Downloaded 196 times


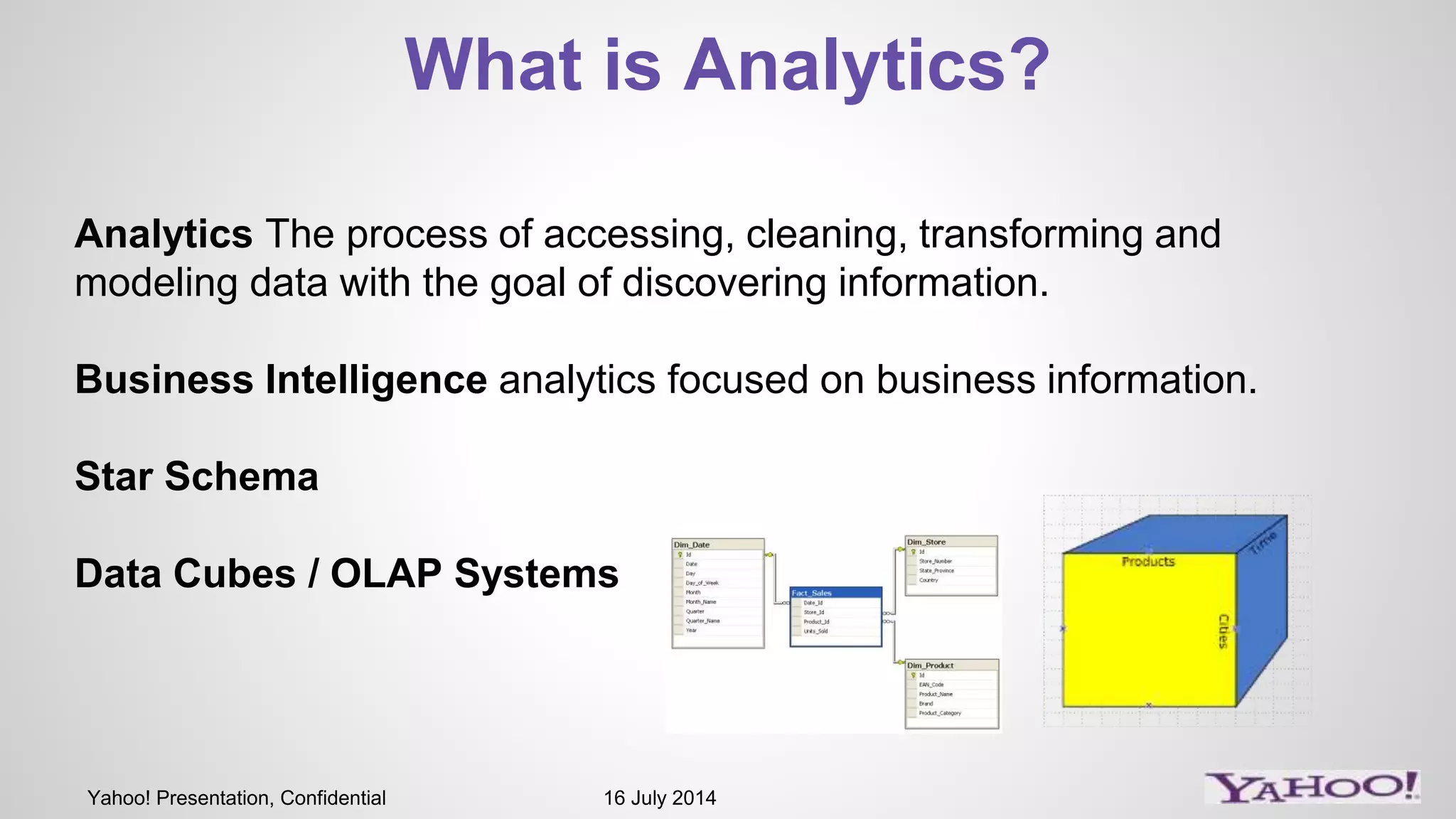
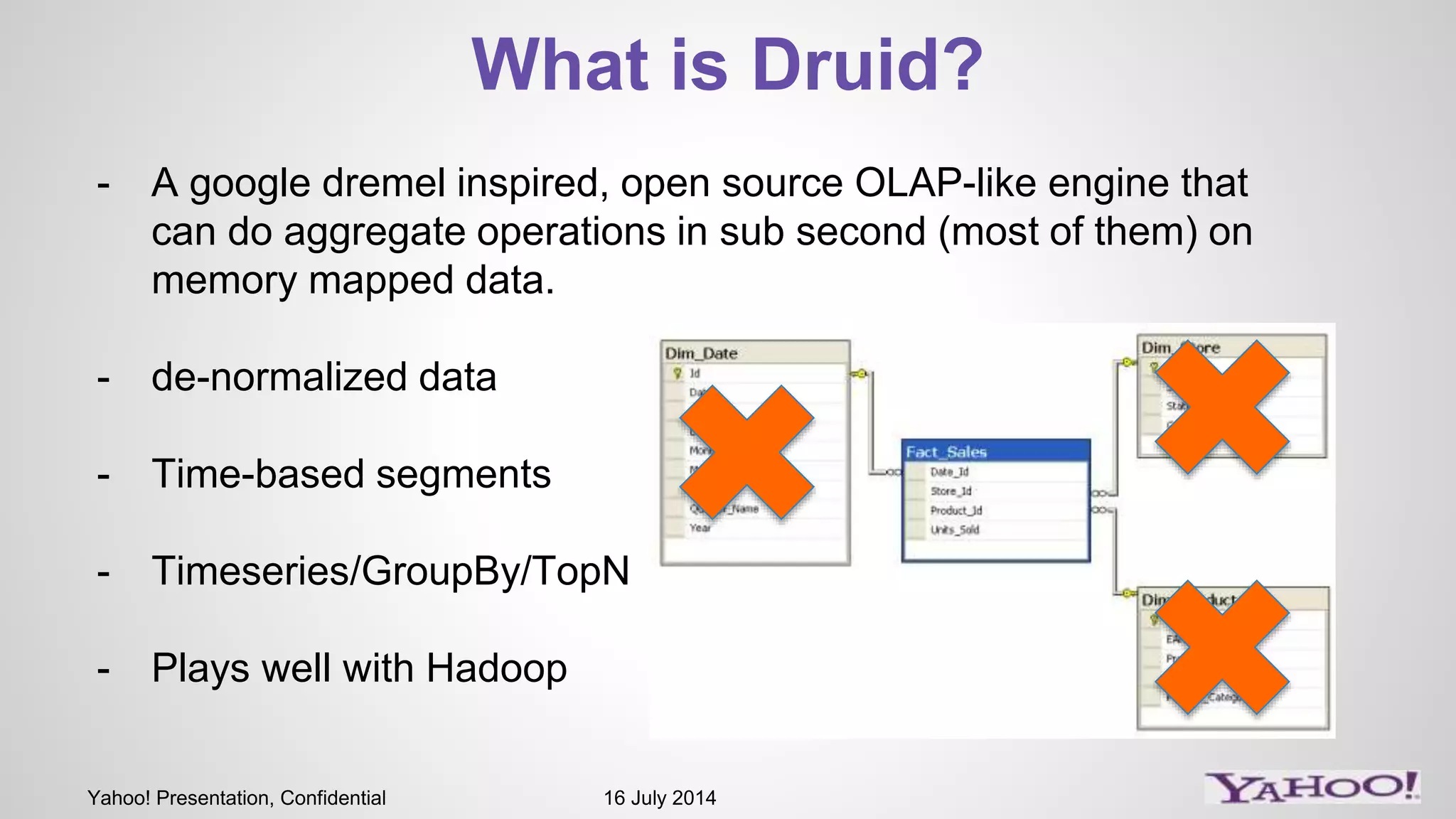
