






![Other Hadoop Configuration
Considerations
Where
Parameter
Se1ing
core-‐‑site.xml
ipc.client.tcpnodelay
true
core-‐‑site.xml
ipc.server.tcpnodelay
true
hdfs-‐‑site.xml
dfs.client.read.shortcircuit
true
hdfs-‐‑site.xml
fs.s3a.buffer.dir
[machine specific]
hbase-‐‑site.xml
hbase.snapshot.master.timeoutMillis
1800000
hbase-‐‑site.xml
hbase.snapshot.master.timeout.millis
1800000
hbase-‐‑site.xml
hbase.master.cleaner.interval
600000 (ms)](https://image.slidesharecdn.com/usecases-session2-150605173427-lva1-app6891/85/HBaseCon-2015-Graph-Processing-of-Stock-Market-Order-Flow-in-HBase-on-AWS-13-320.jpg)









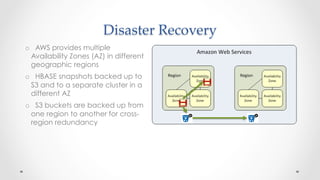




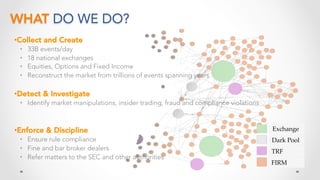
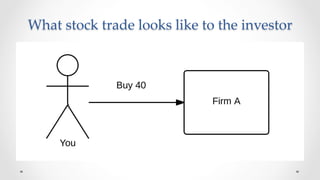
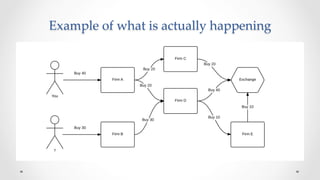
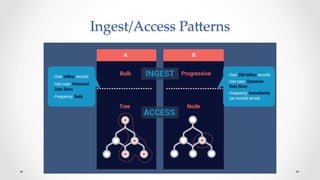
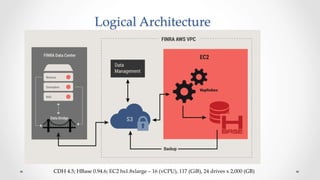
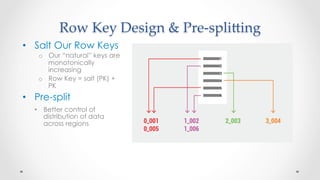
The document discusses stock market order flow reconstruction using HBase on AWS, focusing on data ingestion, processing, and management at FINRA. It outlines the use cases for historical market data analysis and compliance monitoring, detailing batch processing strategies, optimizations, and Hadoop configuration considerations. Additionally, it highlights lessons learned regarding running Hadoop on AWS, particularly with S3 for backup and disaster recovery, and the implications of instance types and network performance.











































































































