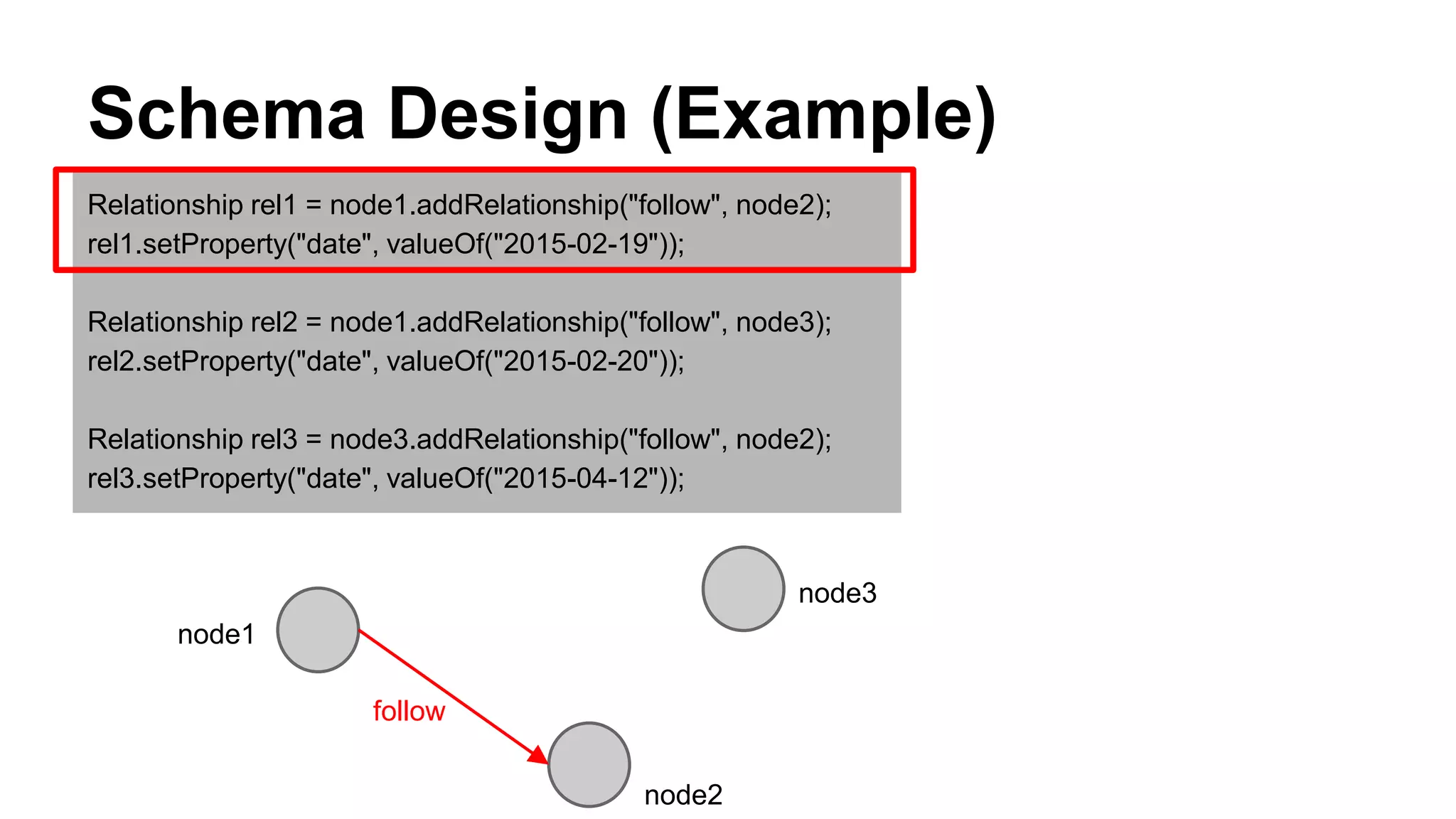
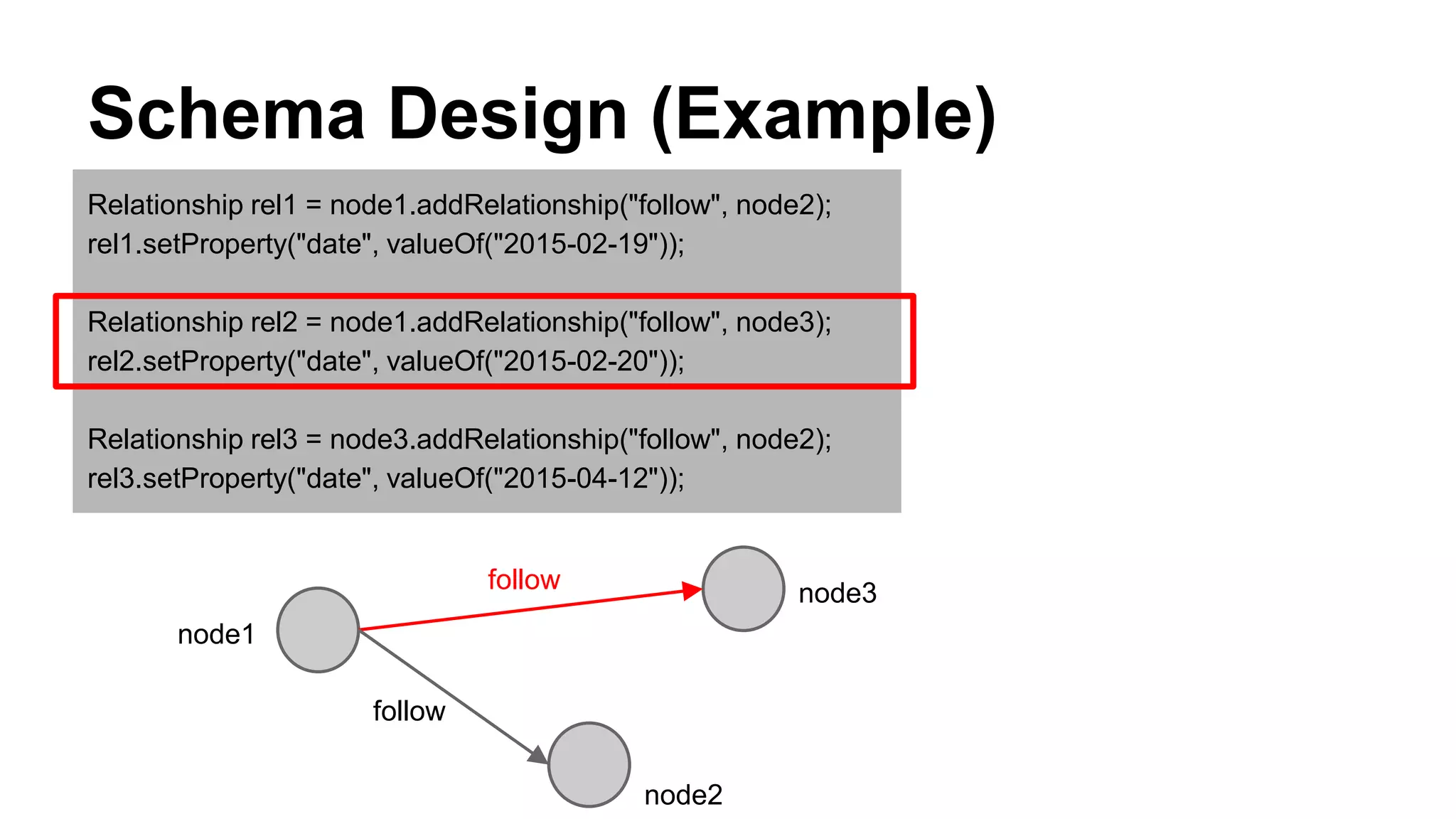
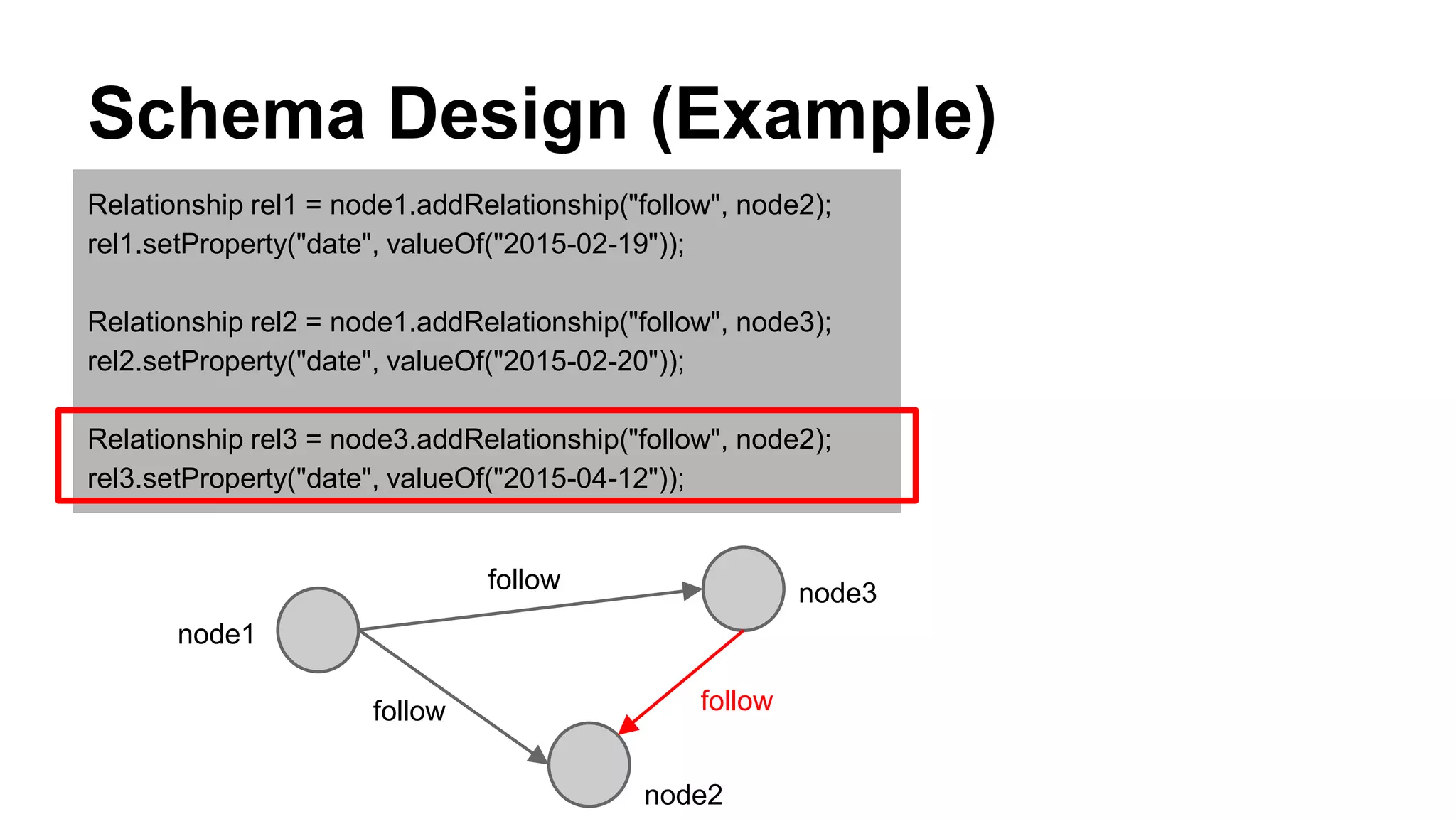



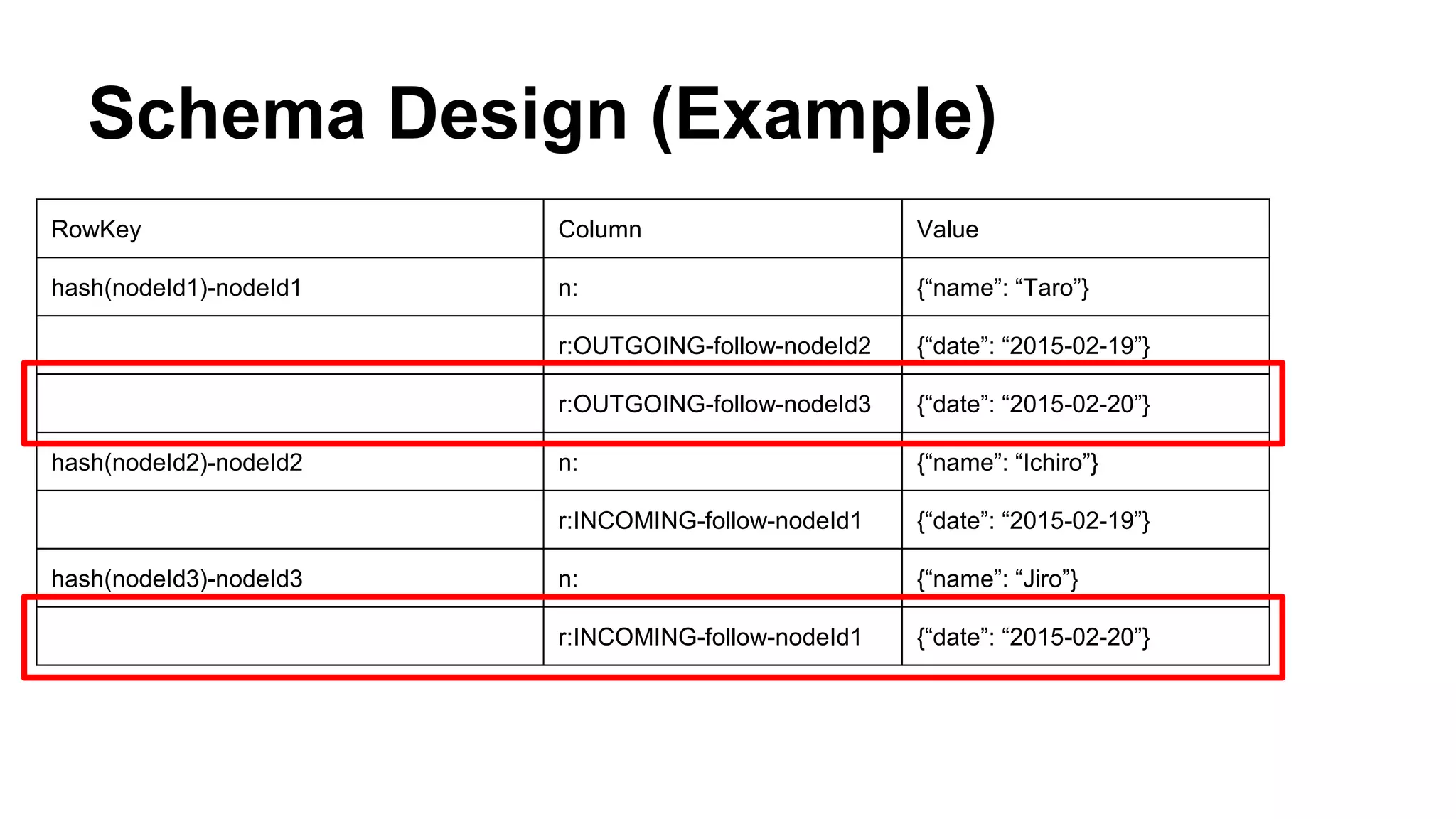
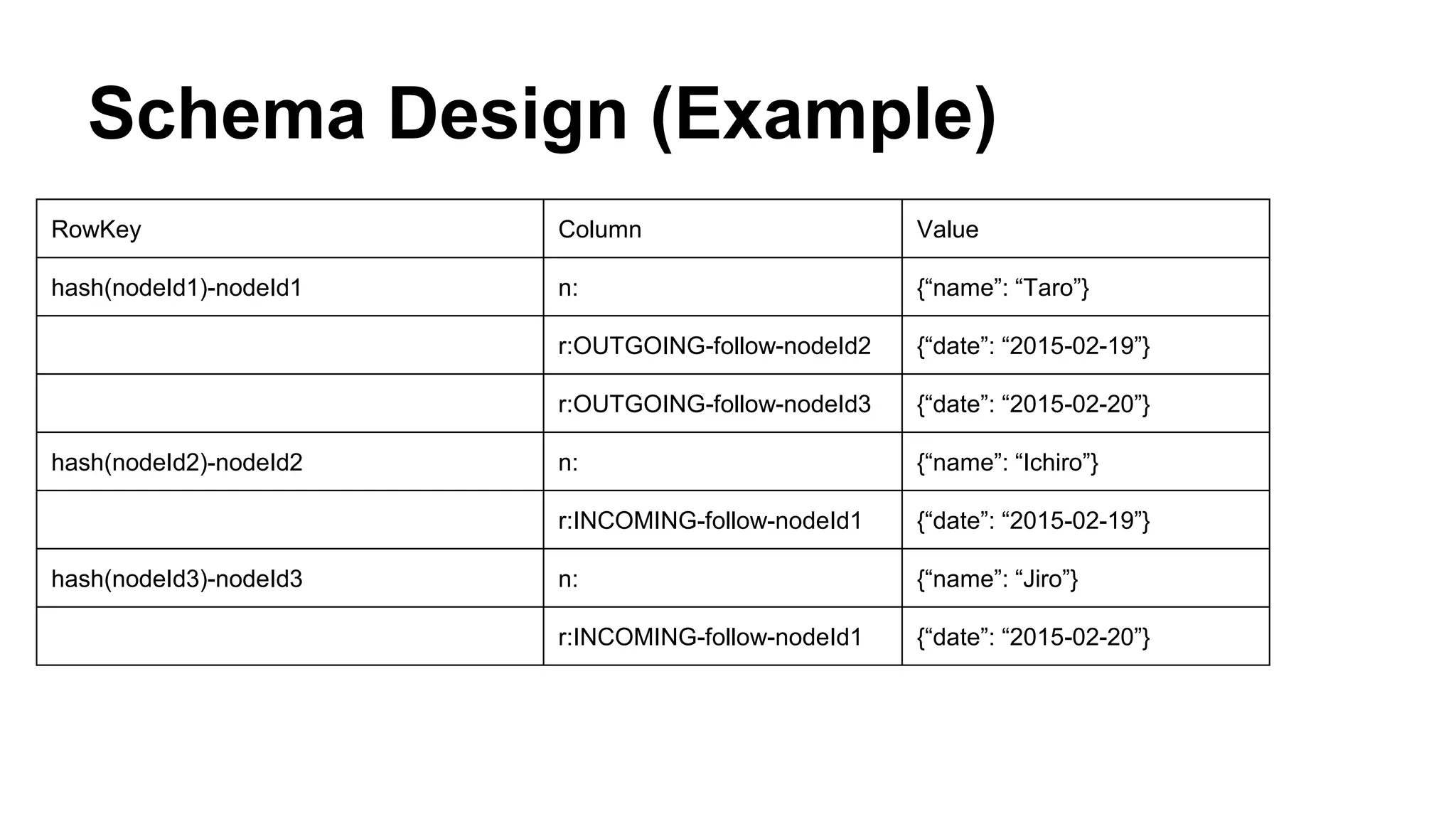