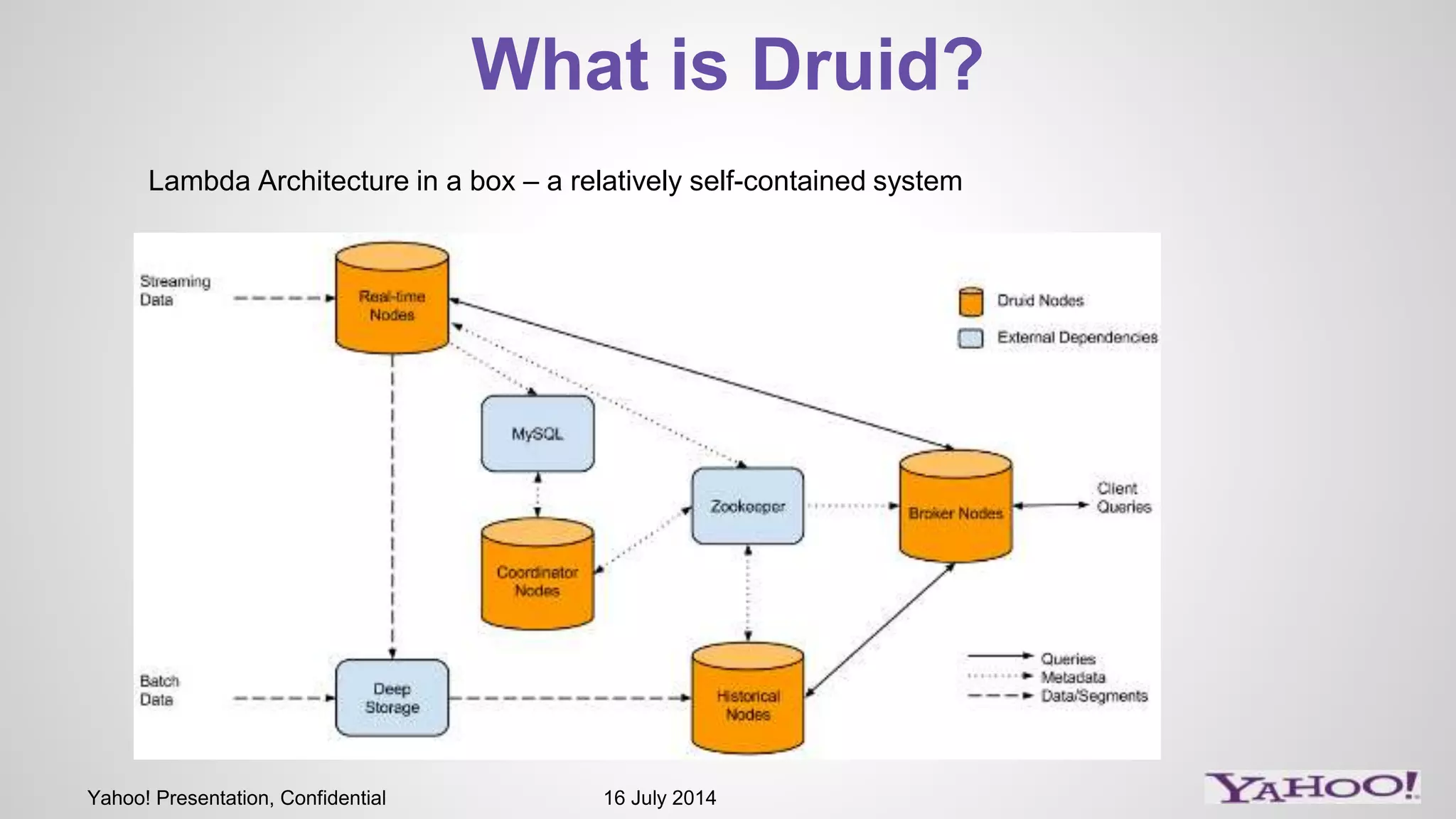


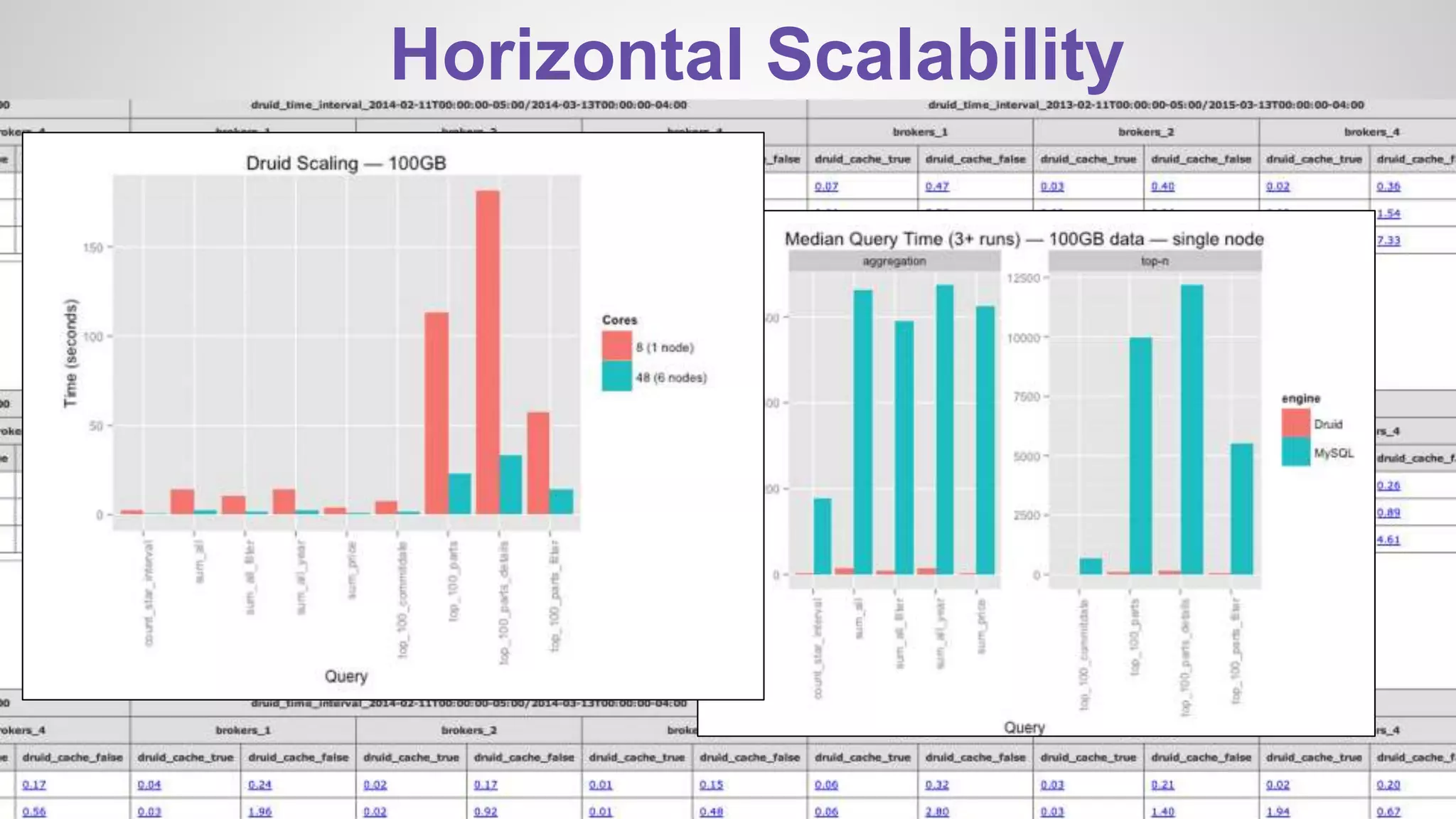

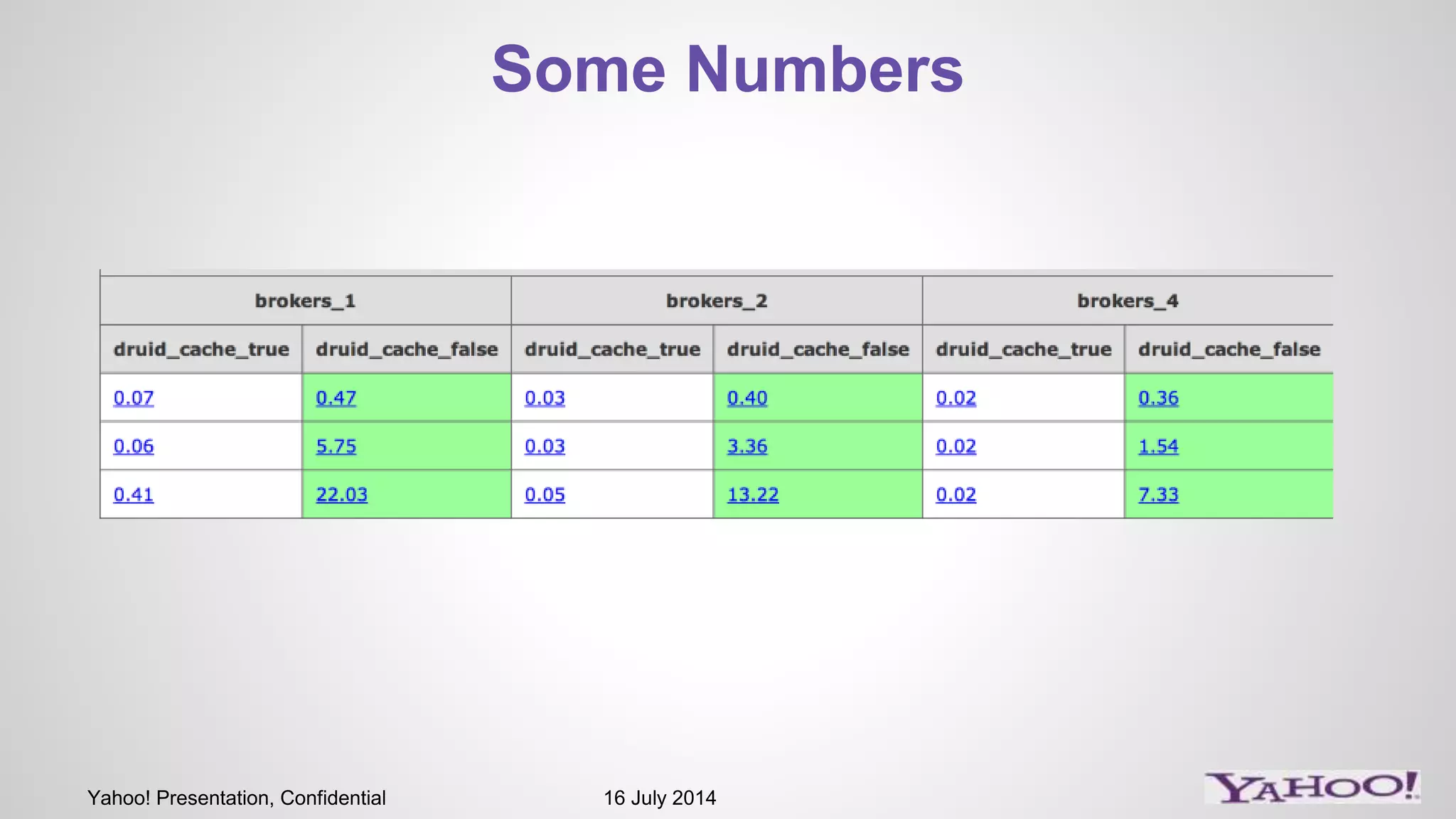

