Downloaded 101 times













![Mapper Example
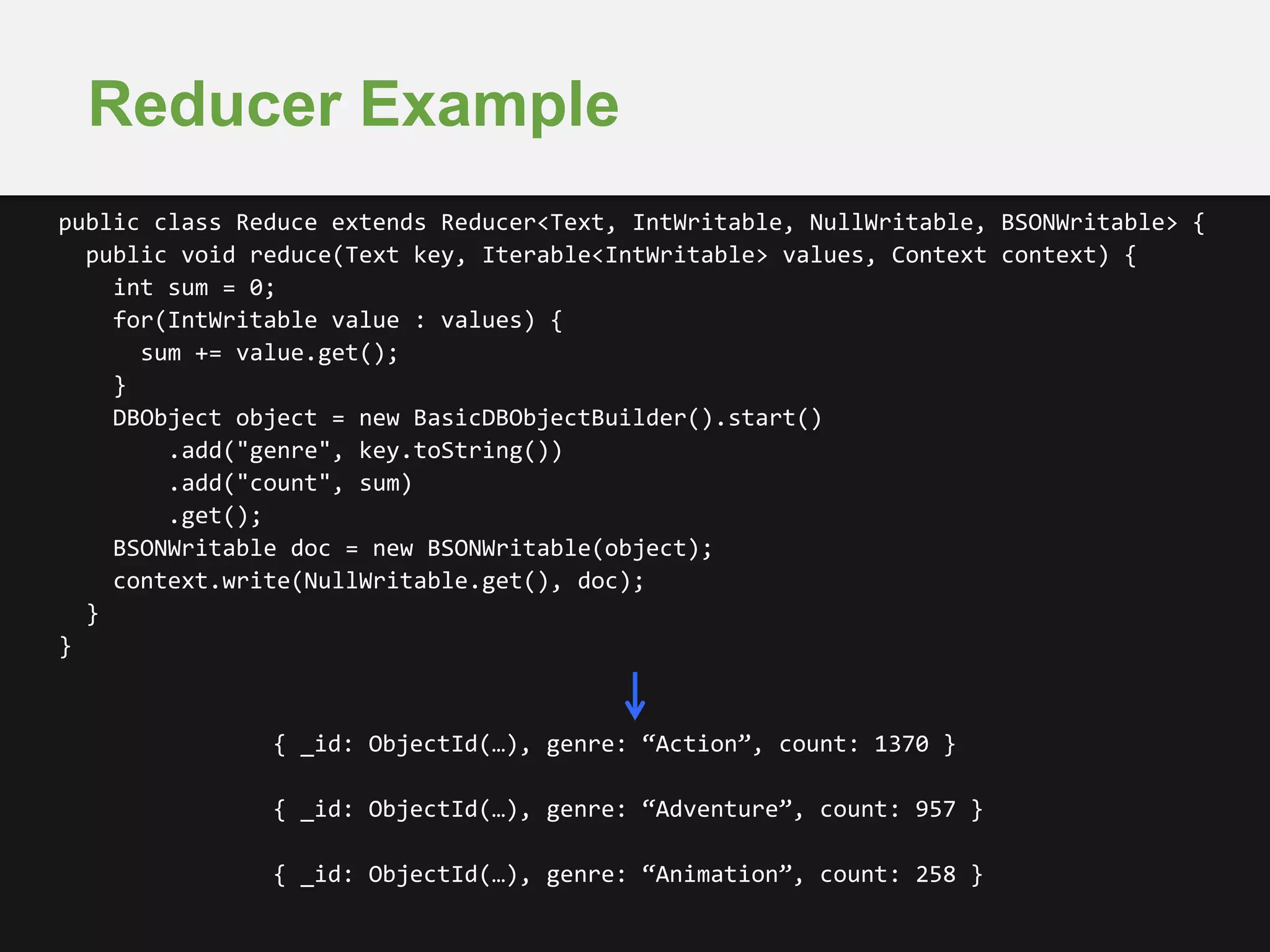
public class Map extends Mapper<Object, BSONObject, Text, IntWritable> {
public void map(Object key, BSONObject doc, Context context) {
List<String> genres = (List<String>)doc.get("genres");
