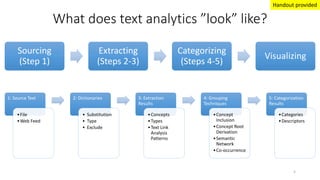
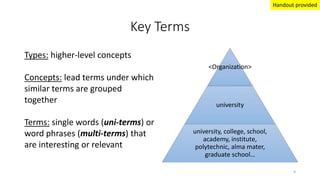
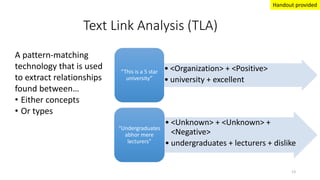
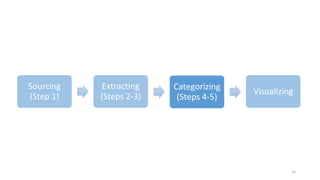
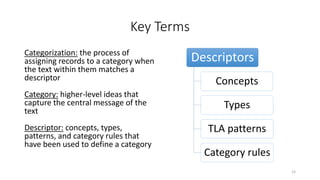
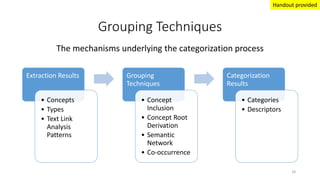
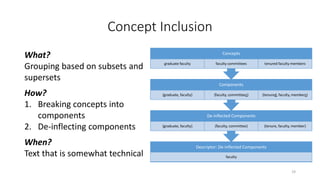
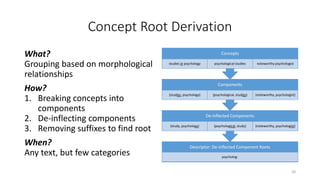
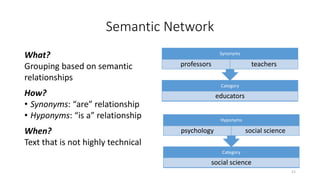
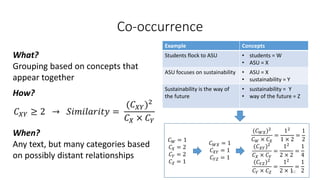
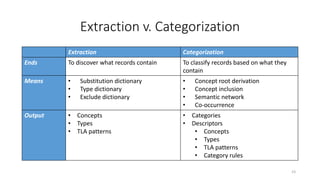
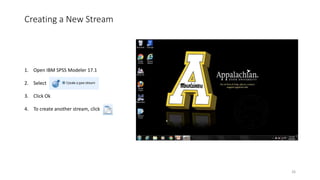
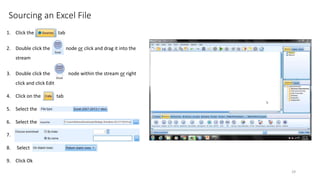
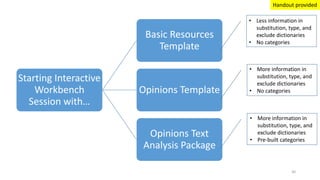
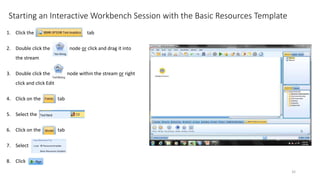
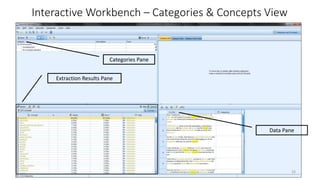
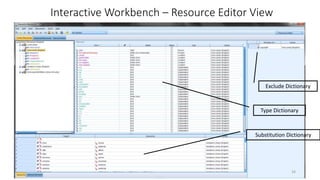
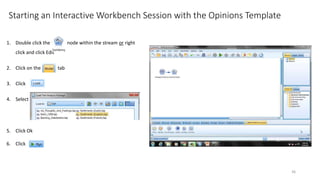
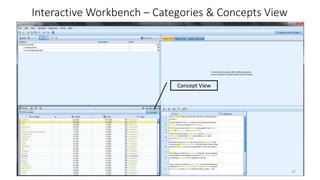
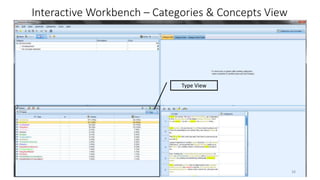
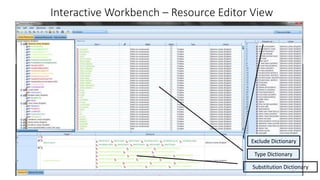
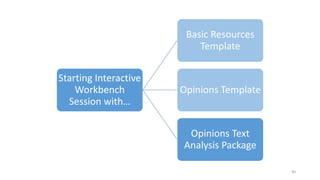
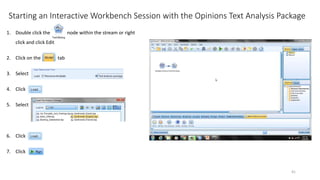
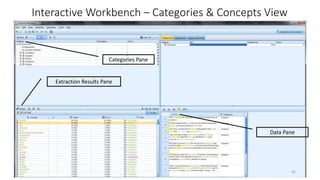
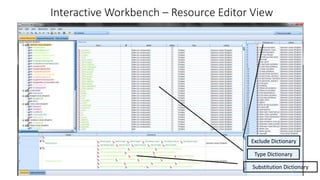
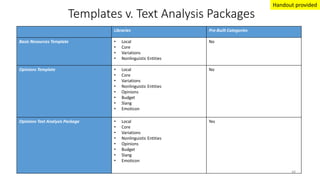
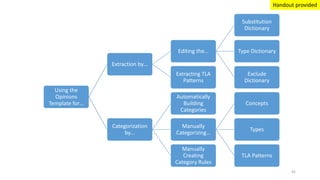
