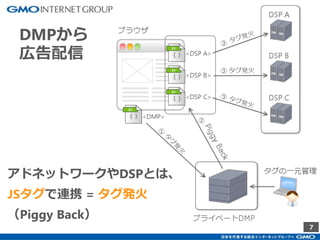
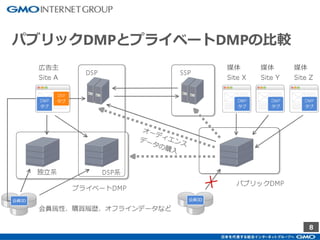
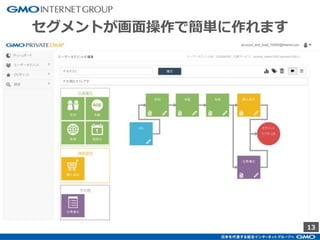
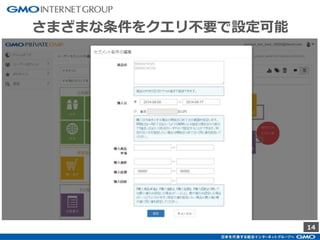
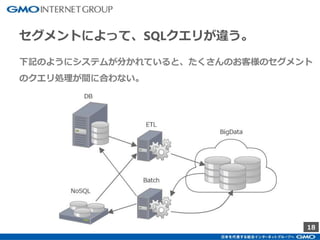
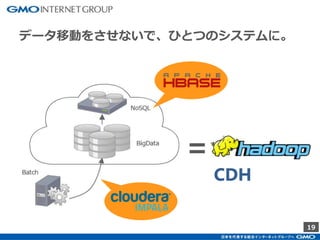
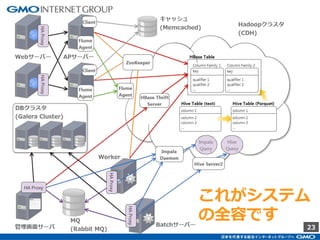
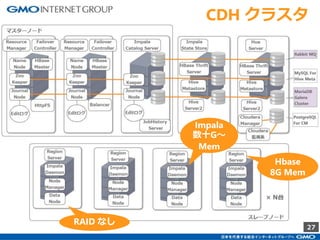
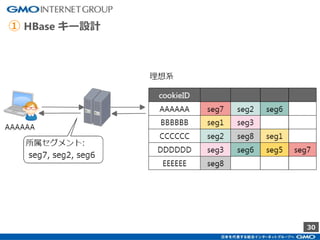
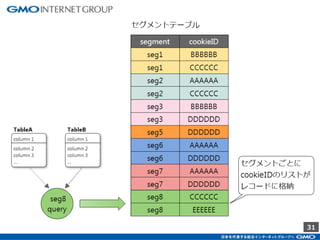
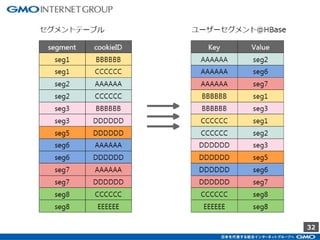
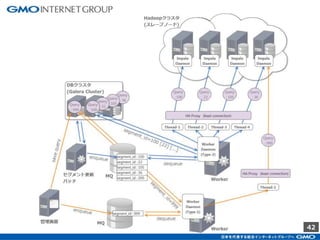
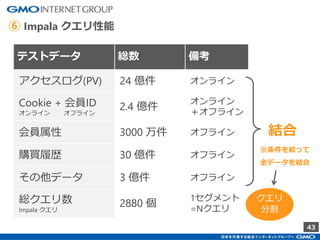
GMOインターネットグループのアドテク・サービスの一つ「GMOプライベートDMP」。GMOアプリクラウドのインフラにCDHのHadoopエコシステムを構築しました。コア・テクノロジーとしてのHBase×Impala活用事例と、システム設計についてご紹介します。











































![[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014l32datastaxapachecassandraiotbigdatanosql-141120022255-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)













![[db tech showcase Tokyo 2017] A15: レプリケーションを使用したデータ分析基盤構築のキモ(事例)by 株式会社インサイトテ...](https://cdn.slidesharecdn.com/ss_thumbnails/a15-170912020524-thumbnail.jpg?width=640&height=640&fit=bounds)















![[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d33presto-141120012543-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[db tech showcase Tokyo 2014] B22: Hadoop Rush!! HDFSからデータを自在に取得、加工するにはどうする? ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b22hadooprushhdfs-141119235245-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)






