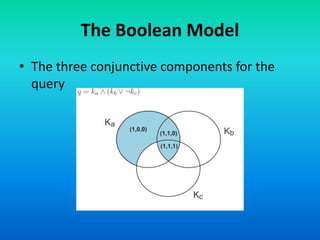
The Boolean model is a classical information retrieval model based on set theory and Boolean logic. Queries are specified as Boolean expressions to retrieve documents that either contain or do not contain the query terms. All term frequencies are binary and documents are retrieved based on an exact match to the query terms. However, this model has limitations as it does not rank documents and queries are difficult for users to translate into Boolean expressions, often returning too few or too many results.















































![ICDIM 06 Web IR Tutorial [Compatibility Mode].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/icdim06webirtutorialcompatibilitymode-250307100423-5b1c7700-thumbnail.jpg?width=640&height=640&fit=bounds)

















