for(String genre : genres) {
context.write(new Text(genre), new IntWritable(1));
}
}
}
{ _id: ObjectId(…), title: “Toy Story”,
genres: [“Animation”, “Children”] }
{ _id: ObjectId(…), title: “Goldeneye”,
genres: [“Action”, “Crime”, “Thriller”] }
{ _id: ObjectId(…), title: “Jumanji”,
genres: [“Adventure”, “Children”, “Fantasy”] }](https://image.slidesharecdn.com/mongodbseattle-mongodbandhadoop2014-09-16-140924165735-phpapp01/75/MongoDB-and-Hadoop-Driving-Business-Insights-25-2048.jpg)









![Execution
$ bin/spark-submit
--master local
--class com.mongodb.hadoop.demo.Recommender demo-1.0.jar
--jars mongo-java-2.12.3.jar,mongo-hadoop-core-1.3.0.jar
--driver-memory 2G
--executor-memory 1G
[insert job args here]](https://image.slidesharecdn.com/mongodbseattle-mongodbandhadoop2014-09-16-140924165735-phpapp01/75/MongoDB-and-Hadoop-Driving-Business-Insights-40-2048.jpg)



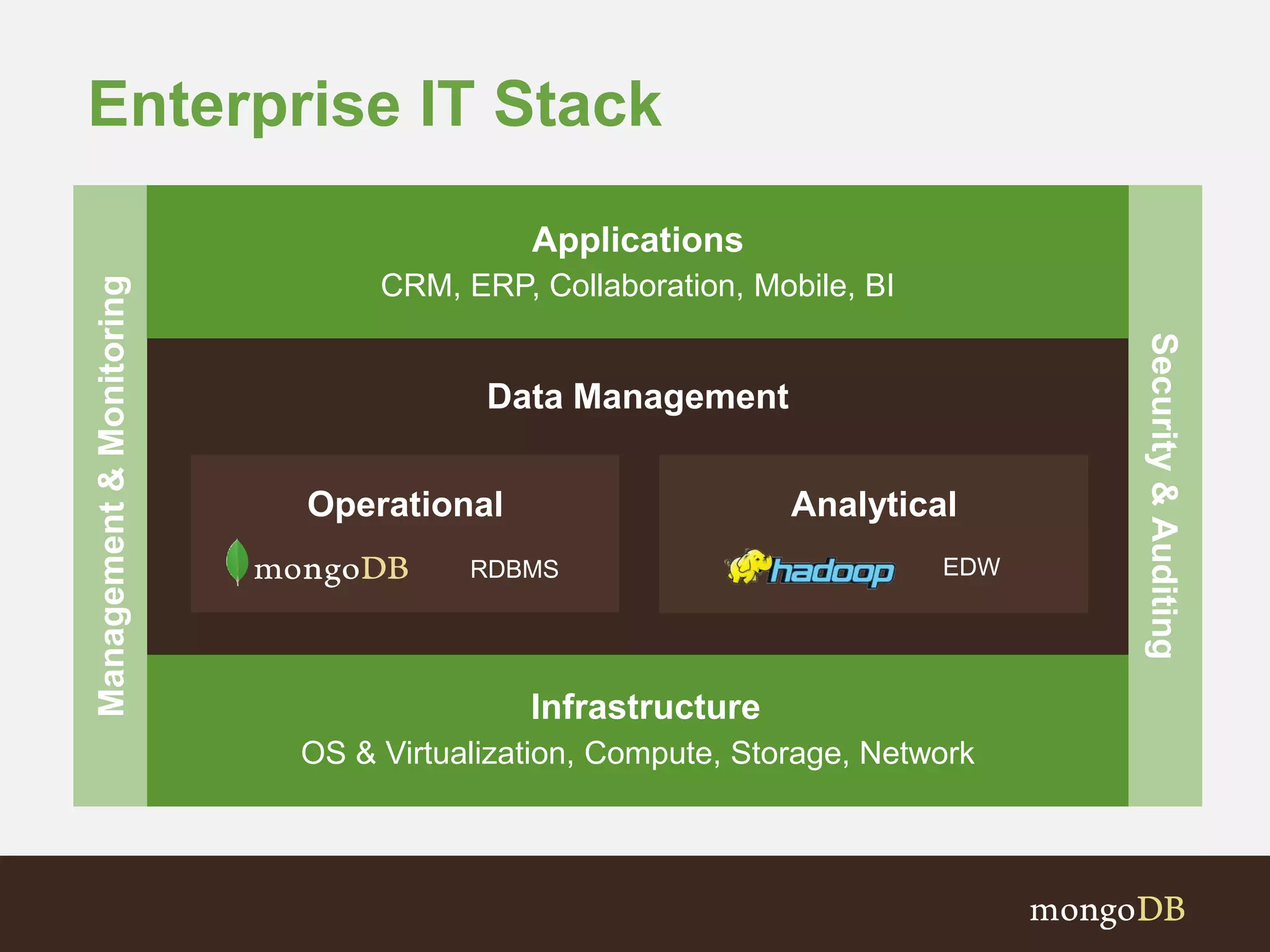
