Downloaded 47 times





![Goals: Compatibility
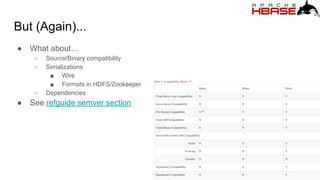
● Double-down on Semantic Versioning, semver
○ Adopted in hbase-1.0.0
○ MAJOR.MINOR.PATCH[-IDENTIFIER]
■ E.g. 2.0.0-alpha1](https://image.slidesharecdn.com/keynote-1-170807120906/85/hbaseconasia2017-hbase-2-0-0-6-320.jpg)




















HBase 2.0.0 is set to enhance compatibility and performance through semantic versioning and a focus on operational efficiency. Key features include a new master core for efficient region management, offheap read/write paths to reduce JVM overhead, and the introduction of asynchronous clients. The roadmap outlines significant improvements and goals for rolling upgrades, scalability, and robustness leading towards future versions like HBase 3.0.0.























































































