Downloaded 65 times








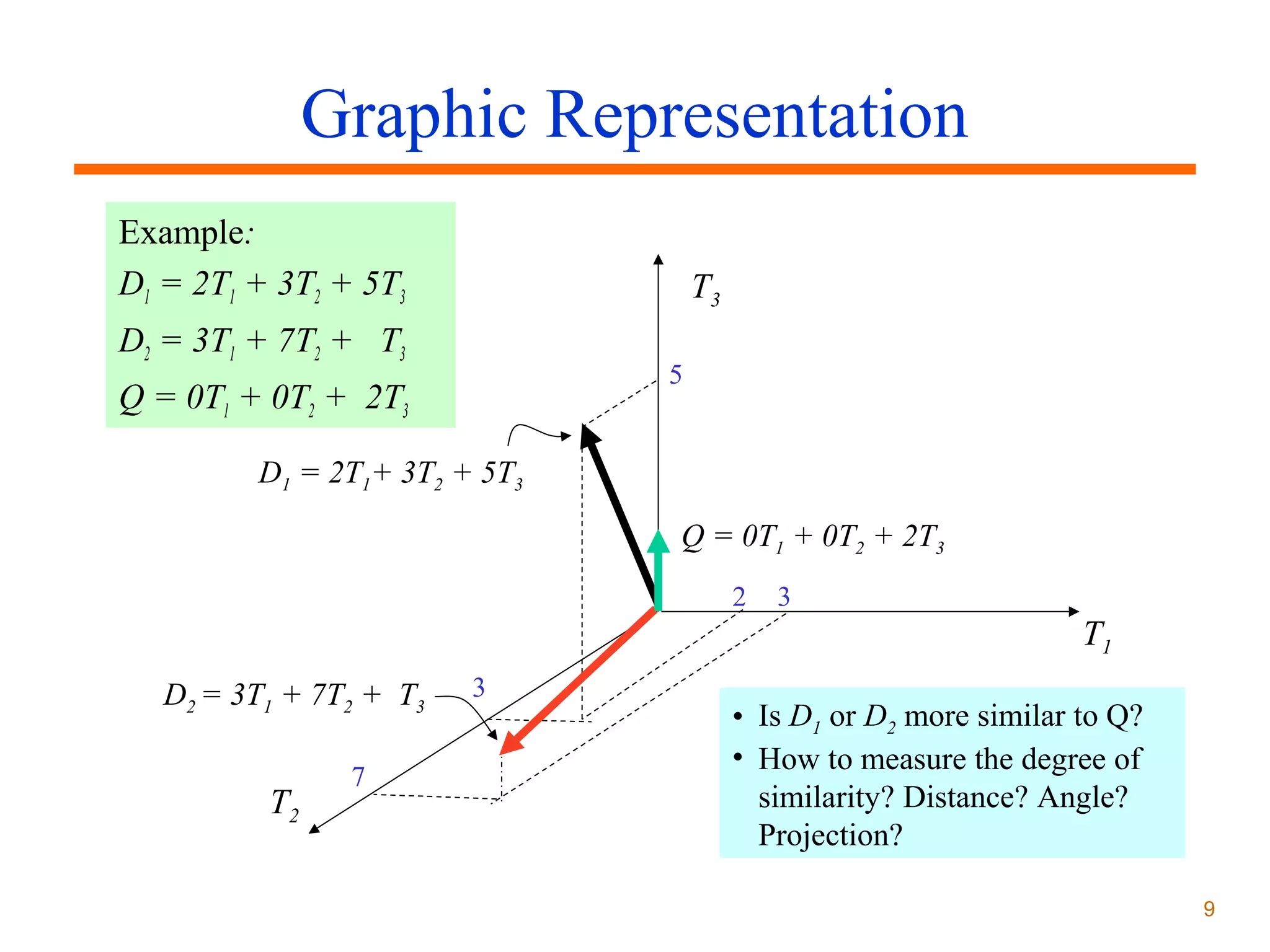













The document discusses two main types of retrieval models: Boolean models which use set theory and vector space models which use statistical and algebraic approaches. Vector space models represent documents and queries as vectors of keywords weighted by factors like term frequency and inverse document frequency. Similarity between document and query vectors is calculated using measures like the inner product or cosine similarity to retrieve and rank documents.
















































