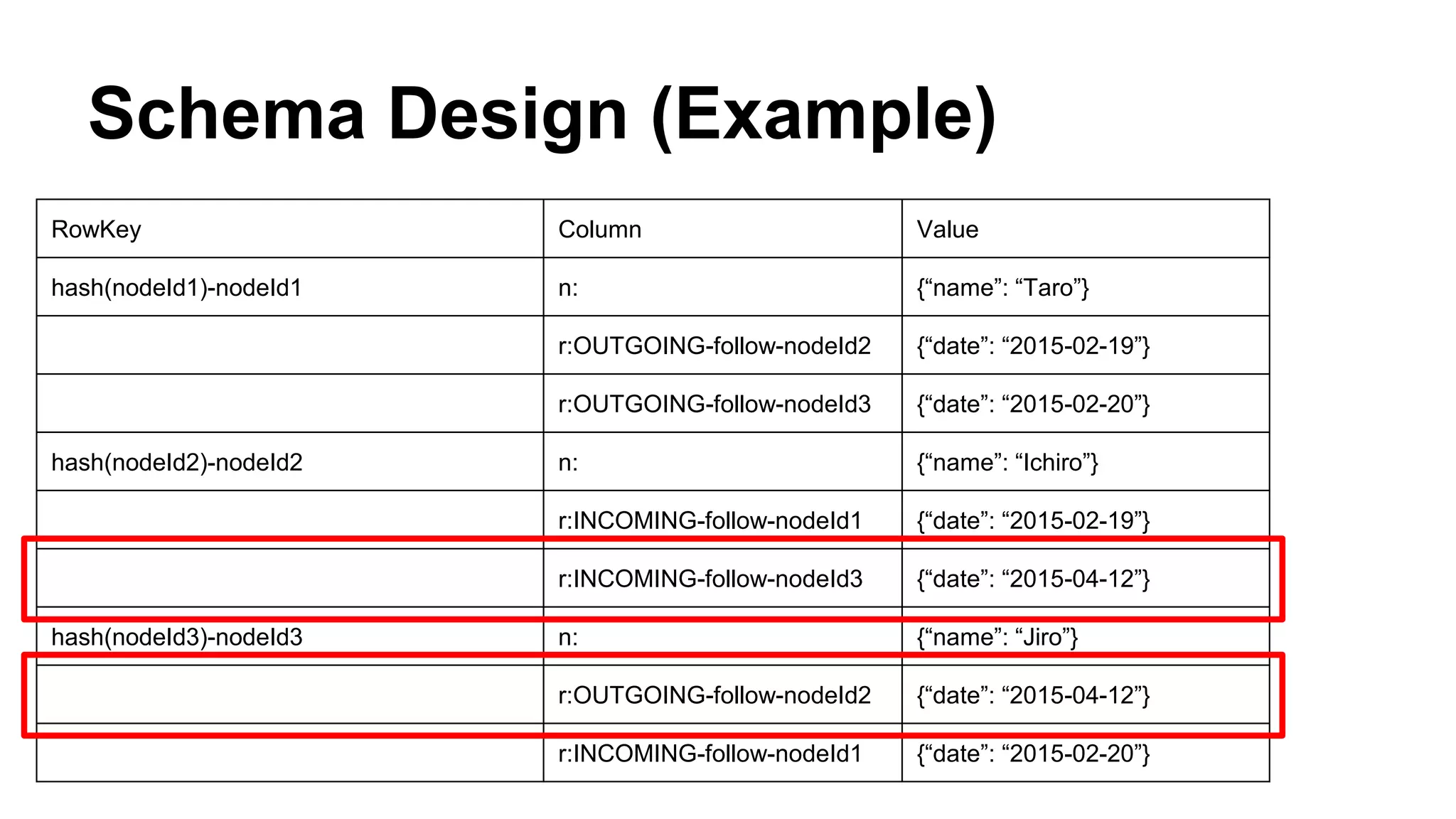
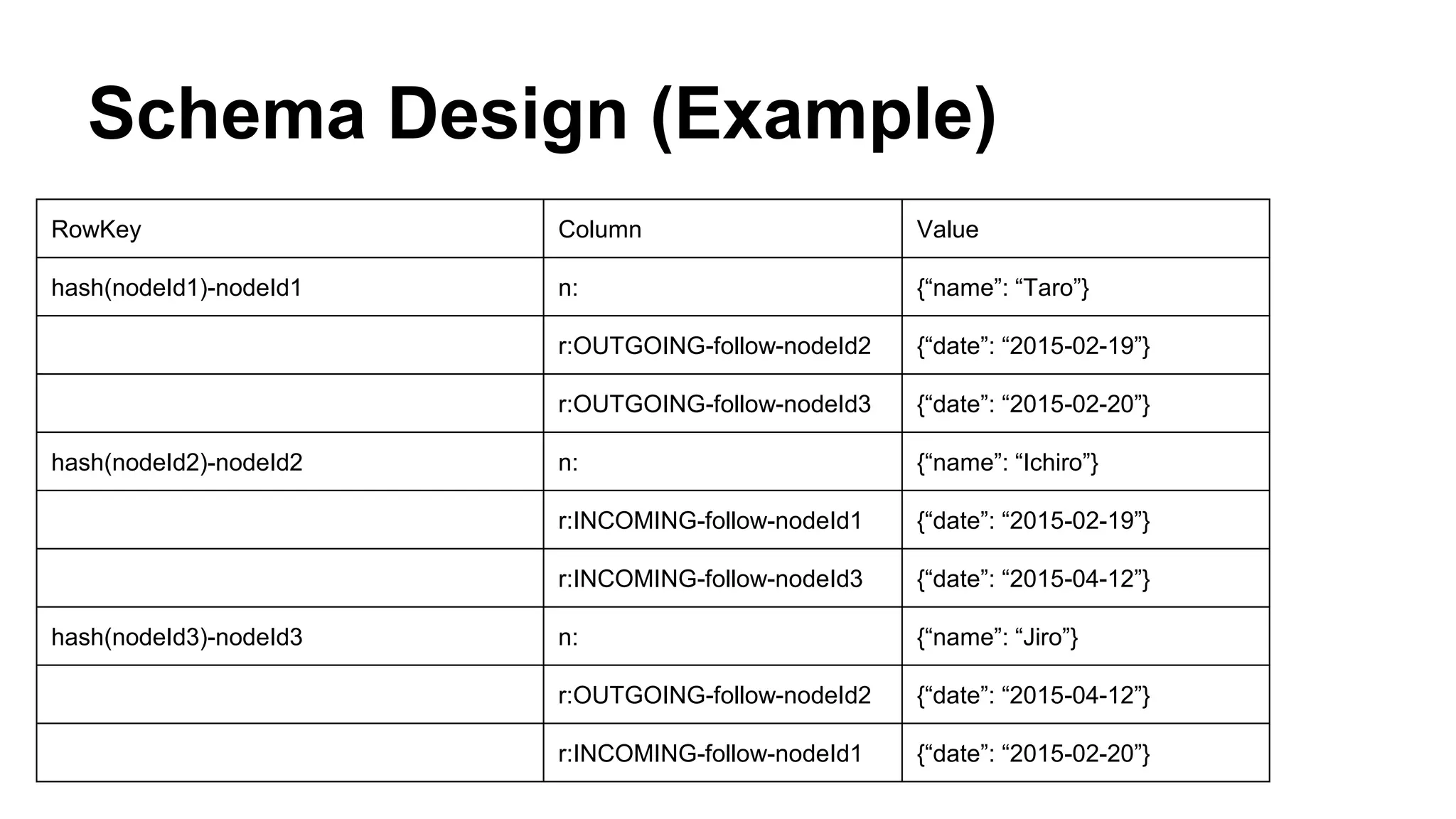
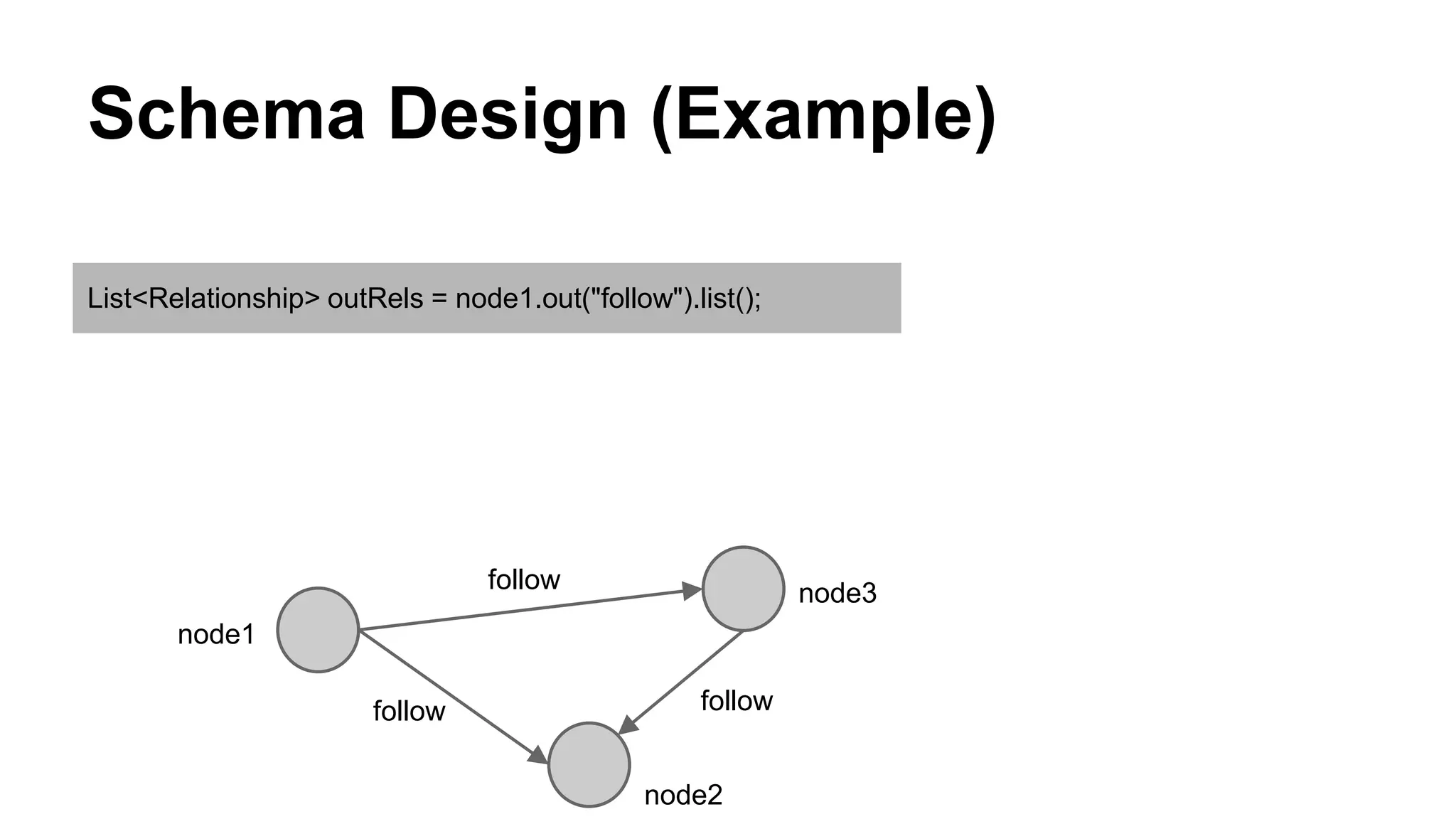
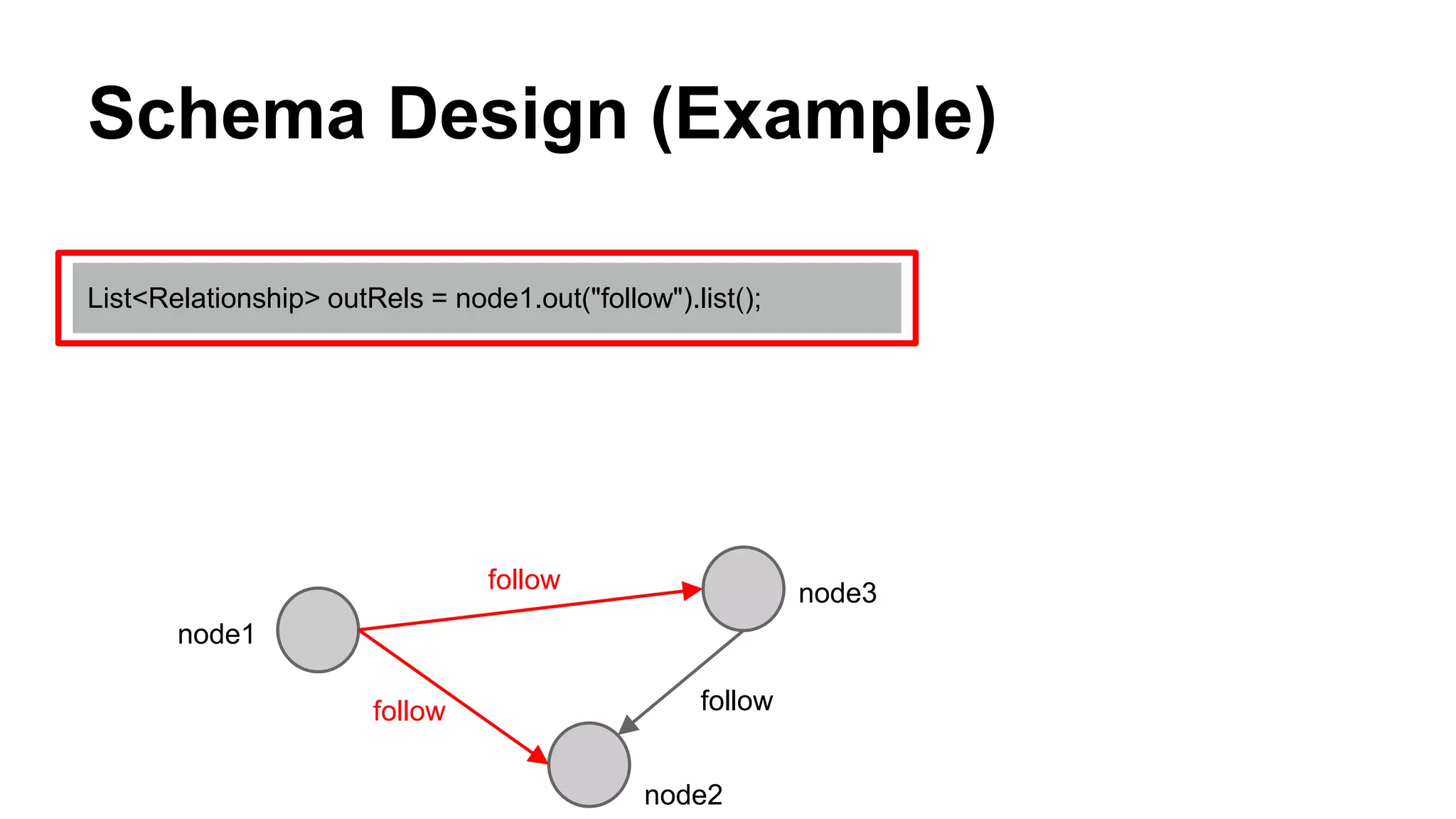
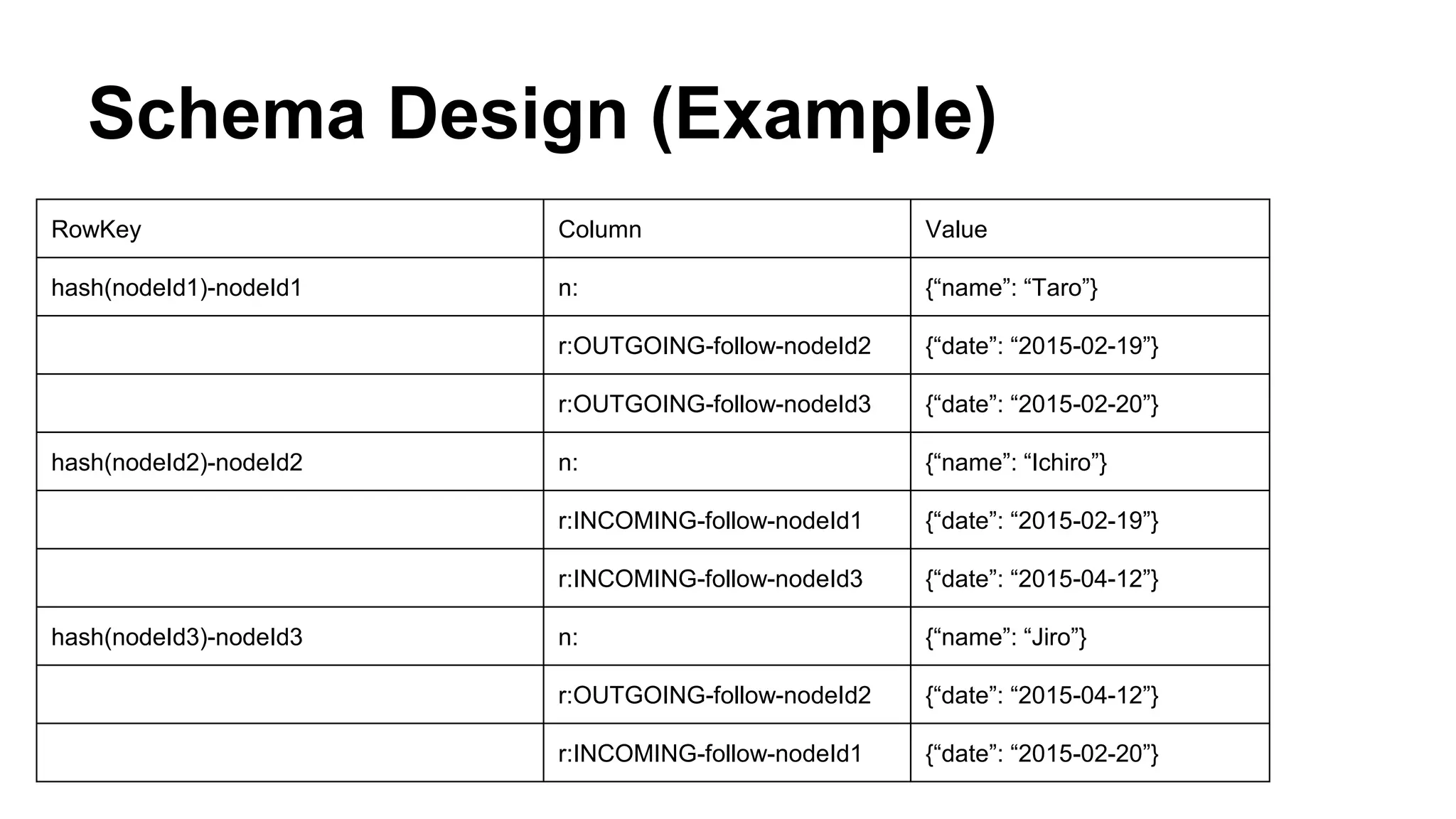
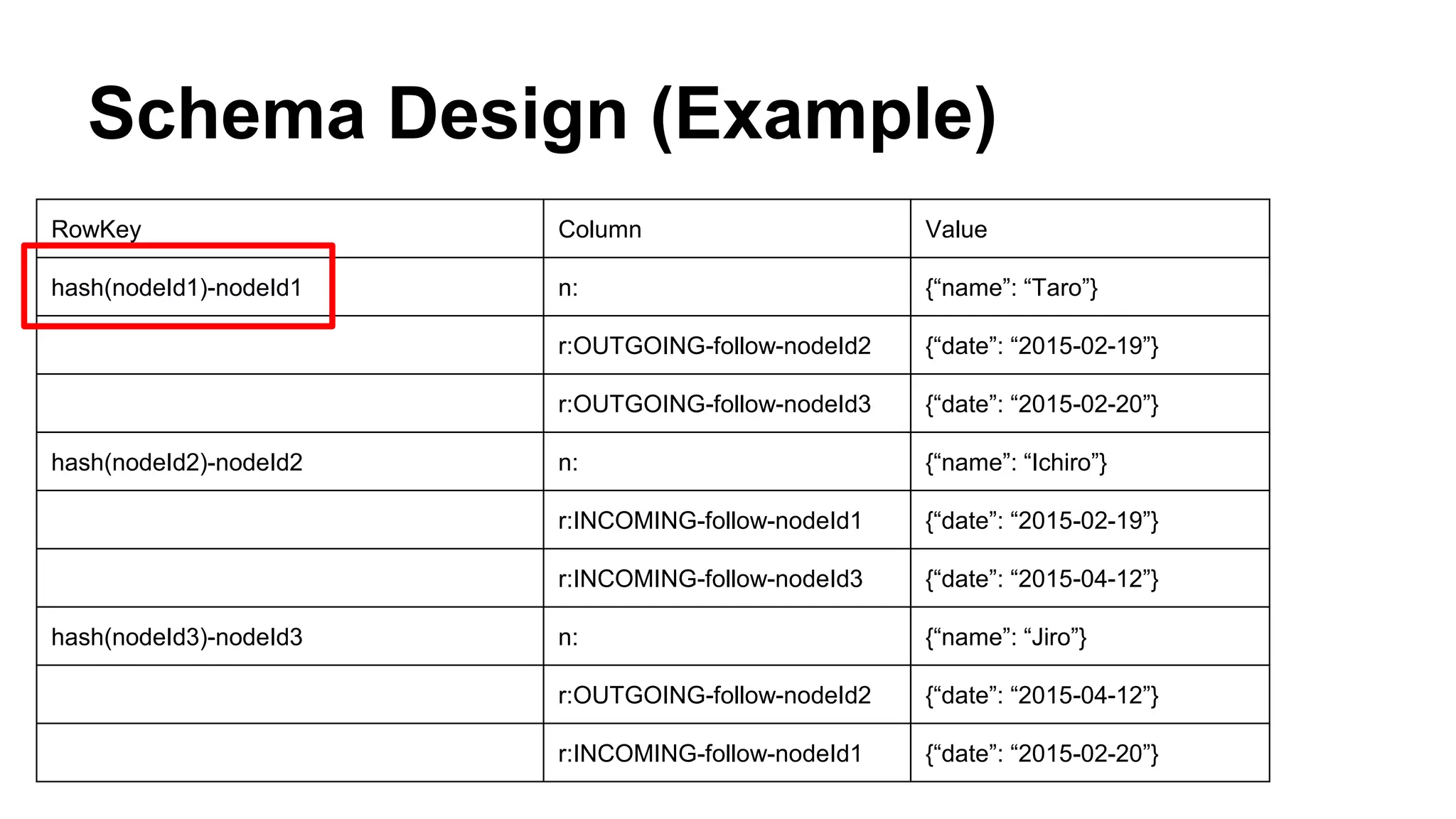