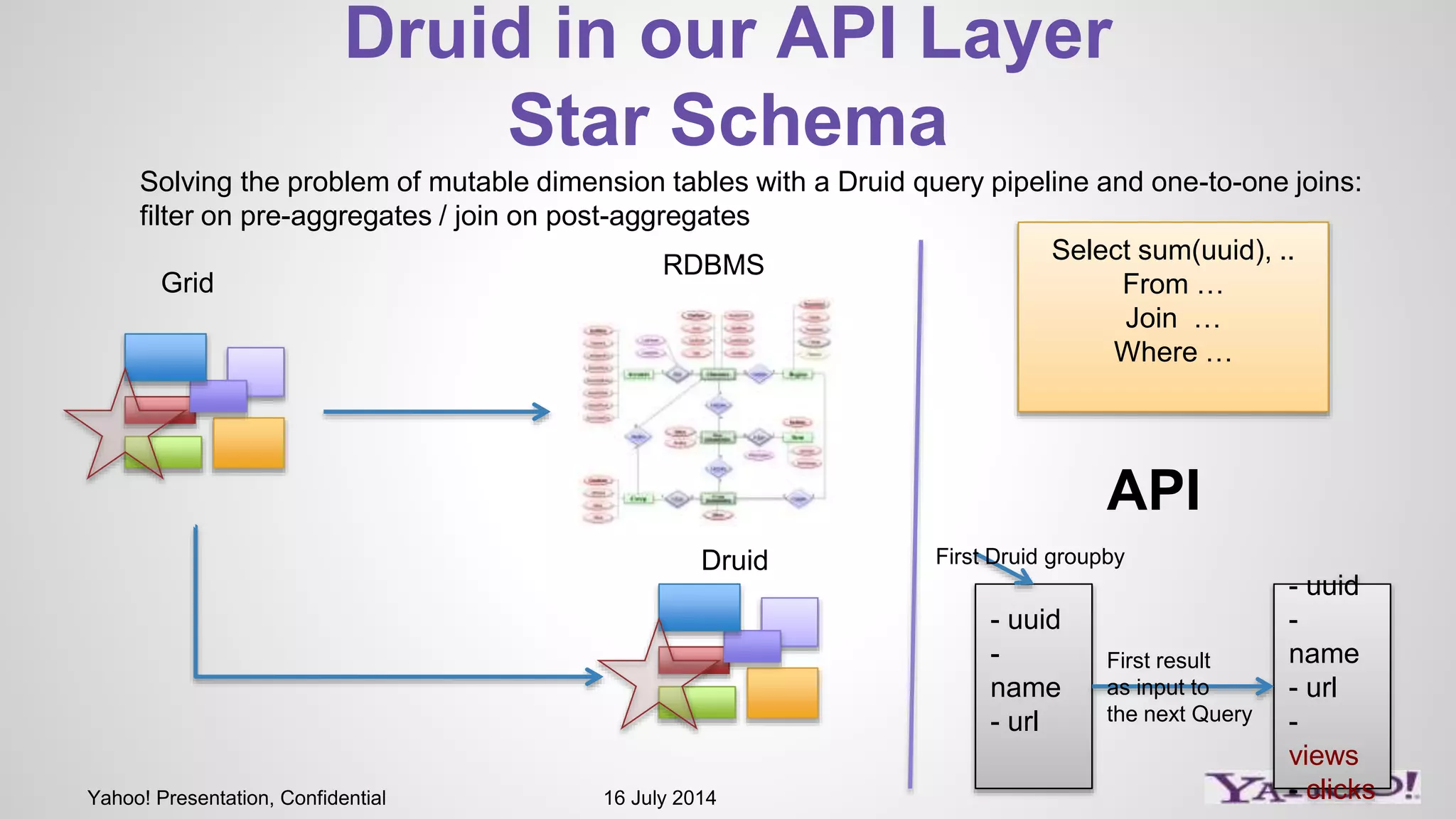
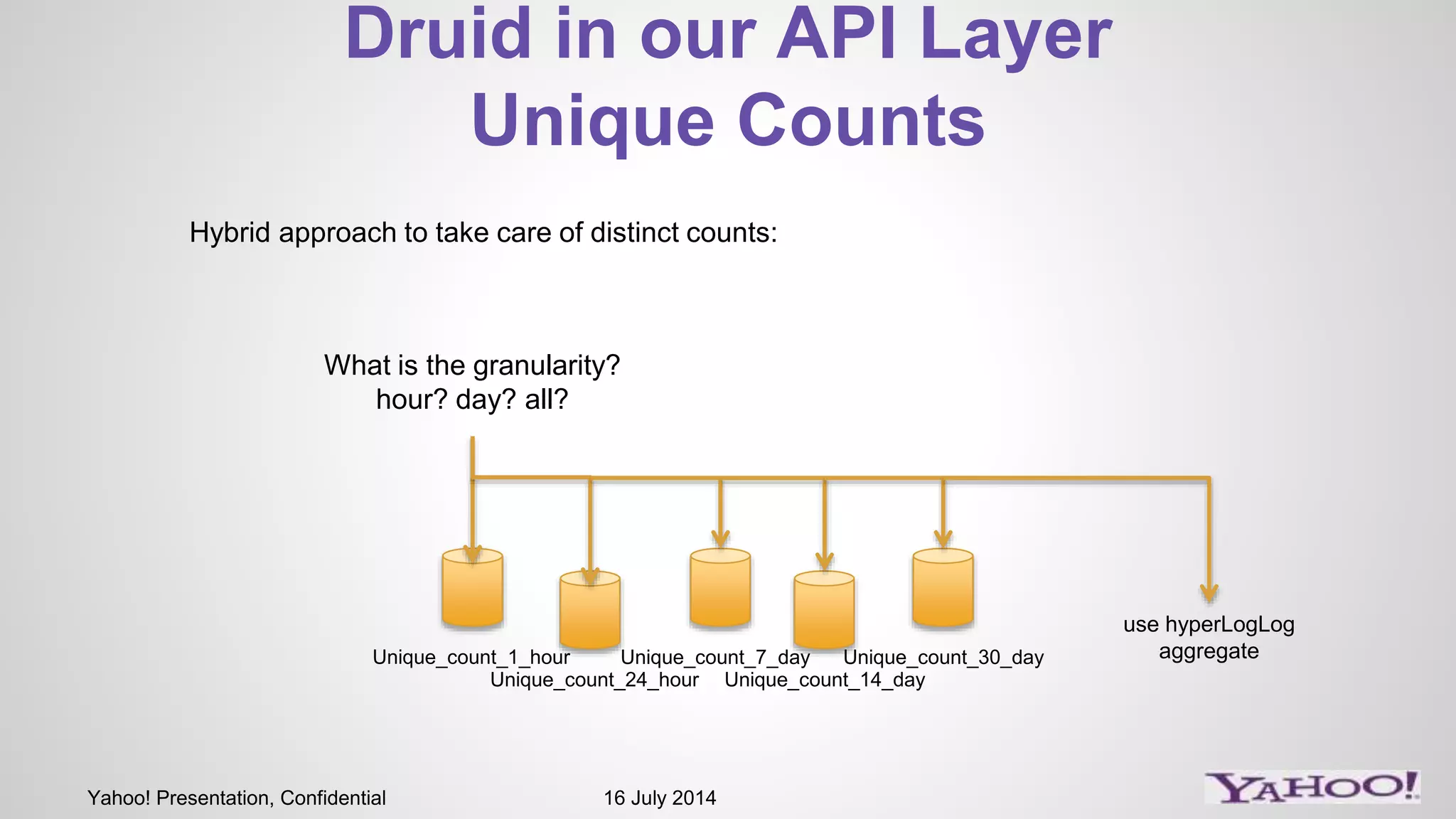
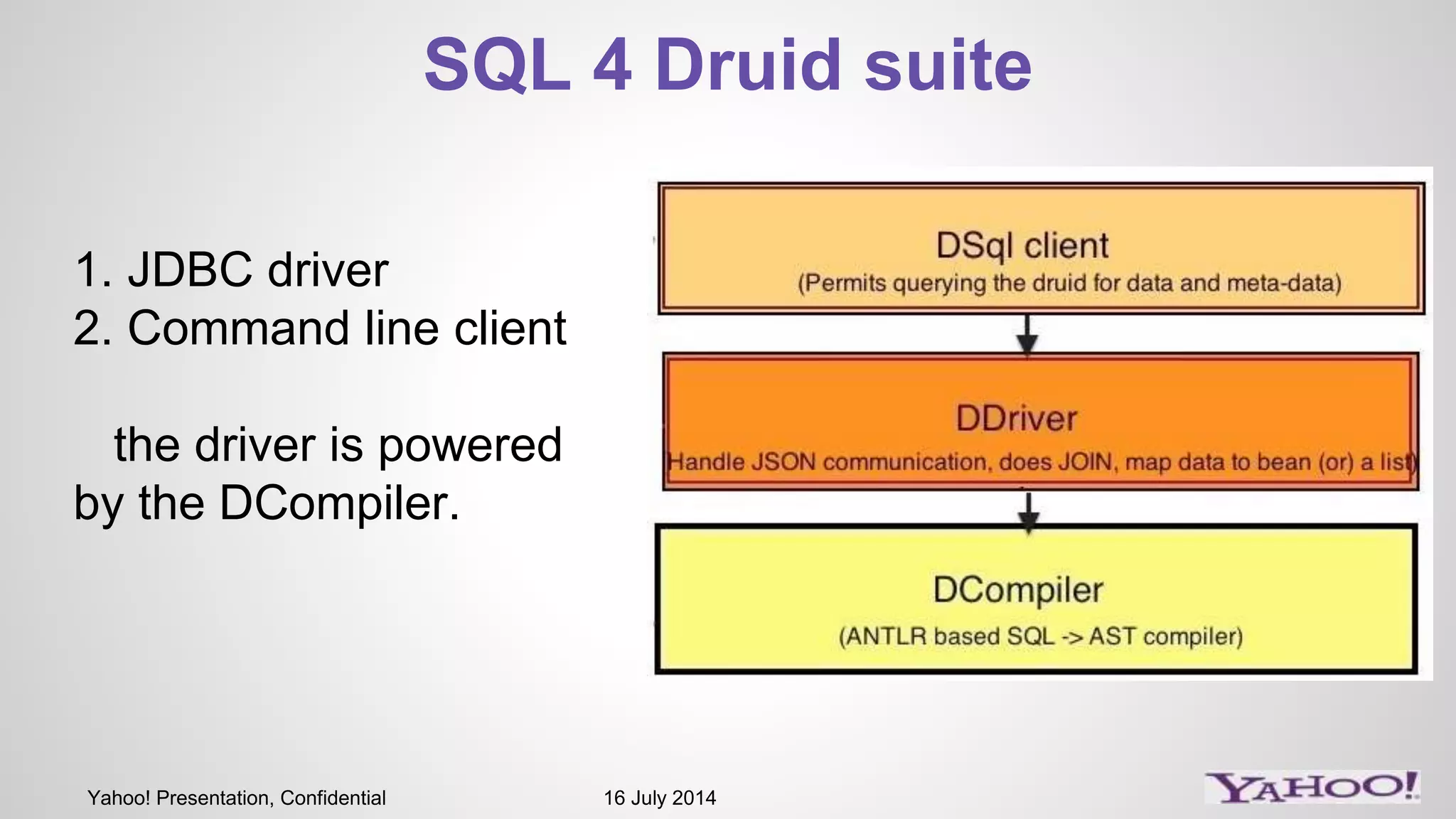












1) The presentation discusses Druid, an open source analytics engine that can perform aggregations on memory mapped data in sub-second time. 2) It describes how Druid fits into their software stack at the API layer and how they extend its capabilities through a SQL interface and addressing limitations like limited querying and missing features like distinct counts. 3) Examples of SQL queries against Druid are shown to demonstrate its capabilities like group by, filtering, joins, and handling of timeseries data.























































































