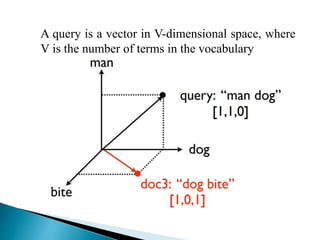
The document discusses various information retrieval models including Boolean, vector space, and probabilistic models. It provides details on how documents and queries are represented and compared in the vector space model. Specifically, it explains that in this model, documents and queries are represented as vectors of term weights in a multi-dimensional space. The similarity between a document and query vector is calculated using measures like the inner product or cosine similarity to retrieve and rank documents.




![ A document is represented as a set of keywords.
Index terms are considered to be either present or absent in a
document and to provide equal evidence with respect to information
needs.
Queries are Boolean expressions of keywords, connected by AND,
OR, and NOT, including the use of brackets to indicate scope.
[[Rio & Brazil] | [Hilo & Hawaii]] & hotel & !Hilton]
Output: Document is relevant or not. No partial matches or ranking.](https://image.slidesharecdn.com/unit2booleanvector-180726102741/85/Boolean-vector-space-retrieval-Models-4-320.jpg)












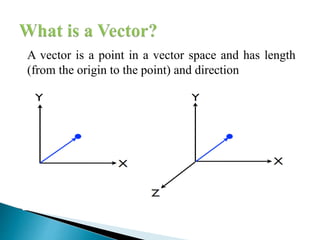
![ A 2-dimensional vector can be written as [x, y]
A 3-dimensional vector can be written as [x, y, z]](https://image.slidesharecdn.com/unit2booleanvector-180726102741/85/Boolean-vector-space-retrieval-Models-18-320.jpg)







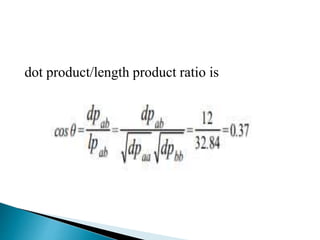
![ a =[1, 2, 3]
b =[4,-5,6]
a with b is dpab = 1*4 + 2*-5 + 3*6 = 12
a with itself is dpaa = 1*1 + 2*2 + 3*3 = 14
b with itself is dpbb = 4*4 + -5*-5 + 6*6 = 77
la = (dpaa) ½ = (14) ½ = 3.74; i.e., the length of a.
lb = (dpbb) ½ = (77)½ = 8.77; i.e., the length of b.
la*lb = (dpaa) ½ * (dpbb) ½ = 32.83;
i.e., the length product (lpab) of a and b.](https://image.slidesharecdn.com/unit2booleanvector-180726102741/85/Boolean-vector-space-retrieval-Models-27-320.jpg)