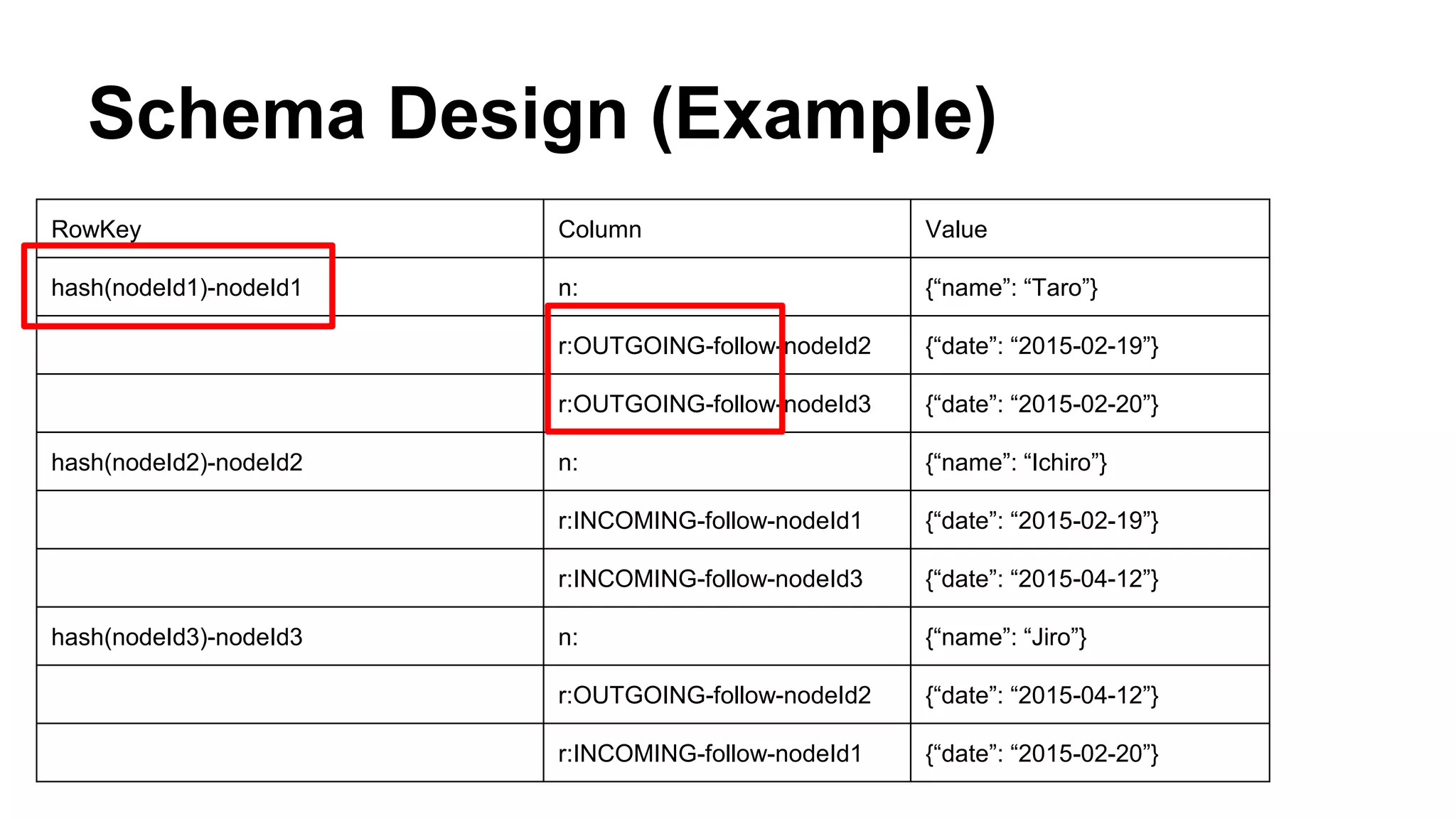
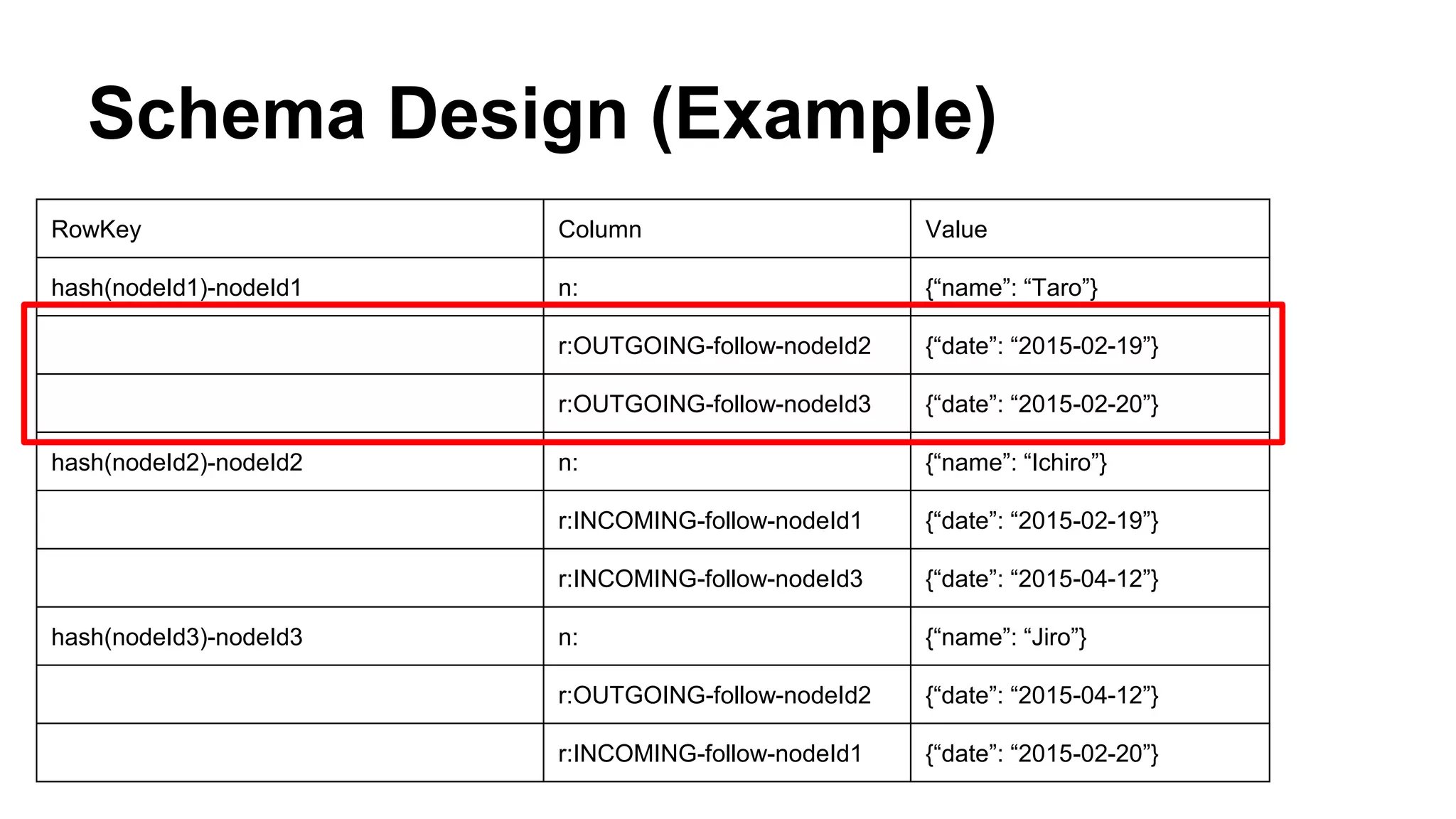
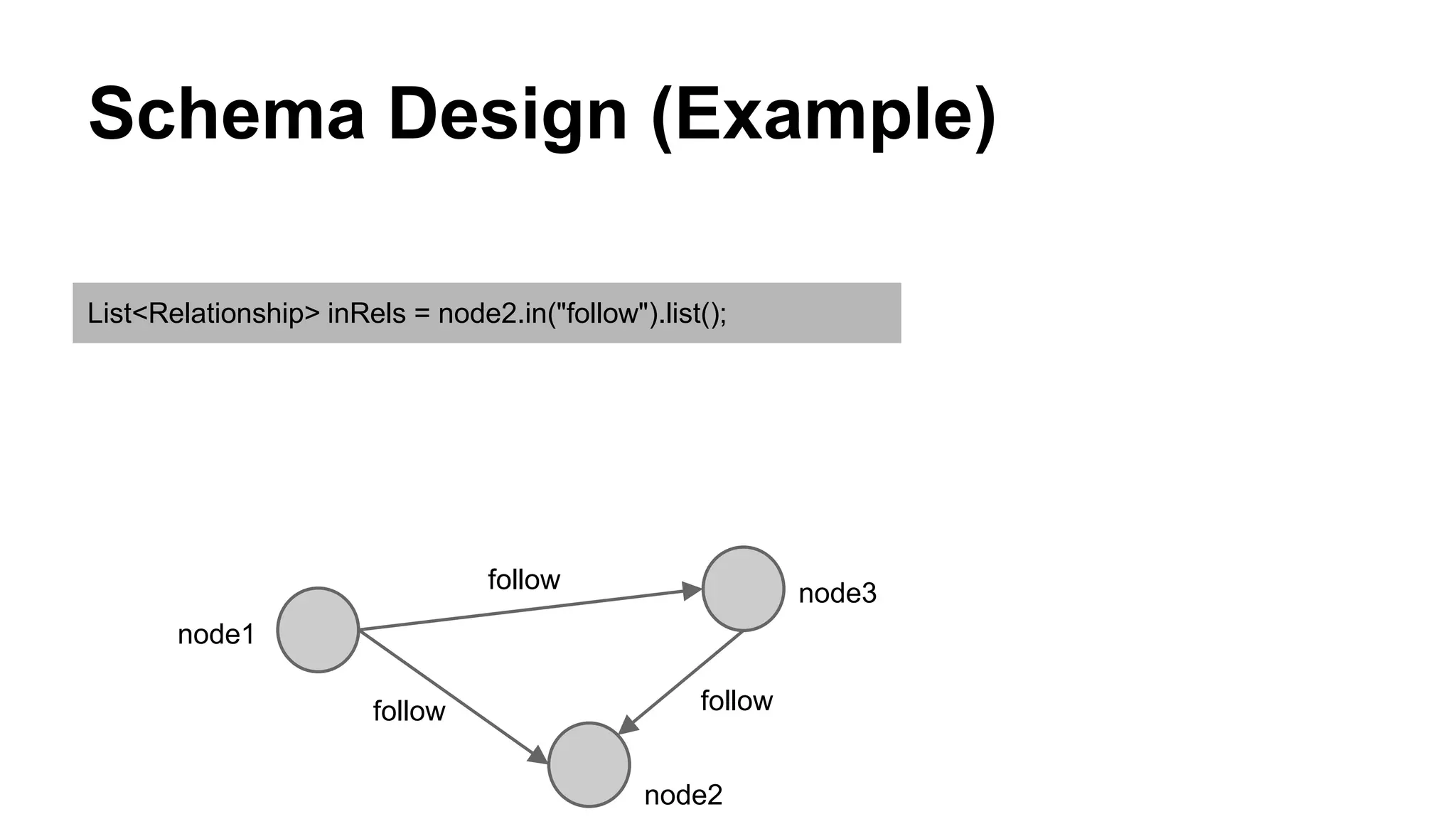
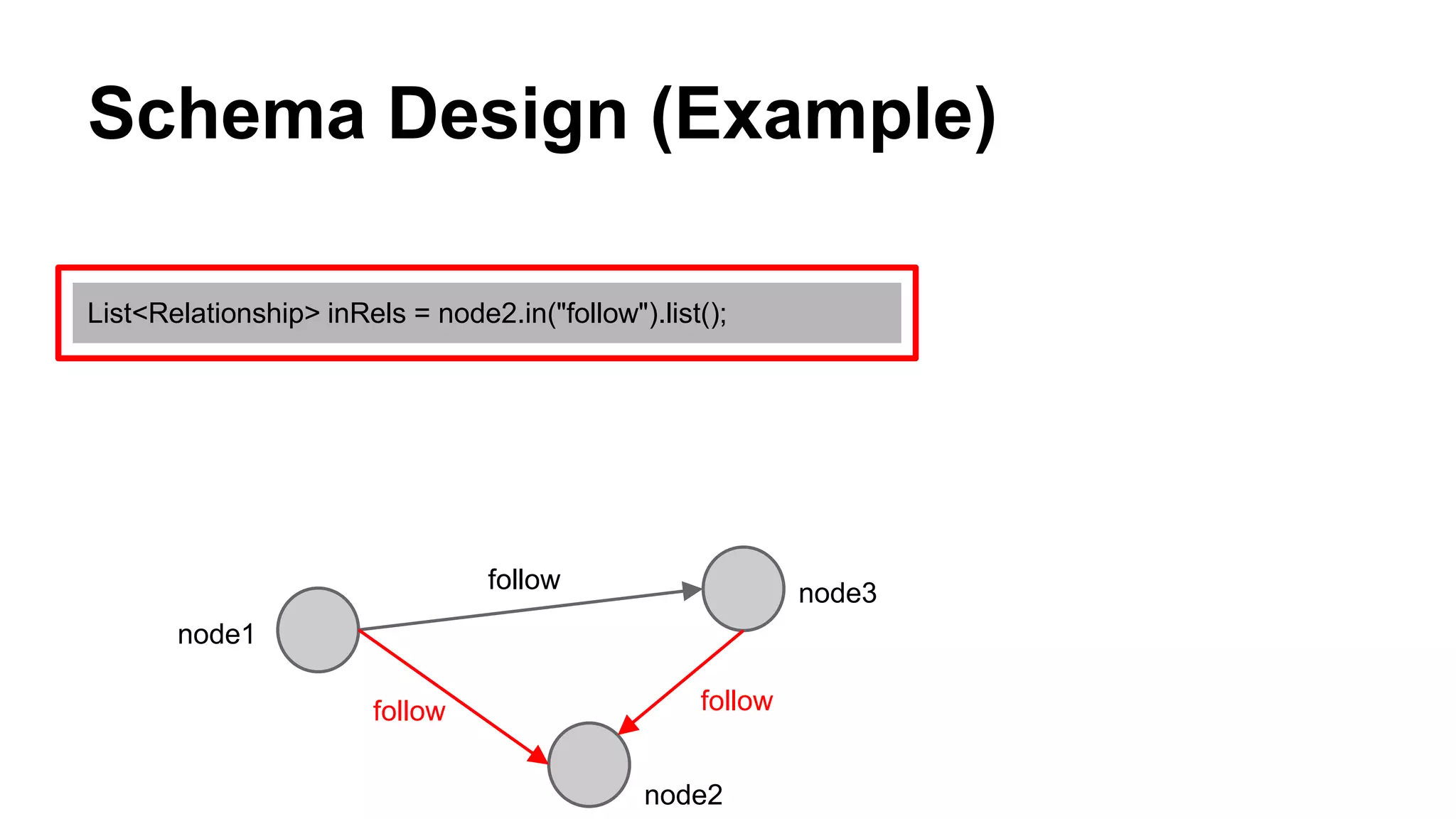
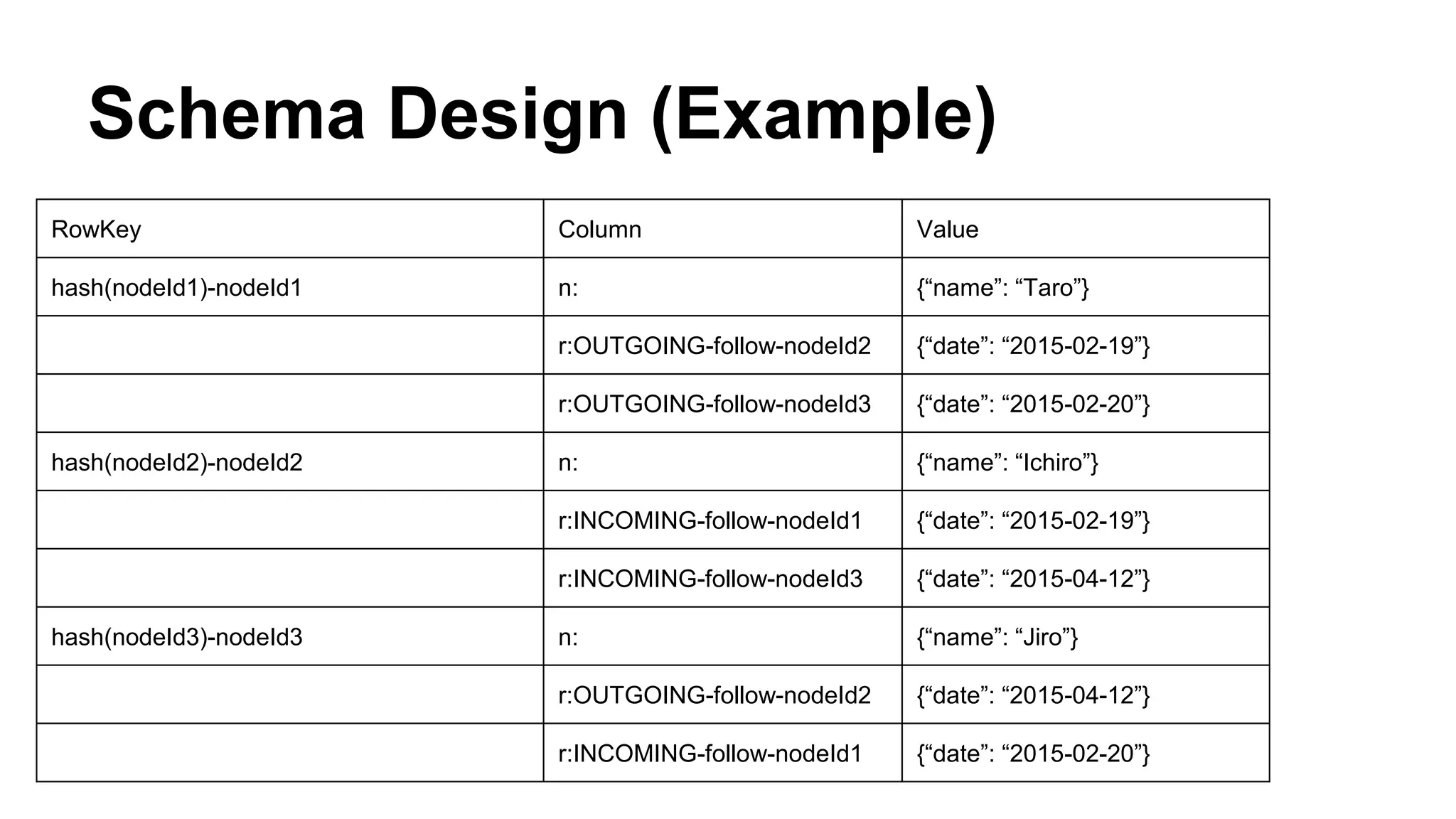

