



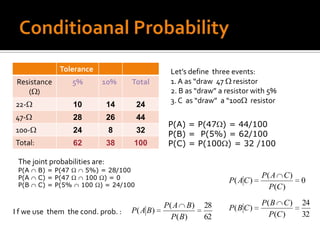



![ The first attempts to develop a probabilistic theory of retrieval were made over
30 years ago [Maron and Kuhns 1960; Miller 1971], and since then there has been
a steady development of the approach. There are already several operational IR
systems based upon probabilistic or semiprobabilistic models.
One major obstacle in probabilistic or semiprobabilistic IR models is finding
methods for estimating the probabilities used to evaluate the probability of
relevance that are both theoretically sound and computationally efficient.
The first models to be based upon such assumptions were the “binary
independence indexing model” and the “binary independence retrieval model
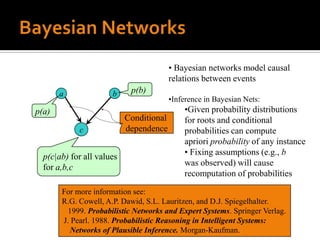
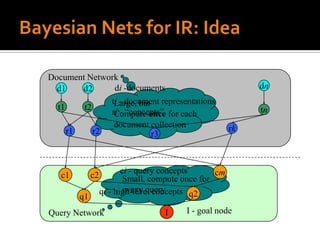
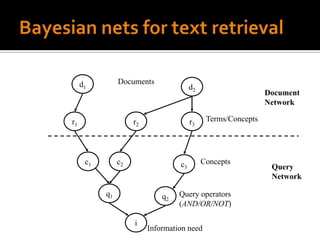
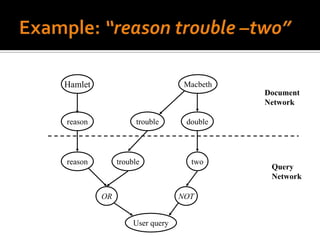
One area of recent research investigates the use of an explicit network
representation of dependencies. The networks are processed by means of
Bayesian inference or belief theory, using evidential reasoning techniques such as
those described by Pearl 1988. This approach is an extension of the earliest
probabilistic models, taking into account the conditional dependencies present in
a real environment.](https://image.slidesharecdn.com/probabilisticinformationretrievalmodelssystems-111129052353-phpapp02/85/Probabilistic-information-retrieval-models-systems-8-320.jpg)





























The document discusses probabilistic information retrieval and Bayesian approaches. It introduces concepts like conditional probability, Bayes' theorem, and the probability ranking principle. It explains how probabilistic models estimate the probability of relevance between a document and query by representing them as term sets and making probabilistic assumptions. The goal is to rank documents by the probability of relevance to present the most likely relevant documents first.

























































































