Downloaded 57 times




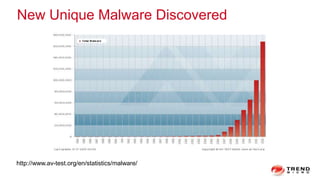
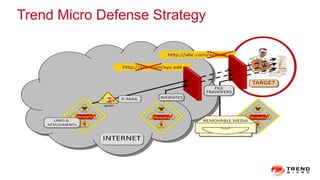
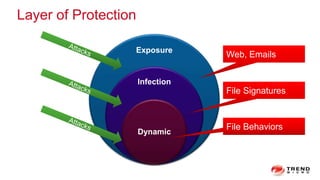

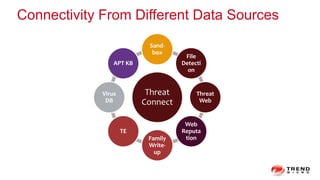
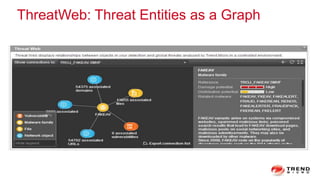
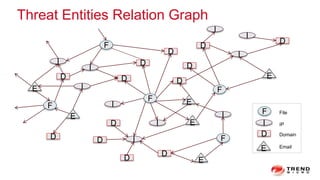
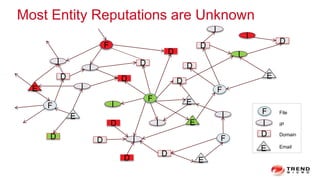
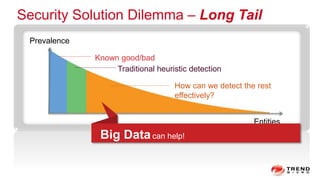

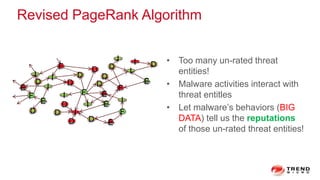





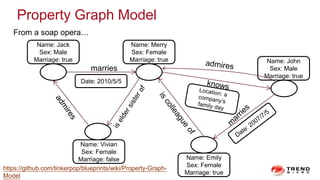





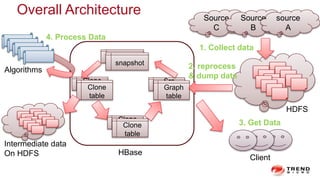
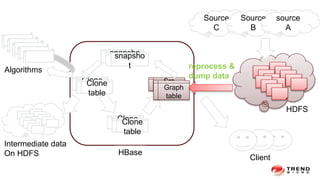


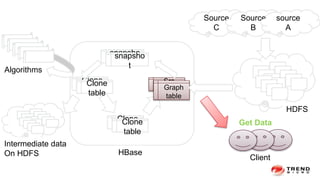




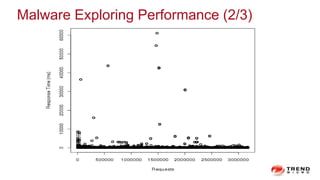
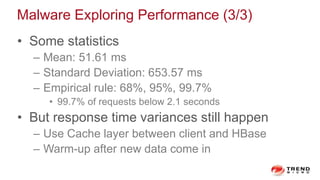
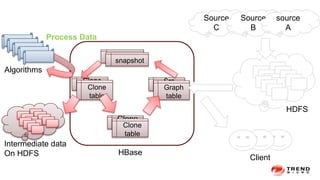

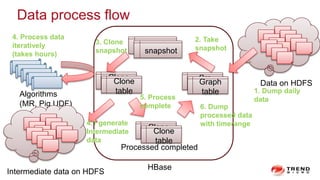

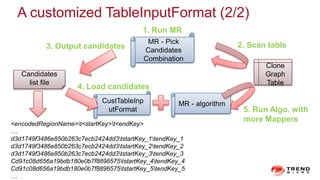








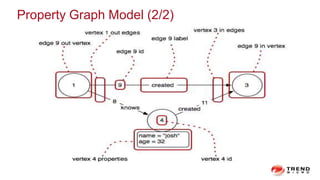

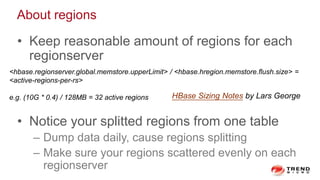

The document discusses a graph service designed for global web entities traversal and reputation evaluation using HBase. It outlines the challenges of threat entity connectivity, the revised PageRank algorithm for assessing unknown reputations based on malware behaviors, and the architecture for storing and processing graph data. Additionally, it covers the implementation details, performance metrics, and the significance of using big data in enhancing security measures against evolving cyber threats.











































































































