



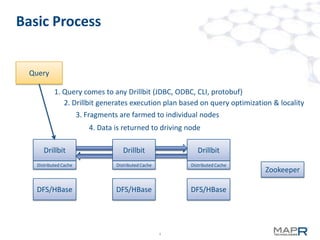
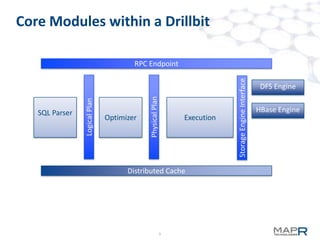
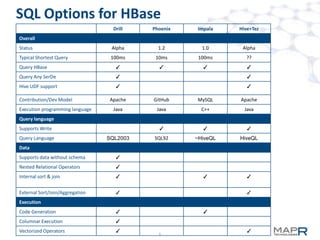






Apache Drill is an interactive SQL query engine for analyzing large scale datasets. It allows for querying data stored in HBase and other data sources. Drill uses an optimistic execution model and late binding to schemas to enable fast queries without requiring metadata definitions. It leverages recent techniques like vectorized operators and late record materialization to improve performance. The project is currently in alpha stage but aims to support features like nested queries, Hive UDFs, and optimized joins with HBase.











































































