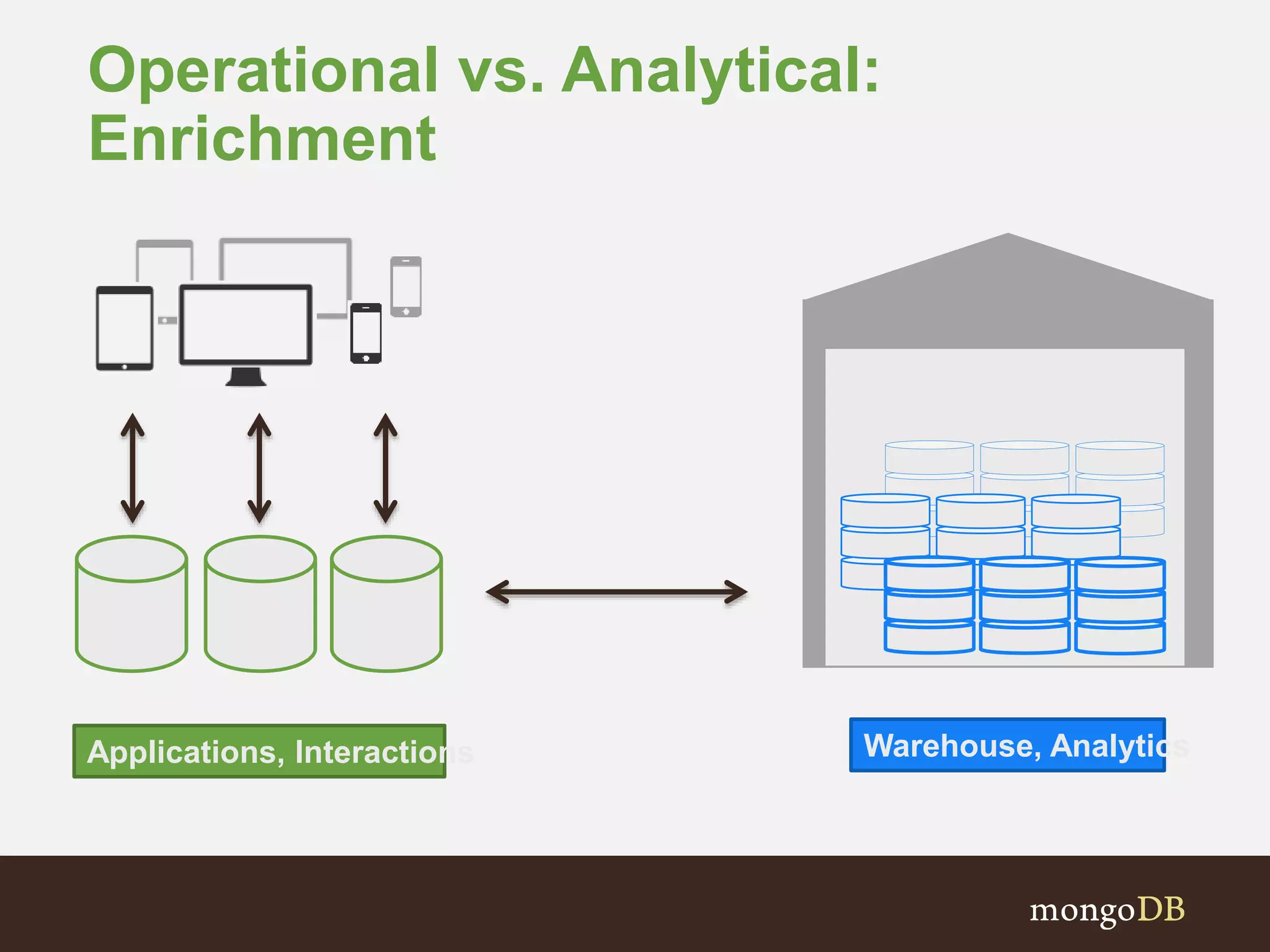
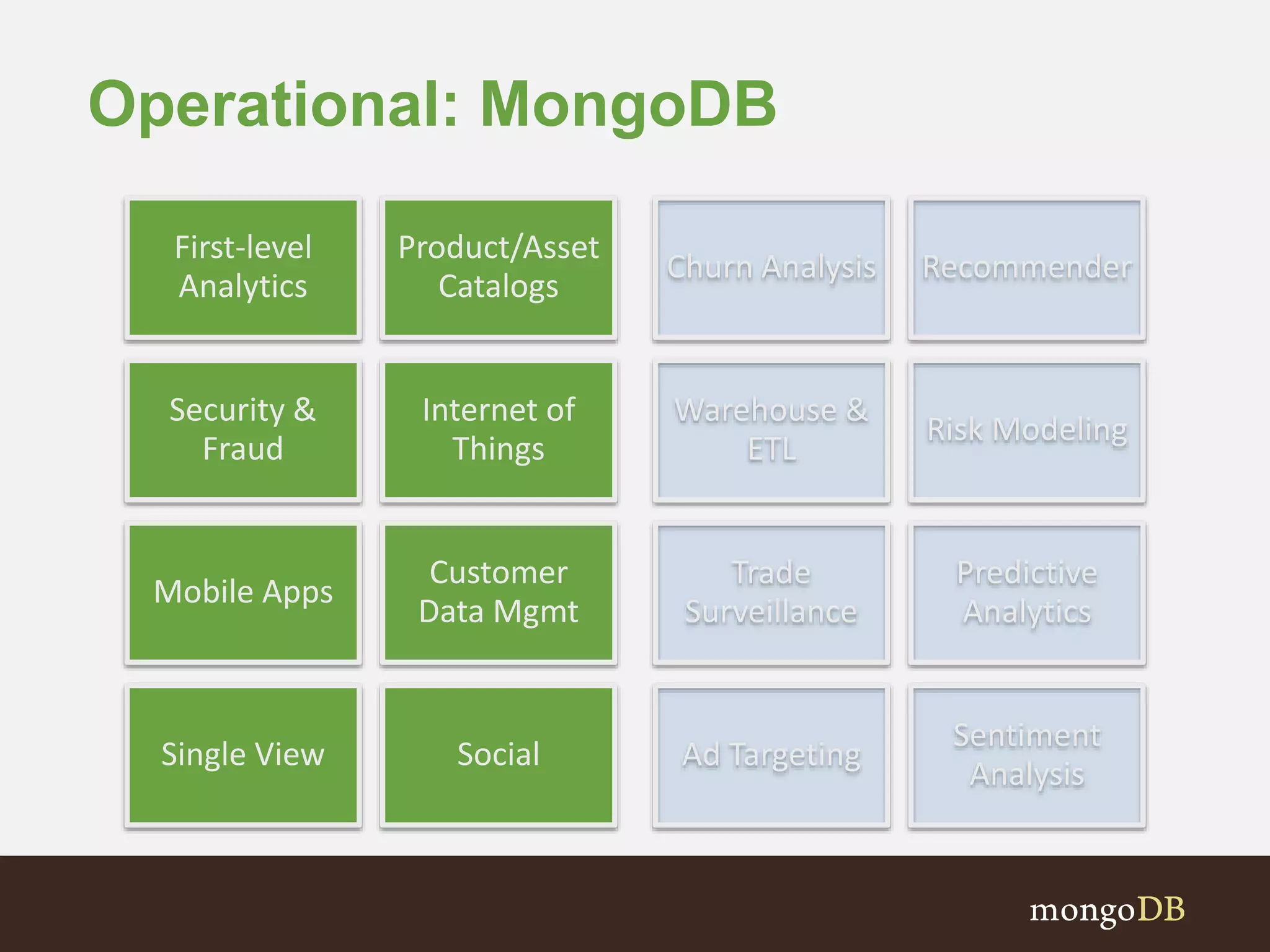
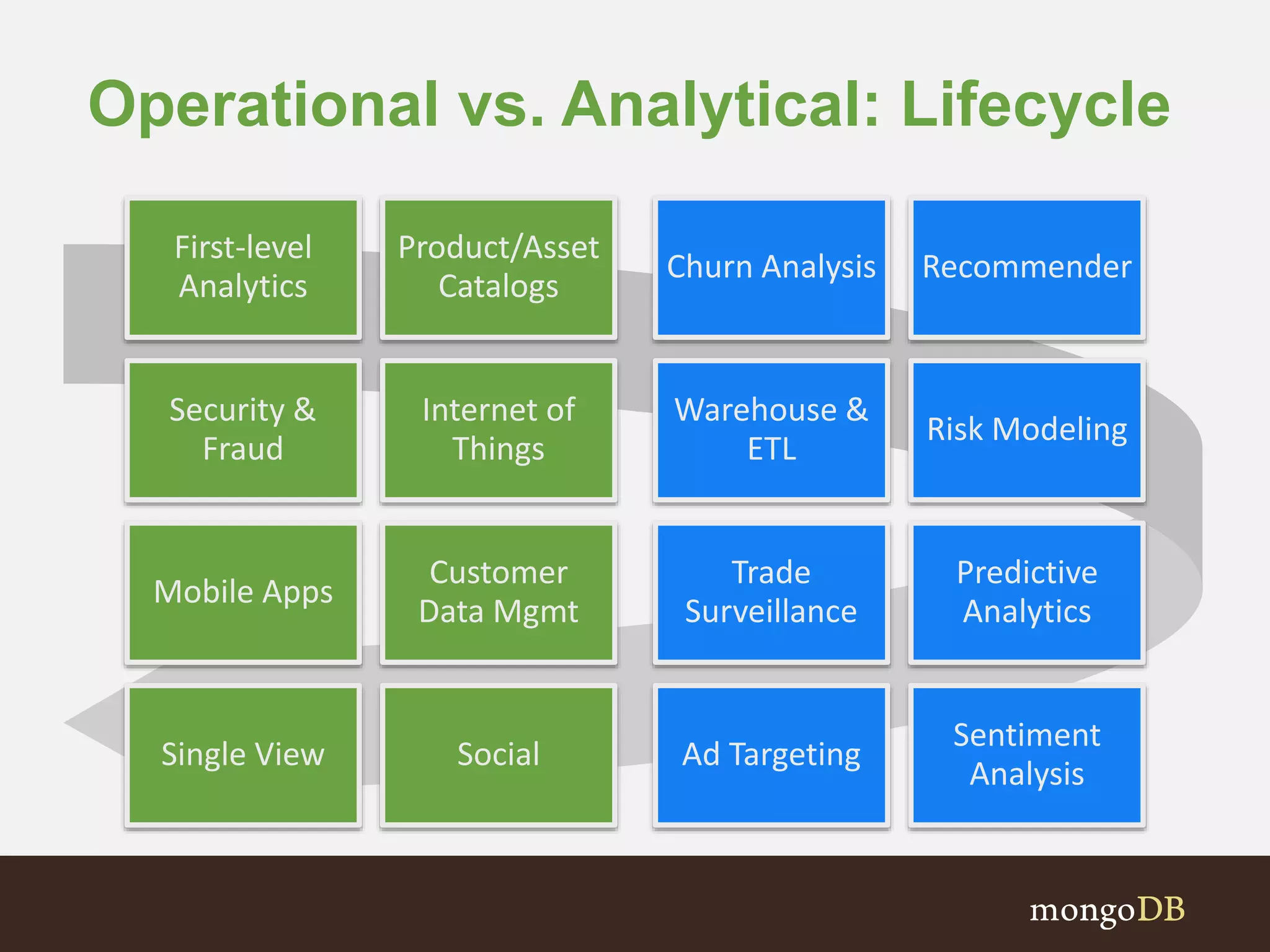
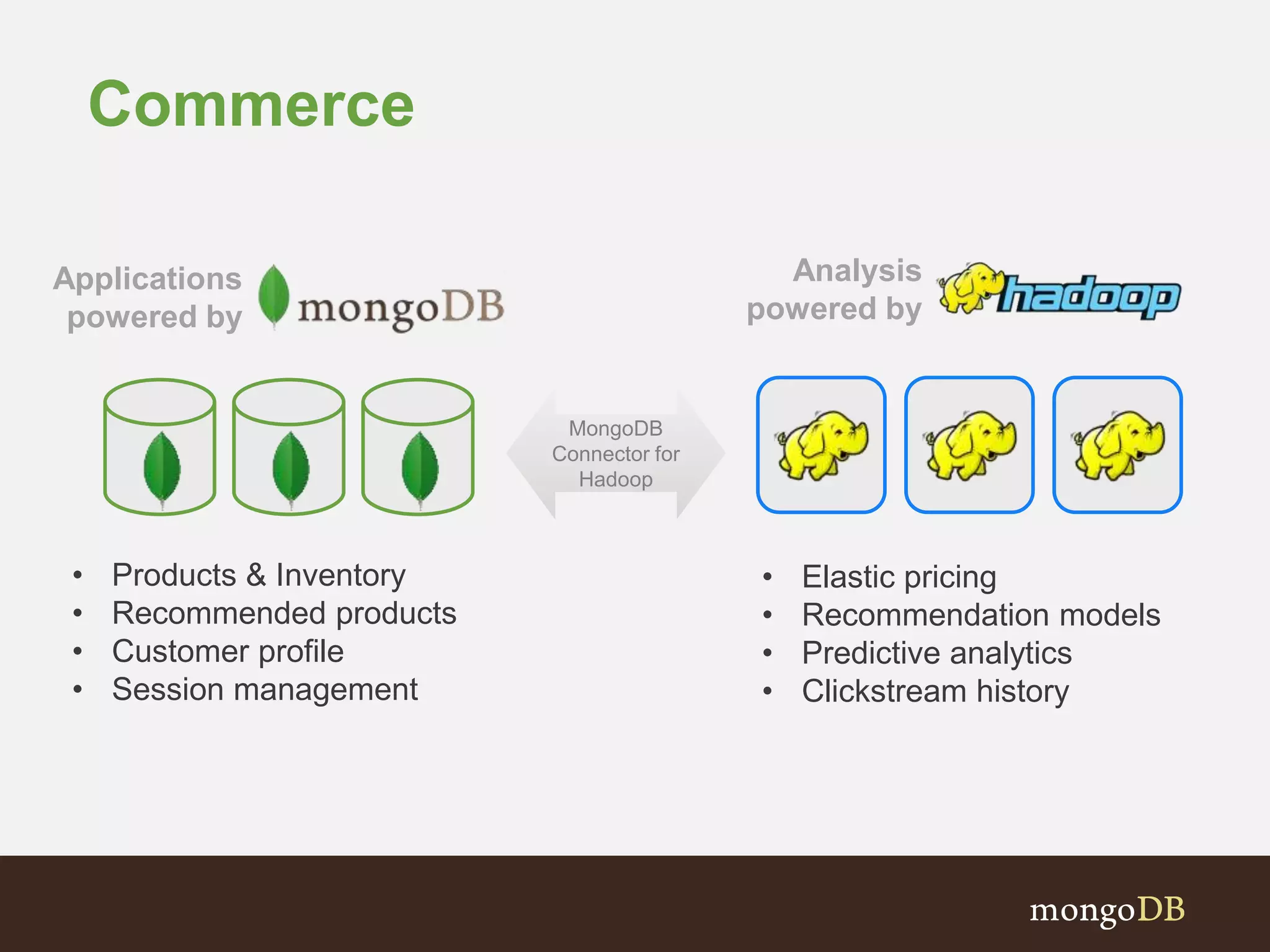
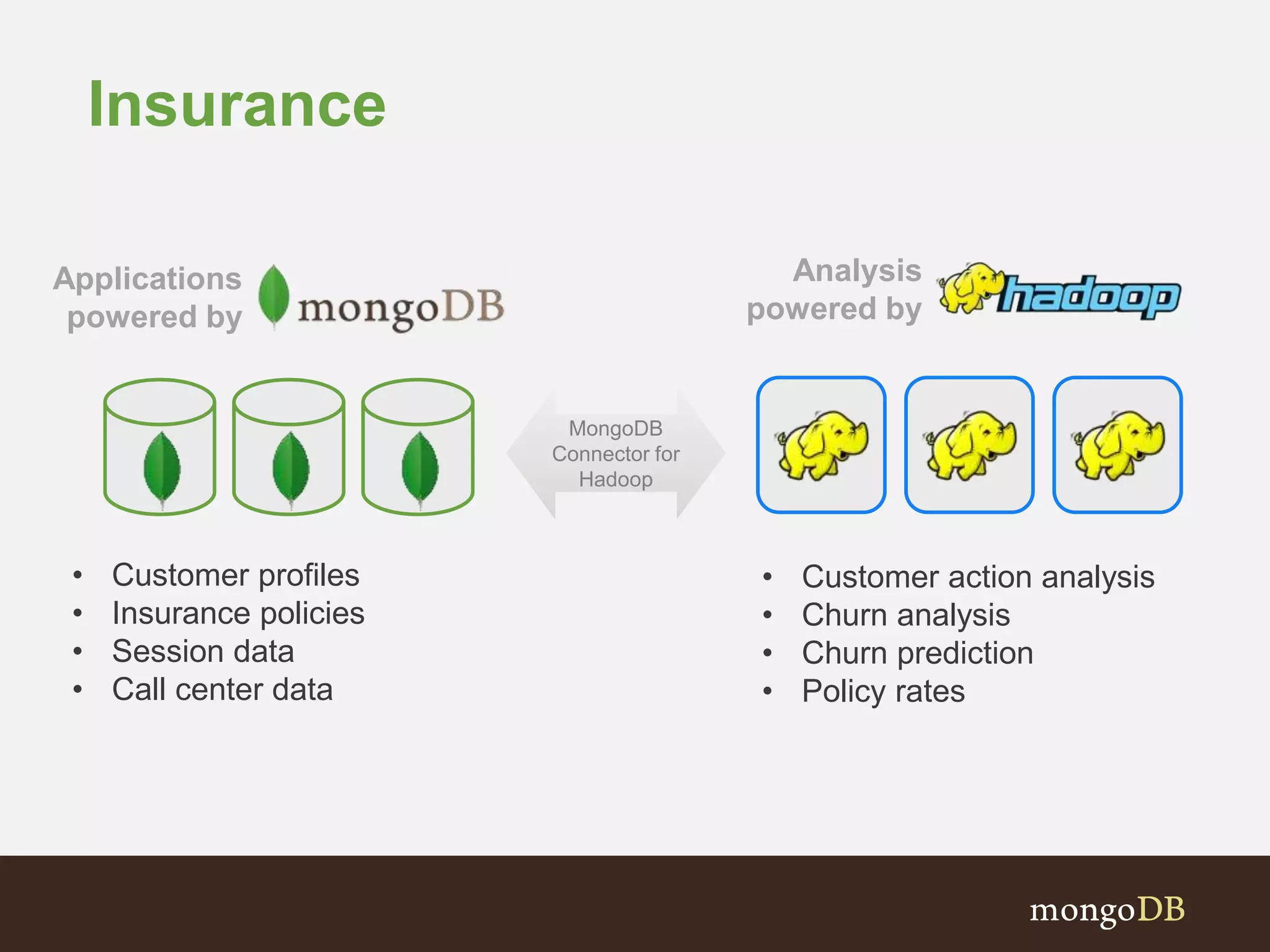
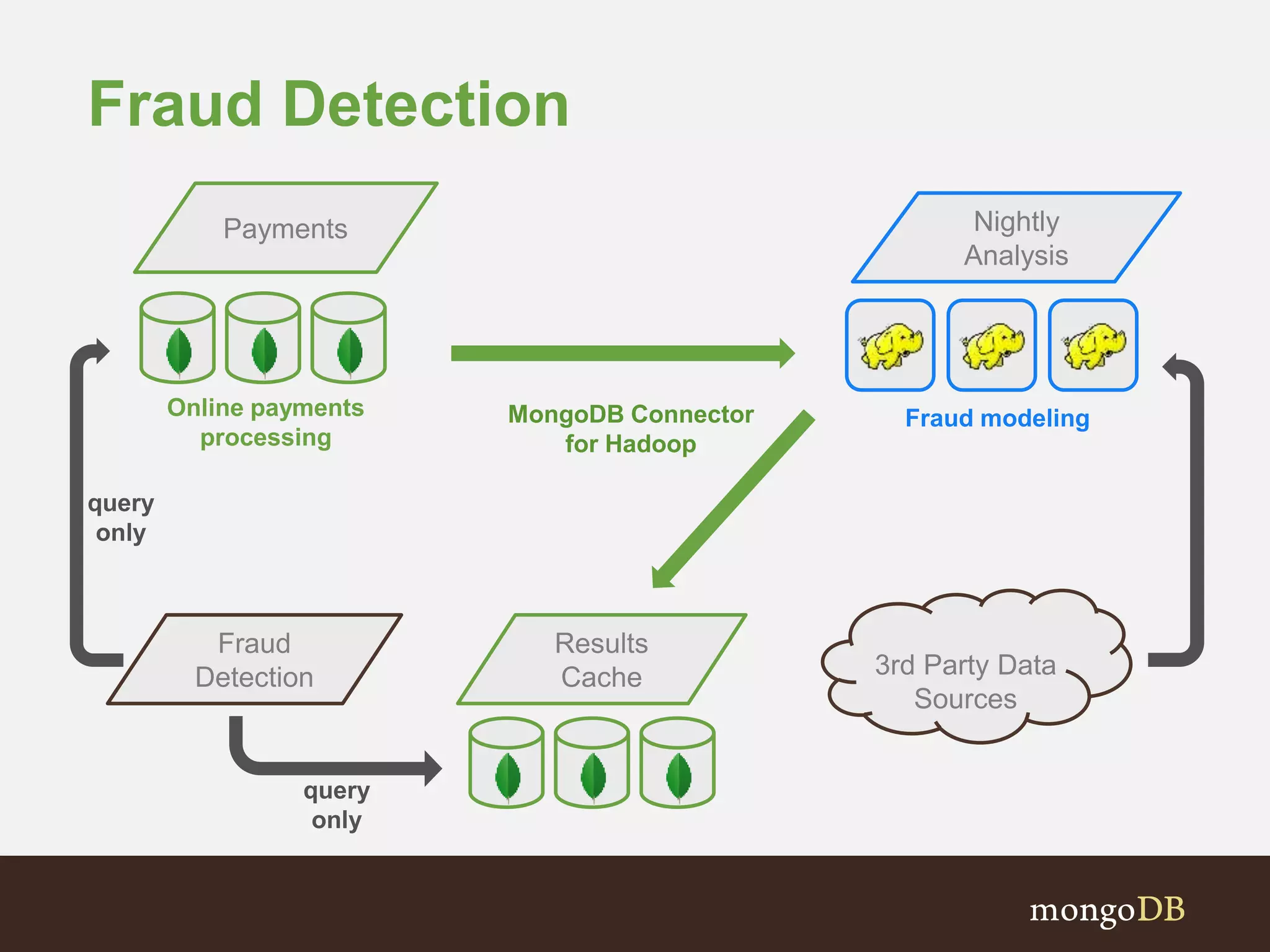
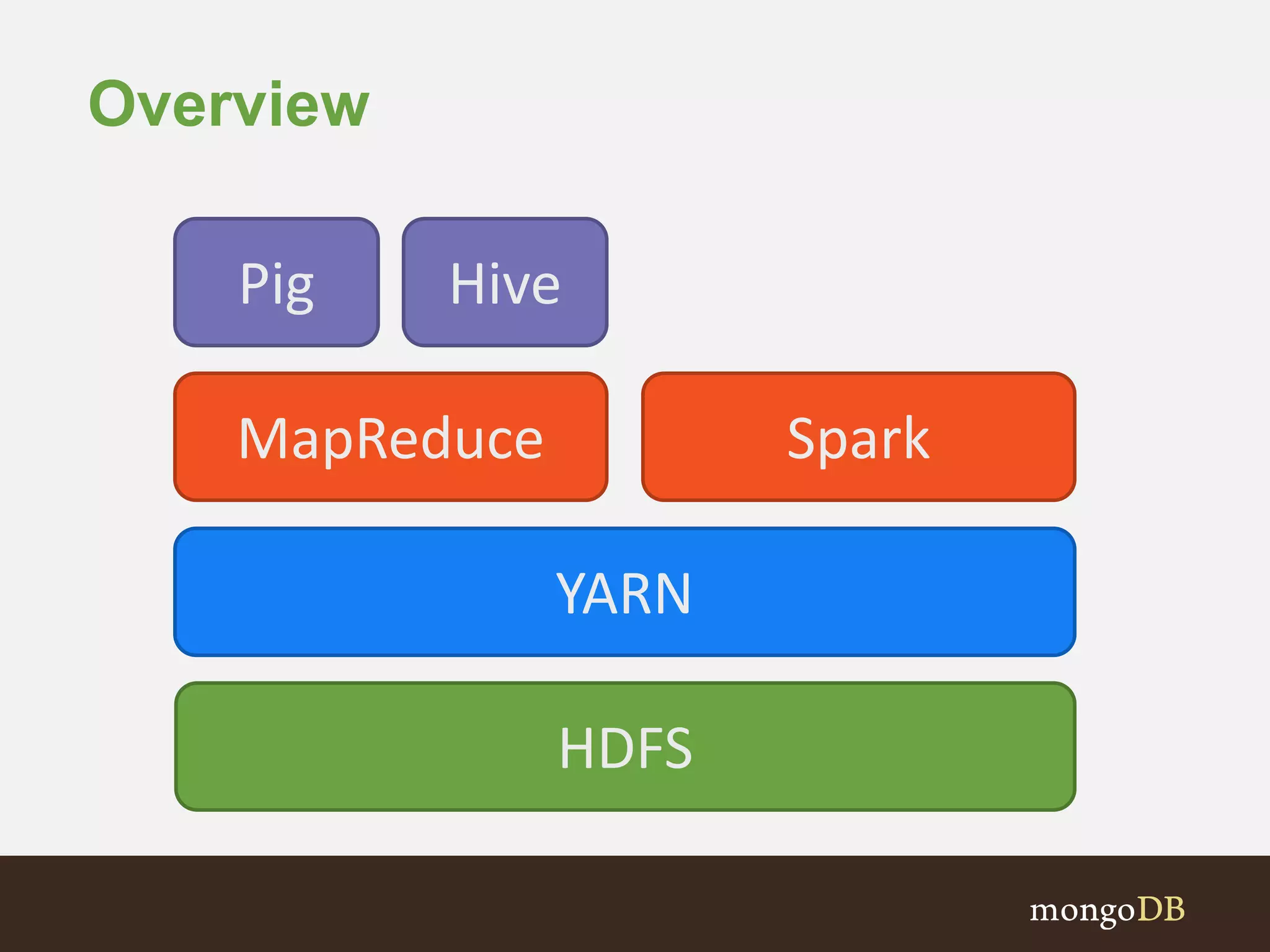