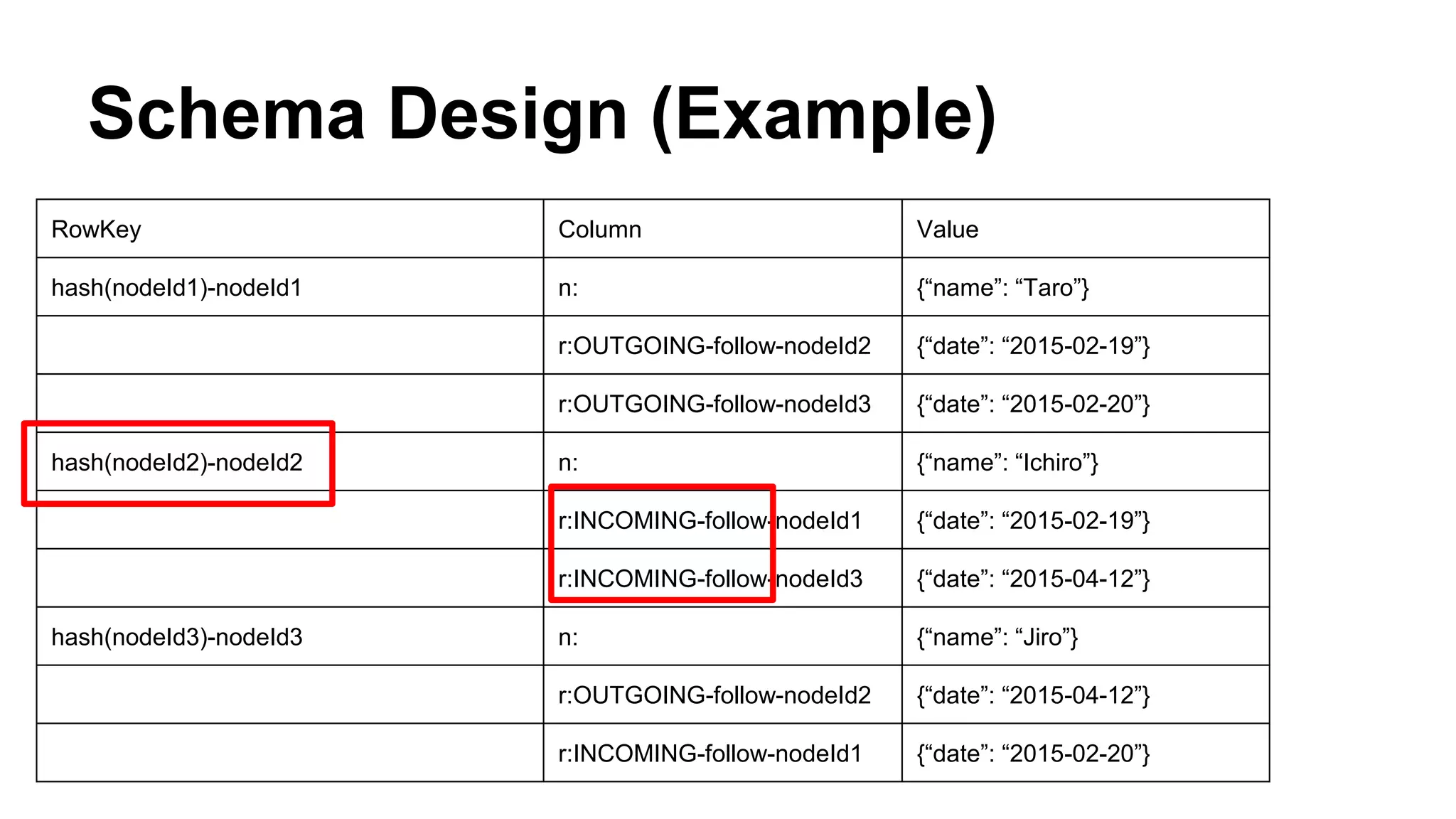
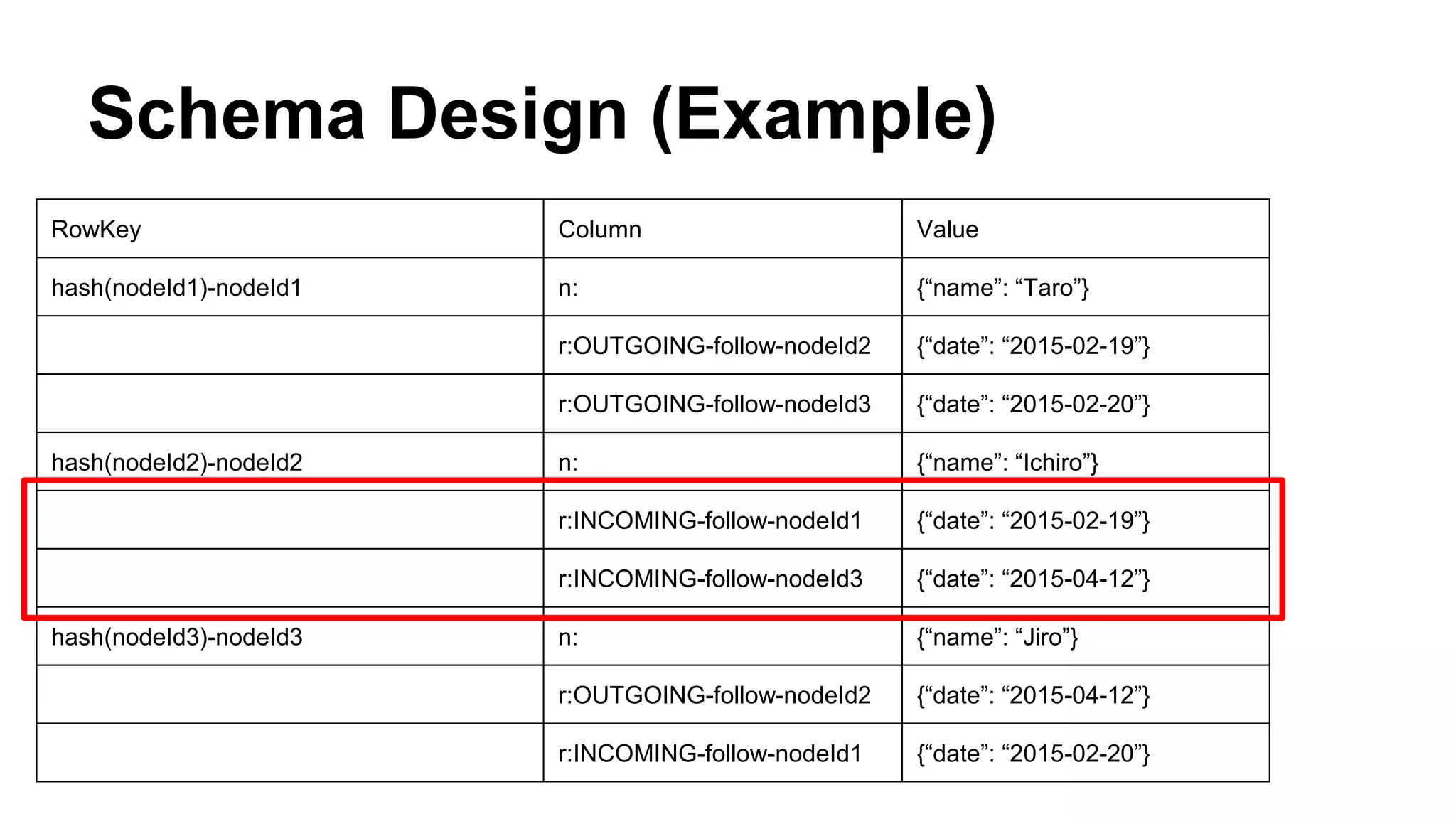





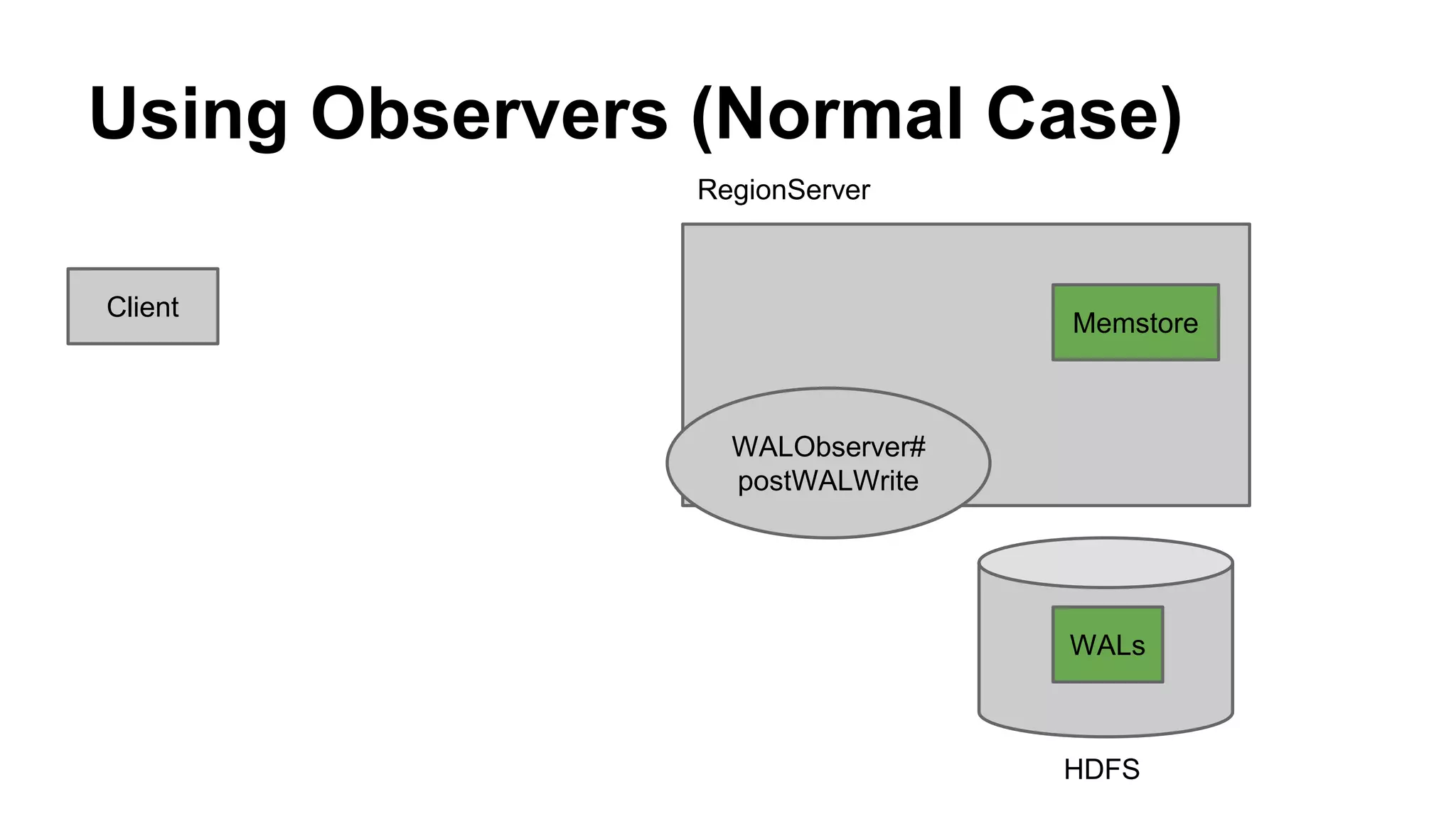
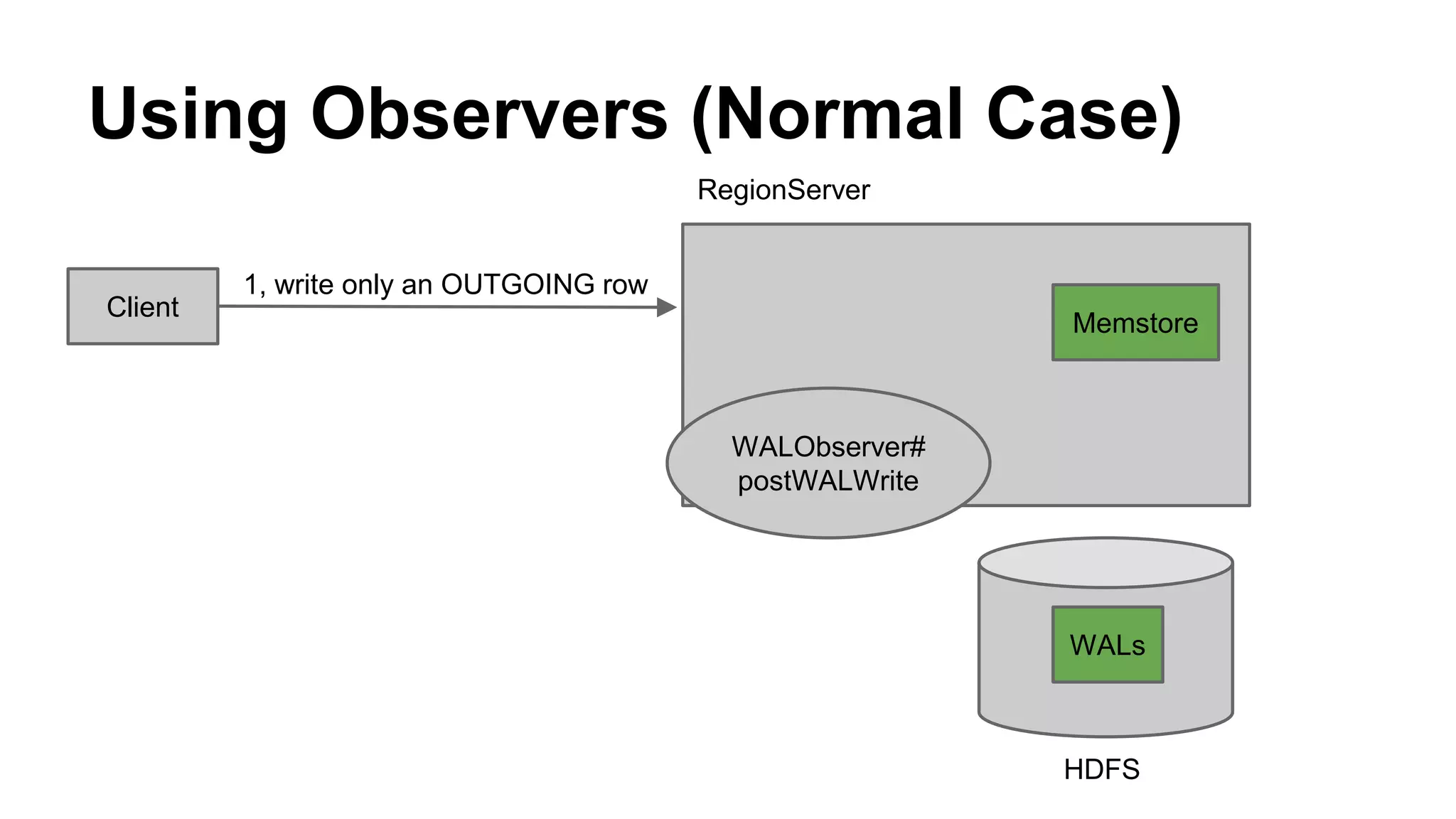
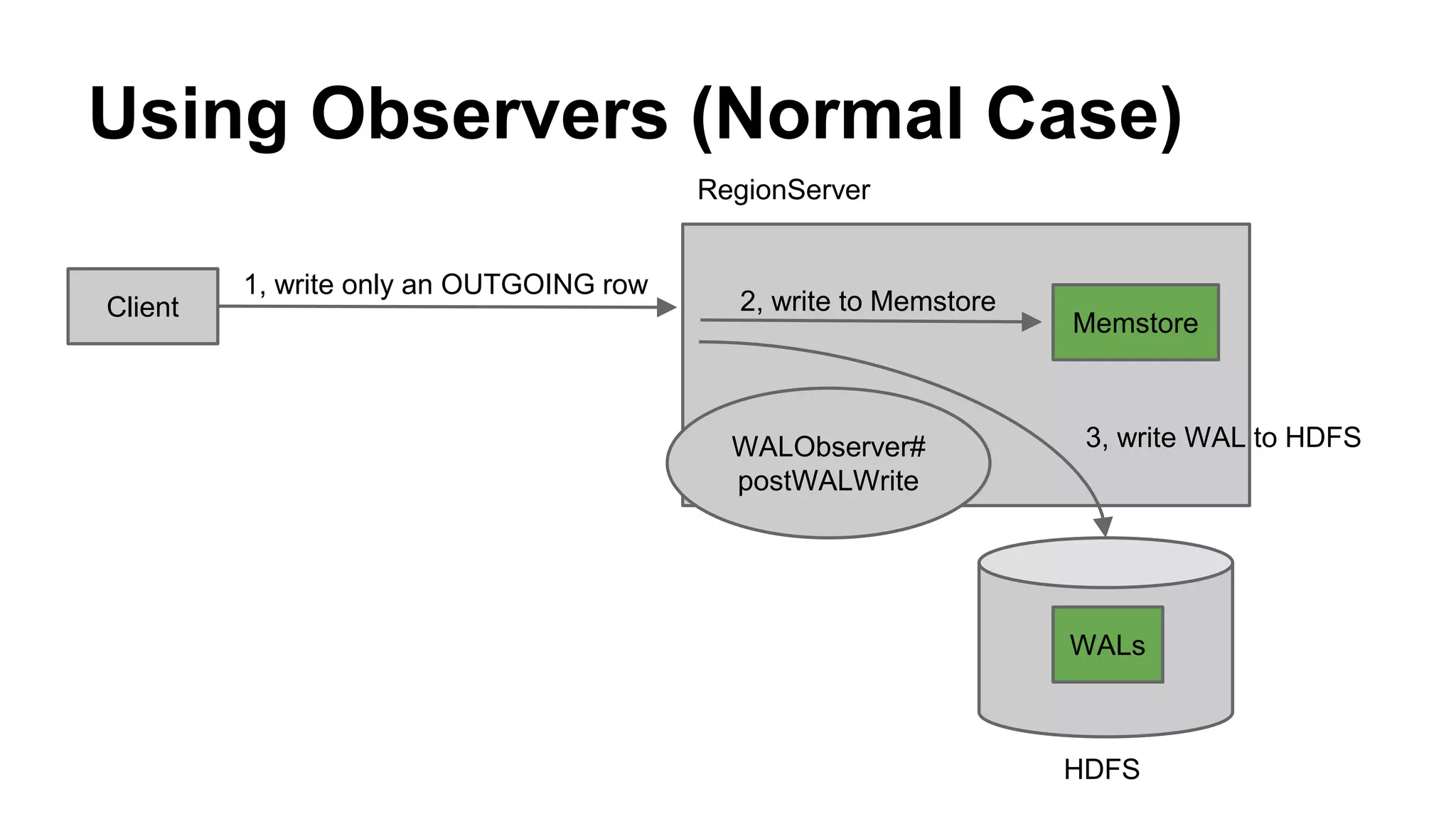