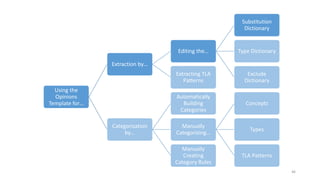
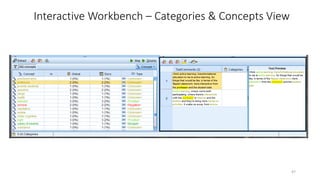
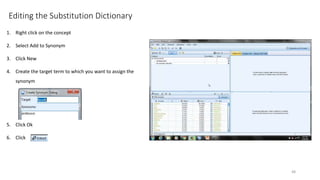
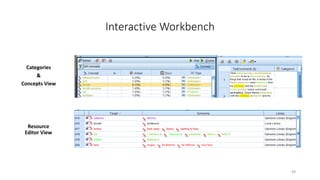
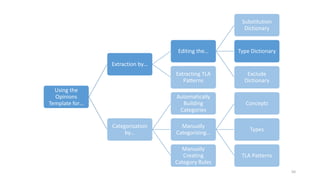
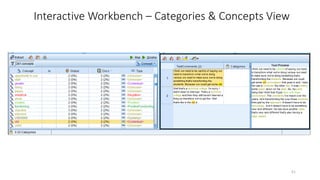
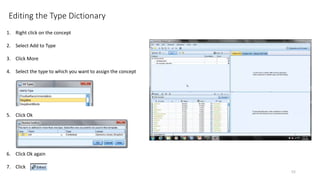
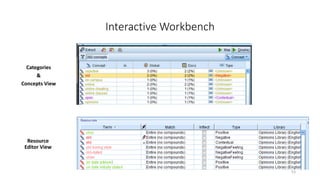
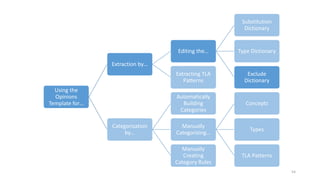
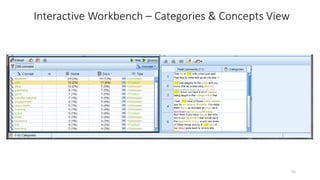
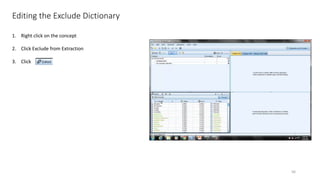
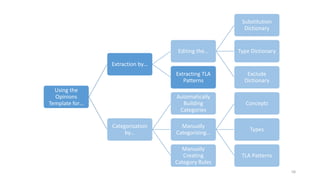
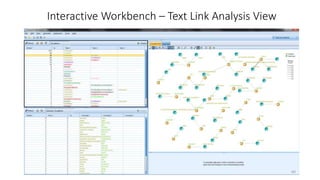
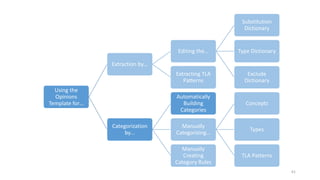
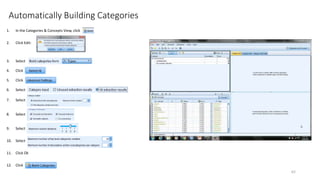
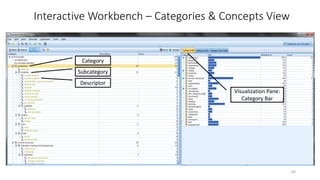
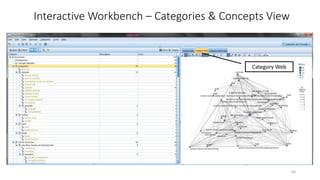
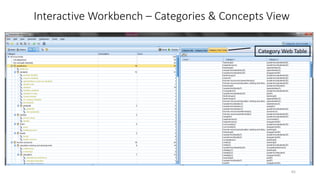
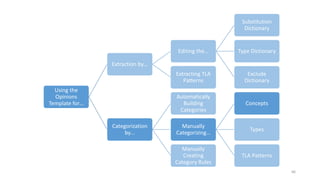
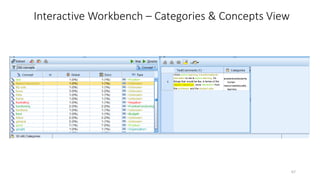
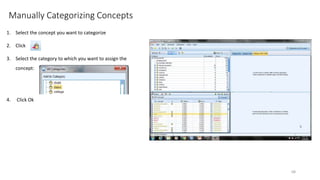
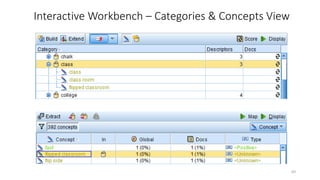
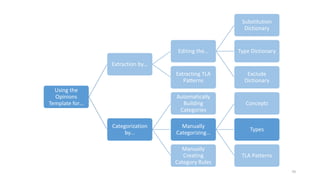
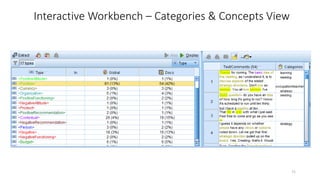
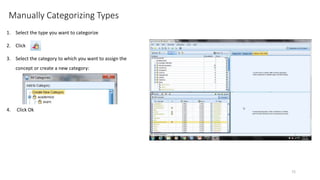
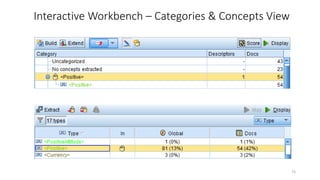
