Downloaded 48 times











![Multidimensional
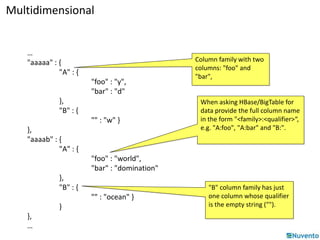
• Labeled tables of rows X columns X timestamp
– Cells addressed by row/column/timestamp
– As (perverse) java declaration:
SortedMap<byte [], SortedMap<byte [],
List<Cell>>>> hbase = new TreeMap<ditto>(new RawByteComparator());
• Row keys uninterpreted byte arrays: E.g. an URL
– Rows are ordered by Comparator (Default: byte-order)
– Row updates are atomic; even if hundreds of columns
• Columns grouped into column-families
– Columns have column-family prefix and then qualifier
• E.g. webpage:mimetype, webpage:language
– Column-family 'printable', qualifier arbitrary bytes
– Column-families in table schema but not qualifiers](https://image.slidesharecdn.com/01-hbase-141206232229-conversion-gate02/85/01-hbase-12-320.jpg)

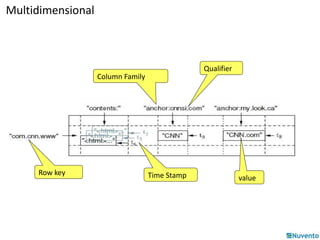







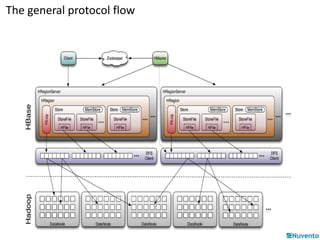



![Buffer-Flush-Compact (minor)
Region
Memstore
HLog
(Append only WAL on
HDFS)
(Sequence file)
(One per region)
HFile on
HDFS
Compact
HFile on
HDFS
StoreFile
HFile on
HDFS
Buffer
Read
Flush
HFile: immutable sorted map (byte[] byte[])
(row, column, timestamp cell value)](https://image.slidesharecdn.com/01-hbase-141206232229-conversion-gate02/85/01-hbase-30-320.jpg)

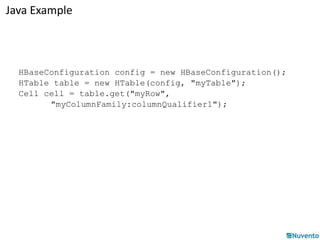








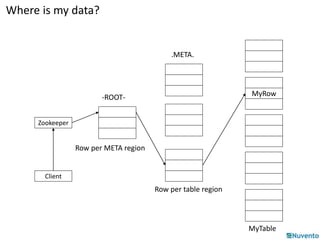
![Using HBase API
HTable: Used for communication with a single HBase table.
new HTable(HBaseConfiguration conf, String tableName)
• Ex:
HTable table = new HTable (conf, Bytes.toBytes ( tablename ));
ResultScanner scanner = table.getScanner ( family );
Put: Used to perform Put operations for a single row.
new Put(byte[] row)
new Put(byte[] row, RowLock rowLock)
• Ex:
HTable table = new HTable (conf, Bytes.toBytes ( tablename ));
Put p = new Put ( brow );
p.add (family, qualifier, value);
table.put ( p );](https://image.slidesharecdn.com/01-hbase-141206232229-conversion-gate02/85/01-hbase-46-320.jpg)
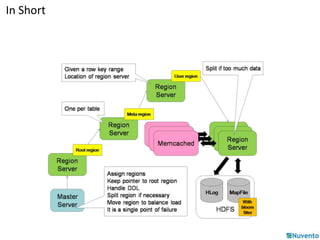
![Using HBase API
Get: Used to perform Get operations on a single row.
new Get (byte[] row)
new Get (byte[] row, RowLock rowLock)
• Ex:
HTable table = new HTable(conf, Bytes.toBytes(tablename));
Get g = new Get(Bytes.toBytes(row));
Result: Single row result of a Get or Scan query.
new Result()
• Ex:
HTable table = new HTable(conf, Bytes.toBytes(tablename));
Get g = new Get(Bytes.toBytes(row));
Result rowResult = table.get(g);
Bytes[] ret = rowResult.getValue( (family + ":"+ column ) );](https://image.slidesharecdn.com/01-hbase-141206232229-conversion-gate02/85/01-hbase-47-320.jpg)
![Using HBase API
Scanner
• All operations are identical to Get
– Rather than specifying a single row, an optional startRow and stopRow
may be defined.
• If rows are not specified, the Scanner will iterate over all rows.
– = new Scan ()
– = new Scan (byte[] startRow, byte[] stopRow)
– = new Scan (byte[] startRow, Filter filter)](https://image.slidesharecdn.com/01-hbase-141206232229-conversion-gate02/85/01-hbase-48-320.jpg)














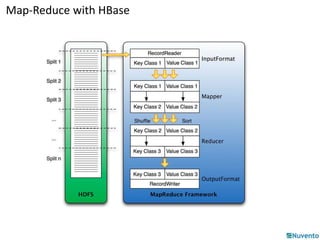
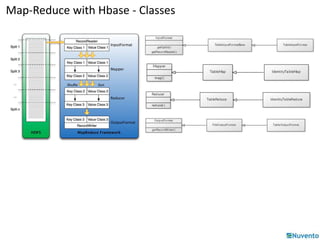
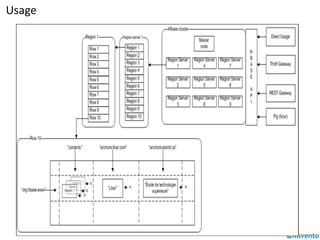
HBase is a distributed, column-oriented database built on top of HDFS that can handle large datasets across a cluster. It uses a map-reduce model where data is stored as multidimensional sorted maps across nodes. Data is first written to a write-ahead log and memory, then flushed to disk files and compacted for efficiency. Client applications access HBase programmatically through APIs rather than SQL. Map-reduce jobs on HBase use input, mapper, reducer, and output classes to process table data in parallel across regions.

























































