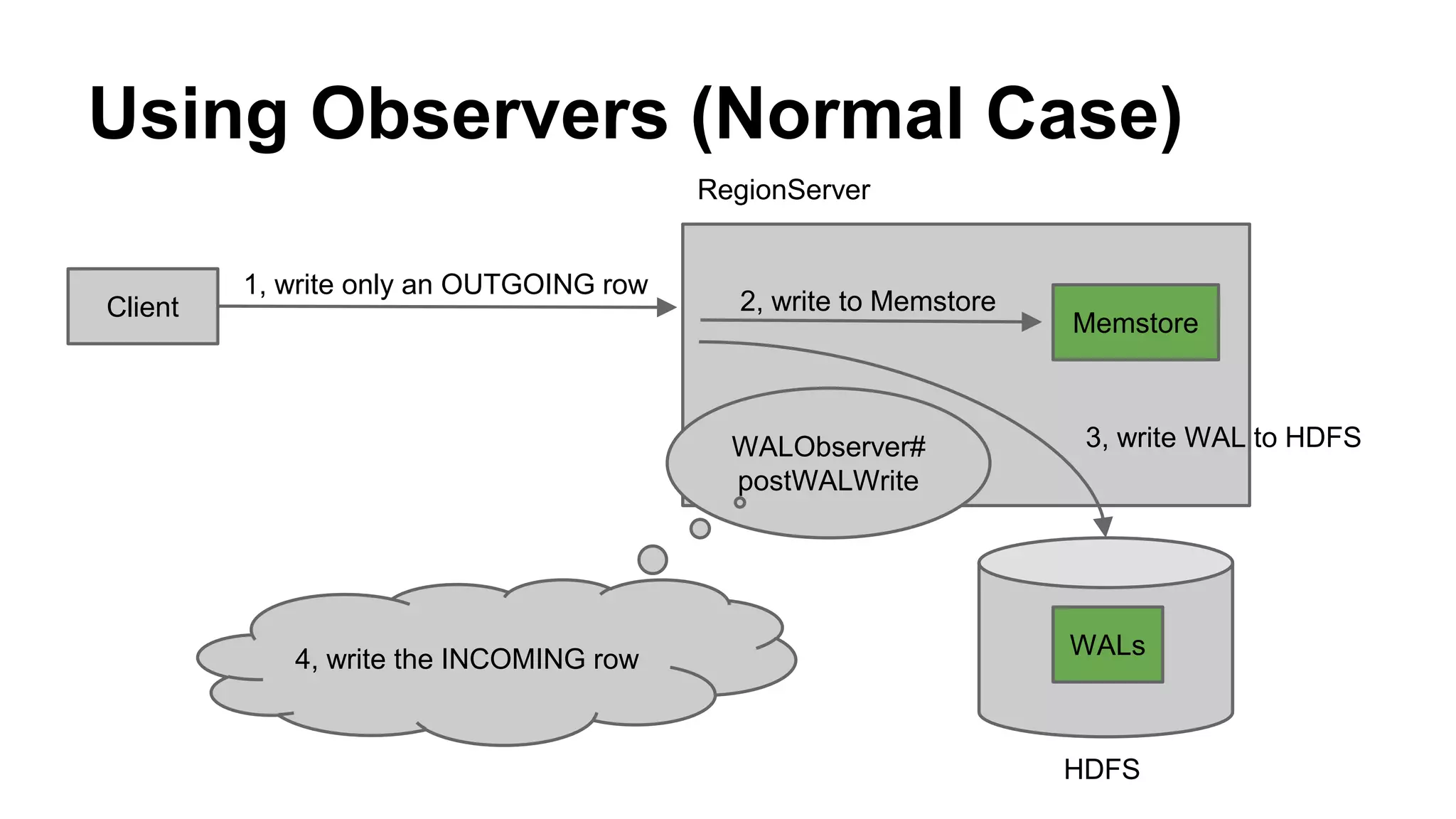
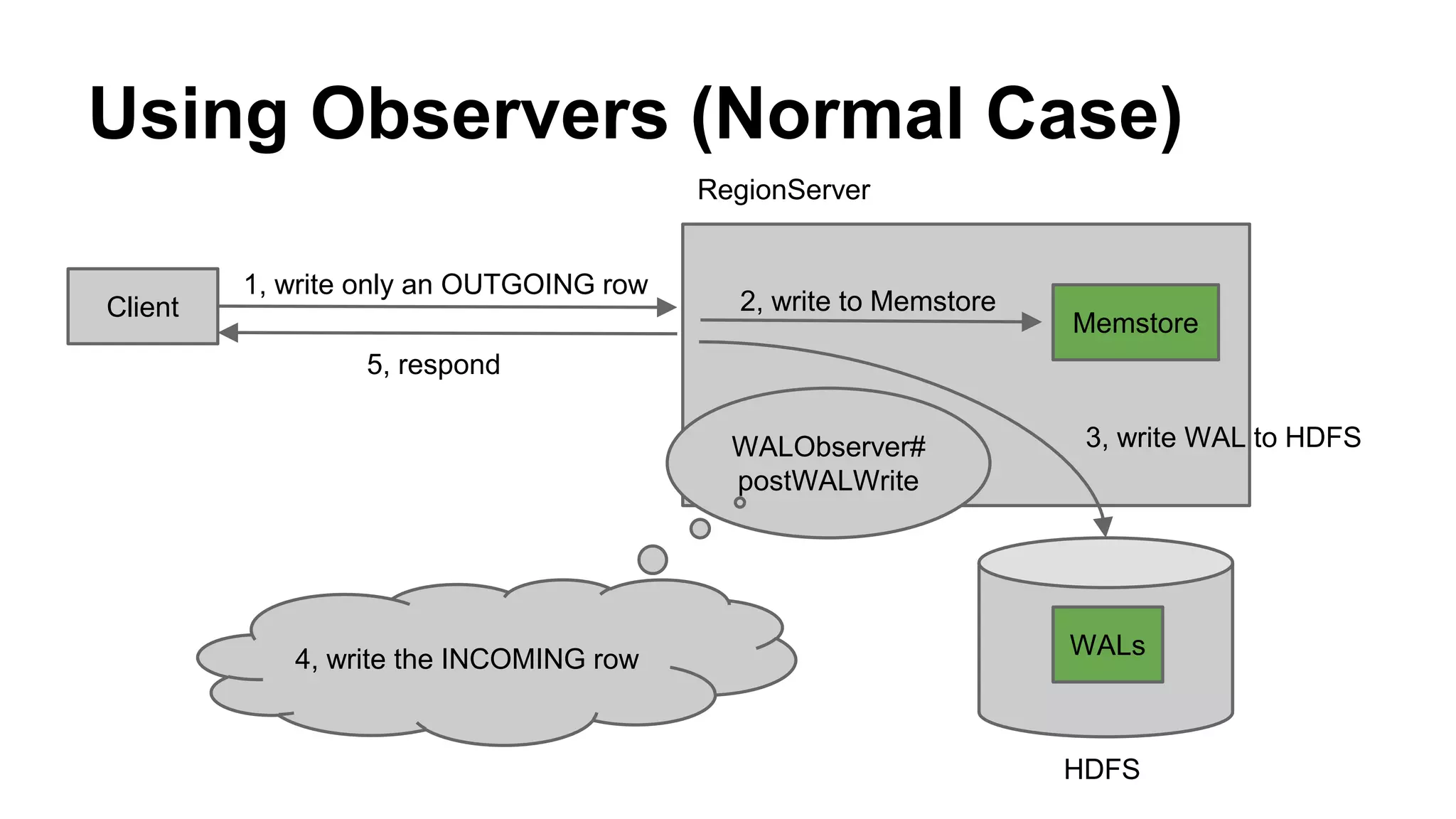
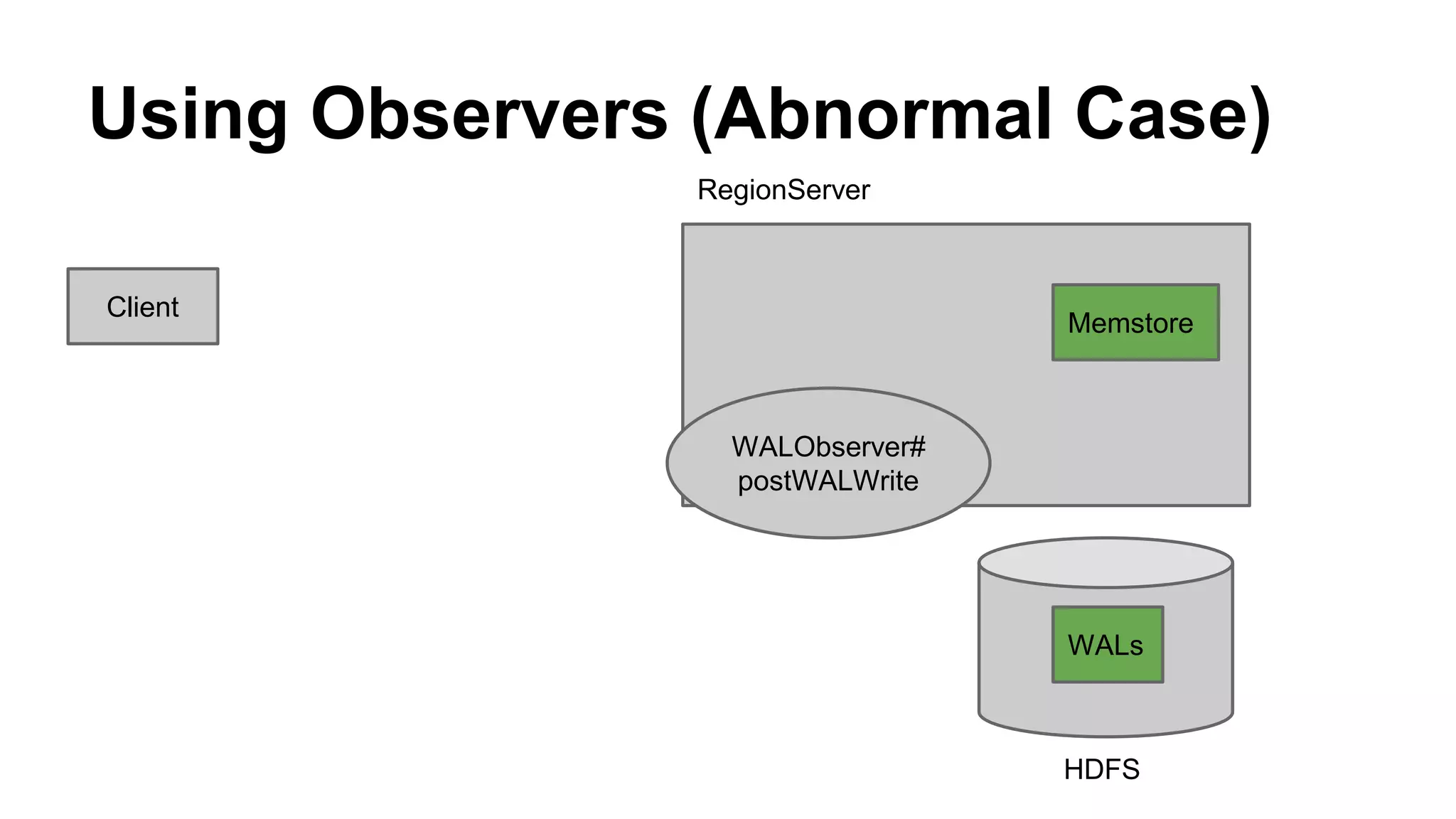
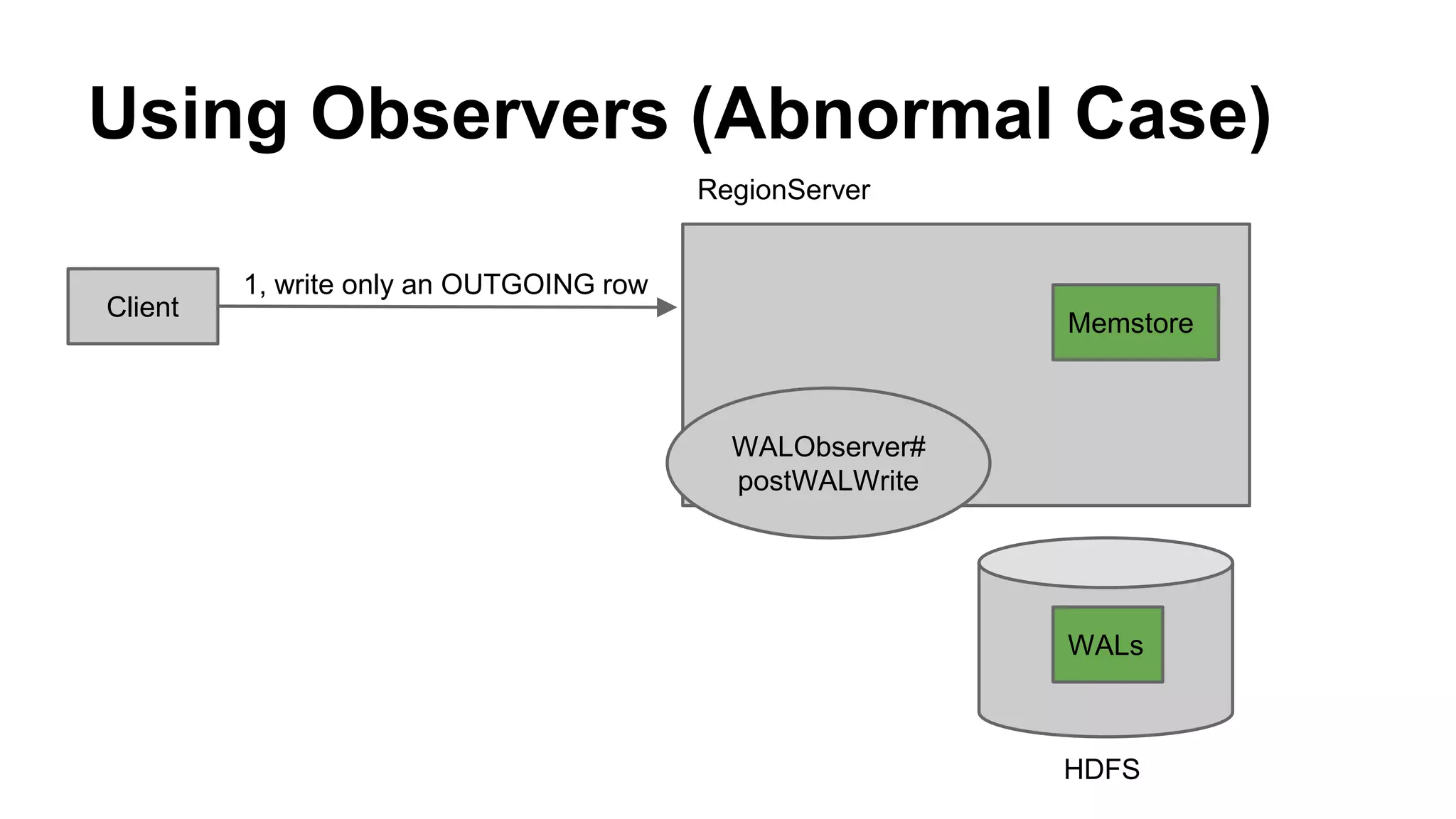
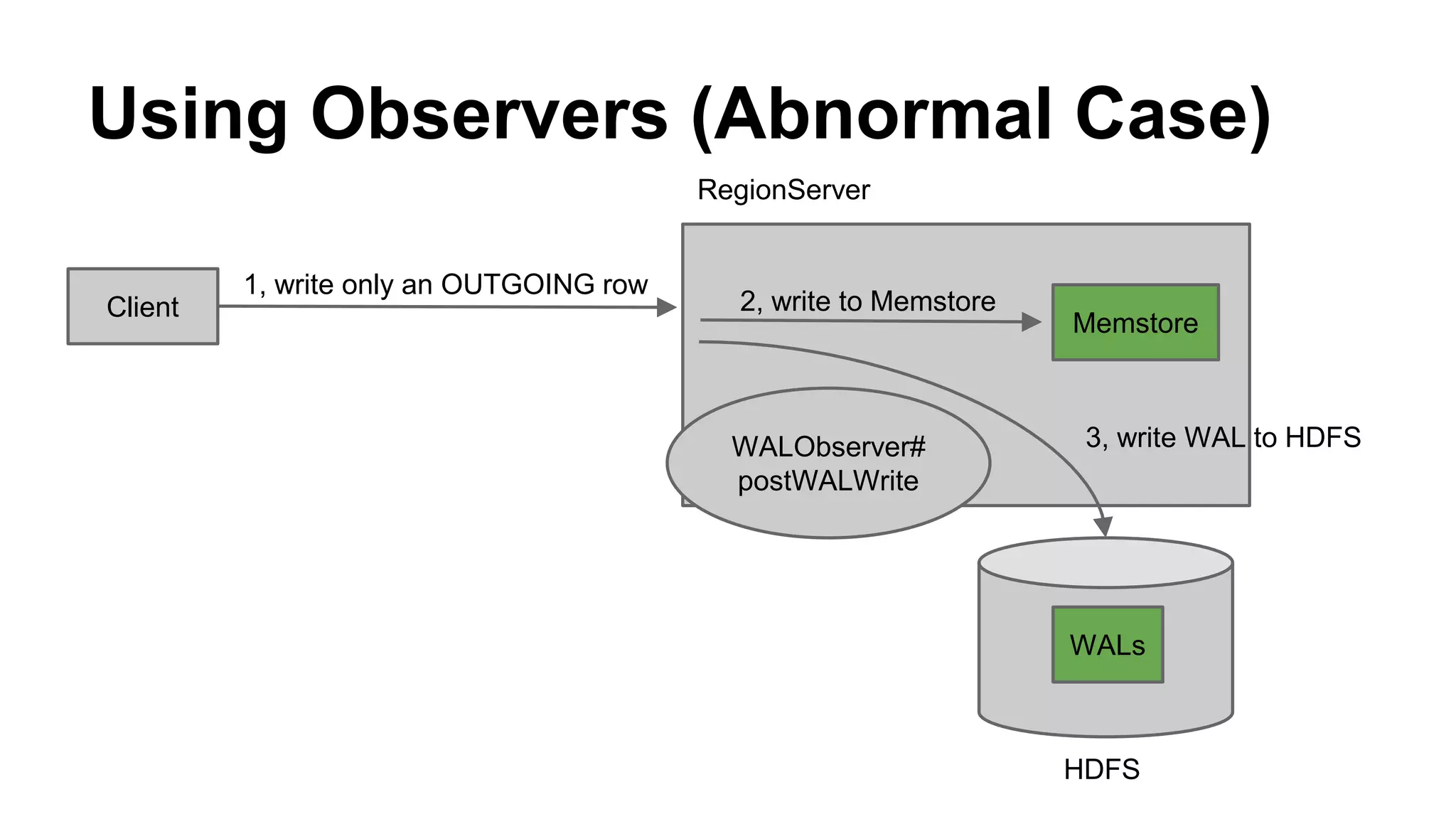
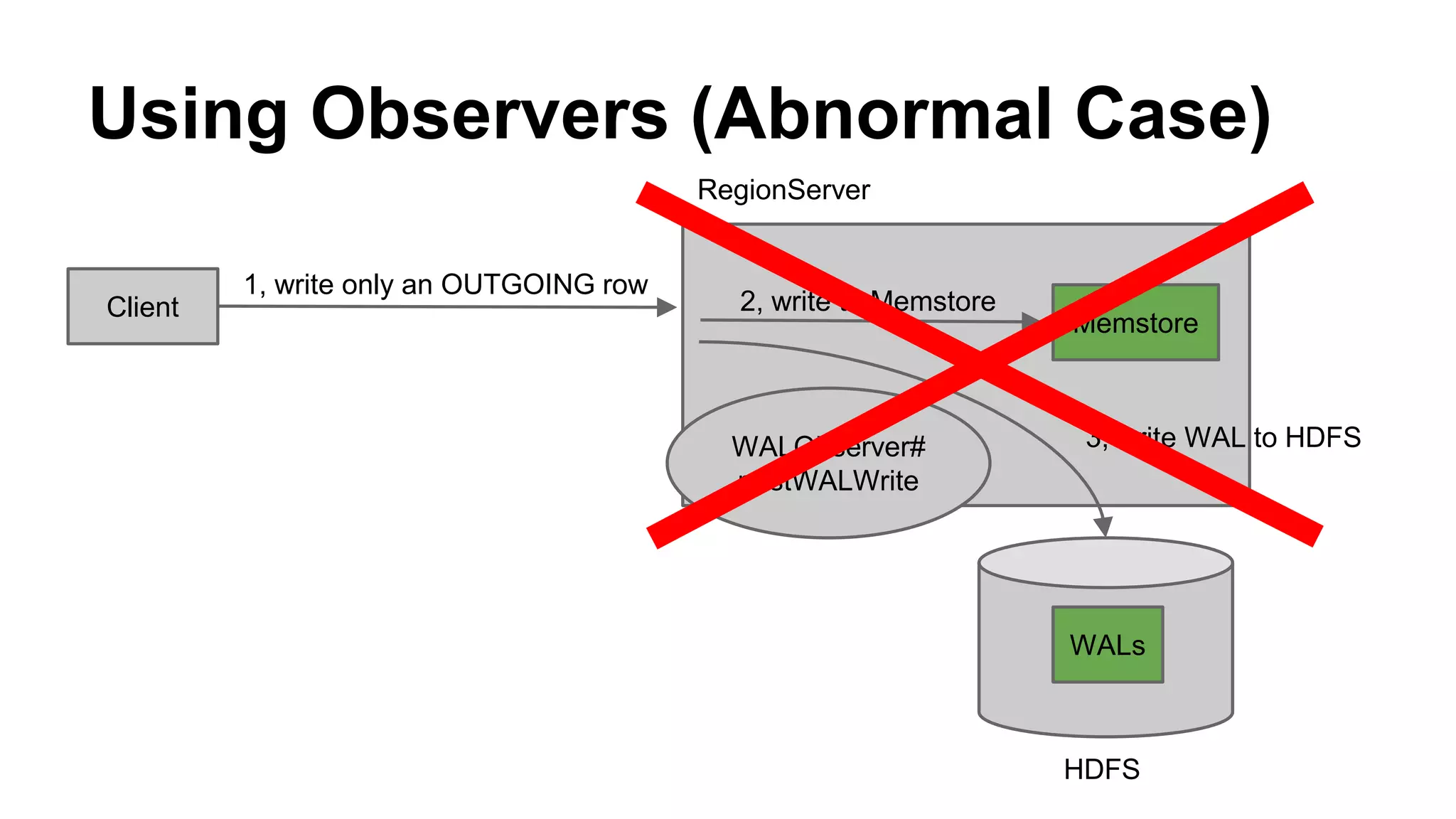