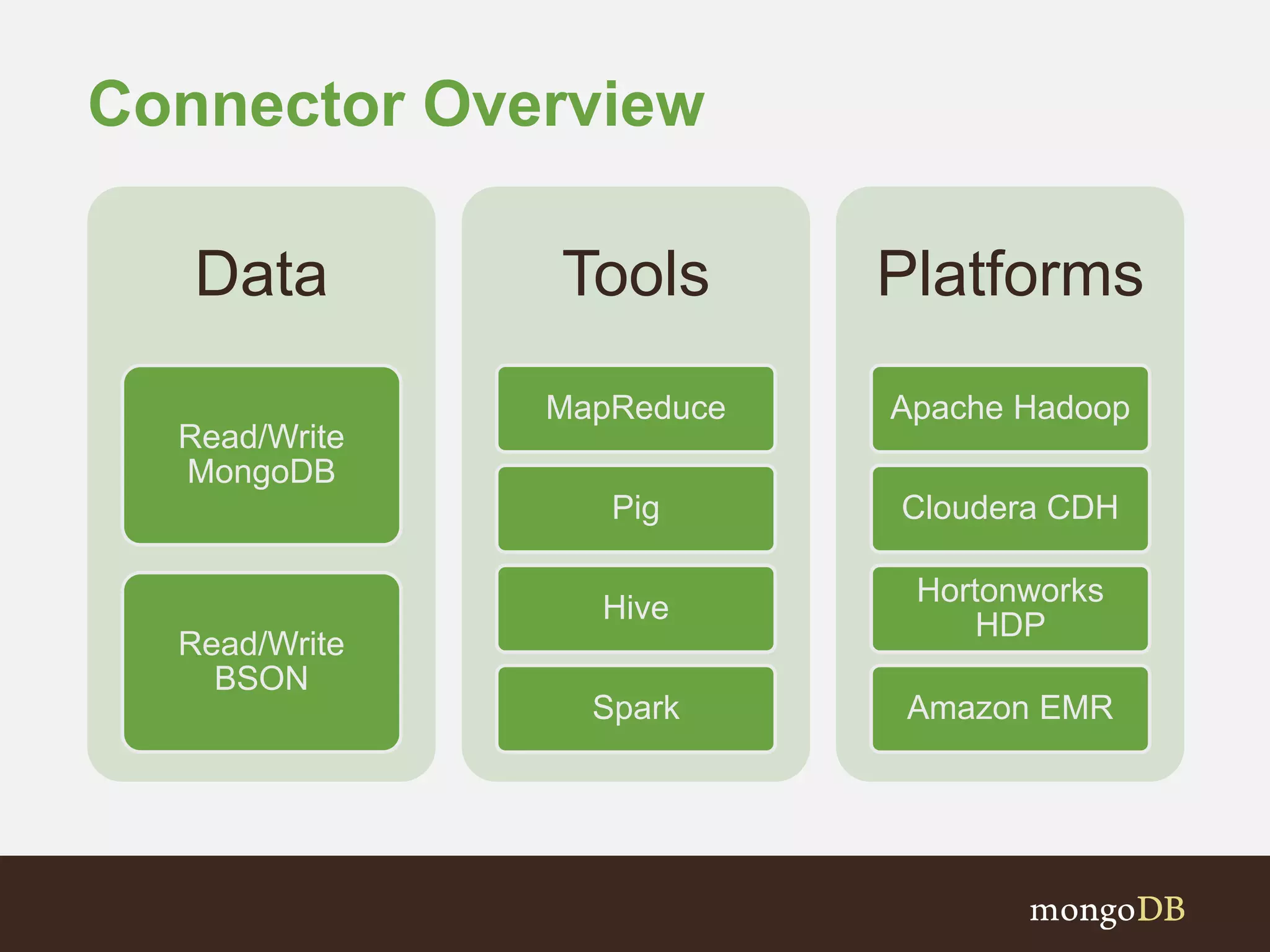
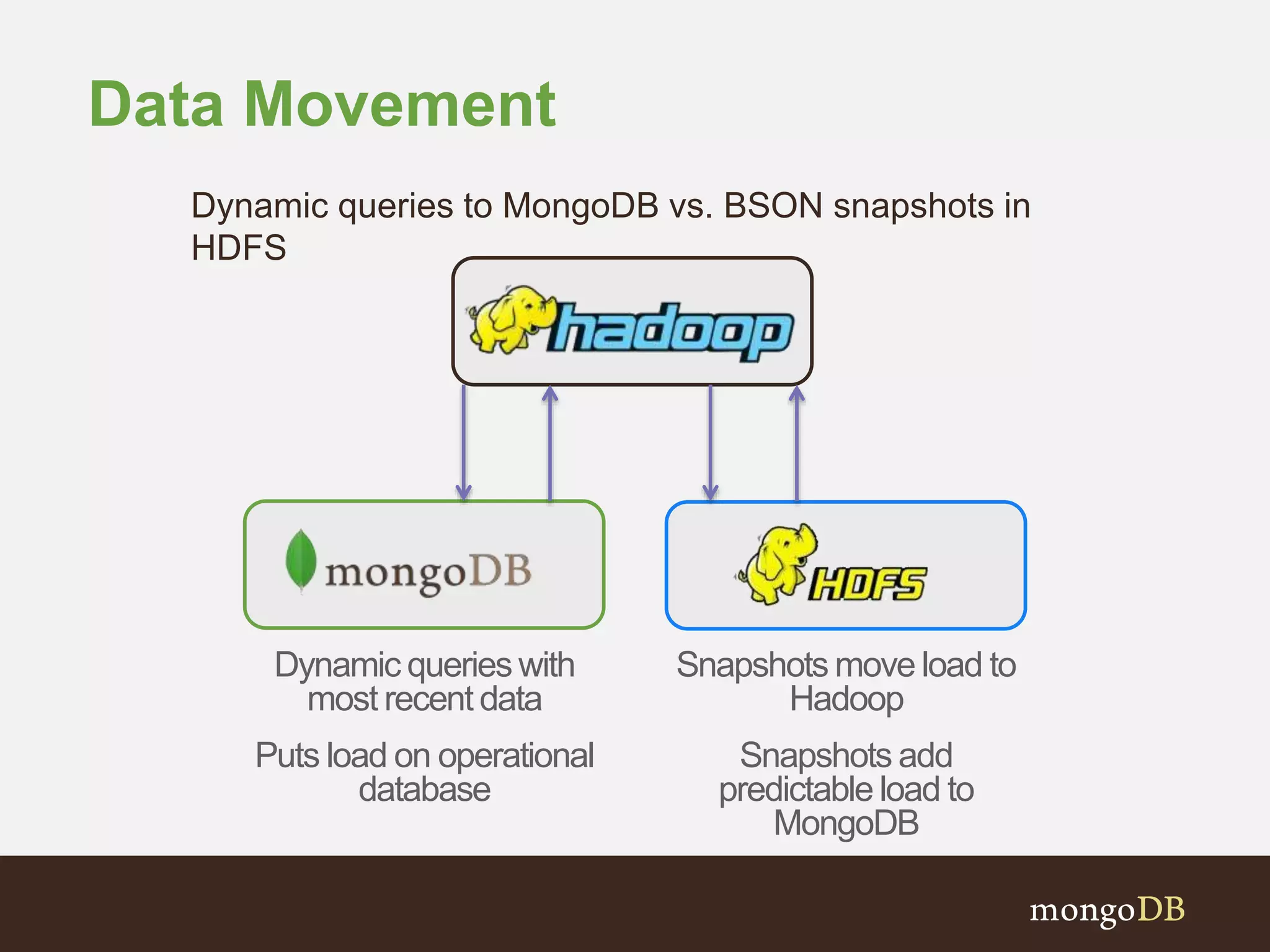
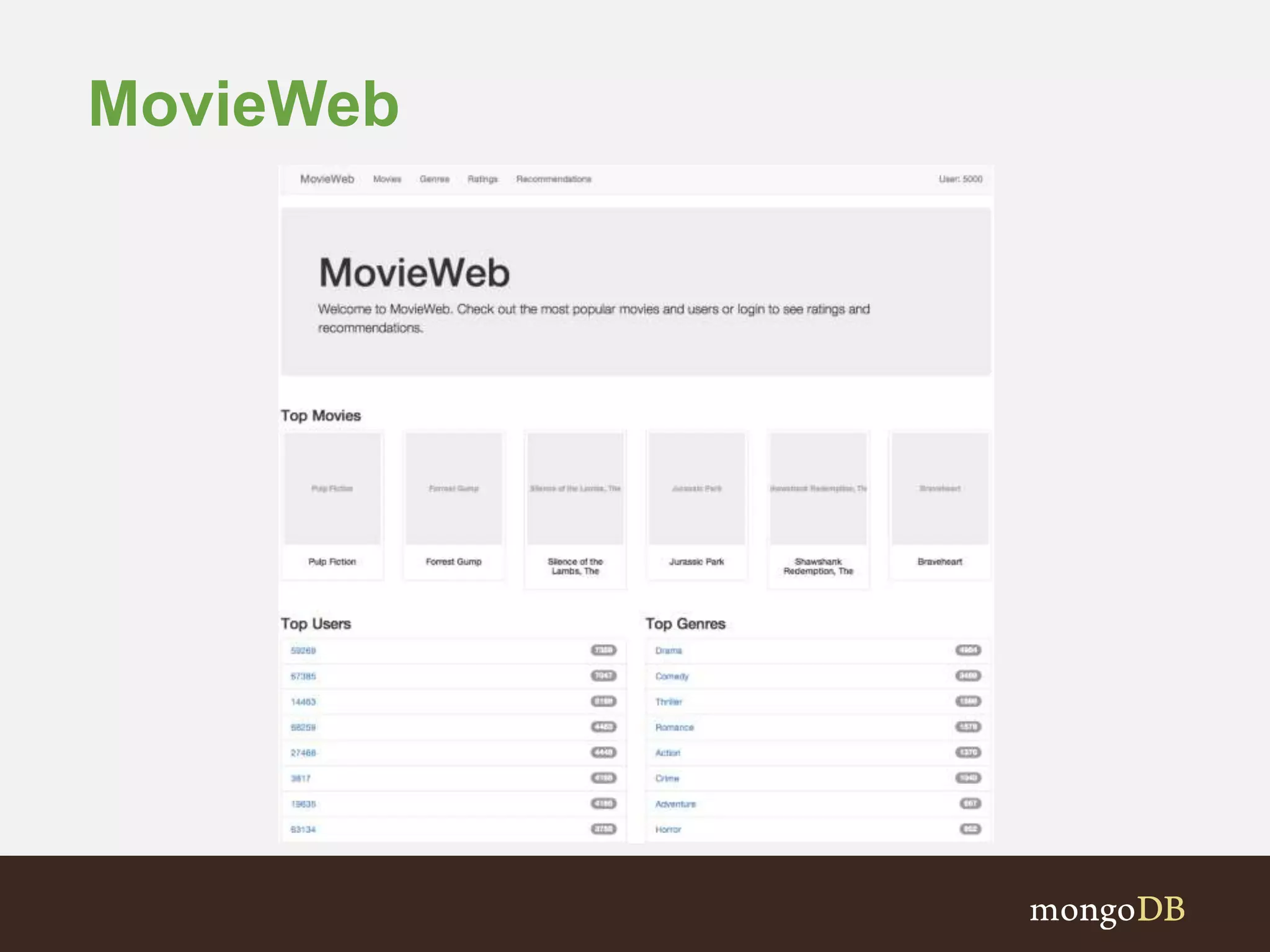
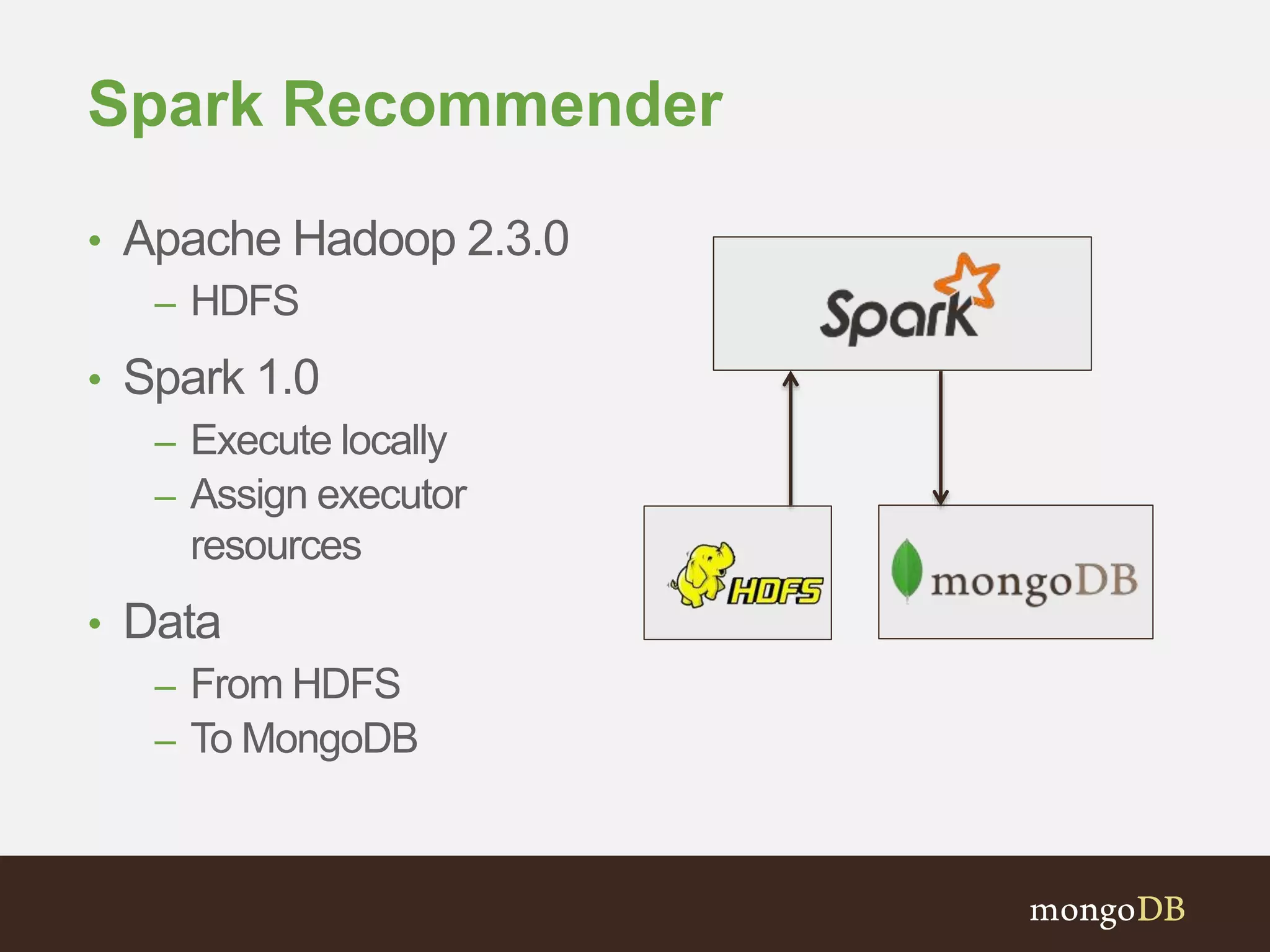
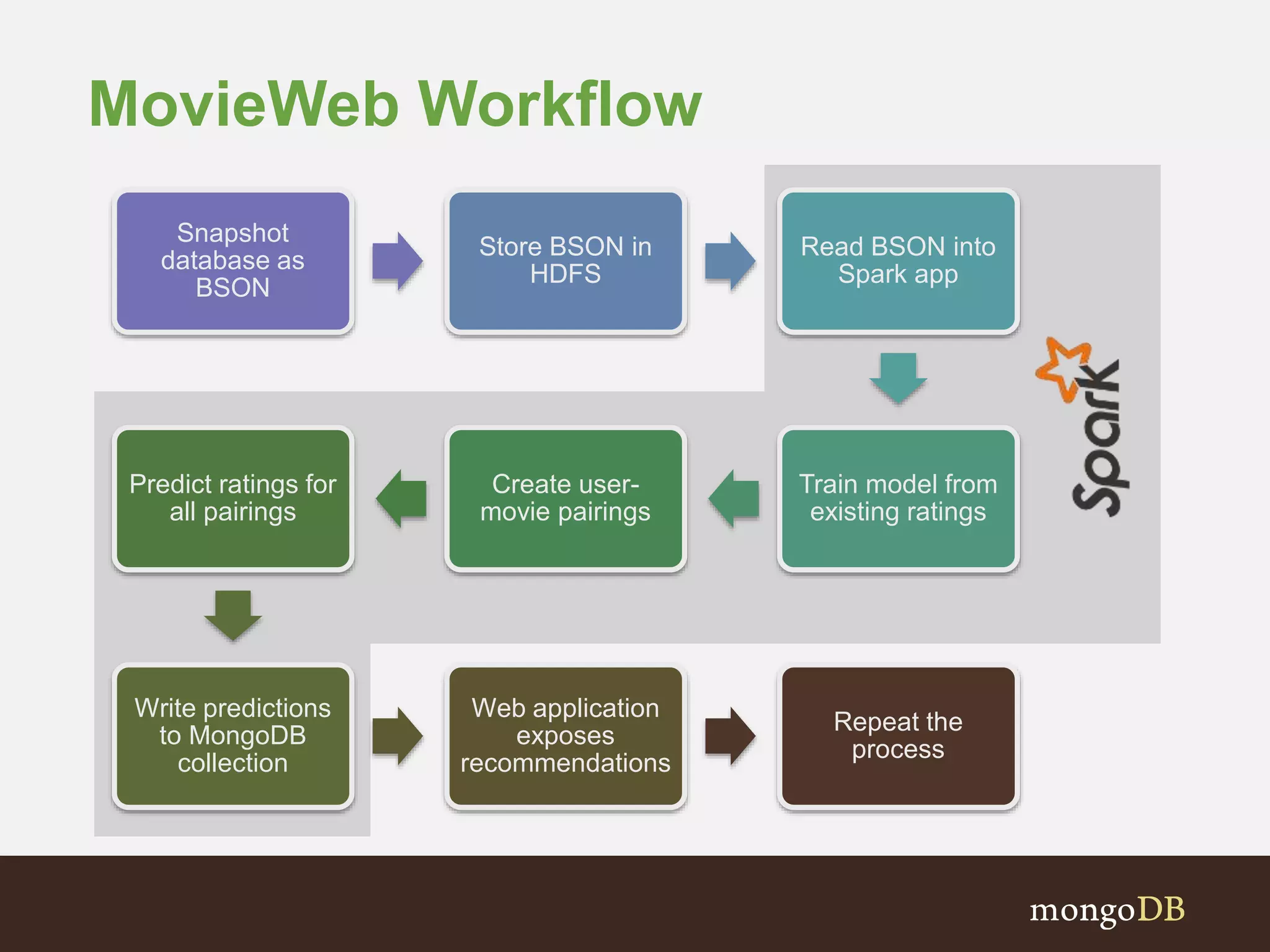
The document presents an overview of the integration between MongoDB and Hadoop, highlighting their capabilities in handling large datasets and providing business insights. It discusses various use cases across different industries, details on Hadoop components, and implementation strategies, including the MongoDB connector for Hadoop. Additionally, it features a demonstration of a web application leveraging both technologies for movie recommendations.






































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)










![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)


![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



