Downloaded 28 times


















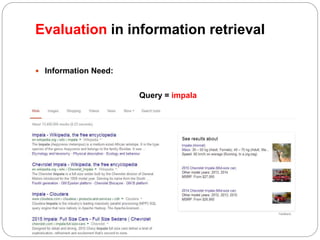


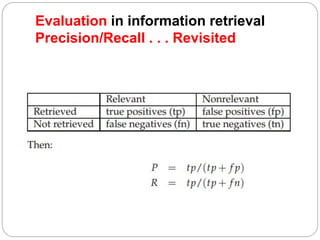




The document discusses different techniques for weighting terms in the vector space model for information retrieval, including: - Sublinear tf scaling using the logarithm of term frequency - Tf-idf weighting - Maximum tf normalization to mitigate higher weights for longer documents It also discusses evaluating information retrieval systems using test collections with queries, relevant documents, and metrics like precision and recall. Standard test collections include Cranfield, TREC, and CLEF.























































