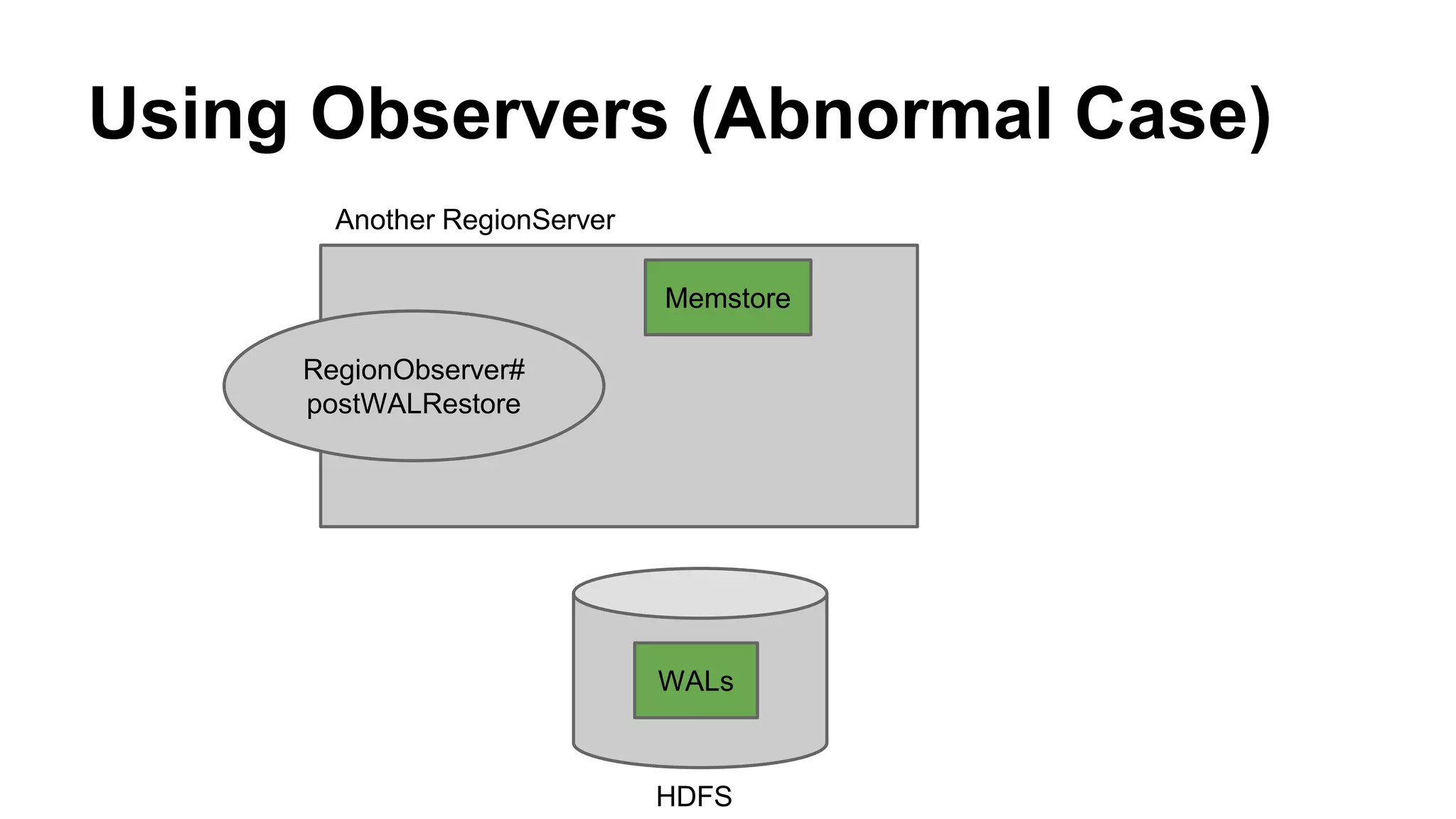
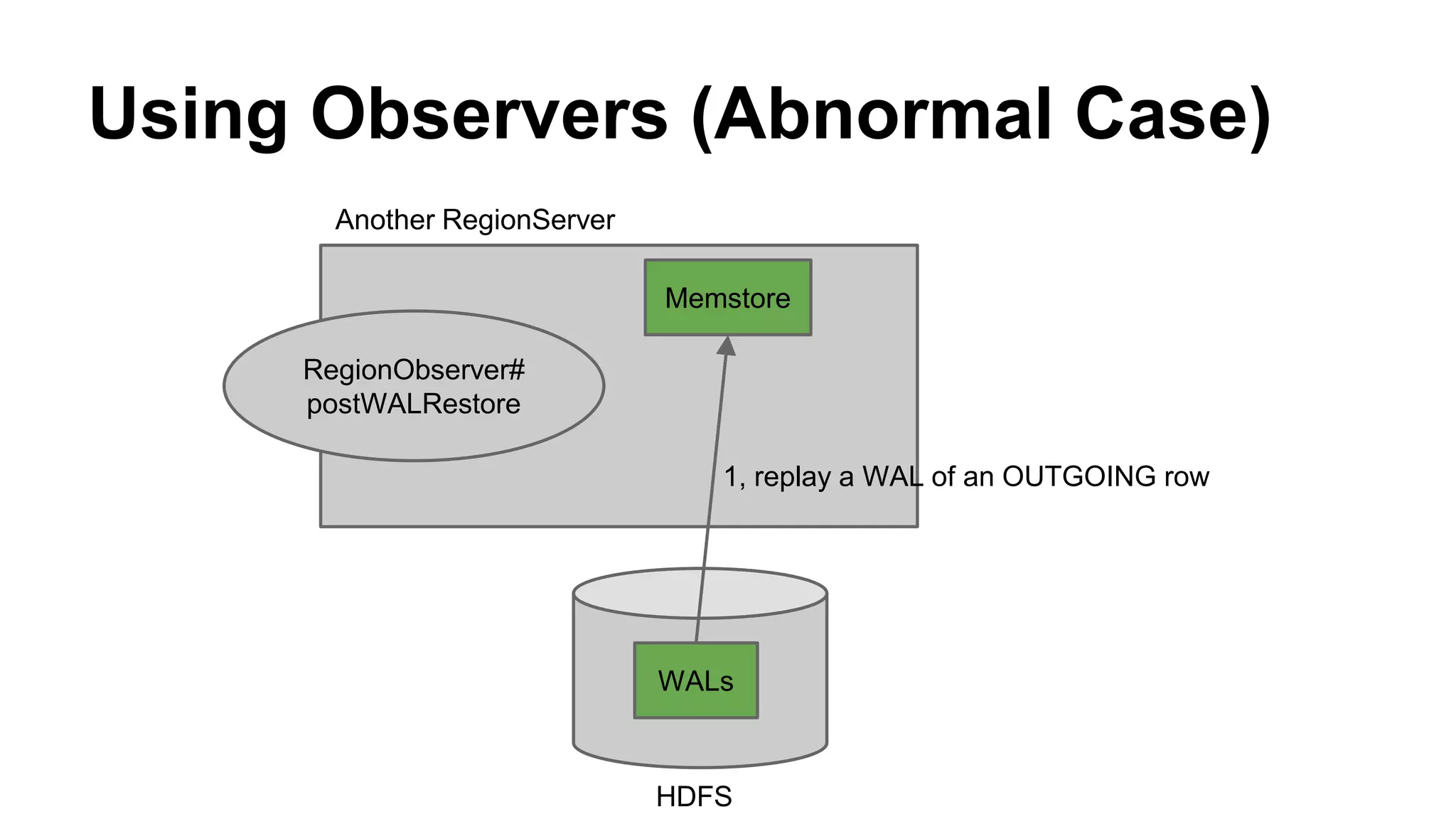
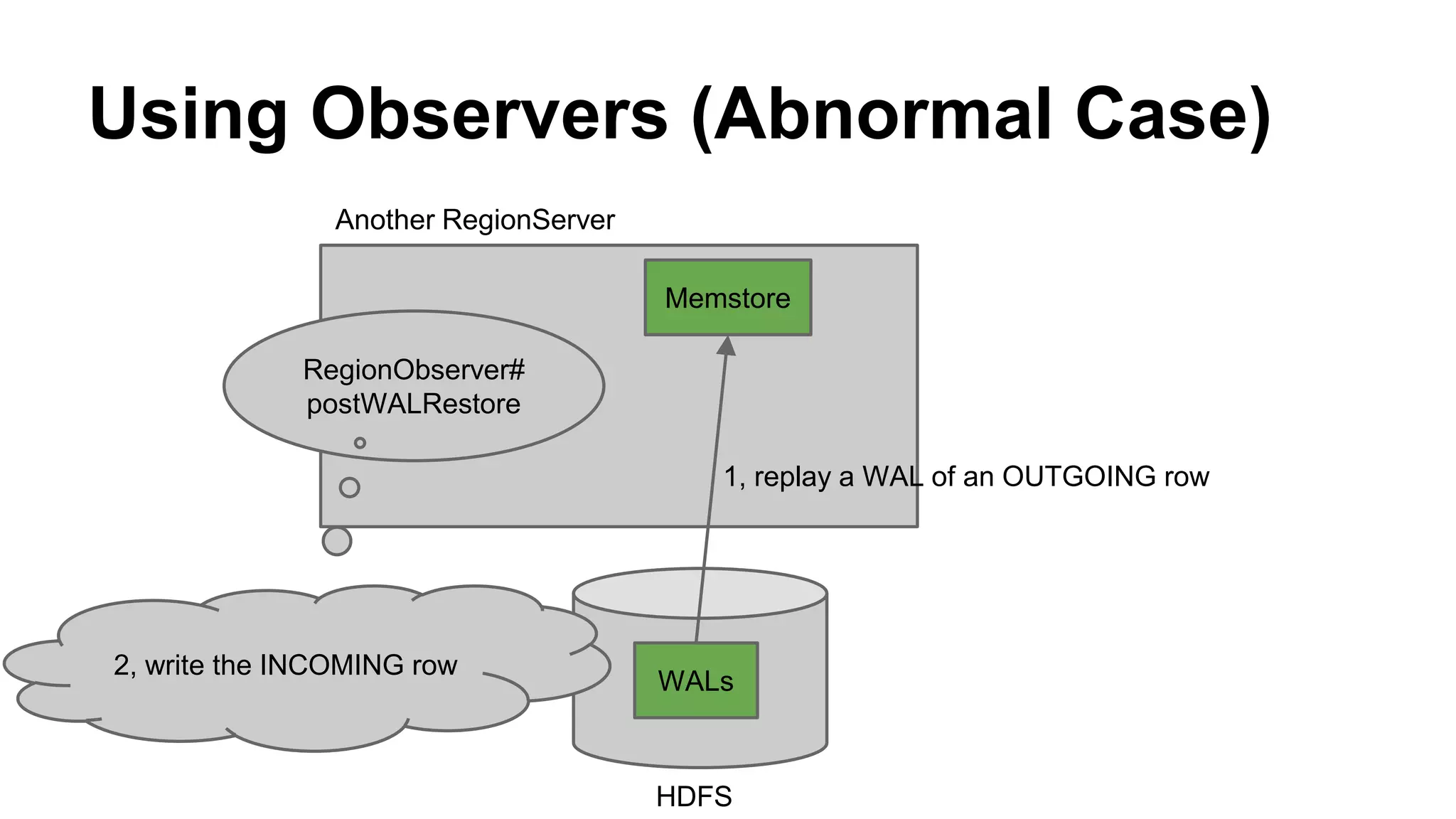



CyberAgent Inc., specializing in social networking and advertising, utilizes HBase for log analysis and social graph databases. The document details their HBase usage history, requirements for scalability and low latency, and specifics about the architecture and schema design for a graph database they developed. Key features of their HBase implementation include fault tolerance, data replication, and performance metrics.










































































































