Download as PDF, PPTX








![Index
● Values are dictionary encoded
{“USA” -> 1, “Canada” -> 2, “Mexico” -> 3, …}
● Bitmap for every dimension value (used by filters)
“USA” -> [0, 1, 0, 0, 1, 1, 0, 0, 0]
● Column values (used by aggregation queries)
[2, 1, 3, 15, 1, 1, 2, 8, 7]](https://image.slidesharecdn.com/druidisraelmeetup16mar2016-160316192750/85/Real-time-analytics-with-Druid-at-Appsflyer-12-320.jpg)









![Sample Query
~# curl -X POST -d@query.json -H "Content-Type: application/json" http://druidbroker:8082/druid/v2?pretty
{
"queryType": "groupBy",
"dataSource": "inappevents",
"granularity": "hour",
"dimensions": ["media_source", "campaign"],
"filter": {
"type": "and", "fields": [{ "type": "selector", "dimension": "app_id", "value": "com.comuto" },
{ "type": "selector", "dimension": "country", "value": "RU" }]
},
"aggregations": [
{ "type": "count", "name": "events_count" },
{ "type": "doubleSum", "name": "revenue", "fieldName": "monetary" }
],
"intervals": [ "2015-12-01T00:00:00.000/2016-01-01T00:00:00.000" ]
}](https://image.slidesharecdn.com/druidisraelmeetup16mar2016-160316192750/85/Real-time-analytics-with-Druid-at-Appsflyer-22-320.jpg)


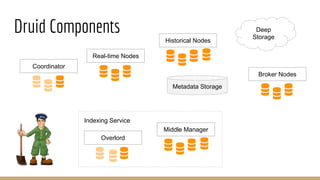



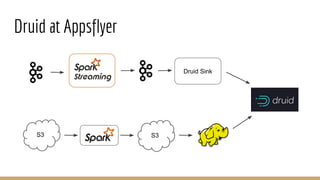






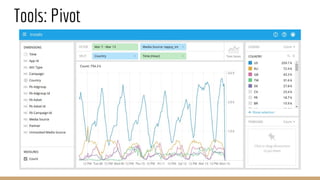
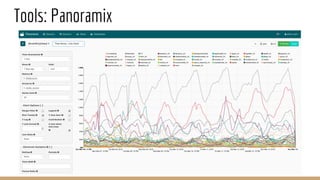


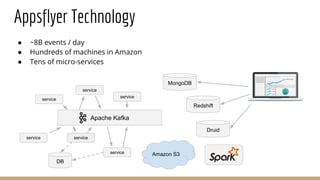
The document discusses the use of Druid, a real-time analytics platform employed at AppsFlyer for processing large data events efficiently. It outlines Druid's architecture, including its storage optimization, ingestion methods, and various components, highlighting its capabilities for analytics such as querying and aggregations. It also addresses considerations for when to use Druid and includes performance tips and configurations for production deployment.





















































































