The document discusses several information retrieval models including the Boolean, vector space, and probabilistic models. It provides details on how each model represents documents and queries, defines relevance, and ranks documents in response to queries. Specifically, it describes:
1) The Boolean model uses exact matching to retrieve only documents that satisfy a Boolean query, but does not rank results.
2) The vector space model represents documents and queries as vectors of term weights and ranks documents based on their similarity to the query vector using measures like cosine similarity.
3) Term frequency-inverse document frequency (TF-IDF) is discussed as a method to weight terms based on their importance.
![UNIT III
MODELING AND RETRIEVAL EVALUATION
2. Basic Retrieval Models
An IR model governs how a document and a query are represented and how the relevance
of a document to a user query is defined.
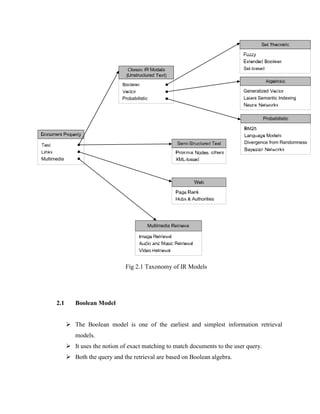
There are Three main IR models:
Boolean model
Vector space model
Probabilistic model
Although these models represent documents and queries differently, they used the same
framework. They all treat each document or query as a “bag” of words or terms.
Term sequence and position in a sentence or a document are ignored. That is, a document
is described by a set of distinctive terms.
Each term is associated with a weight.Given a collection of documents D, let
V = {t1, t2... t|V|} be the set of distinctive terms in the collection, where ti is a term.
The set V is usually called the vocabulary of the collection, and |V| is its size,
i.e., the number of terms in V.
A weight wij > 0 is associated with each term ti of a document dj D. A weight wij > 0
is associated with each term ti of a document dj D.For a term that does not appear in
document dj, wij = 0.
Each document dj is thus represented with a term vector, dj = (w1j, w2j, ..., w|V|j),where
each weight wij corresponds to the term ti V, and quantifies the level of importance of ti
in document dj.
An IR model is a quadruple [D, Q, F, R(qi, dj)] where
1. D is a set of logical views for the documents in the collection
2. Q is a set of logical views for the user queries
3. F is a framework for modeling documents and queries
4. R(qi, dj) is a ranking function](https://image.slidesharecdn.com/unit3irt-230802091722-5c3a7a28/85/UNIT-3-IRT-docx-1-320.jpg)















![Probability Estimates in Practice
Assuming that relevant documents are a very small percentage of the collection,
approximate statistics for non relevant documents by statistics from the whole
collection
Hence, ut (the probability of term occurrence in non relevant documents for a
query) is dft/N and log[(1 − ut )/ut ] = log[(N − dft)/df t ] ≈ log N/df t
The above approximation cannot easily be extended to relevant documents
Statistics of relevant documents (pt ) can be estimated in various ways:
1. Use the frequency of term occurrence in known relevant documents (if
known). This is the basis of probabilistic approaches to relevance
feedback weighting in a feedback loop
2. Set as constant. E.g., assume that pt is constant over all terms xt in the
query and that pt = 0.5
2.5 Latent Semantic Indexing Model
The retrieval models discussed so far are based on keyword or term
matching, i.e., matching terms in the user query with those in the documents.
If a user query uses different words from the words used in a document, the
document will not be retrieved although it may be relevant because the
document uses some synonyms of the words in the user query.
This causes low recall. For example, “picture”, “image” and “photo” are
synonyms in the context of digital cameras. If the user query only has the
word “picture”, relevant documents that contain “image” or “photo” but not
“picture” will not be retrieved.
Latent semantic indexing (LSI), aims to deal with this problem through the
identification of statistical associations of terms.
It is assumed that there is some underlying latent semantic structure in the
data that is partially obscured by the randomness of word choice.](https://image.slidesharecdn.com/unit3irt-230802091722-5c3a7a28/85/UNIT-3-IRT-docx-18-320.jpg)









![Let R q1 be the set of relevant docs for a query q1:
R q 1 = { d3, d5, d9, d25, d39, d44, d56, d71, d89, d123 }
o Consider a new IR algorithm that yields the following answer to q 1 (relevant
docs are marked with a bullet):
01. d123 • 06. d9 • 11. d38
02. d84 07. d511 12. d48
03. d56 • 08. d129 13. d250
04. d6 09. d187 14. d113
05. d8 10. d25 • 15. d3 •
If we examine this ranking, we observe that The document d123, ranked as number
1, is relevant
This document corresponds to 10% of all relevant documents.
Thus, we say that we have a precision of 100% at 10% recall.
The document d56, ranked as number 3, is the next relevant.
At this point, two documents out of three are relevant, and two of the ten relevant
documents have been seen.
Thus, we say that we have a precision of 66.6% at 20% recall.
2.10 Reference Collection
Reference collections, which are based on the foundations established by the Cranfield
experiments, constitute the most used evaluation method in IR
A reference collection is composed of:
o A set D of pre-selected documents
o A set I of information need descriptions used for testing
o A set of relevance judgements associated with each pair [im, dj], im € I and dj € D .
The relevance judgement has a value of 0 if document dj is non-relevant to im , and 1
otherwise.](https://image.slidesharecdn.com/unit3irt-230802091722-5c3a7a28/85/UNIT-3-IRT-docx-28-320.jpg)





![The Rocchio algorithm for relevance feedback
It is the classic algorithm for implementing RF.
The Rocchio algorithm uses the vector space model to pick a relevance feedback
query
Rocchio seeks the query𝑞𝑜𝑝𝑡 that maximizes
𝑞𝑜𝑝𝑡 = 𝑎𝑟𝑔 𝑚𝑎𝑥[𝑠𝑖𝑚(𝑞, 𝐶𝑟) − 𝑠𝑖𝑚(𝑞, 𝐶𝑛𝑟)]
𝑞 = query vector, that maximizes similarity with relevant documents while
minimizing similarity with non relevant documents.
Cr = the set of relevant documents
Cnr = the set of non relevant documents
Under cosine similarity, the optimal query vector 𝑞𝑜𝑝𝑡 for separating the
relevant and non relevant documents is:
𝑞𝑜𝑝𝑡 =
1
|𝐶𝑟|
∑ 𝑑𝑗
𝑑𝑗∈𝐶𝑟
−
1
|𝐶𝑛𝑟|
∑ 𝑑𝑗
𝑑𝑗∈𝐶𝑛𝑟
That is, the optimal query is the vector difference between the centroids of
the relevant and non relevant documents as shown in Figure 2.11](https://image.slidesharecdn.com/unit3irt-230802091722-5c3a7a28/85/UNIT-3-IRT-docx-35-320.jpg)
























































































