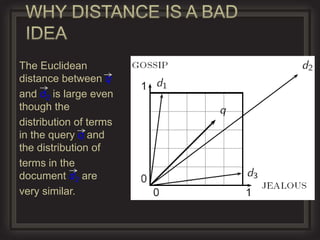
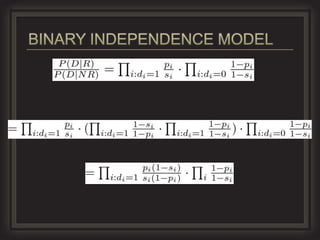
The document discusses probabilistic retrieval models in information retrieval. It provides an overview of older models like Boolean retrieval and vector space models. The main focus is on probabilistic models like BM25 and language models. It explains key concepts in probabilistic IR like the probability ranking principle, using Bayes' rule to estimate the probability that a document is relevant given features of the document, and estimating probabilities based on the frequencies of terms in relevant documents. The goal is to rank documents based on the probability of relevance to the query.