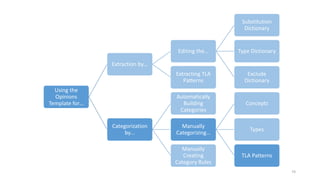
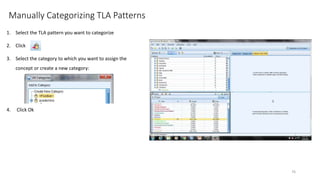
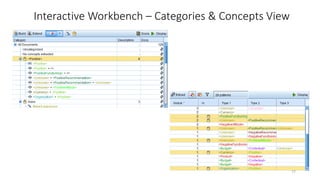
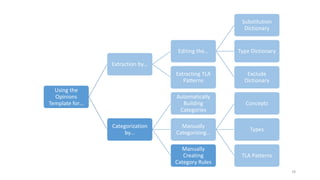
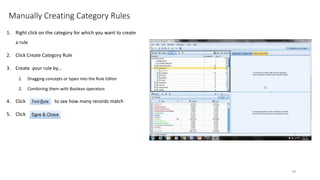
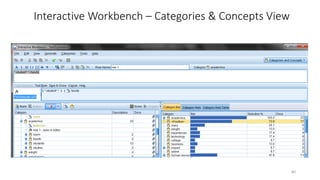
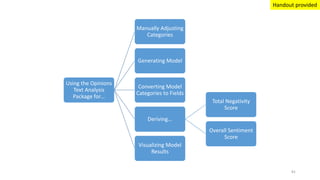
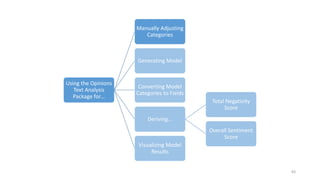
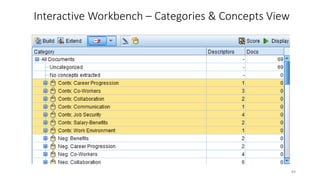
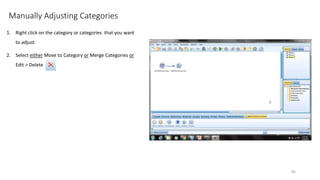
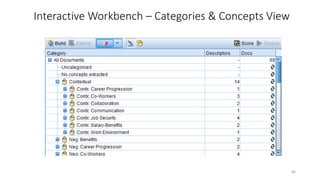
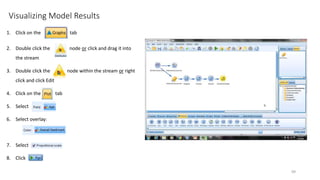
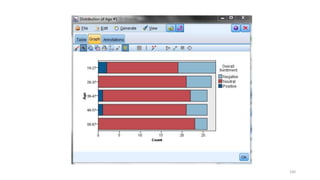
This document provides an introduction to text analytics using IBM SPSS Modeler. It defines key terms related to text analytics and outlines the main steps in the text analytics process: extraction, categorization, and visualization. It then provides a tutorial on using IBM SPSS Modeler to perform text analytics, including sourcing text, extracting concepts and relationships, categorizing records, and visualizing results. Templates and resources are described that can be used to start an interactive workbench session in Modeler for exploring text analytics.